






目录
 https://openaccess.thecvf.com/content_CVPR_2020/papers/Lin_BEDSR-Net_A_Deep_Shadow_Removal_Network_From_a_Single_Document_CVPR_2020_paper.pdf
https://openaccess.thecvf.com/content_CVPR_2020/papers/Lin_BEDSR-Net_A_Deep_Shadow_Removal_Network_From_a_Single_Document_CVPR_2020_paper.pdf https://github.com/IsHYuhi/BEDSR-Net_A_Deep_Shadow_Removal_Network_from_a_Single_Document_Image/blob/main/result/background_color.jpg
https://github.com/IsHYuhi/BEDSR-Net_A_Deep_Shadow_Removal_Network_from_a_Single_Document_Image/blob/main/result/background_color.jpg一、算法提出的背景
什么是BEDSR-Net算法?
我们首先来看一下BEDSR-Net算法的全称:Background Estimation Document Shadow Removal Network,翻译过来的中文意思即是——背景估计文档阴影去除网络。那么顾名思义,这一个算法就是一个专门将文档图像的阴影去除的神经网络算法。
BEDSR-Net算法旨在解决文档图像中的阴影问题,因为阴影可能影响到文档图像的可读性和后续图像处理任务。该算法主要采用了深度学习的方法,利用神经网络来学习文档图像中的阴影特征,并通过去除这些阴影来恢复原始文档图像的清晰度和可读性。
如下图所示,BEDSR-Net算法就是将有阴影图像的左图的阴影去掉,然后形成了右图,中间的图像是原本的没有阴影的文档图像,我们可以发现,使用了BEDSR-Net算法后,基本可以完全将文档的阴影图像去掉。

BEDSR-Net算法有什么用?
对于当今时代的我们来说,文件在我们的日常生活中是不可或缺的,基本上是无处不在的,比如报纸、收据、文件、报告等。而我们也是通常需要获取文档的数字副本。在过去,扫描仪通常用于数字化高质量的文档,所以基本上不会出现什么带有阴影的文档图像。但是随着手机的普及和相机的改进,越来越多的人倾向于使用手机和相机代替扫描仪来获取文件的数字副本,因为它们很容易获得。
但是与扫描仪相比,使用手机摄像头捕获文档通常存在两个问题。首先,由于相机透视,文档的几何形状可能会扭曲,而不是矩形;此外,文档可以折叠或弯曲。其次,拍摄的文档图像容易受到阴影的影响,因为光源经常被相机或用户的手挡住。然而,即使没有遮挡器,在现实世界中拍照时,文档上的照明也经常因为光线的缘故而不均匀。因此,手机摄像头拍摄的文档图像经常出现阴影和阴影不均匀,导致视觉质量和可读性差。而用户们通常更喜欢具有均匀照明的文档,类似于他们使用扫描仪获得的文档,因为扫描仪是在控制良好的照明环境中拍摄照片的。
因此,现在的文档图像带有阴影基本上是非常普遍的,那么我们有必要使用一些方法来去除这些阴影,虽然现在大多数方法都是基于自然图像来去除阴影的,但是整体效果还是不太理想,而且很多算法都不是基于文档图像的。所以BEDSR-Net作为第一个基于深度学习的文档图像阴影去除方法,填补了文档图像阴影去除领域的研究空白,它通过深度学习网络学习文档图像中的阴影特征和去除阴影的策略,从而能够更准确地去除文档图像中的阴影,提高图像的质量和可读性。
总的来说,BEDSR-Net算法在文档图像处理领域具有重要的应用价值。以下是BEDSR-Net算法的一些主要用途:
1. 文档图像阴影去除:BEDSR-Net算法的核心目标是去除文档图像中的阴影。通过去除阴影,可以显著提高文档图像的可读性和质量。这对于文档的自动识别、文字提取、OCR(光学字符识别)等后续图像处理任务非常重要。
2. 提升文档图像质量:由于阴影会导致文档图像的对比度降低、细节模糊等问题,使用BEDSR-Net算法可以提高文档图像的质量。去除阴影后,文档图像的清晰度和可读性得到改善,有助于更好地满足人们的阅读和分析需求。
3. 文档图像分析和处理:去除阴影后的高质量文档图像可以提供更准确的图像特征和信息,有助于进一步的文档图像分析和处理。例如,它可以用于文档分类、布局分析、关键信息提取等任务,从而提升文档处理的自动化程度和准确性。
4. 提高文档图像的可视化效果:去除阴影可以改善文档图像的外观和可视化效果。这对于数字出版物、在线文档浏览和展示等场景中的文档图像显示非常有益。
BEDSR-Net算法与其它去阴影算法的比较?
如下图所示,分别使用Bako、Kligler、Jung、ST-CGAN、ST-CGAN-BE、BEDSR-Net算法来对同一张带有阴影的文档图像进行阴影去除处理,其中ST-CGAN-BE是在ST-CGAN算法的基础上,为了突出背景估计的重要性而增加了一个BE-Net网络从而形成的一个新的算法。另外,第一列的图像是带有阴影的文档图像,第二列GT是原本的没有阴影的图像,后面几列依次对应着每一个算法处理后的去除阴影的文档图像。
对每一个算法的去除阴影效果的图像进行比较,我们可以发现,Bako算法和Kligler算法在去除阴影时会有阴影边缘留存,在阴影和非阴影区域之间的边界周围保留了一些阴影,没有办法很好地将阴影图像去掉,而且还会导致一些图片原有的颜色被洗掉。而Jund算法虽然可以很好地将一些阴影给去掉,但是往往会导致原来的彩色文档图像褪色,尽管文档图像变得更亮。因为它们都是基于启发式方法的一种去除阴影图像的算法,需要更多的手动调节和干预。
而对于ST-CGAN来说,这是一个最先进的自然图像阴影去除方法,但是我们可以发现它没有办法正确地恢复成无阴影图像,阴影区域还是存在的,尽管它变得更亮,而且它的训练数据也是需要大量成对的文档图像进行训练。而我们可以发现经过改良后的算法ST-CGAN-BE虽然没有办法完全地将阴影图像去掉,但是已经可以将大部分的阴影图像去掉了,所以我们可以知道获取背景图像是非常重要的。
而最后对于BEDSR-Net算法来说,它的去除阴影的效果是这么多算法中最好的,不仅可以基本将所有的阴影图像给去除掉,而且还不损坏原来的文档内容以及色彩,基本上与原本的图像保持一致。所以我们可以知道,BEDSR-Net算法在文档阴影去除这一方面的效能是比较理想的,而且还是第一个基于深度学习的文档阴影去除方法。

二、算法的基本原理
算法的总体框架
下面是这一个BEDSR-Net算法的基本框架。首先,为了充分利用文件图像的特有属性(例如其背景颜色一般为纸张颜色),该算法的作者们提出了背景估计模块去提取文件图像的全局背景颜色。而在估计背景颜色的同时,该模块还学习了背景和非背景像素的空间分布信息,并将这些空间分布信息编码为注意力图。然后,根据背景颜色和注意力图的信息,去阴影网络能够更好地完成去除文档图像阴影。在人工合成数据集上训练模型,训练好的模型同样对真实图像具有泛化能力。
所以该算法的总体框架分为了两个子图,分别为背景估计子网络(Background Estimation Network,BE-Net ) 和阴影去除子网络(Shadow Removal Network,SR-Net)。BE-Net主要用于提取背景图像和生成注意力图,然后SR-Net主要是根据生成的注意力图和数据集中带有阴影的文档图像来对阴影进行去除。
对于该算法的图像训练集:
每一个训练样本都有一个样本对(Si,Ni)组成,其中N为样本数,Si为带有阴影的文档图像,而Ni为其对于的非阴影图像。
在两个子网络中,首先根据BE-Net来估计背景图像和注意力图:
其中 ψ(S)表示网络映射函数,然后根据输入的S,计算其背景颜色b以及注意力图H
然后再根据SR-Net来完成图像阴影去除:
其中 ψ(…)表示网络映射函数,然后根据输入的S和(b,H),来计算去除阴影的图像N
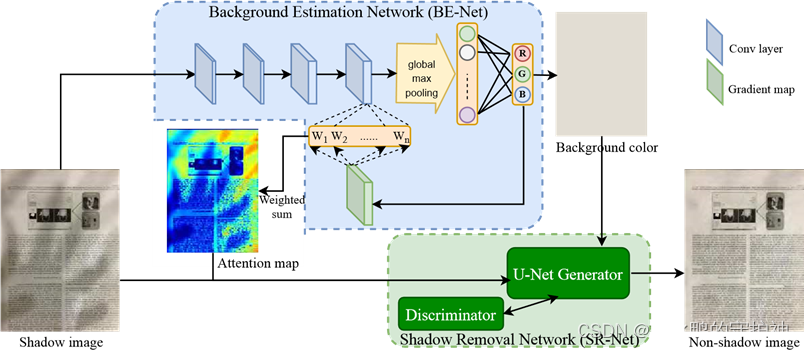
BE-Net(背景估计子网络)
这一个网络主要是作者受到Bako等人的启发,将尝试着去恢复文档的背景颜色,但是Bako等人所使用的启发式方法主要是通过分析颜色分布来进行估计,而当文档被大面积的阴影或彩色图形覆盖时,它往往会导致颜色偏移或颜色褪色。
而作者将使用深度网络对背景颜色进行更加稳健的估计,该神经网络主要需要识别训练集D中的每一个文档图像对(Si,Ni)的真值背景颜色bi。
而如何去获取这一个文档图像的背景颜色呢?可以通过要求用户在非阴影图像Ni中手动拾取属于背景的区域,并计算拾取区域的平均颜色来实现,但是这一个方法的工作量比较大。所以为了减轻手动工作,作者制作了一个自动提取的脚本。
首先,将非阴影文档图像Ni的像素根据其强度值聚类为两组,这两组通常分别对应内容和背景,而且文档的背景颜色通常更亮,因此,可以将强度较高的团簇作为背景团簇。由于图像 Ni 不包含阴影,可以使用背景簇的平均颜色作为训练集中第 i 个图像对的背景颜色 bi。而对于聚类,主要采用了高斯混合模型(GMM)和期望最大化(EM)。其中如果启发式方法失败,例如,当文档具有深色背景色时,用户可以更正结果,可以将强度较低的团簇作为背景团簇。
最后,还需要给定该网络的损失函数计算loss,当给定阴影图像Si和背景颜色bi时,该神经网络BE-Net的损失函数loss为:
因此,可以通过该损失函数来监督该神经网络不断进行训练,使得提取出来的背景颜色接近于真实的背景颜色bi。
如上图所示,BE-Net神经网络主要由四个卷积层组成,后跟一个全局最大池化层和一个全连接层,卷积层从输入阴影图像中提取适当的特征,然后采用全局池化机制,将每个特征图汇总成一个值。主要是通过使用全局池化来桥接卷积层和全连接层,使得该神经网络可以处理不同大小的图像。
而在估计背景图像的时候,可以使用BE-Net的最后一个卷积层的特征图来提取注意力图,提取的注意力图确实可以很好地捕获了阴影图像中无阴影和有阴影所在的位置。
所以我们可以知道,该神经网络BE-Net主要是输入带有阴影的文档图像,然后通过四个卷积层和一个全局最大池化层以及一个全连接层,输出了一个注意力图和一个文档图像的背景图,以供在下一个网络SR-Net中继续进行阴影的去除。
SR-Net(阴影去除子网络)
在获得上面一个子网络输出的背景图像和注意力图后,如何进行阴影的去除呢?
作者采用了条件生成对抗网络(cGAN),该网络在图像到图像转换等许多任务中已被证明是有效的,cGAN模型由两个参与者组成:生成器G和判别器D。当给定一个条件变量时,生成器G旨在生成逼真的图像来欺骗判别器D,而判别器D试图将G生成的图像与数据集中的真实图像区分开来。这一个G和D之间的比赛增强了生成器在产生与真实图像无法区分的结果方面的能力。
对于生成器G,采用的是U-Net模型,这是一个全卷积神经网络,由编码器和解码器组成。解码器中的特征将通过每个空间分辨率的跳跃连接与编码器中的特征相结合。编码器和解码器都使用了五级层次结构。生成器G主要将阴影图像、预测的背景颜
和注意力图
的串联作为输入,然后预测非阴影图像
:
对于判别器D,采用的是马尔可夫判别器(PatchGAN)。D 的输入是阴影图像Si和配对的非阴影图像Ni的6通道串联。而为了训练SR-Net,可以使用以下损失:
其中为测量预测的非阴影图像与真实图像的偏差:
而是G和D竞争的GAN损失值:
而在训练完后,生成器G的输出即可作为该网络SR-Net的输出。
三、算法的神经网络训练
在训练前,我们首先需要在GitHub上下载好源代码,并且确保源码中有如下的代码文件:

随后,我们可以打开文件对代码进行解读,然后我们需要打开命令界面,进入到该文件目录中,然后输入如下的命令:
python utils/make_configs.py --model benet bedsrnet在运行上面的命令后,可以在configs的两个文件夹BENet和SRNet中得到如下所示的文件:
![]()
然后,我们便可以分别对这两个子网络BE-Net和SR-Net进行训练。
BE-Net的训练
首先是对背景估计子网络BE-Net进行训练,值得注意的是,如果我们在进行训练时,运用的是CPU进行训练,我们首先需要将文件目录为.\libs\models\models.py的文件进行如下修改:
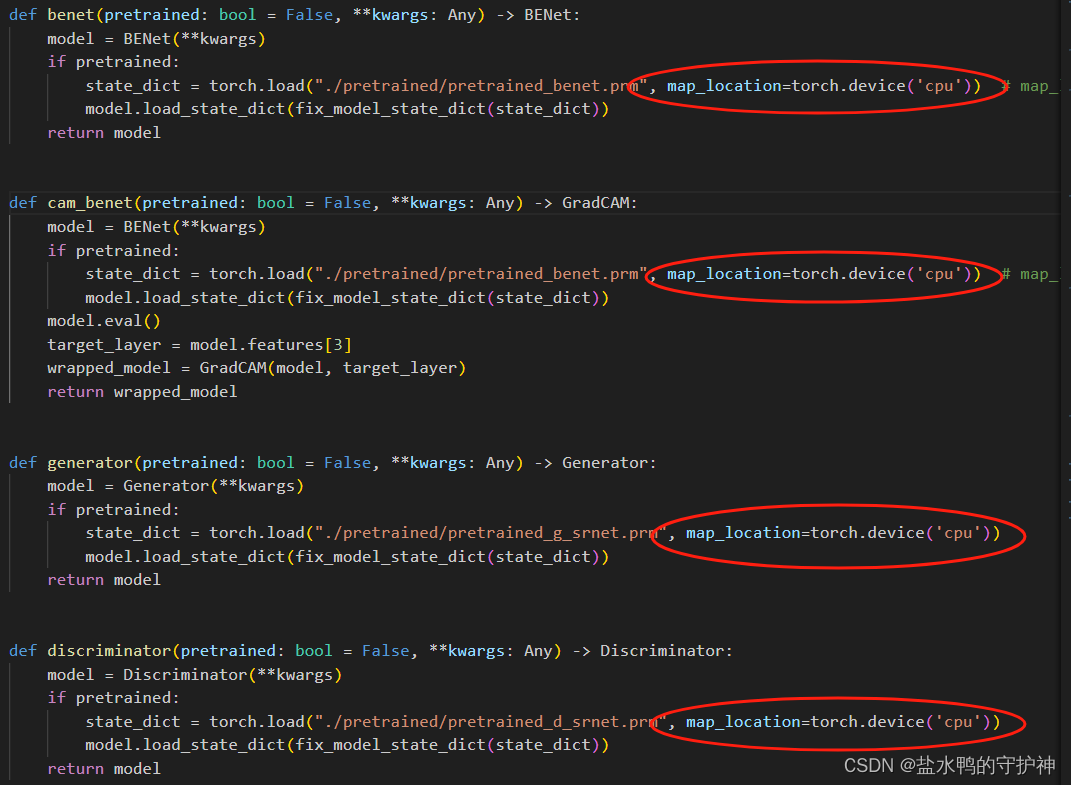
而如果我们采用的是带有GPU的形式来进行训练的话,就可以不必理会。
在我们开始进行训练前,我们首先需要将train_benet.py中的这三行代码注释掉:
from albumentations import Affine # noqa
from albumentations import ColorJitter # noqa
import wandb然后在命令行窗口中输入如下命令开始训练:
python train_benet.py ./configs/model=benet/config.yaml(这一个训练的过程较长,需要耐心地等待,顺便提一句,最好使用性能比较高地电脑来进行训练,不然就会像笔者一样,在训练完后,电脑寿命直接减半……)
在训练结束后,我们可以在configs文件夹的BENet文件夹中看到有几个输出文件,如图所示:
其中log文件是训练日志,prm文件是训练后的模型,yaml文件是运行make_configs.py文件后得到的。至此,我们便训练完了我们的第一个子网络BE-Net。
SR-Net的训练
接下来便可以开始训练我们的第二个子网络SR-Net。如果我们是使用CPU来进行训练,因为在上面子网络BE-Net的训练中已经对文件目录为.\libs\models\models.py的文件进行了修改,所以不必重复修改。
在开始训练之前,我们首先需要对train_bedsrnet.py文件中的如下三行代码进行注释
from albumentations import Affine # noqa
from albumentations import ColorJitter # noqa
import wandb随后需要在文件目录为.\configs\model=bedsrnet\config.yaml的文件中将loss_function_name的“L1”修改为“GAN”。
最后在命令行界面中输入如下的命令即可:
python train_bedsrnet.py ./configs/model=bedsrnet/config.yaml(同样的,训练过程较长,等待……)
在训练结束后,我们便可以在configs文件夹的SRNet文件夹中看到有几个输出文件,如下图所示:
其中log文件是训练日志,prm文件是训练后的模型,yaml文件是运行make_configs.py文件后得到的。至此,我们便成功训练完了我们的第二个子网络SR-Net,也就意味着,我们成功地得到了该算法的一个模型。我们可以在demo文件中对我们训练得到的模型进行测试评估。
四、算法的用法介绍
环境配置——避免踩坑
如何快速地配置好可以运行这一个算法的环境?
如果需要对这一个算法的神经网络进行训练的话,可以参考上一部分——算法的神经网络训练,如果我们只是想直接使用这一个算法来进行带有阴影的文档图像阴影去除的话,我们可以直接使用下载的算法源码中的demo.ipynb文件,这是一个jupyter NoteBook的代码文件,可以使用Anaconda这一个集成环境来进行打开使用。如果我们还没有下载这一个Anaconda怎么办?不用慌,可以直接到百度中搜索Anaconda的安装,或者直接点击这一篇博客Anaconda的安装,按照该博客上面的过程进行安装即可。
好啦,那么如果我们已经安装好了Anaconda,我们如何来配置运行该算法需要的环境呢?
我们首先打开Anaconda的命令行窗口Anaconda prompt
然后新建一个python=3.8的虚拟环境:
conda create your_name python=3.8然后激活并且进入创建的该虚拟环境中:
activate your_name然后下载安装运行这一个BEDSR-Net算法所需的工具以及库:
pip install pandas==1.3.3
pip install torchvision==0.9.1最后我们便可以在Anaconda Navigator中打开相对应的环境配置下的Jupyter NoteBook,并且打开我们下载的源码中的demo.ipynb文件,然后运行里面的第一部分代码:

至此,该算法BEDSR-Net需要运行的环境已经配置好了,接下来我们便可以在该demo文件中进行测试以及使用啦。
算法的测试——在jupyter NoteBook上运行测试
下载源码(可跳过)
我们在配置好了所需的环境后,便可以开始在这一个demo文件中运行和测试这一个BEDSR-Net算法的效果了。
在打开这一个demo文件后,我们便可以发现,首先的第一部分是环境配置和下载源码的压缩文件并且进行解压缩,随后再cd进入指定的文件夹中,同时ls查看该文件夹中有什么文件。如果我们已经在Github上下载过了源码,那么这一部分是可以省略掉的。
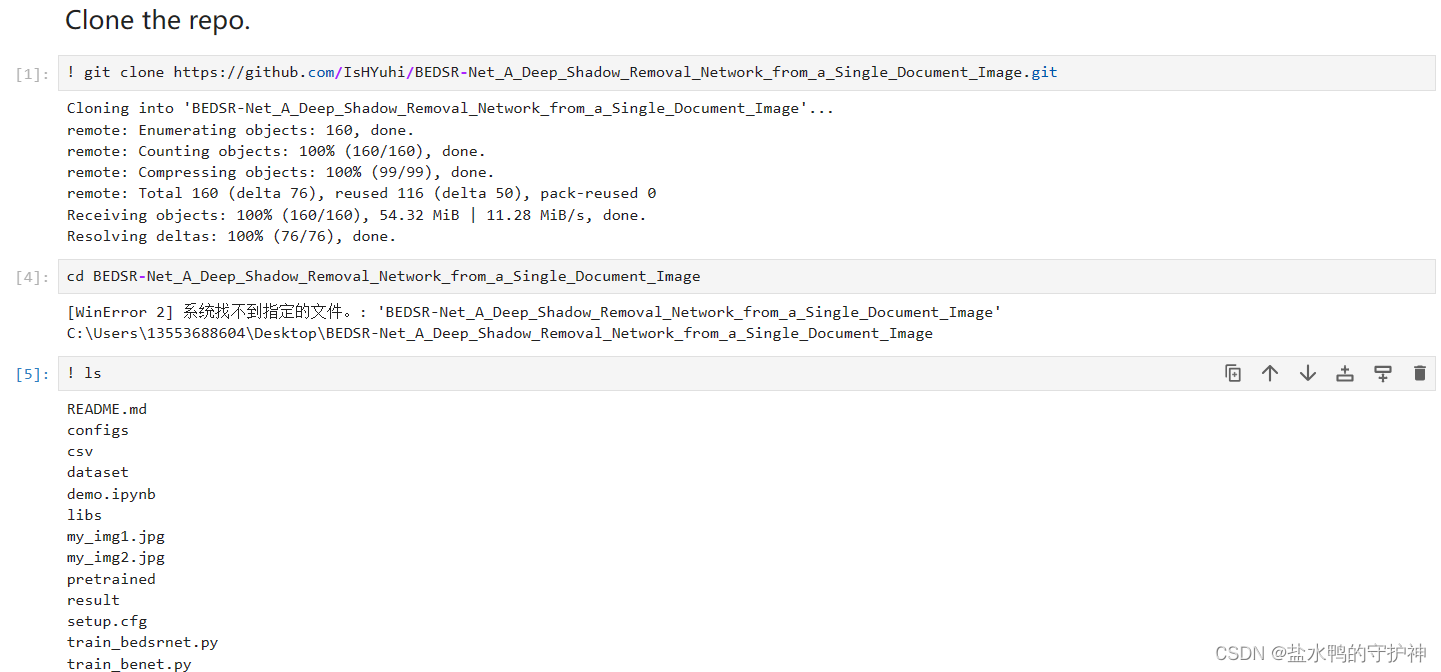
下载数据集和训练好的模型(可跳过)
接着,我们便会发现,这一个demo文件的下一部分为下载数据集dataset、下载训练和测试数据的csv文件以及还有就是已经训练好的神经网络pretrained,应该注意的是,这一些都是从google的drive上面下载的,所以可能需要挂一个代理,如果没有挂代理的话是没有办法连接上的。不知道有没有人和笔者一样倒霉,没有开代理报错没有办法连接上google.drive,但是开了代理就会报错proxy错误,呜呜呜……
如果你也出现了这一个循环bug,不要慌,因为笔者已经帮你把这一个坑都踩过了。首先你需要关掉你的系统代理,然后安装服务模式,最后打开TUN模式,然后再去运行一下下载的代码,就会发现可以成功下载啦。
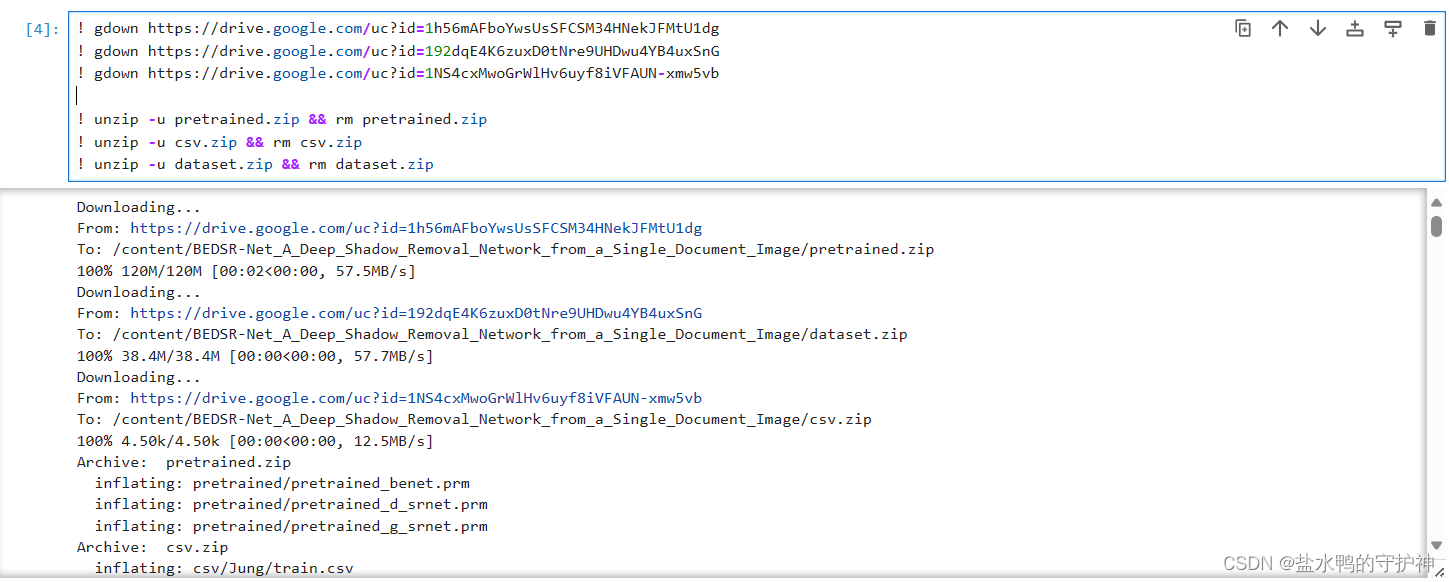
当然,如果你不想以命令行的形式下载这一些内容,你也可以按照README.md文件上的提示去到相对应的网址然后下载压缩包,再解压缩放到相对应的文件夹中即可。


开始运行测试
接下来,我们已经配置好了环境以及安装好了所有运行测试所需的所有文件,我们便可以开始运行文件中的代码内容啦。
首先第一个是导入所需要的包和库,运行即可。
接下来的代码内容是一个用于将张量转换为可显示的图像,方便在图像处理任务中进行可视化和展示的函数,主要的作用是方便进行图像的展示。
下一段代码是创建一个测试数据集的数据加载器 test_loader,该加载器将从名为 "Jung" 的数据集中加载数据,并应用定义的数据变换进行预处理。
接下来的代码就是主要用于设置设备(device),如果可用的话使用CUDA加速,否则就使用CPU
下一段代码就主要用于测试模型的性能,主要通过遍历测试数据集中的每个样本,并使用模型进行推理,将推理结果和相关指标存储在列表中。接着将平均的峰值信噪比psnr和结构相似性指数ssim打印出来,这两个参数就对应着这一个模型的去除文档图像的阴影的性能。
接着下一部分的代码就是将我们测试的结果图像,包括带有阴影的图像、本来没有阴影的图像、去除阴影后的图像、背景图像以及注意力图绘制出来,主要将这一些图像绘制在一个大的图像中,每一行的五个图像都是一一对应的。
下一部分的代码就是在一个大的图像中绘制测试集中每个样本的输入图像。
然后的代码是在一个大的图像中绘制测试集中每个样本的去除阴影后的图像。
接着是在一个大的图像中绘制测试集中每个样本的真实没有阴影的图像。
然后是在一个大的图像中绘制测试集中每个样本的注意力图。
当然还有下一个就是在一个大的图像中绘制测试集中每个样本的背景图。
最后的一部分代码就是可以使用我们自己的带有阴影的文档图像,然后进行阴影去除,并且将结果图像绘制在一个大的图像中,我们使用的带有文档的图像、阴影去除后的图像、背景图像以及注意力图如下图所示:

报错提示与修改
我们在运行这一个demo文件进行代码测试的过程中,发现总是会报一些错误,刚开始我们以为是我们的环境可能并没有配置好,导致了报错。但是在我们重装了几次,并且尝试过了不同的环境之后,我们发现这一个报错并没有消失,我们才意识到,可能是源码出现了bug……不过也正常,毕竟这一个网上下载的源码并不是官方的代码,因为好像paper的作者的源码并没有开源……
那么我们在意识到可能是源码出现bug之后,我们就马不停蹄地对源码进行修改,下面是出现的报错提示,以及我们修改的代码。读者可以观察,如果你们在运行demo文件时并没有出现这一些报错提示的话,那就大吉大利;如果出现了报错提示,那也不需要慌,可以按照下面的修改意见进行代码的修改。如果你们还是没有办法成功运行demo文件,欢迎私信笔者~
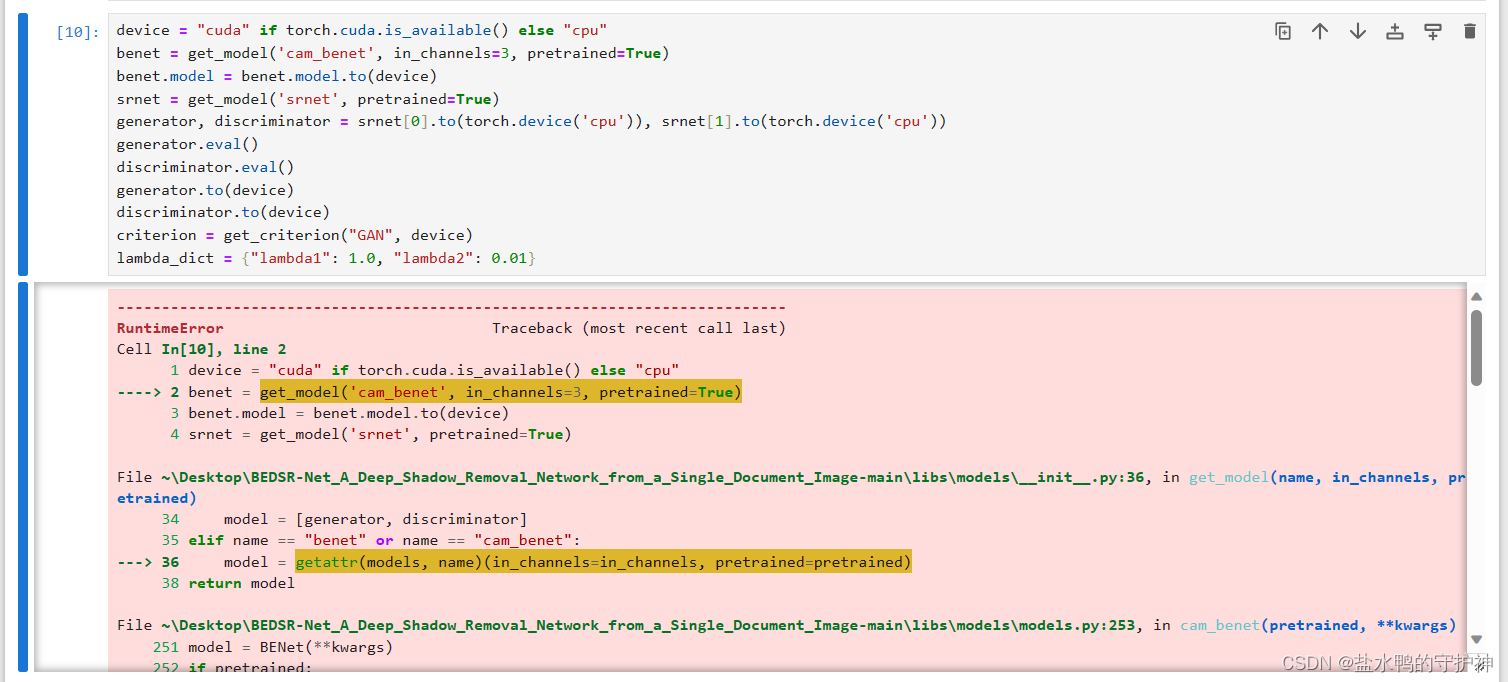
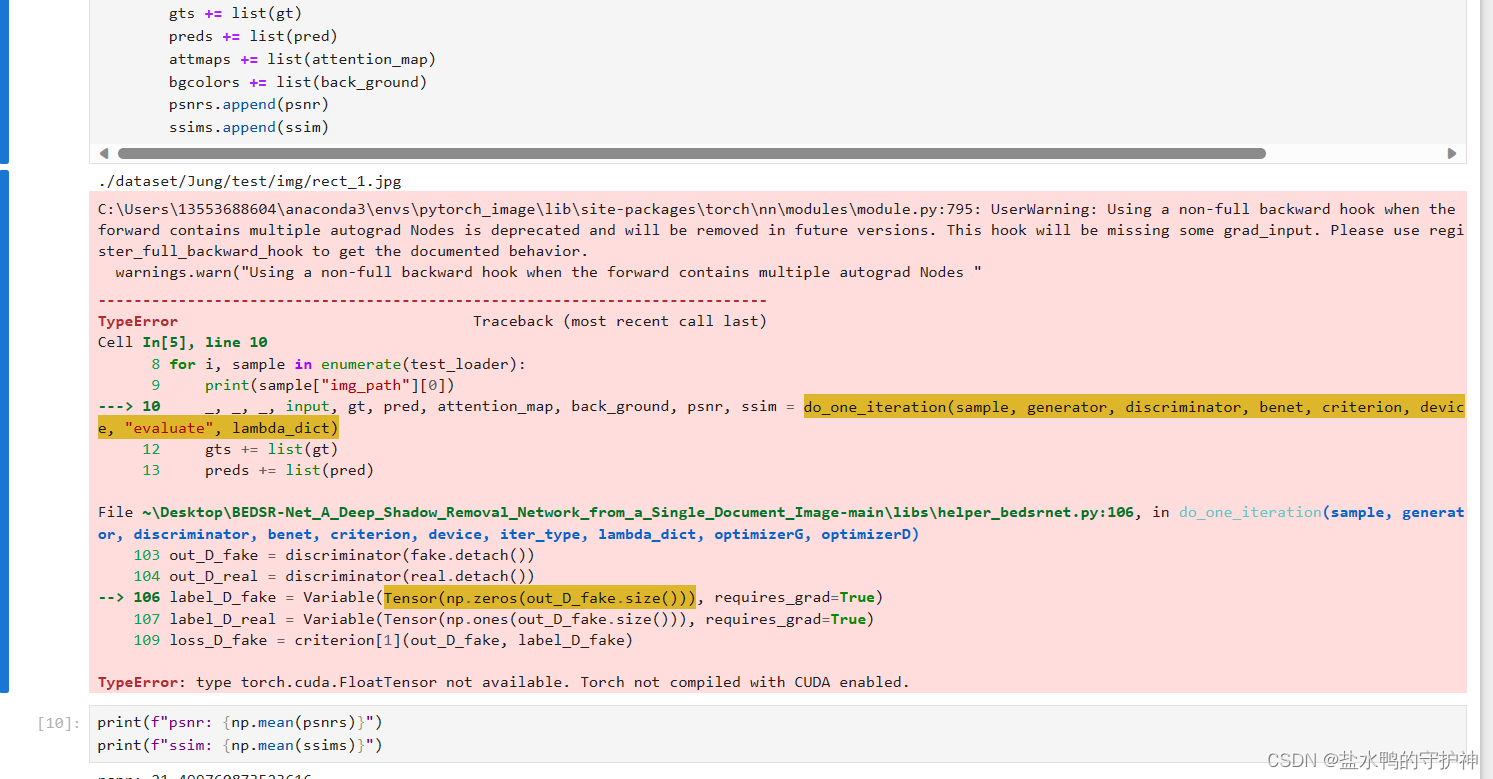
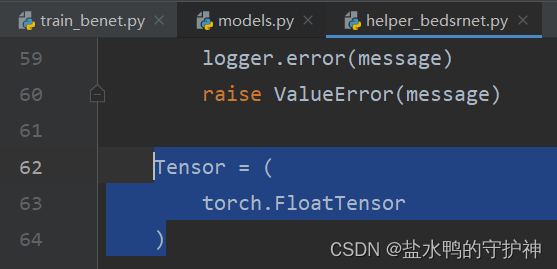
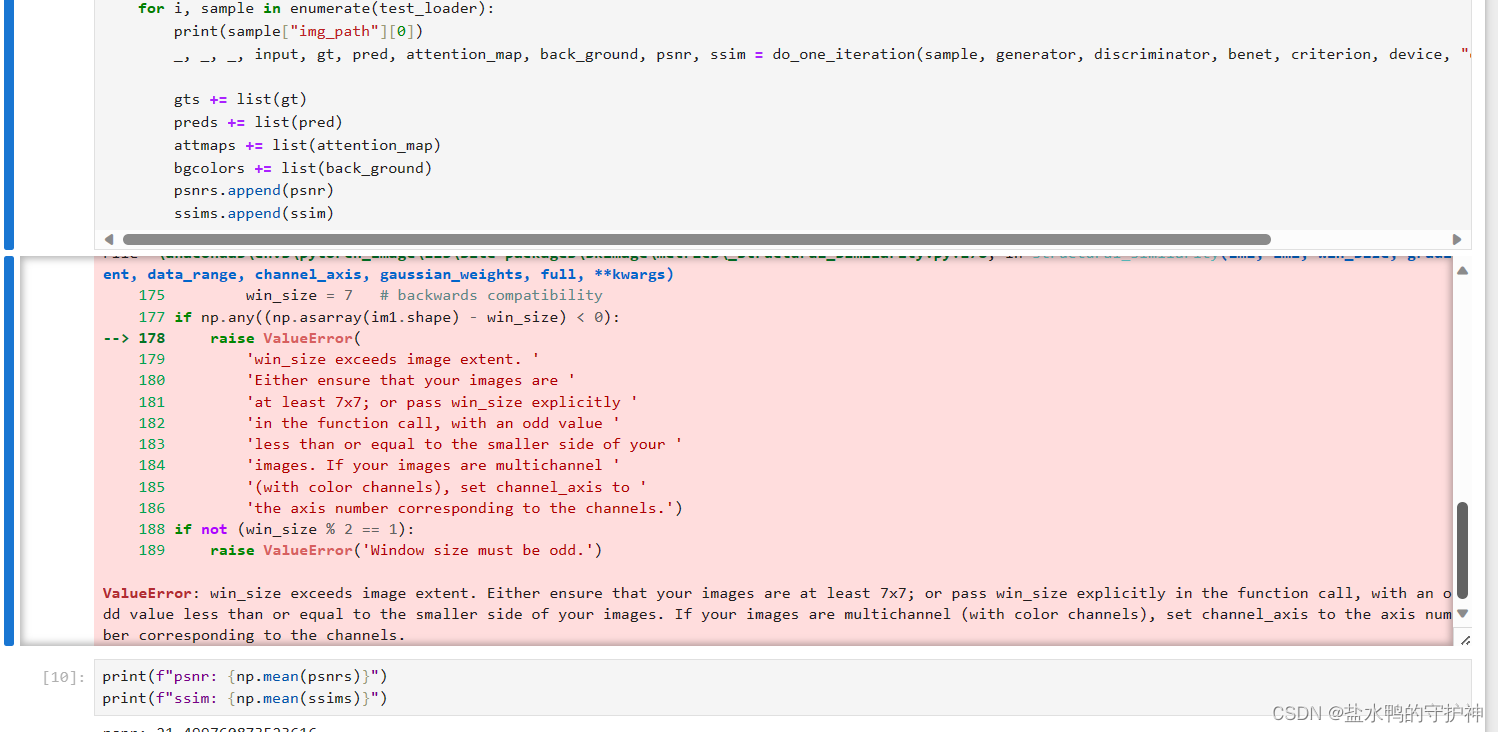
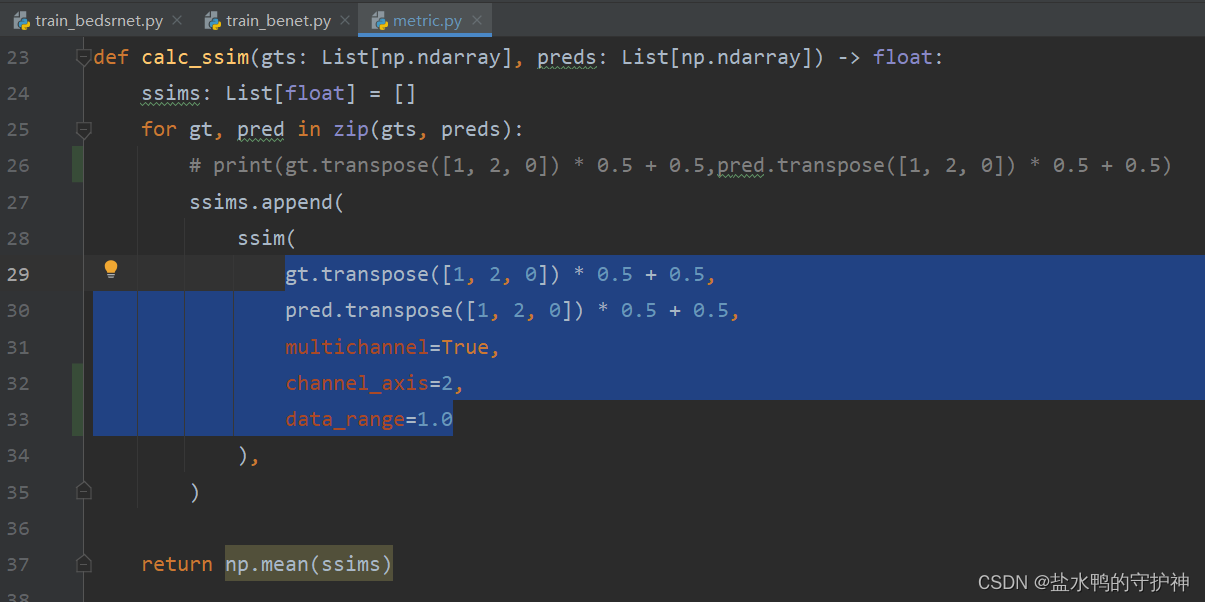
若不使用Google.colab则无需理会下面该错误,直接注释就好
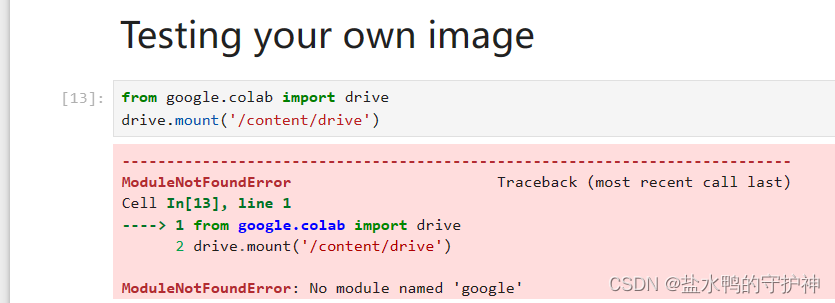
算法的评估指标
将本算法BEDSR-Net与其他的算法,比如Bako、Kligler、Jung、U-Net、ST-CGAN、ST-CGAN-BE一起进行了对比与评估,以突出显示该算法BEDSR-Net的优越性。主要从视觉质量和内容保存两个角度来对该算法进行评估。对于视觉质量,使用了峰值信噪比(PSNR)和结构相似性(SSIM)指数作为指标。而对于内容保存,运用了光学字符识别 (OCR) 技术在恢复的无阴影图像上的性能,一般来说,如果内容恢复得更好,OCR 应该能够识别更多的内容。
视觉质量
定量评估
就是计算每一个方法在去除带有阴影的文档图像的阴影的PSNR和SSIM,这两个计算得到的指标我们可以在demo文件中计算得到,在代码中,就是计算每一个样本的PSNR和SSIM,然后计算得到它们的平均值,然后将这一个平均值作为我们的结果输出。我们可以看到,每一个不同的算法对应的计算得到的PSNR和SSIM如图所示:
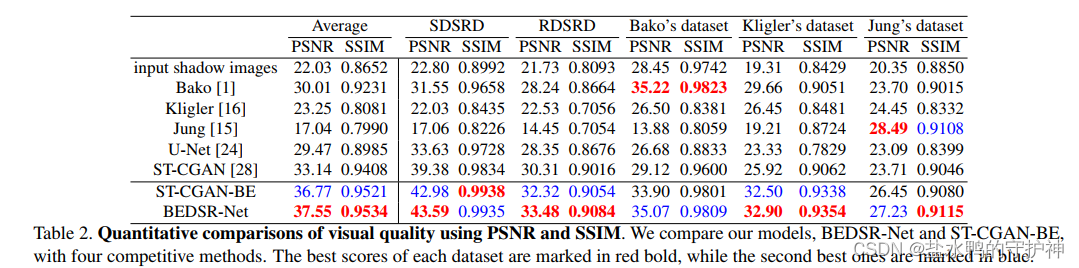
从结果中,我们可以知道,BEDSR-Net在大多数数据集上都优于其他数据集。对于RDSRD、SDSRD和Kligler的数据集,该算法BEDSR-Net都达到了最佳的性能。特别是,本算法模型在Kligler的数据集上明显击败了其他方法,尽管该数据集包含非常暗的阴影和彩色文本。
而对于Bako和Jung的数据集,他们的方法取得了最佳性能,但是,它们在其他数据集上的性能可能很差。例如,Bako等人的方法在Jung的数据集上表现不佳,因为它只能处理光影。另一方面,Jung等人的方法在Bako数据集上的所有比较方法中是最差的,因为它往往会褪色。这些方法源自启发式方法,其数据集通常更符合其启发式方法的特征。
而本算法模型非常有竞争力,在Bako和Jung的数据集上,只有很小的差距。总体而言,该算法BEDSR-Net比以前的方法更稳健,因为它为具有不同特征的图像提供了稳定和良好的结果。
本算法模型是基于U-Net的,而作为一项消融研究,上图报告了在监督设置下在SDSRD上训练的U-Net的性能。我们可以知道BEDSR-Net的性能远远优于U-Net,这表明该算法的性能不仅仅来自 U-Net的架构和训练数据。
作为另一项消融研究,与ST-CGAN相比,ST-CGAN-BE具有更优越的性能,这表明了背景估计模块的重要性。此外,从ST-CGAN-BE到BEDSR-Net的显著性能提升表明,预测的注意力图提供了比ST-CGAN-BE的第一个生成器生成的阴影掩码更有用的信息。最后,BEDSR-Net在参数较少的情况下实现了比ST-CGAN更好的性能,BEDSR-Net为19.8M,ST-CGAN为38.9M。
定性评估
主要是从视觉层面出发,观察每一个算法在进行文档的阴影去除的优异性,主要是对不同数据集中的测试图像,然后利用每一个算法对该图像进行阴影的去除,然后观察该去除阴影后的图像的差异性。在不同的数据集上使用不同的算法进行阴影去除后的图像如下所示:

从结果中,我们可以知道,尽管 Bako 等人的方法在定量评估中表现良好,但它无法恢复带有彩色文本(示例 #7)或大面积阴影(示例 #3)的图像。当有强阴影时,Bako等人的方法和Kligler等人的方法都表现出剩余的阴影边缘(示例 #3 和 #4)。Jung的方法经常会导致结果出现严重的颜色偏移,它的结果通常比地面实况无阴影图像要亮得多,但是颜色被洗掉,对比度降低。
而当有大的黑影时,ST-CGAN会遇到问题(示例#3和#4)。尽管本算法BEDSR-Net模型是从单一主背景色的假设中推导出来的,但它的效用并不像看起来那样受到限制。由于整个文档是作为一个整体的图像捕获的,因此内容和背景之间没有明显的区别。以示例#7为例,这一个可以用两种方式解释:(1)白纸上的十个彩色数字和一个颜色渐变区域,(2)白纸上十个彩色数字,带有颜色渐变。对于第二种解释,存在多种背景颜色,本算法BEDSR-Net仍然获得了良好的结果。
所以我们可以知道,只要文档图像中有一个占主导地位的均匀颜色,该算法BEDSR-Net仍然可以很好地工作,而具有这种特征的文档代表了现实世界的很大一部分。
内容保存
主要是通过报告恢复的无阴影图像的OCR性能来评估如何提高文档的可读性。而进行评估时,使用了188张带有文本的图像。首先,应用开源OCR工具来识别真值无阴影图像的文本和比较方法的结果。然后,通过使用Levenshtein距离(也称为编辑距离)来比较文本字符串来衡量OCR的性能。不同的方法所进行的阴影去除的OCR性能如图所示:

如上图所示,BEDSR-Net的表现要优于其他的算法,这表明它不仅提高了视觉质量,而且通过更好地保留结构和内容提高了文档的可读性。所以我们可以知道,该算法BEDSR-Net不仅仅在进行阴影去除时的效果很好,而且对于去除后的文档的内容的影响都是最低的,即损坏文档的可能性是比较低的。
五、算法的总结
BEDSR-Net是一种用于去除文档图像阴影的深度学习模型。其中它是首个专门用于这一任务的算法模型。该算法的主要特点和步骤可以总结如下:
1. 背景颜色估计(BE-Net):BEDSR-Net使用了一个称为BE-Net的模块,用于估计文档图像的背景颜色,这有助于模型更好地理解文档的特定属性。
2. 注意力图生成:BEDSR-Net能够生成一个称为注意力图的图像,该图像在指示阴影位置时显示出有效的特征。
3. 阴影图像去除(SR-Net):将输入的带有阴影的文档图像和BE-Net输出的背景图像和注意力图作为该子网络的输入,通过生成器G和判别器D之间的博弈来不断进行修正,最后生成器G的输出即为最终的阴影去除后文档图像的结果。
4. 视觉质量提升:BEDSR-Net在视觉质量方面取得了最先进的性能,通过估计的背景颜色和注意力图的帮助,该模型能够有效地去除阴影,提高文档图像的可读性。

















 5815
5815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









