






目录
实验前准备
本实验是在Anaconda下的jupyter notebook上进行的,使用的代码语言为python。在开始实验前,我们首先需要导入所需要的库与包或者模块。本实验是一个线性回归实验,需要处理大量的实验数据,需要处理多维数组对象,以及需要画图进行可视化处理,所以我们需要导入的包为numpy、pandas以及matplotlib.pyplot。
代码实现为:
# 导入所需要的库和包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt一元线性回归模型
实验要求
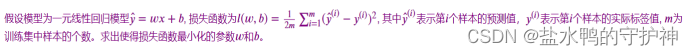
实验数据预处理
我们首先使用pandas读取训练集的数据以及测试集的数据,然后使用numpy将他们转换为矩阵的形式。随后我们可以画出训练集的散点图,初步观察训练集的性质与线性程度。
代码实现为:
# Your code here
#读取数据集
train_frame = pd.read_csv('C:/Users/实验二(线性回归)/train.csv')
test_frame = pd.read_csv('C:/Users/实验二(线性回归)/test.csv')
#转化成numpy矩阵
train = np.array(train_frame)
test = np.array(test_frame)
# 初步观察训练集的数据
train_frame.plot(kind='scatter',x='x',y='y')
plt.title("train_frame scatter")
plt.xlabel("X")
plt.ylabel("Y")
plt.show()散点图如下所示:
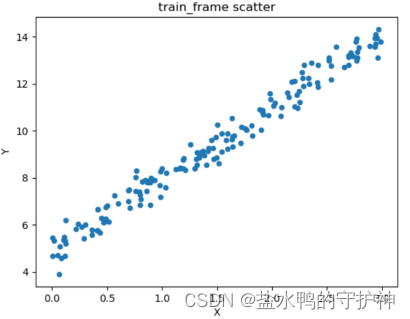
实验结果分析:通过观察训练集的散点图,我们可以发现明显的线性趋势,所以理论上我们是可以使用线性回归拟合得到一条线性方程的。
方法1——最小二乘法
算法原理:
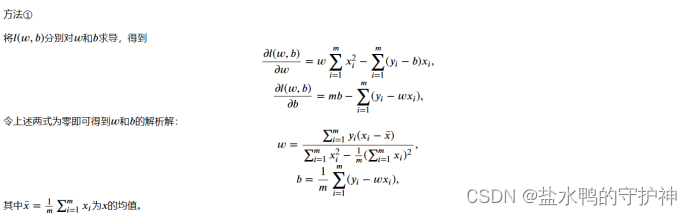
代码实现:
# 方法1
def least_square(data):
# 获取数据中的x与y
X1=data[:,0]
Y1=data[:,1]
# 求出样本的个数
m=len(X1)
# 求出X列数据的均值
X_aver=np.mean(X1)
# 求出w与b
w=(np.sum(Y1*(X1-X_aver)))/(np.sum(X1*X1)-np.power(np.sum(X1),2)/m)
b=np.sum(Y1-w*X1)/m
# 打印结果
print("使用最小二乘法拟合得到的 w=",w,",b=",b)
# 返回结果
return w,b实验测试结果可视化:
# 定义损失函数
def ComputeCost(X,Y,w,b):
m=len(X)
inner=np.power(((w*X+b)-Y),2)
cost=np.sum(inner)/(2*m)
return cost# 处理test的数据,获取数据中的X与Y
X_test=test[:,0]
Y_test=test[:,1]# 方法1结果
# 获取使用方法1计算得到的w与b的值
w1,b1=least_square(train)
# 计算Y的预测值
Y1_pred=w1*X_test+b1
# 计算损失函数
Cost1=ComputeCost(X_test,Y_test,w1,b1)
# 画出测试集的散点图
plt.scatter(X_test,Y_test)
plt.title("test_scatter")
plt.xlabel("X")
plt.ylabel("Y")
# 画出预测的拟合图像
plt.plot(X_test, Y1_pred, color='red')
# 输出损失函数结果
print("使用最小二乘法拟合得到的线性方程的损失函数的值cost=",Cost1)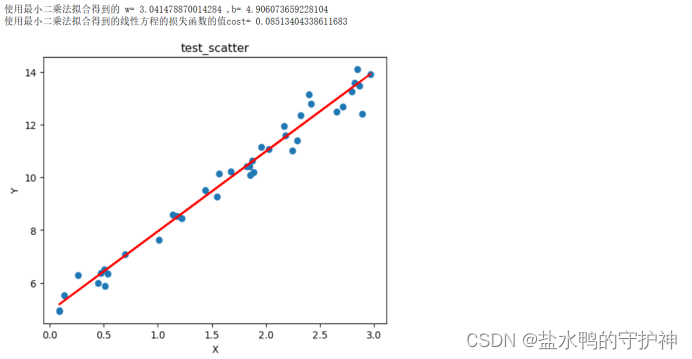
实验结果分析:我们首先定义一个损失函数,用于分析我们线性回归得到的拟合方程的拟合程度。随后我们需要将测试结果进行一个预处理,处理过程与训练集数据的处理过程一致。最后我们将测试集的散点图画出来,并且画出该拟合直线。从实验结果中可以得出,使用最小二乘法拟合得到的w= 3.041478870014284,b= 4.906073659228104,同时使用最小二乘法拟合得到的线性方程的损失函数的值cost= 0.08513404338611683。观察损失函数我们可以得知,使用最小二乘法得到的线性回归方程的拟合程度较高。
方法2——梯度下降法
算法原理:

代码实现:
# 方法2
# 定义梯度下降法的函数
def Gradient_Descent(data):
# 获取数据中的x与y
X2=data[:,0]
Y2=data[:,1]
# 初始化超参数
learning_rate=0.01
max_iterations=100000
threshold=1e-9
batch_size=10
# 初始化w和b为0
w=b=0
# 随机选取小批量数据
batch_indices=np.random.choice(len(X2),size=batch_size,replace=False)
batch_X=X2[batch_indices]
batch_Y=Y2[batch_indices]
# 开始迭代数据
for iteration in range(max_iterations):
# 首先计算Y_hat,即是Y的预测值
Y_hat=w*batch_X+b
# 计算w和b的梯度
dw=np.mean((Y_hat-batch_Y)*batch_X)
db=np.mean(Y_hat-batch_Y)
# 更新w和b的参数
w-=learning_rate*dw
b-=learning_rate*db
# 判断参数更新幅度是否小于阈值
if np.abs(dw)<threshold and np.abs(db)<threshold:
break
# 打印结果数据
print("使用梯度下降法拟合得到的 w=",w,",b=",b)
return w,b实验测试结果可视化:
# 方法2结果
# 获取使用方法2得到的w与b
w2,b2=Gradient_Descent(train)
# 计算Y的预测值
Y2_pred=w2*X_test+b2
# 计算损失函数的值
Cost2=ComputeCost(X_test,Y_test,w2,b2)
# 画出测试集的散点图
plt.scatter(X_test,Y_test)
plt.title("test_scatter")
plt.xlabel("X")
plt.ylabel("Y")
# 画出预测的拟合图像
plt.plot(X_test, Y2_pred, color='red')
# 输出损失函数的值
print("使用梯度下降法拟合得到的线性方程的损失函数的值cost=",Cost2)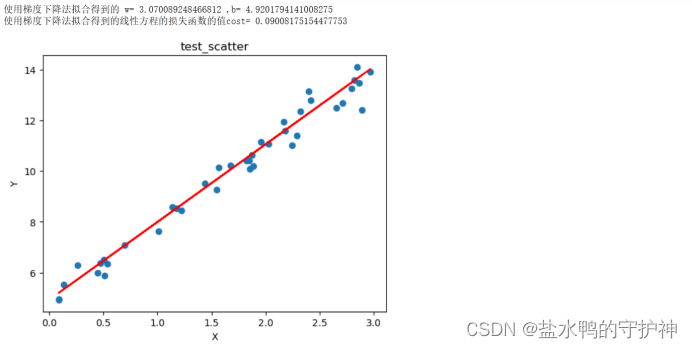
实验结果分析:我们将测试集的散点图画出来,同时打印出使用梯度下降法得到的w和b,并且画出该拟合直线。从实验结果中我们可以得出,使用梯度下降法拟合得到的w= 3.070089248466812,b= 4.9201794141008275,使用梯度下降法拟合得到的线性方程的损失函数的值cost= 0.09008175154477753。观察损失函数的值我们可以得知,使用梯度下降法得到的线性回归方程的拟合程度也是比较高的。
方法3——矩阵求解法
算法原理:

代码实现:
# 方法3
def Matrix(data):
# 创建一个行数与data相同但是列数比data多1列的所有数据均为1的矩阵
temp = np.ones((data.shape[0], data.shape[1] + 1))
# 将data里面的数据复制到temp的第2列到最后之中
temp[:,1:data.shape[1]+1]=data
# 在temp中分离X矩阵
X3=temp[:,:data.shape[1]]
# 在teemp中分离Y矩阵
Y3=temp[:,data.shape[1]:data.shape[1]+1]
# 使用公式B=(XTX)-1XTY来求解矩阵B
B=np.dot(np.linalg.inv(np.dot(X3.T,X3)),np.dot(X3.T,Y3))
# 从矩阵B中取出w与b的值
w=B[1,0]
b=B[0,0]
# 打印结果数据
print("使用矩阵求解法拟合得到的 w=",w,",b=",b)
return w,b实验测试结果可视化:
# 方法3结果
# 获取使用方法3得到的w与b
w3,b3=Matrix(train)
# 计算Y的预测值
Y3_pred=w3*X_test+b3
# 计算损失函数的值
Cost3=ComputeCost(X_test,Y_test,w3,b3)
# 画出测试集的散点图
plt.scatter(X_test,Y_test)
plt.title("test_scatter")
plt.xlabel("X")
plt.ylabel("Y")
# 画出预测的拟合图像
plt.plot(X_test, Y3_pred, color='red')
# 输出损失函数的值
print("使用矩阵求解法拟合得到的线性方程的损失函数的值cost=",Cost3)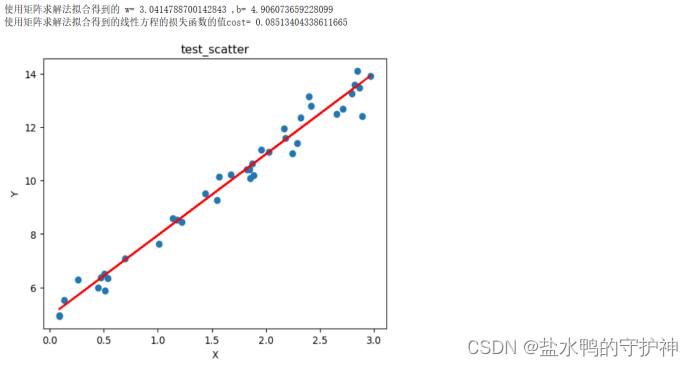
实验结果分析:我们将测试集的散点图画出来,同时打印出使用矩阵求解法得到的w和b,并且画出该拟合直线。从实验结果中我们可以得出,使用矩阵求解法拟合得到的w= 3.0414788700142843 ,b= 4.906073659228099,使用矩阵求解法拟合得到的线性方程的损失函数的值cost= 0.08513404338611665。观察损失函数的值我们可以得知,使用矩阵求解法得到的线性回归方程的拟合程度也是比较高的。
三元线性回归模型
实验要求
![]()
实验数据预处理
我们首先使用pandas读取三元训练集的数据以及测试集的数据,然后使用numpy将他们转换为矩阵的形式。
代码实现为:
# Your code here
# 实验数据预处理
# 首先导入train2以及test2的数据
multi_train_frame=pd.read_csv('C:/Users/实验二(线性回归)/train2.csv')
multi_test_frame=pd.read_csv('C:/Users/实验二(线性回归)/test2.csv')
# 将导入的数据装换为矩阵的形式
multi_train=np.array(multi_train_frame)
multi_test=np.array(multi_test_frame)方法1——矩阵求解法
算法原理:

代码实现:
# 方法1
def Multi_Matrix(data):
# 创建一个行数与data相同但是列数比data多1列的所有数据均为1的矩阵
temp = np.ones((data.shape[0], data.shape[1] + 1))
# 将data里面的数据复制到temp的第2列到最后之中
temp[:,1:data.shape[1]+1]=data
# 在temp中分离X矩阵
X1=temp[:,:data.shape[1]]
# 在teemp中分离Y矩阵
Y1=temp[:,data.shape[1]:data.shape[1]+1]
# 使用公式B=(XTX)-1XTY来求解矩阵B
B=np.dot(np.linalg.inv(np.dot(X1.T,X1)),np.dot(X1.T,Y1))
# 从矩阵B中分别取出w0与w1与w2与w3的值
w0=B[0,0]
w1=B[1,0]
w2=B[2,0]
w3=B[3,0]
# 打印结果数据
print("使用矩阵求解法拟合得到的w0=",w0,",w1=",w1,",w2=",w2,",w3=",w3)
return w0,w1,w2,w3实验测试结果:
# 利用所构建的模型在测试集上进行检验,并且输出均方误差
# 方法1结果
# 获取测试数据集的长度
n=len(multi_Y_test)
# 获取方法1中得到的w0,w1,w2,w3
w0,w1,w2,w3=Multi_Matrix(multi_train)
# 计算得出预测值Y_hat
multi_Y_hat=w0+w1*multi_X1_test+w2*multi_X2_test+w3*multi_X3_test
inner=np.power((multi_Y_hat-multi_Y_test),2)
MSE=np.sum(inner)/n
# 输出结果
print("使用矩阵求解法得到的预测结果的均方误差MSE=",MSE)![]()
实验结果分析:从实验结果可以得知,使用矩阵求解法拟合得到的w0= 5.9425439272594645,w1= 1.007230007858467,w2= 2.003393711530741,w3= 3.010256241220638,使用矩阵求解法得到的预测结果的均方误差= 0.16537691128951676。观察预测结果的均方误差,我们可以得知使用矩阵求解法求得的MSE还是在误差允许范围内的,所以我们使用矩阵求解法所得到的三元线性回归方程的拟合度还是比较高的。
方法2——梯度下降法
算法原理:

代码实现:
# 方法2
def Multi_Gradient_Descent(data):
# 处理数据得到X1,X2,X3,Y
X1=data[:,0]
X2=data[:,1]
X3=data[:,2]
Y=data[:,3]
# 初始化超参数
learning_rate=0.01
max_iterations=100000
threshold=1e-9
batch_size=10
# 初始化w0,w1,w2,w3为0
w0=w1=w2=w3=0
# 随机选取小批量数据
batch_indices=np.random.choice(len(Y),size=batch_size,replace=False)
batch_X1=X1[batch_indices]
batch_X2=X2[batch_indices]
batch_X3=X3[batch_indices]
batch_Y=Y[batch_indices]
#开始迭代
for iteration in range(max_iterations):
# 首先计算Y_hat,即是Y的预测值
Y_hat=w0+w1*batch_X1+w2*batch_X2+w3*batch_X3
# 计算w0,w1,w2,w3的梯度
dw0=np.mean(Y_hat-batch_Y)
dw1=np.mean((Y_hat-batch_Y)*batch_X1)
dw2=np.mean((Y_hat-batch_Y)*batch_X2)
dw3=np.mean((Y_hat-batch_Y)*batch_X3)
# 更新w0,w1,w2,w3的参数
w0-=learning_rate*dw0
w1-=learning_rate*dw1
w2-=learning_rate*dw2
w3-=learning_rate*dw3
# 判断参数更新的幅度是否小于某个阈值
if np.abs(dw0)<threshold and np.abs(dw1)<threshold and np.abs(dw2)<threshold and np.abs(dw3)<threshold:
break
#完成训练
print("使用梯度下降法拟合得到的w0=",w0,",w1=",w1,",w2=",w2,",w3=",w3)
return w0,w1,w2,w3实验测试结果:
# 方法2结果
# 获取测试数据集的长度
n=len(multi_Y_test)
# 获取方法2中得到的w0,w1,w2,w3
w0,w1,w2,w3=Multi_Gradient_Descent(multi_train)
# 计算得出预测值Y_hat
multi_Y_hat=w0+w1*multi_X1_test+w2*multi_X2_test+w3*multi_X3_test
inner=np.power((multi_Y_hat-multi_Y_test),2)
MSE=np.sum(inner)/n
# 输出结果
print("使用梯度下降法得到的预测结果的均方误差MSE=",MSE)![]()
实验结果分析:从实验结果可以得知,使用梯度下降法拟合得到的w0= 6.164131901350548,w1= 0.9654317222590633,w2= 1.985257515334721,w3= 3.002040735120292,使用梯度下降法得到的预测结果的均方误差MSE= 0.1620508400155232。观察预测结果的均方误差,我们可以得知使用梯度下降法求得的MSE还是在误差允许范围内的,所以我们使用梯度下降法所得到的三元线性回归方程的拟合度还是比较高的。
实验总结
线性回归是基于假设目标变量与特征变量之间存在线性关系,然后通过拟合最佳的线性函数来预测目标变量。
线性回归建立了输入特征(自变量)与输出变量(因变量)之间的线性关系,通过拟合最佳的线性模型来预测输出变量的值。
线性回归的主要目标是通过学习样本数据集中的特征和目标变量之间的线性关系,来进行预测和解释。线性回归可以用于预测连续数值型的目标变量,也可以用于分析特征对目标变量的影响程度和方向。线性回归的目标是找到最佳的权重和截距,使得模型的预测值与实际值之间的差异最小化。
在进行线性回归问题的求解过程中,主要有三种算法:
1. 最小二乘法:①最小二乘法是一种通过最小化目标变量与预测值之间的平方差来拟合线性模型的方法。它的核心思想是选择使得预测值与实际观测值之间残差平方和最小的模型参数。②最小二乘法通过求解线性方程组的解析解来确定模型的参数。这意味着可以直接计算出最佳参数值,无需进行迭代优化。③最小二乘法的解析解在数学上是稳定的,可以确保找到全局最优解,而不会陷入局部最优解。④最小二乘法对于存在较大噪声或异常值的数据集比较敏感,可能会导致模型的偏差较大。⑤最小二乘法主要适用于目标变量和特征变量之间存在近似线性关系,数据集规模较小,可以容易地计算矩阵的逆矩阵,数据集不存在较大的噪声或异常值的情况。
2. 梯度下降法:①梯度下降法是一种迭代优化算法,通过不断调整模型参数来最小化损失函数。在线性回归中,梯度下降法通过计算损失函数对模型参数的梯度,并根据梯度的方向和大小更新参数值,直到达到最小化损失的目标。②梯度下降法使用学习率来控制每次迭代中参数的更新步长。学习率需要手动选择,并且影响算法的收敛速度和稳定性。③梯度下降法可能陷入局部最优解而不是全局最优解,特别是在非凸的损失函数中。这可以通过选择合适的学习率和初始化参数来缓解。④梯度下降法的收敛速度取决于学习率的选择和损失函数的形状。较小的学习率可能导致收敛速度较慢,而较大的学习率可能导致无法收敛或发散。⑤梯度下降法相对于最小二乘法对异常值具有一定的鲁棒性,但仍然可能受到大的异常值的影响。⑥梯度下降法可以主要分为批量梯度下降法、随机梯度下降法和mini-batch梯度下降法,这三种梯度下降法的选择取决于数据集的规模、计算资源的限制以及优化效果的要求。⑦梯度下降法主要适用于目标变量和特征变量之间存在近似线性关系,数据集规模较大,无法直接计算矩阵的逆矩阵,数据集中存在噪声或异常值等情况。
3. 矩阵求解法:①矩阵求解法是一种直接求解线性回归模型参数的方法,通过对线性方程组应用线性代数的知识,找到使损失函数最小化的模型参数值。②矩阵求解法通过求解线性方程组的闭式解,直接得到参数的解析解。这使得矩阵求解法相对于迭代优化算法(如梯度下降法)更快速。③矩阵求解法的计算复杂度取决于矩阵的大小和矩阵求逆的计算复杂度,通常为O(n^3)。对于大规模数据集,计算矩阵逆可能会变得耗时且内存占用较高。④矩阵求解法对于存在异常值的数据集比较敏感,因为异常值可能会导致矩阵的条件数增加,使得求解过程不稳定。⑤在应用矩阵求解法之前,通常需要对特征进行缩放,以防止不同特征之间的量级差异对模型参数估计的影响。⑥矩阵求解法主要适用于目标变量和特征变量之间存在精确的线性关系,数据集规模适中,可以直接计算矩阵的逆矩阵,数据集中不存在噪声或异常值,或者可以通过数据预处理进行处理等情况。
线性回归的三种算法对比:
1. 梯度下降法是一种迭代算法,需要选择学习率,可能需要迭代很多轮次,特征维度比较大时也运行正常。
2. 最小二乘法与矩阵求解法都是一种解析解方法,可以直接得到最佳参数,不需要选择学习率,不需要迭代,需要矩阵计算,当维度过大时计算耗时。
3. 梯度下降法适用于各种规模的数据集和复杂的模型,只需要在每次迭代中计算样本的梯度,占用的内存较少,迭代过程可以减少异常值对参数更新的影响。而最小二乘法以及矩阵求解法可以找到使损失函数最小化的最优参数值,适用于较小规模的问题。
4. 梯度下降法对数据预处理和特征缩放较为敏感,而最小二乘法以及矩阵求解法对数据的缩放不太敏感。

















 932
932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









