






一、集成学习概念
集成学习: (Ensemble Learning)是一种机器学习范式,它通过构建并结合多个模型来完成学习任务,获得更好的泛化性能。
核心思想:通过组合多个弱学习器来构建一个强学习器。
bagging思想:有放回的抽样;平权投票,多数表决方式决定预测结果;并行训练。
boosting思想:全部样本(重点关注上一训练器不足的地方训练);加权投票的方式;串行训练。
二、集成学习方法
核心对比:
| 方法 | 训练方式 | 预测方式 | 适用场景 |
| Bagging | 并行训练独立模型 | 投票/平均 | 高方差模型 (如决策树) |
| Boosting | 顺序训练,调整样本权重 | 加权投票/累加 | 高偏差模型 (如弱树) |
| Stacking | 两层模型(基模型+元模型) | 元模型组合基模型预测 | 复杂任务,需模型融合 |
详细对比:
1.Bagging(如随机森林):
训练时:通过"有放回"的自助采样(bootstrap)从训练集中生成多个子集,每个子集"独立"训练一个基学习器(如决策树)。
预测时:所有基学习器对未知样本进行预测,最终结果通过 投票(分类) 或 平均(回归) 得到。
API:sklearn.ensemble.RandomForestClassifier
2.Boosting(如AdaBoosting、GBDT、XGBoost):
训练时:基学习器是顺序训练的,每个新模型都试图修正前一个模型的错误(如调整样本权重或拟合残差)。
预测时:所有基学习器的预测结果进行加权组合(如AdaBoost)或累加(GBDT系列)。
API:sklearn.ensemble.AdaBoostClassifier / sklearn.ensemble.GradientBoostingClassifier
3.Stacking:
训练时:先训练多个不同类型的基学习器,再用它们的输出训练一个元学习器(meta-model)。
预测时:基学习器先预测,然后元学习器基于它们的输出做最终预测。
三、底层详解
Bagging
概述:多个模型独立训练,投票决定结果(稳)
代表算法:
随机森林算法
API:导包:sklearn.ensemble.RandomForestClassifier
n_estimators:决策树数量(default=10)
Criterion:entropy、或者gini(default=gini)
max_depth:指定树的最大深度(default=None表示树会尽可能的生长)
max_features="auto",决策树构建时使用的最大特征数量
bootstrap:是否采用有放回的抽样,如果为False将会使用全部训练样本(default=True)
步骤:1.有放回的随机抽样产生训练集;2.随机挑选n个特征(n小于特征总数);3.训练弱学习器;4.重复1-3,训练n个弱学习器(决策树);5.预测结果:分类问题:多数表决;回归问题:计算平均值。
Boosting
概述:模型逐步改进,加权组合结果(准)
代表算法:
①Adaboost算法(自适应提升)
API:sklearn.ensemble.AdaBoostClassifier
算法思想:通过逐步提高前一步分类错误的样本的权重(放大)来训练一个强分类器。
步骤:1.初始化数据权重,训练第一个学习器,根据预测结果找一个错误率最小的分裂点,然后重新计算样本权重,模型权重;
2.根据新的样本权重,训练第二个学习器,根据结果找一个错误率最小的分裂点,然后再次更新样本权重,模型权重;
3.重复以上过程,依次训练n个弱学习器.最终组合起来进行预测,结果大于0为正类,小于0为负类。
其中:
迭代训练在前一个学习器的基础上,根据新的样本权重训练当前学习器直到训练出n个弱学习器;
n个弱学习器集成预测公式:,其中
为模型权重,输出结果大于0则归为正类,小于0归为负类;
模型权重计算公式:,
是模型权重,
表示第t个弱学习器的错误率;
样本权重计算公式:
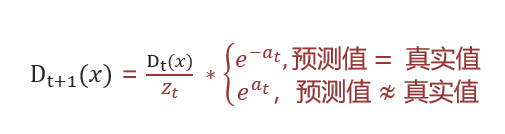
为归一化值(所有样本权重总和),
为样本权重,
为模型权重。
②GBDT(梯度提升树)
首先我们要认识什么是提升树(Boosting Decision Tree ),核心思想是通过迭代拟合残差(即真实观测值与当前模型预测值的差异),逐步提升模型精度。每一轮新模型的目标是拟合前一轮的残差,最终将所有弱学习器的预测结果叠加,形成强学习器。
GBDT的API:sklearn.ensemble.GradientBoostingClassifier
GBDT是用损失函数的负梯度作为残差的近似(当损失函数为平方误差时,负梯度恰好等于残差)
模型:
残差:真实观测值-预测值
每一个新学习器,都是拟合真实值与之前所有基学习器共同预测的结果之间的残差来提升的。
对于回归问题,损失函数是平方损失,GBDT拟合的负梯度就是残差。
对于分类问题,损失函数变为 logloss,此时拟合的目标值就是该损失函数的负梯度值。
步骤:1.初始化弱学习器,将目标值的均值作为初始的预测值;
2.迭代构建学习器,每一个新学习器拟合的是真实值与上一步模型(n-1个模型)预测结果之间的残差;
3.达到指定的学习器个数停止;
4.预测时,将所有弱学习器的输出结果组合起来作为强学习器的输出。
③XGBoost(极端梯度提升树)
XGBoost在很多机器学习竞赛和实际应用中表现出色,后续算法(如LightGBM、CatBoost)均受其启发。
XGBoost (Extreme Gradient Boosting)极端梯度提升树,核心构建思想围绕梯度提升框架展开,通过集成弱学习器(决策树)、优化目标函数和正则化控制实现高效、高精度的模型训练。
构建思想:
1.构建模型的方法是最小化训练数据的损失函数:
训练的模型复杂度较高,易发生过拟合。
2.在损失函数中加入正则化项
提高对未知的测试数据的泛化功能。
XGBoost是对GBDT的改进,并且在损失函数中加入正则化项防止过拟合,提升泛化能力。
当对目标函数求解比较困难时,通过泰勒展开二项式将目标函数换一种近似的表示方式。
泰勒展开:![]()
一阶泰勒展开:![]()
二阶泰勒展开:![]()
XGBoost的API:import xgboost as xgb
模型:
xgboost目标函数:
xgboost的模型复杂度:

















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









