






一、决策树简介
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
决策树是一种树形结构,树中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶子节点代表一种分类结果。
决策树的建立过程(三要素):
1.特征选择:选择较强分类能力的特征;
2.决策树的生成:根据选择的特征生成决策树;
3.决策树的剪枝:决策树也容易过拟合,采用剪枝的方法缓解过拟合。
二、信息熵
“信息熵”:是信息论中的一个核心概念,它本质上是对不确定性或信息量的度量。
信息熵越大,信息的不确定性越大,信息的纯度越低,分类的效果越差;
信息熵越小,信息的不确定性越小,信息的纯度越高,分类的效果越好。
其中表示数据中
类别出现的概率,
表示数据的信息熵,单位是比特。
三、ID3决策树
1.特征选择
信息增益:g(D,A)=H(D)-H(D|A),信息增益 = 熵 - 条件熵
条件熵:子集1占比*子集1的熵作为子集1的结果,然后对所有计算结果求和。
2.决策树的生成
①计算每个特征的信息增益
②使用信息增益最大的特征将数据集拆分为子集
③使用该特征(信息增益最大的特征)作为决策树的一个节点
④若该节点已成功分类(节点中只有一个类的样本)或该节点达到停止生长条件,则停止生长,否则使用剩余特征对子集重复上述(1,2,3)过程。
3.不足
基于信息增益计算的方式,会偏向于选择种类多的特征作为分裂依据。
四、C4.5决策树
1.特征选择
信息增益率:信息增益率=信息增益/特征熵。
特征熵(也称惩罚系数):(特征子集1的占比*
(特征子集1的占比))
2.决策树的生成
类似ID3,只是调整为基于信息增益率进行特征选择,选择增益率大的特征作为分裂依据。
五、CART决策树
Cart模型是一种决策树模型,它即可以用于分类,也可以用于回归。
Cart回归树使用平方误差最小化策略,
Cart分类生成树采用的基尼指数最小化策略。
1.Cart分类树
特征选择:基尼值:
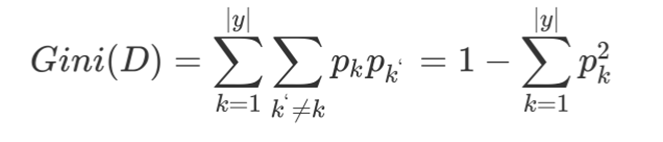
基尼系数:
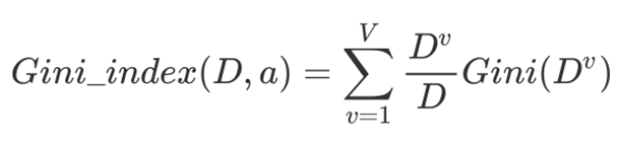
决策树的生成:类似ID3,调整为基于基尼系数进行特征选择。
2.Cart回归树
特征选择:最小化回归树预测结果的平方误差。
决策树的生成:1.选择一个特征,将该特征的值进行排序,取相邻点计算均值作为待划分点
2.根据所有划分点,将数据集分成两部分:R1、R2
3.R1 和 R2 两部分的平方损失相加作为该切分点平方损失
4.取最小的平方损失的划分点,作为当前特征的划分点
5.以此计算其他特征的最优划分点、以及该划分点对应的损失值
6.在所有的特征的划分点中,选择出最小平方损失的划分点,作为当前树的分裂点
六、三种决策树的对比
1.ID3:分支方式(指标)是信息增益
特点:①ID3只能对离散属性的数据集构成决策树
②倾向于选择取值较多的属性
2.C4.5:分支方式(指标)是信息增益率
特点:①缓解了ID3分支过程中总喜欢偏向选择值较多的属性
②可处理连续数值型属性,也增加了对缺失值的处理方法
③只适合于能够驻留于内存的数据集,大数据集无能为力
3.CART:分支方式(指标)是基尼指数
特点:①可以进行分类和回归,可以处理离散属性,也可以处理连续属性
②采用基尼指数,计算量减小
③一定是二叉树
七、剪枝
概念:决策树剪枝(Pruning)是防止决策树过拟合、提高模型泛化能力的关键技术。
问题:当决策树生长得太深、分支太多时,它会过度拟合训练数据中的噪声和细节,导致在未知数据上表现很差。
方案:剪枝通过移除对整体预测贡献不大或可能导致过拟合的部分子树或节点来解决这个问题。
什么是决策树的剪枝:把子树的节点全部删掉,并将该节点作为叶子节点。
决策树剪枝方法:1.预剪枝:在树生长过程中提前停止分裂,比如提前限制树的最大深度(优点:计算效率高,训练快;缺点:可能过早停止,错过重要模式);
2.后剪枝:先让树完全生长,再自底向上修剪子树(优点:保留更多有效结构,泛化性能通常更好;缺点:计算开销大)。

















 2363
2363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









