






Java初步学习
Java源文件的大体结构
package语句
//0个或一个,必须放在文件开始
import | import static 语句
//0个或多个,必须放在所有类定义之前,package语句之后
public class Definition | interfaceDefinition | enumDefinition
//0个或一个public类、接口或枚举定义
class Definition | interfaceDefinition | enumDefinition
//0个或多个普通类、接口或枚举定义
第二章 理解面向对象
面向对象
在目前的软件开发领域有两种主流的开发方法:结构化开发方法和面向对象开发方法。早期的编程语言如:C、Basic、Pascal等都是结构化编程语言;随着软件开发技术的逐渐发展,人们发现面向对象可以提供更好的可重用性、可拓展性和可维护性,于是催生了大量的面向对象的编程语言,如C++、Java、C#和Ruby等。
结构化程序设计简介
结构化设计方法主张按功能来分析系统需求,其主要原则可以概括为自顶向下、逐步求精、模块化等。框架结构化程序设计首先采用结构化分析方法对系统进行需求分析,然后使用结构化设计方法对系统进行概要设计、详细设计、最后采用结构化编程方法来实现系统。这种方式可以较好的保证软件系统的开发进度和质量。
因为结构化设计方法主张按功能把软件系统逐步细分,因此这种方法也被称为面向功能的程序设计方法;结构化程序设计的每个功能对负责对数据进行一次v护理,每个功能都接受一些数据处理完后输出一些数据,这种处理方式也称为面向数据流的处理方式。
结构化程序设计里最小的程序单元是函数,每个函数都负责完成一个功能,用以接收一些输入数据,函数对这些输入数据进行处理,处理完结束后输出一些数据。整个软件系统由一个个函数组成,其中作为程序入口的函数被称为主函数,主函数依次调用其他普通函数,普通函数之间依次调用,从而完成整个软件系统的功能。
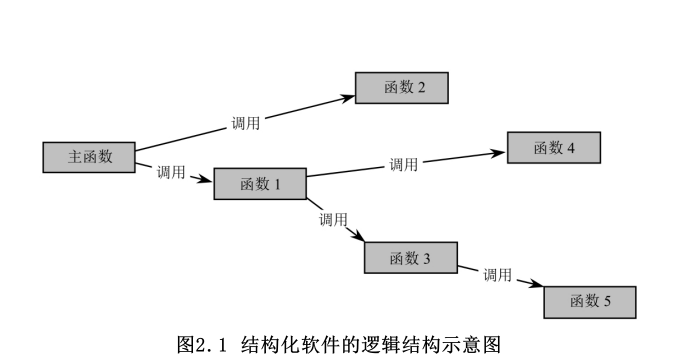
每个函数都是具有输入、输出的子系统,函数的输入数据包括函数形参、全局变量和常量等,函数的输出数据包括函数返回值以及传出参数等。结构化程序的设计方式有如下两个局限性:
- 设计不够直观,与人类的习惯思维不一致,采用结构化程序分析、设计时,开发者需要将客观世界模型分解成一个个功能,每个功能用已完成一定的数据处理。
- 适应性差,可拓展性不强。由于结构i化设计采用自顶向下的设计方式,所以当用户的需求发生改变,或需要修改现有的实现方式时,都需要自顶向下地修改模块结构,这种方式的维护成本相当高。
程序的三种基本结构
在过去的日子里,很多语言都提供了人GOTO语句,GOTO语句非常灵活,可以让程序的控制流程任意流转——如果大量使用GOTO语句,程序完全不需要使用循环。但GOTO语句实在是太随意了,如果程序随意使用GOTO语句,将会让程序变得难以理解且容易出错。在实际开发的过程中,更注重代码的可读性和可修改性,因此GOTO语句逐渐被抛弃了。
Java语言拒绝使用GOTO语句,但它将goto作为保留字,意思是 目前Java版本还未使用GOTO语句,但也许在未来的日子里,当Java 不得不使用GOTO语句时,Java还是可能使用GOTO语句的。
- 顺序结构:程序按照代码编写的顺序依次执行,每个语句都会被执行一次,直到程序结束。
- 选择结构:根据特定条件,程序会有不同的执行路径。通常使用if/else语句来实现,if/else语句会根据条件判断执行哪一段代码。
- 循环结构:程序可以重复执行一段代码,直到满足特定条件才停止。通常使用while和for循环来实现,循环结构可以让程序执行重复的任务,节省时间和工作量。
面向对象程序设计简介
面向对象是一种更优秀的程序设计方法,它的基本思想是使用类、对象、继承、封装、消息等基本概念进行程序设计。它从现实世界中客观存在的事物(即对象)出发来构建软件系统,并在系统构造中尽可能运用人类的自然思维方式,强调直接以现实世界中的事物(即对象)为中心来思考,认识问题,并根据这些事物的本质特点,把它们抽象的表示为系统中的类,作为系统的基本构成单元,这使得软件系统的组件可以直接映像到客观世界,并保持客观世界中事物及其相互关系的本来面貌。
采用面向对象方式开发的软件系统,其最小的程序单元时是类,这些类可以生成系统中的多个对象,而这些对象则直接映像成客观世界的各种事物。
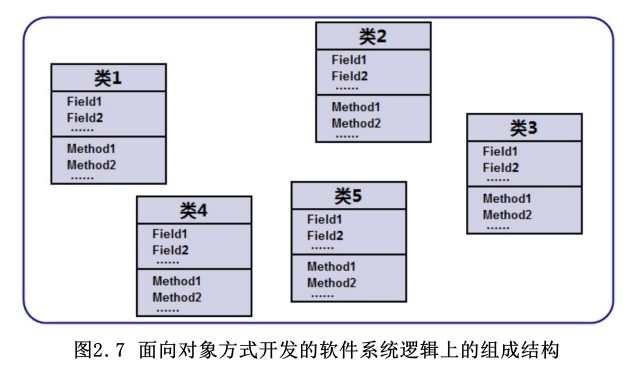
面向对象的软件系统由多个类组成,类代表了客观世界中具有某种特征的一类事物,这类事物往往有一些内部状态数据,比如人有身高、体重、年龄、爱好等各种状态数据。
面向对象的语言不仅使用类来封装一类事物的内部状态数据,这种状态数据就对应成员变量(Field);而且类会提供操作这些状态数据的方法,将会为这类事物的行为特征提供相应的实现,这种实现也是方法。
成员变量 + 方法 = 类定义
面向对象比面向过程对编程粒度要大:面向对象的程序单位是类;而面向过程的程序单位是函数(相当于方法),因此面向对象比面向过程更简单、易用。
在面向过程的程序世界里,一切以函数为中心,函数最大,因此 这件事情会用如下语句来表达:
吃(猪八戒,西瓜);
在面向对象的程序世界里,一切以对象为中心,对象最大,因此 这件事情会用如下语句来表达:
猪八戒.吃(西瓜);
对比两条语句不难发现,面向对象的语句更接近自然语言的语 法:主语、谓语、宾语一目了然,十分直观,因此程序员更易理解。
面向对象的基本特征
面向对象具有三个基本特征:封装(Encapsulation)、继承(Inheritance)和多态(Polymorphism)以及令一特征:抽象。
- 封装(Encapsulation):指将数据和方法封装在类中,对外部隐藏实现细节,只暴露必要的接口。这样可以保证数据的安全性,同时也方便代码的复用和维护。
- 继承(Inheritance):指子类可以继承父类的属性和方法,并可以在此基础上添加自己的属性和方法,实现代码的重用和扩展。
- 多态(Polymorphism):指同一种行为具有多种不同的表现形式。比如,在面向对象的语言中,多态可以通过重载(Overloading)和重写(Overriding)实现。
- 抽象(Abstraction):指将复杂的现实世界问题简化为代码中的抽象类或接口,只关注问题的本质和关键点,忽略不必要的细节。通过抽象可以提高代码的可读性和可维护性。
(虽然抽象是面向对象的重要部分,但它不是面向对象的特征之 一,因为所有的编程语言都需要抽象。当开发者进行抽象时应该考 虑哪些特征是软件系统所需要的,那么这些特征就应该使用程序记录并表现出来。因此,需要抽象哪些特征没有必然的规定,而是取决于软件系统的功能需求。)
这些特征使得面向对象编程具有灵活性、可扩展性、可维护性和可重用性等优点,是现代软件开发中广泛应用的编程范式之一。
面向对象还支持如下几个功能。
- 对象是面向对象方法中最基本的概念,它的基本特点有:标识 唯一性、分类性、多态性、封装性、模块独立性好。
- 类是具有共同属性、共同方法的一类事物。类是对象的抽象; 对象则是类的实例。而类是整个软件系统最小的程序单元,类 的封装性将各种信息细节隐藏起来,并通过公用方法来暴露该 类对外所提供的功能,从而提高了类的内聚性,降低了对象之间的耦合性。
- 对象间的这种相互合作需要一个机制协助进行,这样的机制称 为“消息”。消息是一个实例与另一个实例之间相互通信的机制。
- 在面向对象方法中,类之间共享属性和操作的机制称为继承。 继承具有传递性。继承可分为单继承(一个继承只允许有一个 直接父类,即类等级为树形结构)与多继承(一个类允许有多个直接父类)。由于多继承可能引起继承结构的混乱,而且会大大降低程序的可理解性,所以Java不支持多继承。
在编程语言领域,还有一个“基于对象”的概念,这两个概念极 易混淆。通常而言,“基于对象”也使用了对象,但是无法利用现有的对象模板产生新的对象类型,继而产生新的对象,也就是说,“基 于对象”没有继承的特点;而“多态”则更需要继承,没有了继承的 概念也就无从谈论“多态”。面向对象方法的三大基本特征(封装、 继承、多态)缺一不可。例如,JavaScript语言就是基于对象的,它使用一些封装好的对象,调用对象的方法,设置对象的属性;但是它们无法让开发者派生新的类,开发者只能使用现有对象的方法和属性。
判断一门语言是否是面向对象的,通常可以使用继承和多态来加以判断。“面向对象”和“基于对象”都实现了“封装”的概念,但是面向对象实现了“继承和多态”,而“基于对象”没有实现这些。
面向对象编程的程序员按照分工分为“类库的创建者”和“类库的使用者”。使用类库的人并不都是具备了面向对象思想的人,通常知道如何继承和派生新对象就可以使用类库了,然而他们的思维并没有真正地转过来,使用类库只是在形式上是面向对象的,而实质上只是库函数的一种扩展
Java的面向对象特征
Java是纯村的面向对象编程语言,完全支持封装、继承和多态三大基本特征,Java程序的组成单位就是类,不管多大的Java程序,都是由一个个类组成的。
一切都是对象
在Java语言中,除了8个基本数据类型值以外,一切都是对象,而对象就是面向对象程序设计的中心。对象是人们要进行研究的任何事物,它不仅能表示具体的事物,还能表示抽象的规则、计划或事件。
对象具有状态,一个对象用数据值来描述它的状态。Java通过为对象定义成员变量来描述对象的状态,对象的操作也被称为对象的行为,Java通过为对象定义方法来描述对象的行为。
对象实现了数据和操作的结合。
类和对象
具有相同或相似性质的一组对象的抽象就是类,类是对一类事物的描述,是抽象的、概念上的定义;对象是实际存在的该类事物的个体,因而也称为实例(instance)
对象的抽象化是类,类的具体化就是对象,也可以说类的实例是对象。类用来描述一系列对象,类概述每个对象应包括的数据,类概括每个对象的行为特征,类是规定了某类对象所具有的数据和行为特征。
Java语言使用class关键字定义类,定义类时可使用成员变量来描述该类对象的数据,可使用方法来描述该类对象的行为特征。
在客观世界中有若干类,这些类之间有一定的结构关系。通常有如下两种主要的结构关系:
- 一般->特殊关系:这种关系就是典型的继承关系,Java语言使用extends关键字来表示这种继承关系,Java的子类是一种特殊的父类。因此,这种关系其实是一种"is a"关系。
- 整体->部分结构关系:也被称为组装结构,这是典型的组合关系,Java语言通过在一个类里保存另一个对象的引用来实现这种组合关系。因此,这种关系其实是一种"has a"关系。
每个类都可以通过new关键字来创建多个对象(不完全对,因为有抽象类,抽象类无法创建对象,无法实例化),多个对象的成员变量值可以不同——不同对象的数据存在差异。
第三章 数据类型和运算符
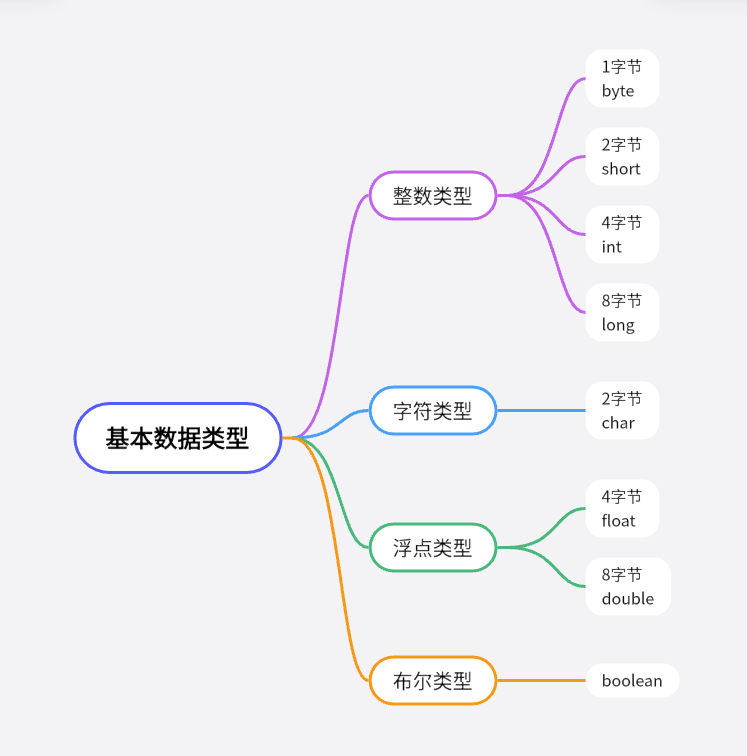
基本数据类型
java语言中的基本数据类型可以分为boolean类型和数值类型。
数值类型又可以分为整数类型和浮点类型,整数类型里的字符类型也可以被单独对待。
需要注意的是字符串不是基本数据类型,字符串是一个类,也就是一个引用数据类型。
boolean类型
boolean类型的值只能为true或false,不能用0或!0代替,其他基本数据类型的值也不会被转换成boolean类型。
字符串类型的rue或false不会被转换成boolean类型,但boolean类型的值在和字符串做连接运算的时候会被转换成字符串形式。
自动类型转换
与c语言的自动类型转换差不多,从精度低的向精度高的可以进行自动转换,倒过来就必须使用强制类型转换。
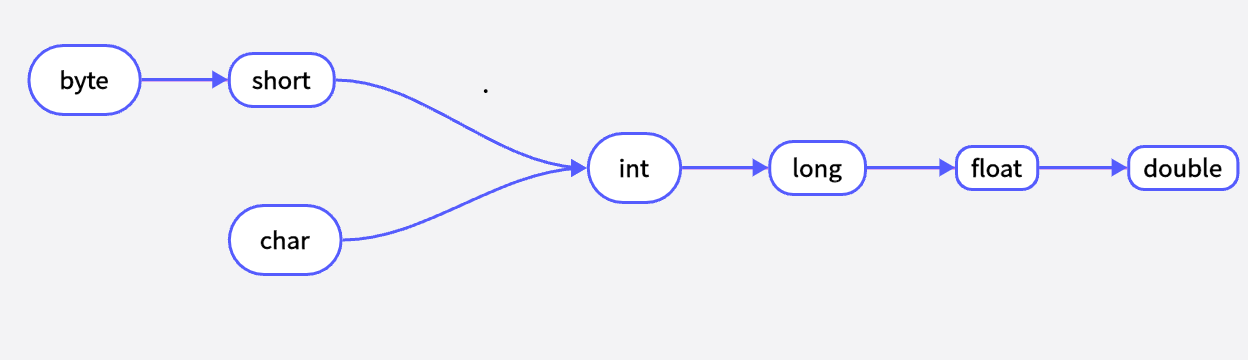
而且在java语言中,把任何基本类型的值和字符串进行连接运算时,基本类型的值将自动转换为字符串类型,由此,如果希望把基本类型的值转换为字符串时,可以把字符串的值和一个空字串进行连接。
强制类型转换
如果希望把上图中箭头后的数据类型转换为箭头前的数据类型,就必须使用强制类型转换,因为箭头后的数据类型范围更大更精确,所以如果希望将范围更大的向前转换可能会造成数据丢失,所以必须使用强制数据转换,强制类型转换的语法格式是:(targetType)value,强制类型转换的运算符是圆括号。
直接量
直接量是指程序中通过源代码直接给出的值,
int a = 5;
//这里的5就是直接量
直接量的类型
能指定直接量的通常只有三种类型:基本类型,字符串类型,null类型。
null是一种特殊类型,它只有一个值null,而且这个直接量可以赋给任何引用类型的变量没用一表示这个引用类型变量中保存的地址为空,即还未指向任何有效对象。
运算符
算术运算符
与c语言不一样的是
+在使用的时候还可以作字符串的连接运算。
逻辑运算符
有几个没见过:
&:不短路于,与&&作用相同,但不会短路;
|:不短路或,与||作用相同,但不会短路;
^:异或,当两个操作数不同时才返回true,如果两个操作数相同则返回false。
第四章 流程控制与数组
控制循环结构
在java语言中break,continue的作用和c语言中一样,但多了一个使用方式
可以使用标签来标识循环体,在使用break或continue的时候就可以直接指定作用循环,包括外层循环。
outer://使用冒号来标识,在java语言中标签只有放在循环前面时才有作用。
for (int i = 0; i < n; i++) {
;
break outer;
continue outer;
;
}
数组
定义
有以下两种定义方式,但建议使用第一种定义方式,更加清晰直观,具有良好可读性。
第二种定义方式已经逐渐被淘汰,C#就已经取消了这种定义方式。
type[] arrayName;
type arrayName[];
初始化
静态初始化
arrayName = new type[] { element1, element2, element3 ...};
//
int[] nums;
nums = new int[] {-1,0,3,5,9,12};//花括号中的数据必须是与type相同的数据类型或者是其所包含的子类。
//也可以写成这种简化模式
int[] nums = {-1,0,3,5,9,12};
动态初始化
动态初始化只指定数组的长度,由系统为每个数组元素指定初始值。
arrayName = new type[length];
//
int nums = new int[10];
执行动态初始化时,程序员只需要指定数组的长度,系统会为数组赋初值。
整数类型(byte short int long): 0;
浮点类型(float double): 0.0;
字符型(char): ‘\u0000’;
布尔类型(boolean): false;
引用类型(类,接口和数组):数组元素的值是null;
foreach循环
从java5之后,Java提供了这种循环来遍历数组和集合。
使用foreach循环的时候,无需获得数组和集合的长度,无需根据索引来访问数组元素和集合元素,foreach会自动遍历数组和集合的每个元素。
int[] nums = {0,1,2,3,4,5,6,7,8,9};
for (int num: nums) {
System.out.print(num);
System.out.print(" ");
}
String[] str = {"zhang","guo"};
for (String ch: str) {
System.out.print(ch);
System.out.print(" ");
}
需要注意的是如果需要对数组内的数据进行赋值等操作的时候,不要使用foreach循环,因为foreach循环中的输出的数据只是形参而已,如果对其做操作不仅达不到效果还可能会报错产生错误。
操作数组的工具类:Arrays
第五章 面向对象上
类和对象
定义类
面向对象的程序设计过程中有两个重要概念:类(class)和对象(object,也被称为实例, instance)。
类是对某一批对象的抽象,可以把类理解成某种概念;
对象才是一个具体存在的实体。
ps:日常中说的人就是人类的实例,而不是人类
[修饰符] class 类名 {
零个到多个构造器定义
零个到多个成员变量
零个到多个方法
}
修饰符可以是 public、final、abstracrt,或者完全省略这三个修饰符,类名只是一个合法的标识符就好
一个类可以包含最常见的三个成员:
构造器、成员变量和方法。
三种成员都可以定义0个或多个,如果三种成员都只定义零个,就是定义了一个空类,这没有太大实际的意义。
类里各成员之间可以互相调用,定义先后顺序没有任何影响,但static修饰的成员不能访问没有static修饰的成员
成员变量用于定义该类或该类的实例所包含的状态数据,方法则用于定义该类或该类的实例的行为特征或者功能实现。构造器用于构造该类的实例,Java语言通过new关键字来调用构造器,从而返回该类的实例。
构造器是一个类创建对象的根本途径,如果一个类没有构造器,这个类就无法创造实例,Java语言会在没有显式构造器的情况下为该类提供一个默认的构造器。
static
static是一个特殊的关键字,它可以用于修饰方法,成员变量等成员。static修饰的成员表明它属于这个类本身,而不属于该类的单个实例,因而通常把static修饰的成员变量和方法也成为类变量、类方法。不使用static修饰的普通方法、成员变量则属于该类的单个实例,而不属于该类。因而通常把不适用static修饰的成员变量和方法也称为实例变量、实例方法。
static的英文直译是静态的意思,所以也将其修饰的成员变量和方法称为静态变量和静态方法,静态方法和静态变量不能访问非静态方法和非静态变量。
定义成员变量
[修饰符] 类型 成员变量名 [=默认值];
-
修饰符:修饰符可以省略,也可以是public、protected、private、static、final,其中 public、protected、private三个最多只能出现一个,可以与static、final组合起来修饰成员变量。
-
类型:类型可以是Java语言允许的任何数据类型,包括基本数据类型和引用数据类型。
-
成员变量名:合法的标识符。
-
默认值:指定初值。
定义方法
[修饰符] 方法返回值类型 方法名(形参列表){
//由零条到多条可执行性的语句组成的方法体
}
- 修饰符:修饰符可以省略,也可以是public、protected、private、static、final、abstract,其中public、protected、private只能出现其一;abstract和final之能出现其一,它们可以和static组合起来修饰方法。
- 方法返回值类型:返回值类型可以是Java语言允许的任何数据类型,如果声明了返回值类型,则方法体内必须有一个有效的return语句们该语句返回一个变量或一个表达式,如果一个方法没有返回值,必须用void来声明其没有返回值。
- 方法名:合法的标识符。
- 形参列表:定义该方法可以接受的参数,形参列表由零组到多组“参数类型 形参”组成,多组参数之间以英文逗号隔开,形参类型和形参名之间以英文空格隔开,一旦在定义方法时指定了形参列表,则调用方法的时候必须传入对应的参数值。
定义构造器
构造器是一个特殊的方法,定义构造器的语法格式和定义方法的语法格式很像
[修饰符] 构造器名[形参列表]{
//由零条到多条可执行性语句构成的构造器执行体
}
- 修饰符:修饰符可以省略,也可以是public、protected、private之一。
- 构造器名:构造器名必须和类名相同
- 形参列表:和定义方法形参列表的格式完全相同
**构造器不能定义返回值类型,也不能使用void声明构造器没有返回值。**如果为构造器定义了返回值类型,或使用void声明,系统会将这个所谓的构造器当作方法处理。
Java的类大致有几个作用:
- 定义变量
- 创建对象
- 调用类的类方法或访问类的类变量
对象的产生和使用
static修饰的方法和成员变量,即可通过类来调用,也可通过实例来调用;没有使用static修饰的普通方法和成员变量,只可通过实例来调用。
对象,引用和指针
对象的this引用
this关键字总是指向调用该方法的对象,根据this出现位置的不同,this作为对象的默认引用有两种情形。
- 构造器中引用该构造器正在初始化的对象
- 在方法中调用该方法的对象
Java允许对象的一个成员直接调用另一个成员,可以省略this前缀。
对于static修饰的方法而言,可以使用类来直接调用该方法,如果在static修饰的方法中使用this关键字,那么它将无法指向合适的对象,所以static修饰的方法中不能使用this引用,也就是说static修饰的方法不能访问不使用static修饰的普通成员,所以,静态成员不能直接访问非静态成员
方法详解
在Java语言中方法不能独立存在,方法必须属于类或对象。
- 方法不能独立定义,方法只能在类体里定义
- 从逻辑意义上来看,方法要么署以该类本身,要么属于该类的一个对象
- 永远不能独立执行方法,执行方法必须使用类或对象作为调用者
方法重载
方法重载是指在一个类中两个方法:
- 两同:同一个类中方法名相同
- 一不同:参数列表不同
系统会根据调用方法时传入的参数来判断执行哪个方法。
成员变量和局部变量
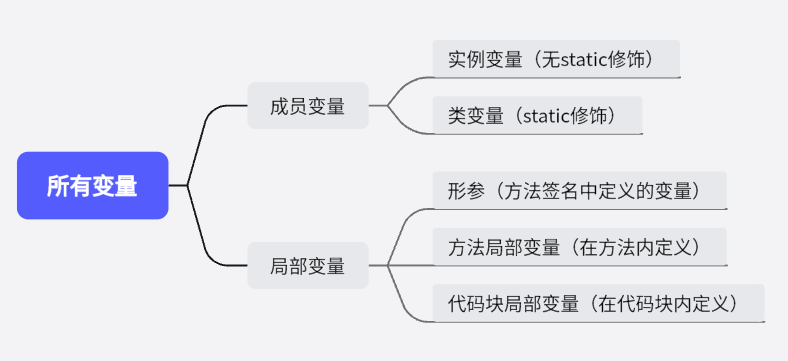
根据定义变量的位置的不同,可以将变量分为两大类:成员变量和局部变量。
成员变量指的是在类里定义的变量
局部变量指的是在方法里定义的变量
成员变量
存在范围
成员变量被分为类变量和实例变量两种,类变量从该类的准备阶段开始存在,直到系统完全销毁这个类,类变量的作用域与这个类的生存范围相同;实例变量则从该类的实例被创建开始存在,直到系统完全销毁这个实例,实例变量的作用域与对应实例的生存范围相同。
访问方式
类变量可以直接用类来访问,也可以用类的实例来访问,不管哪种访问方式其实访问的都是同一个变量,从根本上类变量是属于类本身的,所以应该尽量只使用类来访问,可以提高可读性。
实例变量用类的实例访问,每个实例都拥有自己的实例变量
成员变量是不需要显式初始化的,在定义一个类和实例的时候会对应生成并初始化其类变量和实例变量
局部变量
根据定义形式的不同可以分为以下三种:
- 形参:在定义方法签名时定义的变量,形参的作用域在整个方法内有效。
- 方法局部变量:在方法体内定义的局部变量,它的作用域是从定义该变量的地方生效,到该方法结束时失效。
- 代码块局部变量:在代码块中定义的局部变量,这个局部变量的作用域从定义该变量的地方生效,到该代码结束时失效。
与成员变量不同的是,局部变量除形参之外,都必须显式初始化。
当通过类或对象调用某个方法时,系统会在该方法栈区内为所有的形参分配内存空间,并将实参的值赋给相应的形参,这就完成了形参的初始化。
变量重名
在同一个类里,成员变量的作用范围是整个类内有效,一个类里不能定义两个同名的成员变量,即使一个是类变量,一个是实例变量也不行;一个方法里不能定义两个同名的方法局部变量,方法局部变量与形参也不能同名;同一个方法中不同代码块内的代码块局部变量可以同名;如果先定义代码块局部变量,后定义方法局部变量,前面定义的代码块局部变量与后面定义的方法局部变量也可以同名。
Java允许局部变量和成员变量同名,如果方法里的局部变量和成员变量同名,局部变量会覆盖成员变量,如果需要在这个方法里引用被覆盖的成员变量,可以使用this(对于实例变量)或类名(对于类变量)作为调用者来限定访问成员变量。
隐藏和封装
封装
封装是面向对象的三大特征之一,它指的是将对象的状态信息隐藏在对象内部,不允许外部程序直接访问对象内部信息,而是通过该类所提供的方法来实现对内部信息的操作和访问。对一个类或对象实现良好的封装,可以实现以下目的:
- 隐藏类的实现细节
- 让使用者只能通过事先预定的方法来访问数据,从而可以在该方法里加入控制逻辑,限制对成员变量的不合理访问
- 可进行数据检查,从而有利于保证对象信息的完整性
- 便于修改,提高代码的可维护性
为了实现良好的封装,需要从两个方面考虑
- 将对象的成员变量和实现细节隐藏起来,不允许外部直接访问
- 把方法暴露出来,让方法来控制对这些成员变量进行安全的访问和操作
封装实际上具有的含义是:把该隐藏的隐藏起来,把该暴露的暴露出来。
访问控制符
java提供了三个访问控制符:private,protect,public,还有一个不加任何访问控制符的访问控制级别,提供了4个访问控制级别,由小到大如图所示:
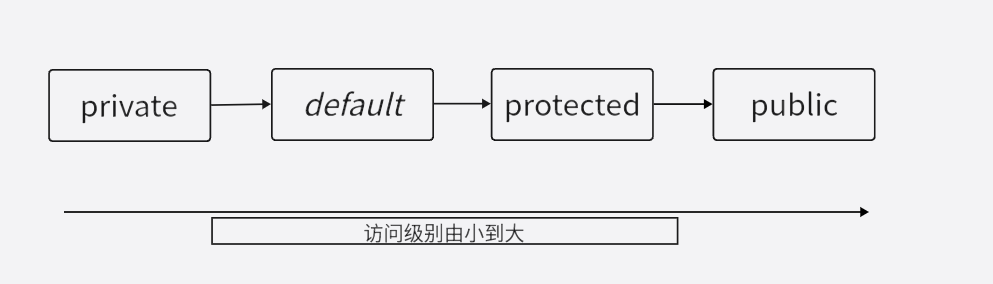
default并没有对应的访问控制符,当不使用任何访问控制符来修饰类或类成员时,系统默认使用该访问控制级别。
private(当前类访问权限)
如果一个类里的一个成员(包括成员变量、方法和构造器等)使用private访问控制符来修饰,则**这个成员只能在当前类的内部被访问。**很显然,这个访问控制符用于修饰成员变量最合适,使用它修饰成员变量就可以把成员变量隐藏在该类的内部。
default(包访问权限)
如果一个类里的一个成员(包括成员变量、方法和构造器等)或者一个外部类不使用任何访问控制符来修饰,就称它是包访问权限的,default访问控制的成员或外部类可以被相同包下的的其它类访问
protected(子类访问权限)
如果一个类里的一个成员(包括成员变量、方法和构造器等)使用protected控制符来修饰,那么这个成员既可以被同一个包中的其它类访问,也可以被不同包中的子类访问。在通常情况下,如果使用protected来修饰一个方法,通常是希望其子类来重写这个方法。
public(公共访问权限)
这是一个最宽松的访问控制级别,如果一个成员(包括成员变量、方法和构造器等)或者一个外部类使用public访问修饰符修饰,那么这个成员或外部类就可以被所有类访问,不管访问类和被访问类是否处于同一个包中,是否具有父子继承关系。

通过上面关于访问控制符的介绍不难发现,访问控制符用于控制一个类的成员是否可以被其他类访问,对于局部变量而言,其作用域就是它所在的方法,不可能被其它类访问,所以不能使用访问控制符来修饰。
对于外部类而言,它也可以使用访问控制符修饰,但外部类只有两种访问控制级别,public和默认,这是因为外部类不存在任何类的内部,所以private和protected对它毫无意义。
如果一个java源文件里定义了一个public修饰的类,那这个源文件的文件名必须与public修饰的类的名相同。
setter和getter
如果一个类里包含了一个名为abc的实例变量,择其对应的setter和getter方法名应为setAbc()和getAbc()(即将原实例变量名的首字母大写,并在前面分别增加set和get动词,就变成setter和gettter方法名),如果一个Java类的每个实例变量都被使用private修饰,并为每个实例变量都提供了public修饰setter和getter方法,那么这个类就是一个符合JavaBean规范的类,因此,JavaBean总是一个封装良好的类,setter和getter方法和起来变成属性,如果只有getter方法,则是只读属性。
包
包是Java提供用来解决类的命名冲突,类文件管理的多层命名空间的机制。
package
Java允许将一组功能相关的类放在同一个package下,从而组成逻辑上的类库单元。如果希望把一个类放在指定的包结构下,应该在Java源程序的第一个非注释行放置如下格式的代码:
包
package packageName;
一旦在Java源文件中使用了这个package语句,就意味着源文件里定义的所有类都属于这个包。位于包中的每个类的完整类名都应该是报名和类名的组合,如果其他人需要使用该包下的类,也应该用包名加类名的组合。
一个源文件只能指定一个包,只能包含一条package语句。
可以在包的下面定义一个子包,如下:
子包
//在一个源文件中定义一个名为lee的包
package lee;
//在零一个源文件中定义一个lee的子包
package lee.sub;
//在这个子包中定义一个类
public class Apple{}
import
一个包内的类可以随意互相调用,不用加包前缀,但不同的包中的类就必须加上包前缀才能调用,为了简化编程,Java引入了import关键字
import关键字可以向某个Java文件中导入指定包层次下每个类或全部类,import语句应该出现在package语句之后,类定义之前。
一个Java源文件中只能包含一个package语句,但可以包含多个import语句,多个import语句用于导入多个包层次下的类
导入单个类
import package.subpackage...ClassName;
例如:
import lee.sub.Apple;
导入全部类
import package.subpackage...*;
上面语句中的 * 代表的是类,不能代表包,所以使用
import lee.*;
语句时,只能导入lee包下的所有类,不包含其子包。如果要导入其子包下所有类,必须要手动再导入一遍。
import static
在JDK1.5之后增加了一种静态导入的语法,静态导入也有两种语法,分别用于导入指定类的单个静态成员变量、方法和全部静态成员变量、方法。
单个导入
import static package.subpackage...ClassName.fieldName|methodName;
上面语法导入 package.subpackage…ClassName 类中名为fieldName的静态变量或者名为methodName的静态方法。
全部导入
import static package.subpackage...ClassName.*;
上面的 * 只能代表静态成员变量或方法名。
所谓静态成员变量、静态方法其实就是类变量、类方法,它们都需要使用static修饰,而static在很多地方都被翻译为静态。
使用import可以省略写包名,使用import static可以连类名都省略。
Java的常用包
java.lang
包含了Java语言的核心类,如String、Math、System、Thread类等,使用这个包下的类无需使用import语句导入,系统会自动导入这个包下的所有类。
java.until
包含了Java大量工具类/接口和集合框架类/接口,例如Arrays和List、Set等
java.net
包含了一些Java网络变成相关的类/接口
java.io
包含了一些Java输入/输出编程相关的类/接口。
java.text
包含了一些Java格式化相关的类
java.sql
包含了Java进行JDBC数据库编程的相关类/接口。
java.awt
包含了抽象窗口工具集(Abstract Window Toolkits)的相关类/接口,这些类主要用与构建图形用户界面(GUI)程序
java.swing
包含了Swing图形用户界面编程的相关类/接口,这些类可用于构建平台无关的GUI程序。
构造器
构造器最大的用处就是在创建对象时,执行初始化。
注意:构造器只能用new关键字调用
当创建一个对象时,系统会默认初始化,这种默认初始化把所有基本类型的实例变量设为0或false,把所有引用类型变量设为null。
构造器也可以自己构造,实现在系统创建对象时就为该对象的实例变量显式指定初始值。
如果未设置构造器,系统会为该类分配一个无参数的构造器,这个构造器执行体为空,不做任何事情。
构造器:
修饰符可以省略,也可以是public、protected、private之一
构造器名必须和类名相同
构造器主要用于被其他方法调用,用以返回该类的实例,因而通常把构造器设置成public访问权限,从而允许系统中任何位置的类来创建该类的对象。
构造器重载
同一个类里具有多个构造器,多个构造器的形参列表不同,即被称为构造器重载。
构造器重载可以实现根据具体情况对实例进行初始化的功能。
如果想要在一个构造器内调用另一个构造器,如果使用new调用一遍会再产生一个新对象,为了避免这种情况,可以使用this关键字来调用另一个重载构造器,系统会通过传参的不同来判断调用哪个构造器。
类的继承
java的继承通过extends关键字来实现,实现继承的类被称为子类,被继承的类 称为父类,也称其为基类、超类。
在包含的含义上,子类是一种特殊的父类,也就是说父类是大类而子类是小类。
extends的意思是扩展,也就是说子类实际上是父类的一种扩展,父类的所有成员变量,方法和内部类都会被继承,但不会继承父类的构造器。子类也会拥有自己的独特成员变量、方法和内部类。
Java中的类只能有一个直接父类,但是可以有无限个间接父类。
如果未显式指定类的父类,那么系统会默认拓展java.lang.Object类。
重写父类的方法
子类拓展了父类,具有父类的除构造器以外的所有成员变量和方法和内部类,但在某些时候,子类需要重写父类的方法,例如鸵鸟也是鸟,但鸟类通用的飞翔对它来说就不合适,这种情况就需要改写方法。
改写的方式被称为方法重写或方法覆盖,它遵循“两同两小一大”的规则
两同:方法名相同,形参列表相同。
两小:子类方法返回值类型应比父类方法返回值类型更小或相等。
一大:子类方法的访问权限应比父类方法的返回权限更大或相等
注意:覆盖方法和被覆盖方法要么都是类方法,要么都是实例方法。
super限定
如果需要在子类方法中调用父类被覆盖的实例方法们则可使用super限定来点用父类被覆盖的实例方法。
super是一个关键字,它用于限定该对象调用它从父类继承得到的实例变量或方法。正如this不能出现在static修饰的方法中一样,super也不能出现在static修饰的方法中。static修饰的方法是属于类的,该方法的调用者可能是一个类,而不是对象,因而super限定也失去了意义。
如果在构造器中使用super,则super用于限定该构造器初始化的是该对象从父类继承得到的实例变量,而不是该类自己定义的实例变量。
如果在某个方法中访问名为a的变量,但没有显式指定调用者,则系统查找a的顺序为:
- 查找该方法中是否有名为a的局部变量
- 查找当前类中是否包含名为a的成员变量
- 查找a的直接父类中是否包含名为a的成员变量,依次上溯a的所有父类,直到 java.lang.Object 类,如果不能找到,就编译错误。
如果在子类里定义了与父类中已有变量同名的变量,那么子类中定义的变量会隐藏父类中定义的变量。是隐藏而不是覆盖,系统在创建子类对象时,依然会为父类中定义的、被隐藏的变量分配内存。
如果被覆盖的是类变量,在子类方法中就可以通过父类名作为调用者来访问被覆盖的类变量。
调用父类构造器
子类不会获得父类的构造器,但子类构造器里可以调用父类构造器的初始化代码,类似于一个构造器调用另一个重载的构造器。
调用重载构造器时使用this关键字调用,在子类构造器中调用父类构造器使用super调用。
不管是否适用super调用来执行父类构造器的初始化代码,子类狗在其总会调用父类构造器一次。子类构造器调用父类构造器分如下几种情况:
- 子类构造器执行体的第一行使用super显式调用父类构造器,系统将根据super调用里传入的实参列表调用父类对应的构造器。
- 子类构造器执行体的第一行代码使用this显式调用本类中重载的构造器,系统将根据this调用里传入的实参列表调用本类中的另一个构造器。执行本类中另一个构造器时也会先调用父类构造器。
- 子类构造器执行体终极没有super调用,也没有this调用,系统将会在执行子类构造器之前,隐式调用父类无参数的构造器。
不管是哪种情况,当调用子类构造器初始化子类对象时,父类构造器总会在子类构造器之前执行;不仅如此,执行父类构造器时,系统会再次上溯执行其父类构造器……以此类推,创建任何Java对象时,最先执行的总是 java.lang.Object 类的构造器。
多态
Java引用变量有两个类型:一个是编译时类型,一个是运行时类型。编译时类型由声明该变量时使用的类型决定,运行时类型由实际赋给该变量的对象决定。如果编译时和运行时类型不一致,就可能出现所谓的多态。
多态性
因为子类其实是一种特殊的父类,因此Java允许把一个子类对象直接付给一个父类引用变量,无需任何类型转换,或者被称为向上转型(upcasting),向上转型由系统自动完成。
当把一个子类对象直接赋给父类引用变量时,当运行时调用该引用变量的方法时,其方法行为总是表现出子类方法的行为特征,而不是父类方法的行为特征,这就可能出现:相同类型的变量、调用同一个方法时呈现出多种不同的行为特征,这就是多态。
与方法不同的是,对象的实例变量不具备多态性。
引用变量的强制类型转换
编写Java程序的时候,引用变量只能调用它编译时类型的方法,而不能调用它运行时类型的方法,即使它实际所引用的对象确实包含该方法。如果需要让这个引用变量调用它运行时类型的方法们则必须把它强制类型转换成运行时类型,强制类型转换需要借助于类型转换运算符。
类型转换运算符是小括号,类型转换运算符的用法是: (type)variable,这种方法可以将variable变量转换成一个type类型的变量,
强制转换符可以将一个基本类型变量转换成另一个类型,还可以将一个引用类型变量转换成其子类型。
在进行强制类型转换时需要注意:
- 基本类型之间的转换只能在数值类型之间进行,这里说的数值类型包括整数型、字符型和浮点型。但数值类型和布尔类型之间不能进行类型转换。
- 引用类型之间的转换只能在具有继承关系的两个类型之间进行,如果是两个没有任何继承关系的类型,则无法进行类型转换,否则编译时就会出现错误。如果试图把一个父类实例转换成子类实例,则这个对象必须实际上是子类实例才行(即编译时类型为父类类型,而运行时类型是子类类型),否则将在运行时引发ClassCastException异常。
在强制类型转换之前,先用 instanceof 运算符判断是否可以成功转换,从而避免出现上述异常。
instanceof运算符
instanceof 运算符的前一个操作数通常是一个引用类型变量,后一个操作数通常是一个类(也可以是接口,可以把接口理解成一种特殊的类),它用于判断前面的对象是否是后面的类,或者其子类、实现类的实例。如果是,则返回true,否则返回false。
注意:instanceof运算符前面操作数的编译时类型要么与后面的类相同,要么与后面的类具有父子继承关系,否则会引起编译错误。
继承与组合
继承是实现类复用的重要手段,但继承带来了一个最大的坏处:破坏封装。相比之下组合是更好的解决方式。
使用继承的注意点
子类扩展父类时,子类可以从父类继承成员变量和方法,如果访问权限允许,子类可以直接访问父类的成员变量和方法。相当于子类可以直接复用父类的成员变量和方法,确实非常方便。
继承带来了高度复用的同时,也严重的破坏了父类的封装性。“每个类都应该疯传它内部信息和实现细节,只暴露必要的方法给其它类使用。但子类可以直接访问父类的成员变量和方法,从而造成子类和父类的高度耦合。
也就是说父类的实现细节对子类完全透明,子类可以访问父类的成员变量和方法,并可以改变父类方法的实现细节(方法重写),从而可能会使子类恶意篡改父类的方法。
为了保证父类有良好的封装性,不会被子类随意改变,设计父类通常应该遵循如下规则:
- 尽量隐藏父类的内部数据。尽量把父类的所有成员变量都设置成private访问类型,不让子类直接访问父类的成员变量。
- 不要让子类可以随意访问、修改父类的方法。父类中那些仅为辅助其他的工具方法,应该使用private修饰,让子类无法访问;如果父类中的方法需要被外部类调用,则必须以public修饰,但又不希望子类重写该方法,可以使用final修饰符修饰;如果希望父类的某个方法被子类重写,又不希望被其它类自由访问,则可以使用protected来修饰该方法。
- 尽量不要在父类构造器中调用将要被子类重写的方法
package extend;
/*
2023.4.1;
疯狂Java讲义,p157;
使用继承的注意点;
*/
public class notice {
public static void main(String[] args){
Sub sub = new Sub();
}
}
class Base{
public Base(){
test();
}
public void test(){
System.out.println("将要被子类重写的方法");
}
}
class Sub extends Base{
protected String name;
/*
该方法覆盖了Base中的test方法
所以会在执行Base构造器时执行该方法,但由于此时name还是空引用,所以会出现null错误
*/
public void test(){
System.out.println("子类重写父类的方法," + "其name字符串的长度" + name.length());
}
}
如果过想把某些类设置成最终类,既不能被当成父类,则可以使用final修饰,例如:java.lang.String 和 java.lang.System。除此之外,使用private修饰这个类的所有构造器,从而保证子类无法覅用该类的构造器,也就无法继承该类。对于吧所有构造器都是用private修饰的父类而言,可另外提供一个静态方法,用于创建该类的实例。
需要从父类派生新的子类的几种情况
- 子类需要额外增加成员变量,而不仅仅是变量值的改变。例如要从Person类派生出Student子类,Person类里没有提供grade成员变量。
- 子类需要增加自己独有的行为方式(包括增加新的方法或重写父类的方法)。例如从Person类派生出Teacher类,需要增加一个独有的teaching()方法,该方法只用于描述Teacher对象独有的行为方式,教学。
如果只是出于类复用的目的,完全可以使用组合来实现。
利用组合实现复用
如果需要复用一个类,除把这个类当成基类来继承外,还可以把该类当成另一个类的组合成分,从而允许新类直接复用该类的public方法,不管是继承还是组合,都允许在新类/子类中直接复用旧类的方法。
对于继承而言,子类可以直接获得父类的public方法,程序使用子类时,将可以直接访问该子类从父类那里继承到的方法;而组合则是把旧类对象作为新类的成员变量组合起来,用以实现新类的功能,用户看到的是新类的方法,而不能看到被组合对象的方法。因此,通常需要在新类里使用private修饰被组合的旧类对象。
package extend.extend_composite;
/*
2023.4.1
java疯狂讲义p159
继承和组合
继承
*/
public class extend {
public static void main (String[] args){
Bird b = new Bird();
b.breathe();
b.fly();
Wolf w = new Wolf();
w.breathe();
w.run();
}
}
class Animal{
private void beat () {
System.out.println("心脏跳动...");
}
public void breathe () {
beat();
System.out.println("吸一口气,吐一口气,呼吸中...");
}
}
class Bird extends Animal {
public void fly () {
System.out.println("我在天空自在地飞翔...");
}
}
class Wolf extends Animal {
public void run () {
System.out.println("我在陆地上快速的奔跑...");
}
}
上面的代码就是简单的继承的标准格式,同样,他们可以写成下面这样的组合形式:
package extend.extend_composite.composite;
/*
2023.4.1
疯狂java讲义 P160
继承和组合
组合
*/
public class composite {
public static void main (String[] args) {
//现在开始构造鸟组合
//需要显式创建Animal,被组合成份
Animal a = new Animal();
Bird b = new Bird(a);
b.breathe();
b.fly();
Animal aa = new Animal();
Wolf w = new Wolf(aa);
w.breathe();
w.run();
}
}
class Animal{
private void beat () {
System.out.println("心脏跳动...");
}
public void breathe () {
beat();
System.out.println("吸一口气,吐一口气,呼吸中...");
}
}
class Bird {
//将原来的父类组合到原来的子类,作为子类的一个组合成份
private Animal a;
public Bird(Animal a){
this.a = a;
}
public void breathe () {
//直接复用Animal提供的breathe()方法来实现Bird的breathe()方法
a.breathe();
}
public void fly () {
System.out.println("我在天空自由的飞翔...");
}
}
class Wolf {
private Animal a;
public Wolf (Animal a) {
this.a = a;
}
public void breathe () {
a.breathe();
}
public void run () {
System.out.println("我在陆地上快速奔跑...");
}
}
继承是对已有的类做改造,以此获得一个特殊的版本,也就是将一个较为抽象的类改造成能适用于某些特定需求的类。因此,对于上面的例子来说,其实继承更能表达其现实意义。
反之如果两个类之间有明确的整体、部分的关系,例如Person类需要复用Arm类的方法,就应该采用组合关系。
继承所要表达的是 “是” ;组合表达的是 “有”;
初始化块
初始化块与构造器作用非常类似,它也可以对Java对象进行初始化操作。
使用初始化块
初始化块是Java类中可出现的第四种成员,一个类里可以有多个初始化块,相同类型的初始化块之间按照前后顺序执行。
初始化块的语法格式如下
[修饰符]{
//初始化块的可执行性代码
...
}
初始化块的修饰符只能是static或者没有,使用static修饰的称为类初始化块(静态初始化块),没有的称为实例初始化块(非静态初始化块)。初始化块里的代码可以包含任何可执行性语句。
package extend.initialize;
/*
2023.4.1
Java疯狂讲义 p161
初始化块
*/
public class initialize {
public static void main (String[] args) {
Person person = new Person();
}
}
class Person{
{
int a = 6;
if (a > 4) {
System.out.println("Person实例初始化块:局部变量a的值大于4");
}
System.out.println("Person的实例初始化块");
}
//定义第二个实例初始化块
{
System.out.println("Person的第二个实例初始化块");
}
//定义无参数的构造器
public Person () {
System.out.println("Person类的无参数构造器");
}
}
/*
输出:
Person实例初始化块:局部变量a的值大于4
Person的实例初始化块
Person的第二个实例初始化块
Person类的无参数构造器
*/
初始化块是一种没有名字无法通过类或对象进行调用的Java类的成员,只在创建Java对象时在构造器之前自动隐式执行。类初始化则在类初始化阶段自动执行。
Java创建一个对象时初始化的顺序
当Java创建一个对象时,系统先为该对象的所有实例变量分配内存(前提是该类已经被加载过了),接着程序开始对这些实例变量执行初始化:先执行实例初始化块或者声明实例变量时指定的初始值(这两个地方的执行顺序是平级的,只看前后顺序),再执行构造器里指定的初始值。
实例初始化块和构造器
实例初始化块是不接受参数的,可以说是构造器的一种补充,在有多个构造器中具有重复的且无需接收的参数的初始化代码时,就可以将这些代码放在实例初始化块中,能更好地提高初始化代码的复用,提高整个应用的可维护性。
类初始化块
如果定义初始化块是使用static修饰,那么这就是一个类初始化块,系统将在类初始化阶段执行类初始化块。
类初始化块不能对实例变量进行初始化处理。
与实例初始化块类似的是,系统在类初始化阶段执行类初始化块时,会一直上溯到java.lang.Object类(如果它包含类初始化块),然后一层层向下执行类初始化块,最后执行本类的类初始化块,这整个类初始化过程完成后,才可以在系统中使用这个类。
package extend.initialize.Class_initialization;
/*
2023.4.1
疯狂Java讲义 p165
类初始化块
*/
public class Class_initialize {
public static void main (String[] args) {
new Leaf();
System.out.println();
new Leaf();
}
}
class Root{
static{
System.out.println("Root的类初始化块");
}
{
System.out.println("Root的实例初始化块");
}
public Root () {
System.out.println("Root的无参数的构造器");
}
public Root (String str) {
System.out.println("Root的带参数构造器");
}
}
class Mid extends Root {
static {
System.out.println("Mid的类初始化块");
}
{
System.out.println("Mid的实例初始化块");
}
public Mid () {
System.out.println("Mid的无参数构造器");
}
public Mid (String msg) {
//通过this调用同一类中重载的构造器
this();
System.out.println("Mid的带参数构造器,其参数值" + msg);
}
}
class Leaf extends Mid {
static {
System.out.println("Leaf的类初始化块");
}
{
System.out.println("Leaf的实例初始化块");
}
public Leaf () {
//通过super调用父类中有一个字符串参数的构造器
super("疯狂Java讲义");
System.out.println("执行Leaf的构造器");
}
}
/*
输出:
Root的实例初始化块
Root的无参数的构造器
Mid的实例初始化块
Mid的无参数构造器
Mid的带参数构造器,其参数值疯狂Java讲义
Leaf的实例初始化块
执行Leaf的构造器
Root的实例初始化块
Root的无参数的构造器
Mid的实例初始化块
Mid的无参数构造器
Mid的带参数构造器,其参数值疯狂Java讲义
Leaf的实例初始化块
执行Leaf的构造器
*/
第一次创建某个类的对象时,系统会对该类进行初始化,也是一直回溯到最顶层的类,然后一层层初始化。第二次创建该类的对象时,就没必要再进行类初始化了。
类初始化块和在声明类变量时指定值的执行是平级的,只看先后顺序。
第六章 面向对象下
包装类
Java保留了8种基本数据类型,但是这8中基本数据类型不支持面向对象的编程机制,也不具备对象的特征,没有成员变量、方法可以被调用。
这会在带来便捷性的同时,带来了一些制约。在Java中所有的引用类型变量都继承了Object类,如果有个方法需要Object类型的参数,但实际需要的值却是基本数据类型的,这就会带来一些不便。
为了解决这八种基本数据类型的变量不能当成Object类型变量使用的问题,Java提供了包装类(Wrapper Class)的概念,为这8种基本数据类型分别定义了相应的引用类型民并称之为基本数据类型的包装类。
| 基本数据类型 | 包装类 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| char | Character |
| float | Float |
| double | Double |
| boolean | Boolean |
除了int和char有些不同外,其他的基本数据类型对应的包装类都是将其首字母大写即可
Java自1.5之后就推出了自动装箱和自动拆箱的功能。
自动装箱就是把一个基本类型变量直接赋给对应的包装类变量,或者赋给Object变量;自动拆箱则是直接把一个包装类对象赋给基本类型变量。
包装类可以实现基本类型变量和字符串之间的转换,把字符串类型的值转换为基本数据类型有两种方式
- 利用包装类提供的parseXxx(String s)静态方法(除Character以外的所有包装类都提供了该方法)
- 利用包装类提供的valueOf(String s)静态方法
String类也提供了多个重载方法用于把基本类型变量转换为字符串。
但一般来说,聪明的人们都会使用下面的方法:
String s = 5 + "";
处理对象
==和equals方法
Java中可以使用==运算符或者equals()方法来判断两个变量是否相等,如果两个变量时基本类型变量,且都是数值类型,则只要
两个变量的值相等,就返回true。但对于引用变量来说,== 比较的是地址,也就是说只有当比较的双方指向同一个对象时,才会返回true。
如果需要判断引用变量的值是否相等,这个时候就要使用equals()方法,这是Object类提供的一个实例方法,因此所有引用变量都可以调用该方法来判断是否与其他引用变量相等。但是这个Object中的方法其实并没有什么用,它与==所起到的效果相同,如果需要进行值判断就必须对其进行重写,例如String类中就已经对其做好了重写。
重写equals()方法应该满足下列条件:
- 自反性:对任意x,x.equals(x)一定返回true;
- 对称性:对任意x和y,如果y.equals(x)返回true,那么x.equals(y)也应该返回true;
- 传递性:对任意y,x,z,如果x.equals(y)返回true,y.equals(z)返回true,则x.equals(z)一定返回true;
- 一致性:对任意x,y,如果对象中用于等价比较的信息没有改变,那么无论调用x.equals(y)多少次,返回的结果应该保持一致;
- 对任何不是null的x,x.equals(null)一定返回false;
类成员
理解类成员
static修饰的成员就是类成员;
类变量属于整个类, 当系统第一次准备使用该类时,系统会为该类变量分配内存空间,类变量开始生效,直到该类被卸载,该类的类变量所占有的内存才被系统的垃圾回收机制回收。类变量生存范围几乎等同于该类的生存范围。当类初始化完成后,类变量也被初始化完成。
类变量既可通过类来访问,也可通过类的对象来访问,但通过类的对象来访问类变量时,实际上还是那个类变量,类变量时整个类持有的,并不属于类的任一个实例。
类方法也与类成员相似,都是属于类的,通过对象调用类方法与通过类调用是一样的。
当通过实例来访问类成员时,实际上也是转换后通过类来访问的,因此即使某个实例为null,也可以正常访问类成员。
对于static关键字而言,:
**类成员不能访问实例成员。**因为类成员是属于类的,作用范围实际大于实例成员,在用类调用类成员时,是没有实例成员来让类成员调用的,而且类成员初始化的时候,如果内部包含实例成员,这些实例成员又没被初始化,会造成大量错误。
单例类
类的构造器大多时候都是public访问权限的,但是如果某个类只有一个单个的实例存在,比如皇帝,此时允许其他类自由创建该类的对象没有任何意义。
如果一个类始终只能创建一个实例,则这个类被称为单例类。
在一些特殊场景下,要求不允许自由创建该类的对象,只允许为该类创建一个对象。为了避免其他类自由创建该类的实例,应该把该类的构造器用private修饰,从而把该类的所有构造器隐藏起来。
更具良好封装的原则:一旦把该类的构造器隐藏起来,就需要提供一个public方法作为该类的构造点,用于创建该类的对象,而该方法必须使用static修饰(因为调用该方法之前还不存在对象,该方法必须是类方法)
除此之外,该类还必须缓存已经创建的对象,否则该类无法知道是否曾经创建过该对象,也就无法保证只创建一个对象。为此该类需要使用一个成员变量来保存曾经创建的对象,因为该成员变量需要被刚才提到的构造点类方法访问,所以也必须使用static修饰。
final修饰符
final关键字可以用于修饰类、变量和方法,用于表示它所修饰的类、方法和变量不可改变。
final修饰变量时,表示该变量一旦获得了初始值就不可被改变,final即可修饰成员变量,也可修饰局部变量、形参。一旦获取了初始值,该final变量的值就不能被重新赋值。
由于final变量获得初始值之后不能被重新赋值,因此final修饰成员变量和修饰局部变量时有一定的区别,
final成员变量
final修饰的成员变量必须由程序员显示的指定初始值。
- 类变量:必须在静态初始化块中指定初始值或声明该类变量时指定初始值,而且只能在两个地方其中之一指定。
- 实例变量:必须在非静态初始化块、声明该实例变量或构造器中指定初始值,而且只能在三个地方的其中之一指定。
final局部变量
系统不会对局部变量进行初始化,局部变量必须由程序员显式初始化。因此使用final修饰局部变量时,既可以在定义是指定默认值,也可以不指定默认值。
如果final修饰的局部变量在定义时没有指定默认值,则可以在后面代码中对该final变量赋初始化值,但只能一次,不能重复复置;如果final修饰的局部变量在定义时已经指定默认值,则后面代码中不能再对该变量赋值。
final修饰的基本类型变量和引用类型变量的区别
当使用final修饰基本类型变量时,不能对基本类型变量重新赋值,因此基本类型变量不能被改变,但对于引用类型变量而言,它保存的仅仅是一个引用,final只保证这个引用类型变量所引用的地址不会改变,但这个对象可以进行改变。
可执行宏替换的final变量
对一个final变量来说,只要满足三个条件,这个final变量就相当于一个直接量
- 使用final修饰符修饰
- 在定义该final变量时指定了初始值
- 该初始值可以在编译时就被确定下来
需要调用类方法的变量无法在编译时就被确定下来
在编译时就确定的值是指向常量池内的,所以如果是引用变量的话,直接量之间是可以 == 的,而在程序运行之后才确定的变量是不会指向常量池内的。
final方法
final修饰的方法不可被重写,如果不希望子类重写父类的某个方法,就可以使用final修饰该方法。
对于一个private方法,因为它仅在当前类中可见,其子类无法访问该方法,所以子类无法重新给该方法——如果子类中定义一个与父类private方法有相同方法名,形参列表,返回值类型的方法,也不是方法重写,只是定义了一个新方法。因此,即使使用final修饰一个private访问权限的方法,依然可以在其子类中重新定义。
final修饰的方法仅仅是不能被重写,是可以重载的。
final类
final修饰的类不可以有子类。
不可变类
不可变类的意思是创建该类的实例后们该实例的实例变量是不可变的。
创建一个不可变类:
- 使用private和final来修饰该类的成员变量
- 提供带参数的构造器(或返回该实例的类方法),用于根据传入参数来初始化类里的成员变量
- 仅为该类的成员变量提供getter方法,不要为该类的成员变量提供setter方法,因为普通方法无法修改final修饰的成员变量
- 如果有必要,重写Object类的hashCode()和equals()方法。equals()方法根据关键成员变量来作为两个对象是否相等的标准,除此之外,还应该保证两个用equals()方法判断为相等的hashCode()也相等。
但由于在使用final保护引用变量的时候其实无法完全保护到引用变量的值,只能保证其地址不变,所以当我们创建的不可变类内有引用变量时,需要通过一些方法保护引用变量
- 在创建实力引用变量时,重新定义一个引用变量来接收传入的引用变量的引用的值,这就在第一步进入的时候保护了实例变量的地址
- 在getter方法中,传出该不可变量的值的时候,创建一个新的引用变量来接收值并传出,之就在出口保护了实例变量的地址。
缓存实例的不可变类
不可变类的实例状态不可改变,可以很方便地被多个对象所共享。如果程序经常需要使用相同的不可变类实例,则应该考虑缓存这种不可变类的实例。毕竟重复创建相同的对象没有太大的意义,而且加大系统开销。如果可能,应该将已经创建的不可变类的实例进行缓存。
本节将用一个数组来作为缓存池,从而实现一个缓存实例的不可变类。
抽象类 abstract
抽象方法是只有方法签名,没有方法实现的方法。
抽象方法和抽象类
抽象方法和抽象类必须使用abstract修饰符来修饰,有抽象方法的类只能被定义为抽象类,抽象类里可以没有抽象方法。
-
抽象类必须使用abstract修饰符来修饰,抽象方法也必须使用abstract修饰,抽象方法不能有方法体
-
抽象类不能被实例化,无法使用new关键字来调用抽象类的构造器创建抽象类的实例。即使抽象类里不包含抽象方法,这个抽象类也不能创建实例。
-
抽象类可以包含成员变量、方法(普通方法和抽象方法)、构造器、初始化块、内部类(接口、枚举)5种成分抽象类的构造器不能用于创建实例,主要是用于被其子类调用。
-
含有抽象方法的类(包括直接定义了一个抽象方法;或继承了一个抽象父类,但没有完全实现父类包含的抽象方法;或实现了一个接口,但没有完全实现接口包含的抽象方法三种情况)只能被定义成抽象类。
利用抽象类和抽象方法的优势,可以更好地发挥多态的优势,使程序更加灵活。
当使用abstract修饰类时,表明这个类只能被继承;当使用abstract 修饰方法时,表明这个方法必须被子类重写,而final修饰的类不能被继承,final修饰的方法不能被重写。因此final和abstract永远不能同时使用。
abstract和private不能同时修饰方法。
static和abstract并不是绝对互斥,虽然不能同时修饰某个方法,但它们可以同时修饰内部类。
定义抽象类只需在普通类上增加abstract修饰符即可。甚至一个 普通类(没有包含抽象方法的类)增加abstract修饰符后也将变成抽 象类。
下面定义一个Shape抽象类。
// 定义一个抽象类 Shape
abstract class Shape {
// 定义一个实例变量 area,用于存储图形的面积
protected double area;
// 定义一个抽象方法,用于计算图形的面积
public abstract void calculateArea();
// 定义一个非抽象方法,用于显示图形的面积
public void displayArea() {
System.out.println("The area of the shape is: " + area);
}
}
// 定义一个圆形类 Circle,继承自 Shape 类
class Circle extends Shape {
// 定义一个私有变量 radius,表示圆形的半径
private double radius;
// 定义一个构造方法,用于创建 Circle 对象并初始化 radius
public Circle(double radius) {
this.radius = radius;
}
// 实现 calculateArea 方法,计算圆形的面积并存储到 area 变量中
public void calculateArea() {
area = Math.PI * radius * radius;
}
}
// 定义一个矩形类 Rectangle,继承自 Shape 类
class Rectangle extends Shape {
// 定义两个私有变量 length 和 width,表示矩形的长和宽
private double length;
private double width;
// 定义一个构造方法,用于创建 Rectangle 对象并初始化 length 和 width
public Rectangle(double length, double width) {
this.length = length;
this.width = width;
}
// 实现 calculateArea 方法,计算矩形的面积并存储到 area 变量中
public void calculateArea() {
area = length * width;
}
}
// 定义一个主类 Main
public class Main {
public static void main(String[] args) {
// 创建一个 Circle 对象,计算并显示圆形的面积
Circle circle = new Circle(5.0);
circle.calculateArea();
circle.displayArea();
// 创建一个 Rectangle 对象,计算并显示矩形的面积
Rectangle rectangle = new Rectangle(3.0, 4.0);
rectangle.calculateArea();
rectangle.displayArea();
}
}
在上面的例子中,Shape 类是一个抽象类,它有一个抽象方法 calculateArea(),以及一个实例变量 area 和一个非抽象方法 displayArea()。Circle 类和 Rectangle 类都继承自 Shape 类,并实现了 calculateArea() 方法来计算圆形和矩形的面积。在 Main 类中,我们创建了一个圆形对象和一个矩形对象,并调用它们的 calculateArea() 和 displayArea() 方法来计算并显示它们的面积。由于 Shape 类是抽象的,我们不能直接实例化它,但可以通过创建 Circle 和 Rectangle 对象来使用它。
如果想子类实现抽象类的一个可以实例化的子类,就必须重写抽象类中的所有抽象方法,否则还是只不过定义了一个抽象类而已
抽象类的作用
抽象类不能创建实例,只能当成父类来被继承。抽象类是从多个具体类中抽象出来的父类,它具有更高层次的抽象。从多个具有相同特征的类中抽象出一个抽象类,以这个抽象类作为其子类的模板,从而避免了子类设计的随意性。
如果编写一个抽象父类,父类提供了多个子类的通用方法,并把一个或多个方法留给其子类实现,这就是一种模板模式,模板模式在现象对象的软件中很常用,其原理简单,实现也很简单。下面是一些使用模板模式的简单规则:
- 抽象父类可以只定义需要使用的某些方法,把不能实现的部分抽象成抽象方法,留给其子类去实现。
- 父类中可能包含需要调用其他系列方法的方法,这些被调方法既可以由父类实现,也可以由其子类实现。夫雷里提供的方法只是定义了一个通用算法,其实现也许并不完全由自身实现,而必须依赖于其子类的辅助。
以下是一个抽象类模板模式的例子,假设我们要实现一个游戏,其中有多个角色需要移动到指定位置,但不同的角色移动的方式可能不同:
// 定义一个抽象类 GameCharacter,作为角色的基类
abstract class GameCharacter {
// 定义一个抽象方法,表示角色移动的方式
public abstract void move();
// 定义一个模板方法,控制角色的移动流程
public void moveCharacter() {
// 执行角色的移动方式
move();
// 执行其他操作,比如播放动画、检查碰撞等
playAnimation();
checkCollision();
}
// 定义一个私有方法,用于播放动画
private void playAnimation() {
System.out.println("Playing animation...");
}
// 定义一个私有方法,用于检查碰撞
private void checkCollision() {
System.out.println("Checking collision...");
}
}
// 定义一个实现类,表示角色通过跳跃移动
class JumpingCharacter extends GameCharacter {
// 实现 move 方法,表示角色跳跃移动
public void move() {
System.out.println("Jumping...");
}
}
// 定义一个实现类,表示角色通过飞行移动
class FlyingCharacter extends GameCharacter {
// 实现 move 方法,表示角色飞行移动
public void move() {
System.out.println("Flying...");
}
}
// 定义一个主类 Main
public class Main {
public static void main(String[] args) {
// 创建一个跳跃角色对象,并执行移动操作
GameCharacter jumpingCharacter = new JumpingCharacter();
jumpingCharacter.moveCharacter();
// 创建一个飞行角色对象,并执行移动操作
GameCharacter flyingCharacter = new FlyingCharacter();
flyingCharacter.moveCharacter();
}
}
在上面的例子中,GameCharacter 类是一个抽象类,其中有一个抽象方法 move(),用于表示角色的移动方式。它还有一个模板方法 moveCharacter(),用于控制角色的移动流程,包括执行移动方式、播放动画和检查碰撞等操作。JumpingCharacter 类和 FlyingCharacter 类都继承自 GameCharacter 类,并实现了 move() 方法来表示角色的不同移动方式。在 Main 类中,我们创建了一个跳跃角色对象和一个飞行角色对象,并调用它们的 moveCharacter() 方法来控制它们的移动流程。
抽象类模板模式的核心思想是将算法的骨架封装在一个模板方法中,而将具体实现放在子类中。这样可以使得算法的结构保持不变,同时又能够灵活地改变算法的具体实现。在上面的例子中,moveCharacter() 方法就是一个模板方法,它控制了角色移动的流程,而具体的移动方式则由子类来实现。
Java9改进的接口
如果将抽象类再抽象更彻底一些,就可以提炼出一种更加特殊的“抽象类”——接口(interface)。Java9对接口进行了改进,允许在接口中定义默认方法和类方法,默认方法和类方法都可以提供方法实现,Java9为接口增加了一种私有方法,私有方法也可以提供方法实现。
接口的概念
同一个类的内部状态数据,各种方法的实现细节完全相同,类是一种具体实例。而接口定义了一种规范,接口定义了某一批类所需要遵守的规范,接口不关心这些类的内部状态数据,也不关心这些类里方法的实现细节,它之规定这些类里必须提供某些方法,提供这些方法的类就可以满足需要。
可见,接口是从多个相似类中抽象出来的规范,接口不提供任何实现。
让规范和实现分离正是接口的好处,让软件系统的各组件之间面向接口耦合,是一种松耦合的设计。
接口中定义的时多个类共同的公共行为规范,这些行为是与外部交流的通道,这就意味着接口里通常是定义一组公用方法。
Java9中接口的定义
定义接口使用interface关键字。
[修饰符] interface 接口名 extends 父接口1,父接口2
{
零个到多个常量定义
零个到多个抽象方法定义
零个到多个内部类、接口、枚举定义
零个到多个私有方法、默认方法或类方法定义
}
- 修饰符可以是public或者省略,如果省略了public访问控制 符,则默认采用包权限访问控制符,即只有在相同包结构下才 可以访问该接口。
- 接口名应与类名采用相同的命名规则,即如果仅从语法角度来 看,接口名只要是合法的标识符即可;如果要遵守Java可读性 规范,则接口名应由多个有意义的单词连缀而成,每个单词首 字母大写,单词与单词之间无须任何分隔符。接口名通常能够 使用形容词。
- 一个接口可以有多个直接父接口,但接口只能继承接口,不能继承类。
在上面语法定义中,只有在Java 8以上的版本中才允许在接口 中定义默认方法、类方法。关于内部类、内部接口、内部枚举的知 识,将在下一节详细介绍。
由于接口定义的是一种规范,因此接口里不能包含构造器和初始化块定义。接口里可以包含成员变量(只能是静态常量)、方法(只能是抽象实例方法、类方法、默认方法或私有方法)、**内部类(包括 内部接口、枚举)**定义。
前面已经说过了,接口里定义的是多个类共同的公共行为规范, 因此接口里的常量、方法、内部类和内部枚举都是public访问权限。 定义接口成员时,可以省略访问控制修饰符,如果指定访问控制修饰 符,则只能使用public访问控制修饰符。
Java 9为接口增加了一种新的私有方法,其实私有方法的主要作 用就是作为工具方法,为接口中的默认方法或类方法提供支持。私有 方法可以拥有方法体,但私有方法不能使用default修饰。私有方法可 以使用static修饰,也就是说,私有方法既可是类方法,也可是实例 方法
对于接口里定义的静态常量而言,它们是接口相关的,因此系统会自动为这些成员变量增加static和final两个修饰符。也就是说,在 接口中定义成员变量时,不管是否使用public static final修饰符, 接口里的成员变量总是使用这三个修饰符来修饰。而且接口里没有构 造器和初始化块,因此接口里定义的成员变量只能在定义时指定默认值。
接口里定义的方法只能是抽象方法、类方法、默认方法或私有方 法,因此如果不是定义默认方法、类方法或私有方法,系统将自动为 普通方法增加abstract修饰符;定义接口里的普通方法时不管是否使 用 public abstract 修 饰 符 , 接 口 里 的 普 通 方 法 总 是 使 用 public abstract来修饰。接口里的普通方法不能有方法实现(方法体);但 类方法、默认方法、私有方法都必须有方法实现(方法体)。
默认方法
从Java 8开始,在接口里允许定义默认方法,默认方法必须使用 default修饰,该方法不能使用static修饰,无论程序是否指定,默认方法总是使用public修饰——如果开发者没有指定public,系统会自 动为默认方法添加public修饰符。由于默认方法并没有static修饰, 因此不能直接使用接口来调用默认方法,需要使用接口的实现类的实例来调用这些默认方法。
**从Java 8开始,在接口里允许定义类方法,**类方法必须使用 static修饰,该方法不能使用default修饰,无论程序是否指定,类方法总是使用public修饰——如果开发者没有指定public,系统会自动为类方法添加public修饰符。类方法可以直接使用接口来调用。
Java 9增加了带方法体的私有方法,这也是Java 8埋下的伏笔: Java 8允许在接口中定义带方法体的默认方法和类方法—这样势必会 引发一个问题,当两个默认方法(或类方法)中包含一段相同的实现 逻辑时,程序必然考虑将这段实现逻辑抽取成工具方法,而工具方法是应该被隐藏的,这就是Java 9增加私有方法的必然性。
接口里的成员变量默认是使用public static final修饰的,因此即使另一个类处于不同包下,也可以通过接口来访问接口里的成员变量。
接口的继承
接口的继承和类继承不一样,接口完全支持多继承,即一个接口可以有多个直接父接口。和类继承相似,子接口扩展某个父接口,将会获得父接口里定义的所有抽象方法、常量。
一个接口继承多个父接口时,多个父接口排在extends关键字之 后,多个父接口之间以英文逗号(,)隔开。下面程序定义了三个接 口,第三个接口继承了前面两个接口。
interface InterfaceA {
void foo();
}
interface InterfaceB {
void bar();
}
interface InterfaceC extends InterfaceA, InterfaceB {
void baz();
}
class MyClass implements InterfaceC {
public void foo() {
System.out.println("foo");
}
public void bar() {
System.out.println("bar");
}
public void baz() {
System.out.println("baz");
}
}
public class Main {
public static void main(String[] args) {
MyClass myClass = new MyClass();
myClass.foo();
myClass.bar();
myClass.baz();
}
}
使用接口
接口不能用于创建实例,但接口可以用于声明引用类型变量。当 使用接口来声明引用类型变量时,这个引用类型变量必须引用到其实 现类的对象。除此之外,接口的主要用途就是被实现类实现。归纳起 来,接口主要有如下用途 ;
- 定义变量,也可用于进行强制类型转换。
- 调用接口中定义的常量
- 被其它类实现
一个类可以实现一个或多个接口,继承使用extends关键字,实现 则使用implements关键字。因为一个类可以实现多个接口,这也是 Java为单继承灵活性不足所做的补充。类实现接口的语法格式如下:
类实现接口的语法格式如下:
class MyClass implements MyInterface {
// 类的成员变量和方法
}
其中,MyClass 是实现了 MyInterface 接口的类名,implements 关键字用于表示类实现了一个或多个接口,MyInterface 是要实现的接口名。在实现接口的类中,需要实现接口中定义的所有抽象方法,否则会导致编译错误。
例如,下面的例子中,我们定义了一个 Calculator 接口,其中包含了四个抽象方法。我们创建了一个 BasicCalculator 类,它实现了 Calculator 接口,并实现了接口中定义的所有抽象方法:
// 定义一个计算器接口
interface Calculator {
int add(int x, int y);
int subtract(int x, int y);
int multiply(int x, int y);
int divide(int x, int y);
}
// 实现 Calculator 接口的类
class BasicCalculator implements Calculator {
public int add(int x, int y) {
return x + y;
}
public int subtract(int x, int y) {
return x - y;
}
public int multiply(int x, int y) {
return x * y;
}
public int divide(int x, int y) {
return x / y;
}
}
在上面的例子中,我们定义了一个 Calculator 接口,其中包含了四个抽象方法。我们创建了一个 BasicCalculator 类,它实现了 Calculator 接口,并实现了接口中定义的所有抽象方法。这样,我们就可以通过 BasicCalculator 类创建一个基本的计算器对象,并使用它的 add、subtract、multiply 和 divide 方法进行加减乘除运算了。
接口不能显式继承任何类,但所有接口类型的引用变量都可以直 接赋给Object类型的引用变量。
接口和抽象类
接口和抽象类很像,它们都具有如下特征。
- 接口和抽象类都不能被实例化,它们都位于继承树的顶端,用 于被其他类实现和继承。
- 接口和抽象类都可以包含抽象方法,实现接口或继承抽象类的普通子类都必须实现这些抽象方法。
但接口和抽象类之间的差别非常大,这种差别主要体现在二者设计目的上。
接口作为系统与外界交互的窗口,接口体现的是一种规范。对于 接口的实现者而言,接口规定了实现者必须向外提供哪些服务(以方 法的形式来提供);对于接口的调用者而言,接口规定了调用者可以 调用哪些服务,以及如何调用这些服务(就是如何来调用方法)。当 在一个程序中使用接口时,接口是多个模块间的耦合标准;当在多个 应用程序之间使用接口时,接口是多个程序之间的通信标准。
从某种程度上来看,接口类似于整个系统的“总纲”,它制定了 系统各模块应该遵循的标准,因此一个系统中的接口不应该经常改 变。一旦接口被改变,对整个系统甚至其他系统的影响将是辐射式 的,导致系统中大部分类都需要改写。
抽象类则不一样**,抽象类作为系统中多个子类的共同父类,它所 体现的是一种模板式设计**。抽象类作为多个子类的抽象父类,可以被 当成系统实现过程中的中间产品,这个中间产品已经实现了系统的部 分功能(那些已经提供实现的方法),但这个产品依然不能当成最终产品,必须有更进一步的完善,这种完善可能有几种不同方式。
除此之外,接口和抽象类在用法上也存在如下差别。
- 接口里只能包含抽象方法、静态方法、默认方法和私有方法, 不能为普通方法提供方法实现;抽象类则完全可以包含普通方法。
- 接口里只能定义静态常量,不能定义普通成员变量;抽象类里则既可以定义普通成员变量,也可以定义静态常量。
- 接口里不包含构造器;抽象类里可以包含构造器,抽象类里的构造器并不是用于创建对象,而是让其子类调用这些构造器来完成属于抽象类的初始化操作。
- 接口里不能包含初始化块;但抽象类则完全可以包含初始化块。
- 一个类最多只能有一个直接父类,包括抽象类;但一个类可以直接实现多个接口,通过实现多个接口可以弥补Java单继承的不足。
面向接口编程
简单工厂模式
简单工厂模式是一种创建型设计模式,它提供了一个工厂类,用于根据客户端传递的参数来创建不同的对象。简单工厂模式是最简单的工厂模式,它将对象的创建过程封装在一个工厂类中,让客户端无需了解对象的具体创建过程,只需要提供需要创建的对象的类型即可。
下面是一个简单的例子,演示了简单工厂模式的应用。我们定义了一个 Animal 接口,表示动物的行为,其中包含了一个 makeSound 抽象方法。然后我们创建了一个 Dog 类和一个 Cat 类,它们都实现了 Animal 接口,并实现了 makeSound 方法。接着,我们创建了一个 AnimalFactory 工厂类,用于根据客户端传递的参数来创建不同的动物对象。
interface Animal {
void makeSound();
}
class Dog implements Animal {
public void makeSound() {
System.out.println("汪汪汪");
}
}
class Cat implements Animal {
public void makeSound() {
System.out.println("喵喵喵");
}
}
class AnimalFactory {
public static Animal createAnimal(String type) {
if ("dog".equals(type)) {
return new Dog();
} else if ("cat".equals(type)) {
return new Cat();
} else {
throw new IllegalArgumentException("Invalid animal type: " + type);
}
}
}
public class Main {
public static void main(String[] args) {
Animal dog = AnimalFactory.createAnimal("dog");
Animal cat = AnimalFactory.createAnimal("cat");
dog.makeSound();
cat.makeSound();
}
}
在上面的例子中,我们定义了一个 Animal 接口,其中包含了一个 makeSound 抽象方法。然后我们创建了一个 Dog 类和一个 Cat 类,它们都实现了 Animal 接口,并实现了 makeSound 方法。接着,我们创建了一个 AnimalFactory 工厂类,它包含了一个静态方法 createAnimal,用于根据客户端传递的参数来创建不同的动物对象。在 Main 类的 main 方法中,我们通过调用 AnimalFactory.createAnimal 方法来创建狗和猫的对象,然后通过调用它们的 makeSound 方法,分别输出了狗和猫发出的声音。
简单工厂模式的优点在于它可以将对象的创建过程封装在一个工厂类中,使得客户端无需了解对象的具体创建过程。这样可以使得代码更加灵活和可扩展,同时也可以降低代码的耦合度。但是,简单工厂模式的缺点在于它不够灵活,一旦需要创建新的对象类型,就需要修改工厂类的代码,这可能会导致代码的膨胀和维护的困难。
简单工厂模式适用于以下场景:
- 对象的创建过程相对简单,不需要太多的复杂逻辑。
- 客户端不需要了解对象的具体创建过程,只需要提供需要创建的对象的类型即可。
- 需要根据不同的情况来创建不同的对象,但是这些对象都有相同的基类或接口。
下面是一些简单工厂模式的应用场景的例子:
- 图形绘制工具:一个图形绘制工具需要支持画不同类型的图形,比如圆形、矩形、三角形等。这些图形类都实现了同一个图形接口,可以使用简单工厂模式来创建不同的图形对象。
- 数据库连接池:一个数据库连接池需要支持不同类型的数据库连接,比如 MySQL、Oracle、SQL Server 等。这些数据库连接都有相同的接口,可以使用简单工厂模式来创建不同类型的数据库连接对象。
- 日志记录器:一个日志记录器需要支持不同类型的日志输出方式,比如控制台输出、文件输出、数据库输出等。这些日志输出方式都有相同的接口,可以使用简单工厂模式来创建不同类型的日志输出对象。
在这些场景中,简单工厂模式可以让客户端通过传递不同的参数来创建不同类型的对象,从而避免了客户端需要了解对象的具体创建过程。同时,简单工厂模式也使得代码更加灵活和可扩展,可以方便地增加或修改对象的类型,而不需要修改客户端的代码。
命令模式
命令模式是一种行为型设计模式,它将请求封装成一个对象,并将请求的发起者和执行者分离开来,从而可以实现请求的发送者和接收者之间的解耦。
考虑这样一种场景:某个方法需要完成某一个行为,但这个行为的具体实现无法确定,必须等到执行该方法时才可以确定。具体一 点:假设有个方法需要遍历某个数组的数组元素,但无法确定在遍历 数组元素时如何处理这些元素,需要在调用该方法时指定具体的处理行为。
在命令模式中,请求被封装成一个命令对象,该对象包含了请求的接收者和执行的方法。请求的发送者只需要创建一个命令对象,并将其发送给请求的接收者,而不需要知道命令的具体执行过程。请求的接收者负责执行命令,并确保命令的正确执行。
下面是一个简单的例子,演示了命令模式的应用。我们定义了一个 Command 接口,表示命令的行为,其中包含了一个 execute 抽象方法。然后我们创建了一个 Light 类,它包含了开灯和关灯的方法。接着,我们创建了一个 Switch 类,它包含了开关灯的方法,并使用命令模式将这些方法封装成了命令对象。
interface Command {
void execute();
}
class Light {
public void turnOn() {
System.out.println("开灯");
}
public void turnOff() {
System.out.println("关灯");
}
}
class TurnOnCommand implements Command {
private Light light;
public TurnOnCommand(Light light) {
this.light = light;
}
public void execute() {
light.turnOn();
}
}
class TurnOffCommand implements Command {
private Light light;
public TurnOffCommand(Light light) {
this.light = light;
}
public void execute() {
light.turnOff();
}
}
class Switch {
private Command turnOnCommand;
private Command turnOffCommand;
public Switch(Command turnOnCommand, Command turnOffCommand) {
this.turnOnCommand = turnOnCommand;
this.turnOffCommand = turnOffCommand;
}
public void turnOn() {
turnOnCommand.execute();
}
public void turnOff() {
turnOffCommand.execute();
}
}
public class Main {
public static void main(String[] args) {
Light light = new Light();
Command turnOnCommand = new TurnOnCommand(light);
Command turnOffCommand = new TurnOffCommand(light);
Switch lightSwitch = new Switch(turnOnCommand, turnOffCommand);
lightSwitch.turnOn();
lightSwitch.turnOff();
}
}
在上面的例子中,我们定义了一个 Command 接口,其中包含了一个 execute 方法。然后我们创建了一个 Light 类,它包含了开灯和关灯的方法。接着,我们创建了 TurnOnCommand 和 TurnOffCommand 类,它们实现了 Command 接口,并将 Light 对象作为构造函数的参数传入。最后,我们创建了一个 Switch 类,它包含了开关灯的方法,并将 TurnOnCommand 和 TurnOffCommand 对象作为构造函数的参数传入。
在 Switch 类中,我们定义了 turnOn 和 turnOff 方法,它们分别调用了 turnOnCommand 和 turnOffCommand 对象的 execute 方法,从而实现了开灯和关灯的操作。
在 Main 类中,我们创建了一个 Light 对象和两个命令对象 TurnOnCommand 和 TurnOffCommand,并将它们作为参数传入 Switch 对象的构造函数中。最后,我们调用了 Switch 对象的 turnOn 和 turnOff 方法,从而实现了开灯和关灯的操作。
在命令模式中,Switch 对象充当了请求的发起者和接收者之间的中介者,它负责将请求封装成命令对象,并将命令对象发送给请求的接收者。这样,请求的发送者和接收者之间就可以解耦,从而提高了代码的灵活性和可维护性。
Lambda表达式
Lambda表达式支持将代码块作为方法参数,Lambda表达式允许使用更简洁的代码来创建只有一个抽象方法的接口(这种接口被称为函数式接口)的实例。
Lambda表达式入门
对象与垃圾回收
finalize方法
在垃圾回收机制回收某个对象所占用的内存之前,通常要求程序调用适当的方法来清理资源,在没有明确指定清理资源的情况下,Java提供了默认机制来清理该对象的资源,这个机制就是finalize方法,该方法是定义在Object类里的实例方法。
当finalize方法返回后,对象消失,垃圾回收机制开始执行。方法原型中的throws Throwable表示它可以跑出任何类型的异常。
finalize方法具有如下4个特点:
- 永远不要主动调用某个对象的finalize方法,该方法应交给垃圾回收机制调用。
- finalize方法和时被调用,是否被调用具有不确定性,不要把finalize方法当成一定会被执行的方法。
- 当JVM执行可恢复对象的finalize方法时,可能使该对象或系统中其他对象重新变成可执行态。
- 当JVM执行finalize方法时出现异常时,垃圾回收机制不会报告异常,程序继续执行。
对象的软、弱和虚引用
Java语言对对象的引用有如下4种方式:
- 强引用:Java中最常见的引用方式,程序创建一个对象,并把这个对象赋值给一个引用变量,程序通过该引用变量来操作实际的对象,对象和数组都采用了这种强引用的方式,当一个对象被一个或一个以上的引用变量所引用时,它处于可达状态,不可能被系统垃圾回收机制回收。
- 软引用:软引用需要通过SoftReference类来实现,当一个对象只有软引用时,它有可能被垃圾回收机制回收,程序也可以使用该对象。对于只有软引用的对象而言,当系统内存空间不足时,系统可能会回收它。软引用通常用于对内存敏感的程序中。
- 弱引用:弱引用通过WeakReference类来实现,弱引用和软引用很像,但若引用的引用级别耕地。对于只有弱引用的对象而言,当系统垃圾回收机制运行时,不管内存是否足够,总会回收该对象所占用的内存。当然,并不是说当一个对象只有弱引用的时候,让就会被立即回收——正如那些失去引用的对象一样,必须等到系统垃圾回收机制运行的时候才会被回收
- 虚引用:虚引用通过PhantomReference类来实现,虚引用完全类似于没有引用。虚引用对对象本身没有太大影响,对象甚至感觉不到虚引用的存在,如果一个对象只有一个虚引用的时候,那么它和没有引用的效果大致相同。虚引用主要用于耿总对象被垃圾回收的状态,虚引用不能单独使用,虚引用必须和引用队列ReferenceQueue联合使用
上面三个引用类都包含了一个get方法,用于获取被它们引用的对象。
引用队列由java.lang.ref.ReferenceQueue类表示,它用于保存被回收后对象的引用。当联合使用软引用、弱引用和引用队列时,系统在回收被引用的对象之后,将把被回收对象对应的引用添加到关联的引用队列中。与软引用和弱引用不同的是,虚引用在对象被释放之前,将把它对应的虚引用添加到它关联的引用队列中,这可以在对象被回收之前采取行动。
软引用和弱引用九二一单独使用,但虚引用不能单独使用且单独使用毫无意义。
虚引用的主要作用就是可以让程序通过检查与虚引用的引用队列中是否已经包含了该虚引用,从而了解虚引用所引用的对象是否即将被回收。
第七章 Java基础类库
与用户互动
运行Java程序的参数
public static void main(String[] args){}//这是main方法的方法签名
- public修饰符:Java类由JVM调用,为了让JVM可以自由调用这个main方法,所以使用public修饰符把这个方法暴露出来
- static修饰符:JVM调用这个主方法的时候,不会先创建该类的对象,所以只能通过类方法调用
- void返回值:main方法返回值也是返回JVM,这没有任何意义,所以main方法没有返回值
还包括一个字符串数组形参,根据方法调用的规则:谁调用方法,谁负责为形参赋值。也就是说args由JVM赋值。
使用Scanner获取键盘输入
Scanner是一个基于正则表达式的文本扫描器,它可以从文件、输入流、字符串中解析出基本类型值和字符串值。Scanner类提供了多个构造器,不同的构造器可以接收文件、输入流、字符串作为数据源,用于从文件、输入流、字符串中解析数据。
Scanner主要提供了两个方法来扫描输入,
-
hasNextXXX():是否还有下一个输入项,其中XXX可以是int Long等代表基本数据类型的字符串。如果只是判断是否包含下一个字符串,就可以直接使用hasNext()。
-
nextXXX():获取下一个输入项。
在默认情况下Scanner使用 空格、Tab空白、回车,作为多个输入项之间的分隔符。
import java.util.Scanner;
public class StdinExample {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.print("Enter your name: ");
String name = scanner.nextLine();
System.out.print("Enter your age: ");
int age = scanner.nextInt();
System.out.println("Your name is " + name + " and your age is " + age);
scanner.close();
}
}
如果想要改变分隔符,可以使用useDelimiter(String pattern)方法即可,该方法的参数应该是一个正则表达式。
Scanner提供了两个简单的方法来进行行读取:
- boolean hasNextLine(): 返回输入源中是否还有下一行
- String nextLine(): 返回输入源中下一行的字符串
Scanner不仅可以获取字符串输入项,也可以获取任何基本类型的输入项。
系统相关
System类
System类代表当前Java程序运行的平台,程序不能创建System类的对象,System类提供了一些类变量和类方法,允许直接通过System类来调用这些类变量和类方法。
System类提供了代表标准输入、标准输出和错误输出的类变量,并提供了一些静态方法用于访问环境变量、系统属性的方法,还提供了加载文件和动态链接库的方法。
加载文件和动态链接库的方法主要对native方法有用,对于一些特殊的功能(如访问操作系统底层硬件设备等)Java程序无法实现,必须借助C语言来完成,此时需要使用C语言为Java方法提供实现,其实现步骤如下:
- Java程序中声明native修饰的方法,类似于abstract方法,只有方法签名,没有实现。使用带-h选项的javac命令编译该Java程序,降生成一个.class文件和一个.h文件。
- 写一个.cpp文件实现native方法,这一步需要包含第一步产生的.h文件(这个.h文件中又包含了JDK带的jni.h文件).
- 将第二步的.cpp文件编译成功动态链接库文件
- 在Java中用System的loadLibrary…()方法或Runtime类的loadLibrary()方法加载第三步产生的多年柜台链接库文件,Java程序中就可以调用这个native方法了。
常用类
Object类
是所有类、数组、枚举类的父类,也就是说,Java允许把素有类型的对象赋给Object类型的变量。当定义一个类时没有使用extends关键字为它显式指定父类,则该类默认继承Object父类。
Object类提供了如下几个常用方法:
- boolean equals(Objecct obj) :判断指定对象于该对象是否相等,如果直接调用比较的将是地址,所以如果想精准判断需要对该方法进行重写。
- protect
第八章 Java集合
Java集合概述
为了保存数量不确定的数据,以及保存具有映射关系的数据(也被称为关联数组),Java提供了集合类。集合类主要负责保存、盛装其他数据,因此集合类也被称为容器类。所有的集合类都位于java.util包下,后来为了处理多线程下的并发安全问题,Java 5还在java.util.concurrent包下提供了一些多线程支持的集合类。
集合类和数组不一样,数组元素既可以是基本类型的值,也可以是对象(实际上保存的是对象的引用变量),而集合里只能保存对象(实际上保存的是对象的引用变量)。
Java的集合类主要有两个接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口,这两个接口又包含了一些子接口或实现类。
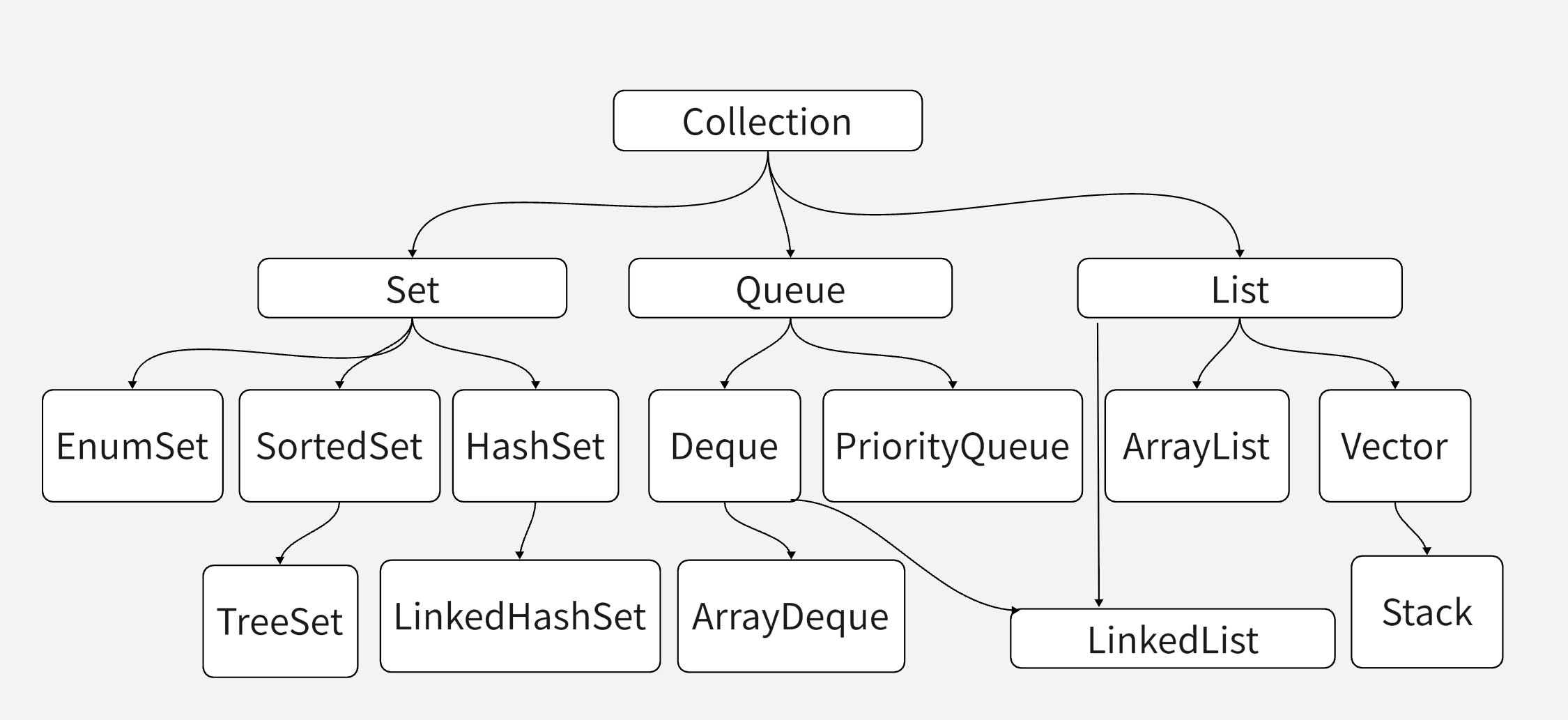
这是Collection体系里的集合,其中Set和List接口是Collection接口派生的两个子接口,他们分别代表了无序集合和有序集合;Queue是Java提供的队列实现,有点类似于List。
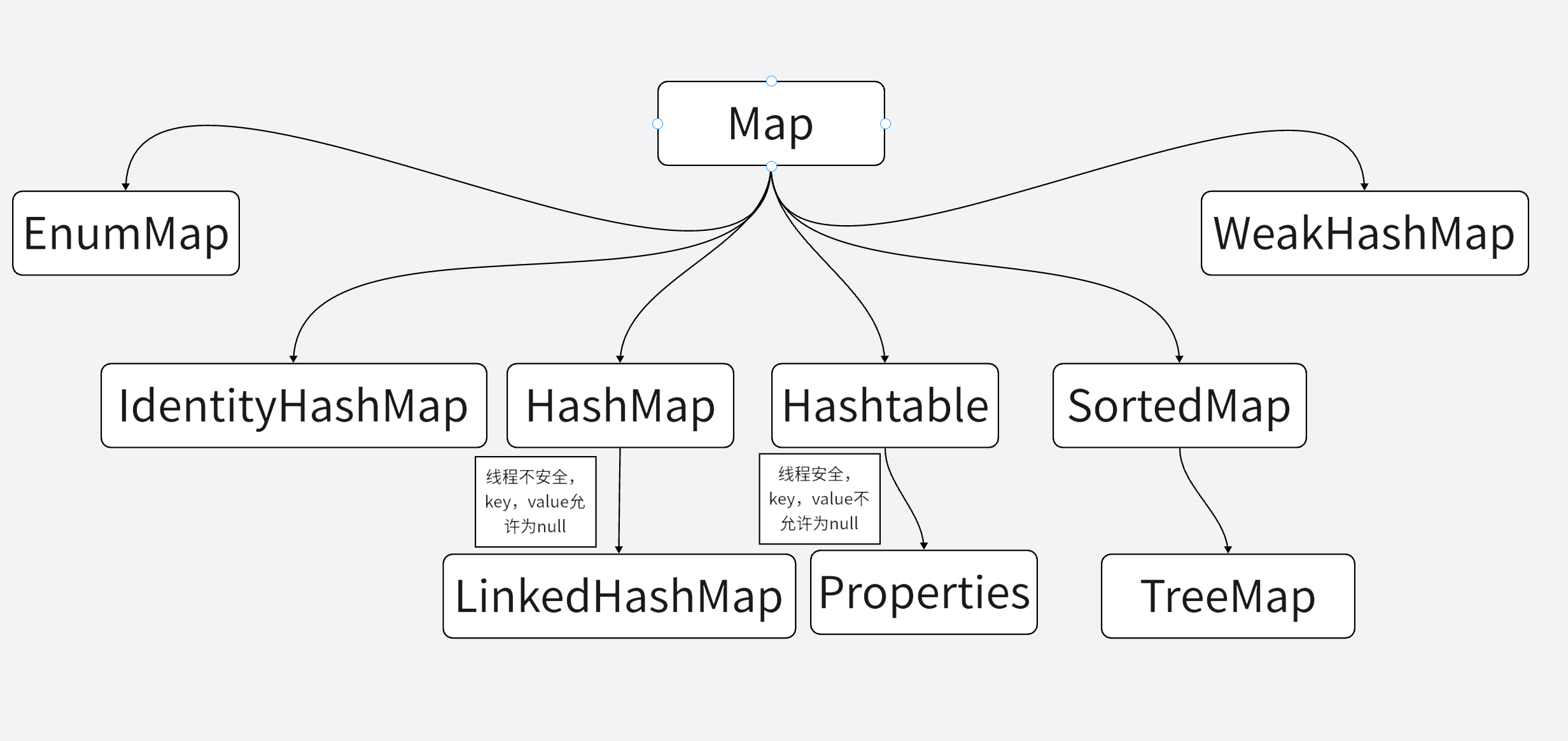
这是Map接口的众多实现类,这些实现类在功能、用法上存在一定差异,但它们都有一个功能特征:Map保存的每项数据都是key-value对,也就是有key-value两个之组成。Map中的key是不可重复的,key用于表示集合里的每项数据,如果需要查阅Map中的数据时,总是根据Map的key来获取。
Java中的集合可以分为三大类,Set集合类似于一个罐子,把一个对象添加到Set集合时,Set集合无法记住添加这个元素的顺序,所以
Set里的元素不能重复(否则系统无法准确识别这个元素);List集合非常像一个数组,它可以记住每次添加元素的顺序、且List的长度可变。Map集合也像一个罐子,只是它里面的每项数据都由两个值组成,
如果访问List集合中的元素,可以直接根据元素的索引来访问;如果访问Map集合中的元素,可以根据每项元素的key来访问其value;如果访问Set集合中的元素,则只能根据元素本身来访问。
对于Set、List、Queue和Map四种集合,最常用的实现类分别是HashSet,TreeSet,ArrayDeque,LinkedList,HashMap,TreeMap等类。
Collection 和 Iterator 接口
Collection接口是List、Set和Queue接口的父接口,该接口里定义的方法既可用于操作Set集合,也可用于操作List和Queue集合。Collection接口里定义了如下操作集合元素的方法:
- boolean add(Object o):该方法用于向集合里添加一个元 素。如果集合对象被添加操作改变了,则返回true。
- boolean addAll(Collection c):该方法把集合c里的所有元 素添加到指定集合里。如果集合对象被添加操作改变了,则返 回true。
- void clear():清除集合里的所有元素,将集合长度变为0。
- boolean contains(Object o):返回集合里是否包含指定元 素。
- boolean containsAll(Collection c):返回集合里是否包含 集合c里的所有元素。
- boolean isEmpty():返回集合是否为空。当集合长度为0时返 回true,否则返回false。
- Iterator iterator():返回一个Iterator对象,用于遍历集 合里的元素。
- boolean remove(Object o):删除集合中的指定元素o,当集 合中包含了一个或多个元素o时,该方法只删除第一个符合条件 的元素,该方法将返回true。
- boolean removeAll(Collection c):从集合中删除集合c里包 含的所有元素(相当于用调用该方法的集合减集合c),如果删 除了一个或一个以上的元素,则该方法返回true。
- boolean retainAll(Collection c):从集合中删除集合c里不 包含的元素(相当于把调用该方法的集合变成该集合和集合c的 交集),如果该操作改变了调用该方法的集合,则该方法返回 true。
- int size():该方法返回集合里元素的个数。
- Object[] toArray():该方法把集合转换成一个数组,所有的 集合元素变成对应的数组元素。
使用Lambda表达式遍历集合
Java 8为Iterable接口新增了一个forEach(Consumer action)默 认方法,该方法所需参数的类型是一个函数式接口,而Iterable接口是Collection接口的父接口,因此Collection集合也可直接调用该方法。
当程序调用Iterable的forEach(Consumer action)遍历集合元素 时,程序会依次将集合元素传给Consumer的accept(T t)方法(该接口 中唯一的抽象方法)。正因为Consumer是函数式接口,因此可以使用 Lambda表达式来遍历集合元素。
使用Lambda表达式来遍历集合元素可以大大简化代码,使代码更加精简、易读和易于维护。下面是一个示例,演示了如何使用Lambda表达式来遍历一个字符串列表,并将每个字符串全部转换为大写字母:
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("Alice");
names.add("Bob");
names.add("Charlie");
names.add("David");
names.add("Eve");
names.forEach(name -> System.out.println(name.toUpperCase()));
}
}
在上面的代码中,我们首先创建了一个字符串列表 names,并向其中添加了几个字符串。接着,我们使用 forEach 方法来遍历该列表,该方法接受一个 Lambda 表达式作为参数。Lambda 表达式 name -> System.out.println(name.toUpperCase()) 表示将列表中的每个字符串转换为大写字母,并输出到控制台上。
使用 Lambda 表达式来遍历集合元素可以让代码更加简洁和易读,同时也可以提高代码的性能,因为它可以更好地利用多核处理器的能力来进行并行处理。
使用Iterator遍历集合元素
Iterator接口也是Java集合框架的成员,但它与Collection系列、Map系列的集合不一样:Collection系列集合、Map系列集合主要 用于盛装其他对象,而Iterator则主要用于遍历(即迭代访问) Collection集合中的元素,Iterator对象也被称为迭代器。
Iterator接口隐藏了各种Collection实现类的底层细节,向应用程序提供了遍历Collection集合元素的统一编程接口。Iterator接口 里定义了如下4个方法。
- boolean hasNext():如果被迭代的集合元素还没有被遍历 完,则返回true。
- Object next():返回集合里的下一个元素。
- void remove():删除集合里上一次next方法返回的元素。
- void forEachRemaining(Consumer action),这是Java 8为 Iterator新增的默认方法,该方法可使用Lambda表达式来遍历集合元素
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("Alice");
names.add("Bob");
names.add("Charlie");
Iterator<String> iterator = names.iterator();
while (iterator.hasNext()) {
String name = iterator.next();
System.out.println(name);
}
}
}
从上面代码中可以看出,Iterator仅用于遍历集合,Iterator本 身并不提供盛装对象的能力。如果需要创建Iterator对象,则必须有 一个被迭代的集合。没有集合的Iterator仿佛无本之木,没有存在的 价值。
Iterator必须依附于Collection对象,若有一个Iterator对 象,则必然有一个与之关联的Collection对象。Iterator提供了两 个方法来迭代访问Collection集合里的元素,并可通过remove()方 法来删除集合中上一次next()方法返回的集合元素。
当使用Iterator迭代访问Collection集合元素时,Collection集 合里的元素不能被改变,只有通过Iterator的remove()方法删除上一 次 next() 方 法 返 回 的 集 合 元 素 才 可 以 ; 否 则 将 会 引 发 java.util.Concurrent ModificationException异常。
Iterator迭代器采用的是快速失败(fail-fast)机制,一旦在迭 代过程中检测到该集合已经被修改(通常是程序中的其他线程修 改),程序立即引发ConcurrentModificationException异常,而不是 显示修改后的结果,这样可以避免共享资源而引发的潜在问题。
使用Lambda表达式遍历Iterator
Java 8 为 Iterator 新 增 了 一 个 forEachRemaining(Consumer action)方法,该方法所需的Consumer参数同样也是函数式接口。当程 序调用Iterator的forEachRemaining(Consumer action)遍历集合元素 时,程序会依次将集合元素传给Consumer的accept(T t)方法(该接口 中唯一的抽象方法。
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Iterator<Integer> iterator = numbers.iterator();
iterator.forEachRemaining(number -> System.out.println(number));
}
}
上面程序中粗体字代码调用了Iterator的forEachRemaining()方 法来遍历集合元素,传给该方法的参数是一个Lambda表达式,该 Lambda表达式的目标类型是Comsumer,因此上面代码也可用于遍历集 合元素。
使用foreach循环遍历集合元素
除可使用Iterator接口迭代访问Collection集合里的元素之外, 使用Java 5提供的foreach循环迭代访问集合元素更加便捷。如下程序 示范了使用foreach循环来迭代访问集合元素。
import java.util.Arrays;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
for (Integer number : numbers) {
System.out.println(number);
}
}
}
上面代码使用foreach循环来迭代访问Collection集合里的元素更 加简洁,这正是JDK 1.5的foreach循环带来的优势。与使用Iterator 接口迭代访问集合元素类似的是,foreach循环中的迭代变量也不是集 合元素本身,系统只是依次把集合元素的值赋给迭代变量,因此在 foreach循环中修改迭代变量的值也没有任何实际意义。
同样,当使用foreach循环迭代访问集合元素时,该集合也不能被改变,否则将引发Concurrent ModificationException异常。
使用Predicate操作集合
Predicate是Java中的一个函数式接口,用于表示一个输入参数的布尔型测试。在集合操作中,我们可以使用Predicate来过滤集合中的元素,只保留符合条件的元素。以下是一个示例,演示了如何使用Predicate过滤一个字符串列表中的元素:
import java.util.Arrays;
import java.util.List;
import java.util.function.Predicate;
public class Main {
public static void main(String[] args) {
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David", "Eva");
Predicate<String> startsWithA = name -> name.startsWith("A");
Predicate<String> endsWithVowel = name -> "AEIOUaeiou".indexOf(name.charAt(name.length() - 1)) >= 0;
names.stream()
.filter(startsWithA.and(endsWithVowel))
.forEach(System.out::println);
}
}
/*
.forEach(System.out::println) 是Java 8中新增的一种遍历方式,用于将集合中的元素逐个输出到标准输出流(控制台)上。
在Java 8之前,我们需要使用for循环或迭代器来遍历集合元素,并手动将每个元素输出到控制台上。而在Java 8中,我们可以使用Lambda表达式和方法引用来简化代码,使得遍历集合元素更加方便和易读。.forEach(System.out::println) 就是其中的一种方式,它使用方法引用的方式将控制台输出流的println方法作为Lambda表达式的主体,从而将集合中的每个元素输出到控制台上。
以下是一个示例,演示了如何使用.forEach(System.out::println)输出一个整数列表中的元素:
import java.util.Arrays;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.forEach(System.out::println);
}
}
在上面的代码中,我们首先创建了一个整数列表 numbers,并向其中添加了几个整数。接着,我们使用 .forEach(System.out::println) 将整数列表中的每个元素输出到控制台上。
需要注意的是,.forEach(System.out::println) 方法只能用于遍历集合元素,并将元素输出到控制台上。如果需要对集合元素进行其他操作,例如筛选、映射、聚合等,需要使用其他的集合操作方法,例如 filter()、map()、reduce() 等。
*/
在上面的代码中,我们首先创建了一个字符串列表 names,并向其中添加了几个字符串。接着,我们定义了两个Predicate对象 startsWithA和 endsWithVowel,分别表示字符串以字母“A”开头和以元音字母结尾的条件。接着,我们使用 stream() 方法将列表转换为流,并使用 filter() 方法过滤符合条件的元素。在本例中,我们使用 and() 方法将两个Predicate对象进行逻辑与操作,同时满足两个条件才能通过过滤。最后,我们使用 forEach() 方法将过滤后的结果输出到控制台上。
在集合操作中,使用Predicate可以使代码更加简洁易读,同时也可以提高代码的可重用性和可维护性。需要注意的是,Predicate是一个函数式接口,可以使用Lambda表达式或方法引用来创建Predicate对象。此外,Predicate还可以和其他函数式接口(例如Function、Consumer等)结合使用,实现更加复杂的集合操作。
使用Stream操作集合
Java 8还新增了Stream、IntStream、LongStream、DoubleStream 等流式API,这些API代表多个支持串行和并行聚集操作的元素。上面4 个接口中,Stream是一个通用的流接口,而IntStream、LongStream、 DoubleStream则代表元素类型为int、long、double的流。
Java 8 还 为 上 面 每 个 流 式 API 提 供 了 对 应 的 Builder , 例 如 Stream.Builder 、 IntStream.Builder 、 LongStream.Builder 、 DoubleStream.Builder,开发者可以通过这些Builder来创建对应的 流。
独立使用Stream的步骤如下:
①使用Stream或XxxStream的builder()类方法创建该Stream对应 的Builder。
②重复调用Builder的add()方法向该流中添加多个元素。
③调用Builder的build()方法获取对应的Stream。
④调用Stream的聚集方法。
在上面4个步骤中,第4步可以根据具体需求来调用不同的方法, Stream提供了大量的聚集方法供用户调用,具体可参考Stream或 XxxStream的API文档。对于大部分聚集方法而言,每个Stream只能执行一次。
Java Stream 的主要特点是:
- Stream 不会修改原始数据源,而是通过一系列的操作(如过滤、映射、排序、汇聚等)生成新的 Stream,并最终生成想要的结果;
- Stream 操作可以进行流水线式的操作,即一条语句中可以包含多个 Stream 操作,这样可以在遍历数据集合时尽量减少迭代次数,提高性能;
- Stream 操作可以并行执行,利用多核处理器的特性,提高处理大规模数据集合的效率。
Java Stream 的使用方式比较灵活,可以通过方法引用、Lambda 表达式等方式来定义 Stream 操作,同时也提供了丰富的操作方法,如 filter、map、reduce 等,可以满足不同场景下的数据处理需求。
以下是一个使用 Java Stream 进行数据处理的例子:
假设有一个整数列表,需要对其中的偶数进行过滤,并计算所有偶数的平方和。可以使用 Java Stream 的 filter 和 map 方法来实现
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
int sumOfSquaresOfEvenNumbers = numbers.stream()
.filter(n -> n % 2 == 0) // 过滤偶数
.map(n -> n * n) // 计算平方
.reduce(0, Integer::sum); // 汇聚求和
System.out.println(sumOfSquaresOfEvenNumbers); // 输出 220
在上述代码中,首先将整数列表转换成 Stream,然后使用 filter 方法过滤偶数,再使用 map 方法计算平方,最后使用 reduce 方法将所有平方数求和。这里使用了 Lambda 表达式来定义 Stream 操作,代码简洁且易于理解。
Java Stream 提供了丰富的操作方法,可以满足不同场景下的数据处理需求。以下是常用的 Stream 操作方法及其功能解析:
- filter(Predicate predicate):根据给定的条件过滤 Stream 中的元素,只保留符合条件的元素。
例如,过滤整数列表中的偶数可以这样实现:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> evenNumbers = numbers.stream().filter(n -> n % 2 == 0).collect(Collectors.toList());
- map(Function<T, R> mapper):对 Stream 中的每个元素执行给定的操作,并将结果映射成一个新的元素。
例如,将整数列表中的每个元素平方可以这样实现:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> squares = numbers.stream().map(n -> n * n).collect(Collectors.toList());
- flatMap(Function<T, Stream> mapper):对 Stream 中的每个元素执行给定的操作,并将结果扁平化为一个新的 Stream。
例如,将字符串列表中的每个元素拆分成单词并去重可以这样实现:
List<String> words = Arrays.asList("hello world", "hello java", "world java");
List<String> uniqueWords = words.stream()
.flatMap(line -> Arrays.stream(line.split(" ")))
.distinct()
.collect(Collectors.toList());
- distinct():去除 Stream 中重复的元素。
例如,从整数列表中去除重复元素可以这样实现:
List<Integer> numbers = Arrays.asList(1, 2, 3, 2, 4, 1, 5, 3);
List<Integer> distinctNumbers = numbers.stream().distinct().collect(Collectors.toList());
- sorted():对 Stream 中的元素进行排序,默认升序排序。
例如,对整数列表进行升序排序可以这样实现:
List<Integer> numbers = Arrays.asList(3, 1, 4, 1, 5, 9, 2, 6, 5, 3);
List<Integer> sortedNumbers = numbers.stream().sorted().collect(Collectors.toList());
- reduce(T identity, BinaryOperator accumulator):对 Stream 中的所有元素进行汇聚操作,将所有元素按照给定的方式合并成一个结果。
例如,计算整数列表中所有元素的和可以这样实现:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
int sum = numbers.stream().reduce(0, (a, b) -> a + b);
- forEach(Consumer action):对 Stream 中的每个元素执行给定的操作。
例如,输出整数列表中的每个元素可以这样实现:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
numbers.stream().forEach(System.out::println);
以上仅是常用的 Stream 操作方法之一,Java Stream 还提供了其他丰富的操作方法,比如 findFirst、count、max、min 等,可以根据不同的需求选择使用。
Set集合
Set集合类似于一个罐子,可以把多个对象放入,但Set集合不能记住元素的添加顺序,Set没有提供任何的额外方法,实际上与Collection 基本相同,只是在行为上Set不允许包含重复元素。
Set集合不允许包含相同的元素,如果试图把两个相同的元素加入同一个Set集合中,则添加失败。
HashSet类
HashSet按照Hash算法来储存集合中的元素,具有很好的储存和查找性能。
特点:
- 不能保证元素的排列顺序,顺序可能与添加顺序不同。
- HashSet不是同步的,如果多个线程同时访问同一个HashSet,假设有两个或者两个以上同时修改了HashSet集合时,则必须通过代码来保证其同步
- 集合元素值可以是null
当向HashSet集合中存入一个元素时,HashSet会调用该对象的 hashCode()方法来得到该对象的hashCode值,然后根据该hashCode值 决定该对象在HashSet中的存储位置。
如果有两个元素通过equals方法比较返回true,但它们的hashCode方法返回值不同,HashSet将会把它们储存在不同的位置时,依然可以添加成功。
如果两个对象的hashCode()方法返回的hashCode值相同,但它们 通过equals()方法比较返回false时将更麻烦:因为两个对象的 hashCode值相同,HashSet将试图把它们保存在同一个位置,但又不行 (否则将只剩下一个对象),所以实际上会在这个位置用链式结构来 保存多个对象;而HashSet访问集合元素时也是根据元素的hashCode值 来快速定位的,如果HashSet中两个以上的元素具有相同的hashCode 值,将会导致性能下降。
也就是说,HashSet集合判断两个元素相等的标准是两个对象通过 equals()方法比较相等,并且两个对象的hashCode()方法返回值也相等。
HashSet中每个能存储元素的“槽位”(slot)通常称为“桶”。
当程序把可变对象添加到HashSet中之后,不要再去修改该集合元素中参与计算hashCode()、equals()的实例变量,将会导致HashSet无法正确操作这些集合元素
LinkedHashSet类
HashSet还有一个子类LinkedHashSet,LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护 元素的次序,这样使得元素看起来是以插入的顺序保存的。也就是 说,当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元 素的添加顺序来访问集合里的元素。 LinkedHashSet 需 要 维 护 元 素 的 插 入 顺 序 , 因 此 性 能 略 低 于 HashSet的性能,但在迭代访问Set里的全部元素时将有很好的性能, 因为它以链表来维护内部顺序。
输出LinkedHashSet集合的元素时,元素的顺序总是与添加顺序一 致。
TreeSet类
TreeSet是SortSet接口的实现类,它可以确保集合元素处于排序状态。与HashSet相比,TreeSet还提供了如下几个额外的方法:
- Comparator comparatoe():如果TreeSet采用了定制排序,则该方法返回定制排序所使用的Comparator;如果TreeSet采用了自然排序,则返回null。
- Object first():返回集合中的第一个元素。
- Object last():返回集合中的最后一个元素。
- Object lower(Object e):返回集合中位于指定元素之前的元素(及小鱼指定元素的最大元素,参考元素不需要是TreeSet集合里的元素)。
- Object higher(Object e):返回集合中位于指定元素之后的元素(及大于指定元素的最小元素,参考元素不需要是TreeSet里的元素)。
- SortedSet subSet(Object fromElement, Object toElement):返回此Set的自己和,范围从fromElement(包 含)到toElement(不包含)。
- SortedSet headSet(Object toElement):返回此Set的子集, 由小于toElement的元素组成。
- SortedSet tailSet(Object fromElement):返回此Set的子 集,由大于或等于fromElement的元素组成。
TreeSet采用红黑树的数据结构来存储集合元素。
TreeSet支持两种排序方法:自然排序和定制排序。在默认情况下,TreeSet采用自然排序。
1.自然排序
TreeSet会调用集合元素的compareTo(Object obj)方法来比较元 素之间的大小关系,然后将集合元素按升序排列,这种方式就是自然排序。
Java提供了一个Comparable接口,该接口里定义了一个comparaTo( Object obj)方法,该方法返回一个整数值,实现该接口的类必须实现该方法,实现了该接口的类的对象就可以比较大小,当一个对象调用该方法与另一个对象进行比较时,例如obj1.compareTo(obj2),如果该方法返回0,则表明这两个对象相等; 如果该方法返回一个正整数,则表明obj1大于obj2;如果该方法返回 一个负整数,则表明obj1小于obj2。
Java的一些常用类已经实现了Comparable接口,并提供了比较大 小的标准。
下面是实现了Comparable接口的常用类。
➢ BigDecimal、BigInteger以及所有的数值型对应的包装类:按 它们对应的数值大小进行比较。
➢ Character:按字符的Unicode值进行比较。
➢ Boolean:true对应的包装类实例大于false对应的包装类实 例。
➢ String:依次比较字符串中每个字符的Unicode值。
➢ Date、Time:后面的时间、日期比前面的时间、日期大。
如果试图把一个对象添加到TreeSet时,则该对象的类必须实现 Comparable接口,否则程序将会抛出异。
如果希望TreeSet能正常运作,TreeSet只能 添加同一种类型的对象。
一旦改变了TreeSet集合里可变元素的实例变量,当再试图删除该 对象时,TreeSet也会删除失败(甚至集合中原有的、实例变量没被修 改但与修改后元素相等的元素也无法删除)。
当可变对象的实例变量被修改时,TreeSet在处理 这些对象时将非常复杂,而且容易出错。为了让程序更加健壮,推 荐不要修改放入HashSet和TreeSet集合中元素的关键实例变量。
2.定制排序
TreeSet 是一个基于红黑树实现的集合类,它可以自动将元素按照自然顺序排序或者使用指定的 Comparator 进行排序。如果你需要对 TreeSet 进行定制排序,你可以通过实现 Comparator 接口来指定比较规则。
Comparator 接口有一个 compare(T o1, T o2) 方法,它用于比较两个对象的大小。该方法返回一个整数值,如果 o1 的大小小于 o2 的大小,则返回负数,如果 o1 的大小等于 o2 的大小,则返回 0,如果 o1 的大小大于 o2 的大小,则返回正数。
例如,假设我们有一个 Student 类,它有两个属性:name 和 score。我们想要按照 score 从大到小的顺序对 Student 对象进行排序,可以这样实现 Comparator 接口:
public class ScoreComparator implements Comparator<Student> {
@Override
public int compare(Student s1, Student s2) {
return s2.getScore() - s1.getScore();
}
}
然后我们可以通过传入 ScoreComparator 对象来对 TreeSet 进行定制排序:
Set<Student> set = new TreeSet<>(new ScoreComparator());
set.add(new Student("Alice", 90));
set.add(new Student("Bob", 80));
set.add(new Student("Charlie", 95));
这样,set 中的元素就会按照 score 从大到小的顺序排列。
使用 Lambda 表达式可以非常方便地对 TreeSet 进行定制排序。
Set<Student> set = new TreeSet<>((s1, s2) -> s2.getScore() - s1.getScore());
set.add(new Student("Alice", 90));
set.add(new Student("Bob", 80));
set.add(new Student("Charlie", 95));
EnumSet类
EnumSet是专为枚举类设计的集EnumSet的集合元素也是有序的,EnumSet以枚举值在Enum类的定义顺序来决定集合元素的顺序。
EnumSet在内部以位向量的形式储存,这种存储形式非常紧凑、高效,因此EnumSet对象占用内存很小,而且运行效率很好。尤其时进行批量操作(如调用containsAll() 和retainAll()方法)时,如果其参数也时EnumSet集合,则该批量操作的执行速度也非常快。
EnumSet集合不允许加入null元素,如果试图插入null元素,EnumSet将抛出NullPointerException异常。。如果只是想判断EnumSet 是否包含null元素或试图删除null元素都不会抛出异常,只是删除操作将返回false,因为没有任何null元素被删除。
EnumSet类没有暴露任何构造器来创建该类的实例,程序应该通过 它提供的类方法来创建EnumSet对象。EnumSet类它提供了如下常用的 类方法来创建EnumSet对象。
- allOf(Class elementType): 创建一个包含指定枚举类里所有枚举值的EnumSet集合。
- complementOf(EnumSet s):创建一个其元素类型与指定EnumSet里元素类型相同的EnumSet集合,新EnumSet集合包含原EnumSet集合所不包含的、此枚举类剩下的枚举值(即新EnumSet集合和原EnumSet集合的集合元素加起来就是该枚举类的所有枚举值)
- copyOf(Collection c):使用一个普通集合来创建EnumSet集合。
- copyOf(EnumSet s):创建一个与指定EnumSet具有相 同元素类型、相同集合元素的EnumSet集合。
- noneOf(Class elementType):创建一个元素类型为 指定枚举类型的空EnumSet。
- of(E first, E…rest):创建一个包含一个或多个 枚举值的EnumSet集合,传入的多个枚举值必须属于同一个枚举类。
- range(E from, E to):创建一个包含从from枚举值 到to枚举值范围内所有枚举值的EnumSet集合。
各Set实现类的性能分析
HashSet的性能总是比TreeSet好(特别是最常用的添 加、查询元素等操作),因为TreeSet需要额外的红黑树算法来维护集 合元素的次序。只有当需要一个保持排序的Set时,才应该使用 TreeSet,否则都应该使用HashSet。
HashSet还有一个子类:LinkedHashSet,对于普通的插入、删除 操作,LinkedHashSet比HashSet要略微慢一点,这是由维护链表所带 来的额外开销造成的,但由于有了链表,遍历LinkedHashSet会更快
EnumSet是所有Set实现类中性能最好的,但它只能保存同一个枚举类的枚举值作为集合元素。
EnumSet是所有Set实现类中性能最好的,但它只能保存同一个枚 举类的枚举值作为集合元素。
必须指出的是,Set的三个实现类HashSet、TreeSet和EnumSet都 是线程不安全的。如果有多个线程同时访问一个Set集合,并且有超过 一个线程修改了该Set集合,则必须手动保证该Set集合的同步性。通 常可以通过Collections工具类的synchronizedSortedSet方法来 “包装” 该Set集合。此操作最好在创建时进行,以防止对Set集合的意外 非同步访问。
Set<String> set = new HashSet<>();
Set<String> synchronizedSet = Collections.synchronizedSet(set);
上面的代码创建了一个 HashSet 对象,并使用 synchronizedSet() 方法将其包装成一个同步的 Set 集合。然后,可以在多线程环境下访问 synchronizedSet,而不用担心线程安全问题。
需要注意的是,虽然使用 synchronizedSet() 方法可以确保线程安全,但它会带来一定的性能开销。因此,在单线程环境下,不建议使用同步的 Set 集合,可以直接使用原生的 HashSet、TreeSet 或 EnumSet。只有在多线程环境下,才需要考虑使用同步的 Set 集合。
List集合
List集合代表一个元素有序、可重复的集合,集合中每个元素都有其对应的顺序索引。List集合允许使用重复元素,可以通过索引来访问指定位置的集合元素。List集合默认按元素的添加顺序设置元素的索引。
改进的List接口和ListIterator接口
List集合里增加了一些根据索引来操作集合元素的方法。
- add(int index, Object element):将元素element插入到List集合的index处。
- addAll(int index, Collection c):将集合c所包含的所有元素都插入到List集合的index处。
- get(int index):返回集合index索引处的元素。
- indexOf(Object o):返回对象o在List集合中第一次出现的位置索引。
- lastIndexOf(Object o):返回对象o在List集合中最后一次出现的位置索引。
- remove(int index):删除并返回index索引处的元素。
- set(int index, Object element):将index索引处的元素替换成element对象,返回被替换的旧元素。
- List subList(int fromIndex, int toIndex):返回从索引fromIndex(包含)到索引toIdex(不包含)处所有集合元素组成的子集和。
- replaceAll(UnaryOperator operator):根据operator 指定的计算规则重新设置List集合的所有元素。
- sort(Comparator c):根据Comparator参数对List集合 的元素排序。
ListIterator
是 Iterator 的子接口,它在 Iterator 的基础上提供了更多的遍历操作,例如向前遍历、修改元素、添加元素等。ListIterator 只能用于 List 集合,因为它需要支持随机访问和修改元素的操作。
ListIterator 接口定义了一些额外的方法,例如:
boolean hasPrevious():判断是否还有上一个元素可以遍历;E previous():返回上一个元素,并将指针向前移动一位;int nextIndex():返回下一个元素的索引;int previousIndex():返回上一个元素的索引;void set(E element):用新元素替换最近返回的元素;void add(E element):在最近返回的元素后面插入一个元素。
使用 ListIterator 遍历 List 的基本流程如下:
List<String> list = new ArrayList<>();
// 添加元素
ListIterator<String> iterator = list.listIterator();
while (iterator.hasNext()) {
String element = iterator.next();
// 处理元素
}
上面的代码使用 ArrayList 来演示了如何使用 ListIterator 遍历 List。首先通过调用 listIterator() 方法获取一个 ListIterator 对象,然后使用 while 循环和 hasNext()、next() 方法来遍历 List 中的元素。在循环中,每次调用 next() 方法都会返回下一个元素,并将指针移动到下一个位置。
需要注意的是,**ListIterator 可以向前遍历 List,但是在遍历过程中不能修改 List 的大小,**否则会抛出 ConcurrentModificationException 异常。如果需要在遍历 List 的同时修改 List,可以使用 List 接口提供的其他方法,例如 add()、remove() 等。
ArrrayList和Vector实现类
ArrayLsit和Vector最为List类的两个典型实现,完全支持前面介绍的List接口的全部功能。
ArrayList和Vector类都是基于数组实现的List类,所以ArrayList和Victor类封装了一个动态的、允许再分配的Object[]数组。
ArrayList或Vector对象使用initialCapacity参数来设置该数组 的长度,当向ArrayList或Vector中添加元素超出了该数组的长度时, 它们的initialCapacity会自动增加。
对于通常的编程场景,程序员无须关心ArrayList或Vector的 initialCapacity。但如果向ArrayList或Vector集合中添加大量元素 时,可使用ensureCapacity(int minCapacity)方法一次性地增加 initialCapacity。这可以减少重分配的次数,从而提高性能。
如 果 创 建 空 的 ArrayList或Vector集合时不指定initialCapacity参数,则Object[] 数组的长度默认为10。
ArrayList和Vector还提供了如下两个方法来重新分配Object[]数组
-
ensureCapacity(int minCapacity) : 将 ArrayList 或 Vector集合的Object[]数组长度增加大于或等于minCapacity 值;
-
trimToSize():调整ArrayList或Vector集合的Object[] 数组长度为当前元素的个数。调用该方法可减少ArrayList或 Vector集合对象占用的存储空间。
Vector的系列方法中方法名更短的方法属于后来新增的方法。方法名更长的方法则是Vector原有的方法。Java改写了Vector原有的方法,将其方法名缩短是为了简化编程。
实际上,Vector具有很多缺点,通常尽量少用Vector实现类
区别
Vector 和 ArrayList 都是 Java 集合框架中的 List 实现类,它们都可以存储一组有序的元素,并提供了一系列对元素进行添加、删除、查找等操作的方法。但是它们之间也存在一些差异,主要包括以下几点:
- 线程安全性:Vector 是线程安全的,而 ArrayList 不是。Vector 内部使用同步方法来保证线程安全,但是这会带来一些性能上的开销。而 ArrayList 不是线程安全的,如果需要在多线程环境下使用 ArrayList,需要使用同步措施来保证线程安全。
- 扩容机制:Vector 和 ArrayList 在扩容机制上也存在差异。Vector 扩容时,会将原数组的容量增加一倍,而 ArrayList 扩容时,会将原数组的容量增加一半。这也意味着,Vector 在扩容时可能会浪费更多的内存空间。
- 性能问题:由于 Vector 内部使用同步方法来保证线程安全,因此在单线程环境下,它的性能可能会比 ArrayList 差。此外,由于 Vector 和 ArrayList 都是基于数组实现的,它们在插入或删除元素时,需要对数组进行移动操作,这会带来一定的时间开销。
- 其他方面:Vector 和 ArrayList 还存在一些其他方面的差异。例如,Vector 支持在任意位置插入和删除元素,而 ArrayList 只支持在末尾插入和删除元素。此外,Vector 还提供了一些特有的方法,例如 elementAt()、firstElement()、lastElement() 等。
综上所述,Vector 和 ArrayList 都有各自的优缺点。如果需要在多线程环境下使用 List,可以考虑使用 Vector;如果在单线程环境下使用 List,可以考虑使用 ArrayList,因为它的性能可能会更好。
Vector还提供了一个Stack子类,可以用于模拟栈,但是这是一个非常古老的Java集合类,它同样是线程安全的、性能较差的,可以使用ArrayDeque来代替它。
固定长度的List
前面将数组的时候介绍了一个操作数组的工具类:Arrays,该工具类提供了asList方法们该方法可以把一个数组或指定个数的对象转换成一个List集合,这个List集合既不是ArrayList实现类的实例,也不是Vector实现类的实例,而是Arrays的内部类ArrayList的实例。
Arrays.ArrayList是一个固定长度的List集合,程序只能便利访问该集合里的元素,不可增加、删除该集合里的元素。
Queue集合
Queue集合用于模拟队列这种数据结构,队列通常是指“先进先出”(FIFO)的容器。队列的头部保存在队列中存放时间最长的元素,队列的尾部保存在队列中存放时间最短的元素。新元素插入(offer)到队列的尾部,访问元素(poll)操作会返回队列头部的元素。
Queue接口中定义了如下几个方法:
- void add(Object e):就昂指定元素加入此队列的尾部。
- Object element() :获取队列头部的元素,但是不删除该元素。
- boolean offer(Object e):将指定顶元素加入此队列的尾部,当使用有容量限制的队列时,此方法比add方法更好
- Object peek:获取队列头部的元素,但是不删除该元素,如果此队列为空,返回null。
- Object poll:获取队列头部的元素,并删除,为空则返回null。
- Object remove:获取的队列头部的元素,并删除该元素。
Queue接口有一个PriorityQueue实现类。除此之外,Queue还有一个Deque接口,Dequed爱表一个“双端队列”,双端队列可以同时从两端来添加、删除元素,因此Deque的实现类即可当成队列使用,也可当成栈使用。
PriorityQueue实现类
PriorityQueue是基于优先级的队列,并不是一个标准的队列实现类,因为它保存队列元素的顺序并不是按加入队列的顺序,而是按队列元素的大小进行重新排序。因此当调用peek方法或者poll方法取出队列中的元素的时候,并不是去除最先进入队列的元素,而失去出队列中最小的元素,这已经违反了队列的先进先出的基本原则。
PriorityQueue不允许插入null元素,还需要对队列元素进行排序,依然是两种排序,自然排序和定制排序。
- 自然排序:采用自然排序的集合中的元素必须实现了Comparable接口,而且应该是同一个类的多个实例,否则可能导致ClassCastException异常。
- 定制排序:创建队列的时候,传入一个Comparator对象,该对象负责对队列中的所有原不俗进行排序。采用定制排序时不要求队列元素实现Comparable接口。
其他要求与TreeSet基本一致。
Deque接口与ArrayDeque实现类
Deque接口是Queue接口的子接口,它代表一个双端队列,Deque接口里定义了一些双端队列的方法,这些方法允许从两端来操作队列的元素。
Deque不仅可以当成双端队列使用,而且可以被当成栈来使用,因为该类里还包含了pop、push两个栈方法。
Deque接口提供了一个典型的实现类,ArrayDeque,它是一个基于数组实现的双端队列,创建Deque的时候同样可以指定一个numElements参数,该参数指定Objecct[]数组的长度,如果不指定该参数,Deque底层数组的长度为16.
LinkedList实现类
双向链表
LinkedList类是List接口的实现类——这意味着它是一个List集合,可以根据索引来随机访问集合中的元素。除此之外,LinkedList还实现了Deque接口,可以被当成双端队列来使用,因此既可以被当成栈,又可以被当成队列。
LinkedList与ArrayList、ArrayDeque的实现机制完全不同,ArrayList、ArrayDeque内部以数组的形式来保存集合中的元素,因此随机访问集合元素时有较好的性能;而LinkedList内部以链表的形式来保存集合中的元素,随即访问的时候效率就会较差,但在插入、删除性能比较出色。
各种线性表的性能分析
- 如果需要遍历List集合元素,对于ArrayList、Vector集合,应该是用随机访问方法来遍历集合元素,对于LinkedList集合,则应该采用迭代器(Iterator)来遍历集合元素。
- 如果需要经常执行插入、删除操作来改变包含大量数据的List集合的大小,可考虑使用LinkedList。使用其他的是需要经常重新分配内部数组的大小,效果可能较差。
- 如果有多个线程需要同时访问List集合中的元素,使用Collections将集合包装为线程安全的集合。
增强的Map集合
Map用于保存具有映射关系的数据,因为Map集合里保存着两组值,一组值用于保存key,一族中保存value,key和value可以是任何引用类型的变量,
Map的key不允许重复。
key和value之间存在单向一对一关系,即通过指定的key,总能找到唯一的、确定的value。从Map中取出数据的时候,只要给出指定的key就可以取出对应的value。如果把Map中的两组值拆开来看,Map里的数据应该是如下结构:
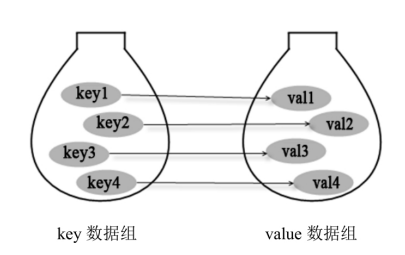
Map中的所有key放在一起就是一个Set集合,Map中有一个keySet方法,用于返回Map中的所有key组成的Set集合。
Map里的所有value放在一起就像一个List,每个元素都可以根据索引来查找,只是Map中的索引使用的是另一个对象。
Map也被称为字典,或关联数组。
Map接口中定义了如下常用方法:
- void clear():删除该Map对象中的所有key-value对。
- boolean containsKey(Object key):查询Map中是否包含指定的key。
- boolean containsValue(Object Value):查询Map中是否包含一个或多个value。
- Set entrySet():返回Map中包含key-value对所组成的Set集合,每个集合元素都是Map.Entry(Entry是Map的内部类)对象。
- Object get(Object key):返回指定的key对应的value;如果不包含key,则返回null。
- boolean isEmpty():查询该Map是否为空,为空则返回null。
- Set keySet():返回该Map中所有key组成的Set集合。
- Object put(Object key,Object value):添加一个key-value对,如果当前已有一个相同的key,则新的对会覆盖旧的。
- void putAll(Map m):将指定Map中的key-value对复制到本Map中。
- Object remove(Object key):删除指定key所对应的key-value对,返回被删除的key对应的value,不存在key则返回null
- boolean remove(Object key, Object value):这是Java8新增的方法,删除中的key、value对应的key,value对,返回值既是成功与否
- int size():返回该Map中key-value对的个数。
- Collection values():返回该Map中所有的value组成的Collection。
Map中包括一个内部类Entry,该类封装了一个key-value对。Entry包含如下三个方法:
- Object getKey():返回该Entry里包含的key值。
- Object getValue():返回该Entry里的value值。
- Object setValue(V value):设置该Entry里包含的value值,并返回新设置的value值。
Map最典型的用法就是成对地添加、删除key-value对,接下来可以判断该Map中是否包含指定key们是否包含指定value,也可以通过Map提供地keySet方法获取所有key组成的集合,进而边里Map中所有的key-value对。
HashMap重写了toString()方法,实际上所有的Map实现类都重写 了toString()方法,调用Map对象的toString()方法总是返回如下格式 的字符串:{key1=value1,key2=value2…}。
Java8为Map新增的方法
Java 8为Map新增了一些方法,包括:
forEach(BiConsumer<? super K, ? super V> action):对Map中的每个键值对执行给定的操作。getOrDefault(Object key, V defaultValue):返回指定键对应的值,如果该键不存在,则返回默认值。putIfAbsent(K key, V value):如果Map中不存在指定的键,则将指定的键值对添加到Map中。remove(Object key, Object value):如果Map中指定的键值对存在,则将其从Map中删除。replace(K key, V value):如果Map中存在指定的键,则用指定的值替换该键对应的值。replaceAll(BiFunction<? super K, ? super V, ? extends V> function):使用给定函数对Map中的每个键值对执行替换操作。compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction):使用给定函数计算指定键的值,并将其替换为计算结果。computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction):如果Map中不存在指定的键,则使用给定函数计算该键的值并将其添加到Map中。computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction):如果Map中存在指定的键,则使用给定函数计算该键的值,并将其替换为计算结果。merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction):使用给定函数将指定键的值与给定值进行组合,并将组合结果替换为该键的值。
这些方法可以使Map的使用更加灵活和方便,提高了开发效率。
HashMap和Hashtable实现类
它们之间的关系类似于ArraySet和Vector的关系:Hashtable是一个古老的Map实现类。
Hashtable和HashMap存在两点典型区别:
- Hashtable是一个线程安全的Map实现,HashMap线程不安全,所以HashMap比Hashtable性能略高,但是当多线程时,使用Hashtable。
- Hashtable不允许使用null作为key和value,但HashMap可以。
Hashtable应该尽量少用,即使需要创建线程安全的类,也可以使用Collections工具类包装HashMap使其变成线程安全的。
尽量不要使用可变对象作为HashMap的key,如果实在需要使用,不要在程序中修改。
LinkedHashMap实现类
HashMap也有一个LinkedHashMap子类;也是用双向链表,维护的顺序就是插入顺序。
LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap;但因为它以链表来维护内部顺序,所以在迭代访问Map里的全部元素时将有较好的性能。
使用Properties的读写属性文件
Properties类是Hashtable类的子类,正如它名字所暗示的,该对象在处理属性文件时特别方便 (Windows操作平台上的ini文件就是一种属性文件)。
在Java中,可以使用java.util.Properties类来读写属性文件。下面是一个简单的例子:
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Properties;
public class PropertiesExample {
public static void main(String[] args) {
Properties prop = new Properties();
// 读取属性文件
try (FileInputStream fis = new FileInputStream("config.properties")) {
prop.load(fis);
} catch (IOException e) {
e.printStackTrace();
}
// 读取属性值
String dbHost = prop.getProperty("db.host");
String dbPort = prop.getProperty("db.port");
String dbUser = prop.getProperty("db.user");
String dbPassword = prop.getProperty("db.password");
// 输出属性值
System.out.println("db.host = " + dbHost);
System.out.println("db.port = " + dbPort);
System.out.println("db.user = " + dbUser);
System.out.println("db.password = " + dbPassword);
// 修改属性值
prop.setProperty("db.password", "new_password");
// 写入属性文件
try (FileOutputStream fos = new FileOutputStream("config.properties")) {
prop.store(fos, "Database Configuration");
} catch (IOException e) {
e.printStackTrace();
}
}
}
在上面的例子中,首先创建了一个Properties对象,然后使用load方法从属性文件中读取属性值。读取属性值时,可以使用getProperty方法获取指定键的值。然后输出属性值,并使用setProperty方法修改了一个属性值。最后使用store方法将修改后的属性值写入属性文件中。
需要注意的是,在使用load方法读取属性文件时,需要使用FileInputStream来打开文件输入流。同样,在使用store方法写入属性文件时,需要使用FileOutputStream来打开文件输出流。在使用完输入流和输出流后,需要及时关闭它们,以避免资源泄漏。
SortedMap接口和TreeMap实现类
TreeMap就是一个红黑树数据结构,每个key-value对即作为红黑树的一个节点。TreeMap存储key-value对时,需要根据key对节点进行排序。同样还是那两种排序:自然排序和定制排序。
WeakHashMap实现类
WeakHashMap是Java集合框架中的一种特殊的Map实现,它的键是弱引用(Weak Reference),也就是说,当某个键不再被其他对象引用时,它可以被垃圾回收器回收,这样就可以避免内存泄漏的问题。与之相反的是,如果使用的是强引用(Strong Reference),即使某个键不再被使用,它也不会被垃圾回收器回收,从而可能导致内存泄漏。
与普通的HashMap相比,WeakHashMap的性能会略微降低,因为它需要更频繁地处理键的垃圾回收。但是,在需要使用缓存的场景下,WeakHashMap是一种非常有用的工具,它可以自动地清除过期的缓存,从而避免内存泄漏。
下面是一个简单的WeakHashMap的例子:
import java.util.Map;
import java.util.WeakHashMap;
public class WeakHashMapExample {
public static void main(String[] args) {
Map<Key, Value> cache = new WeakHashMap<>();
Key key1 = new Key("key1");
Value value1 = new Value("value1");
Key key2 = new Key("key2");
Value value2 = new Value("value2");
cache.put(key1, value1);
cache.put(key2, value2);
System.out.println("cache contains key1: " + cache.containsKey(key1));
System.out.println("cache contains key2: " + cache.containsKey(key2));
key1 = null;
key2 = null;
System.gc(); // 手动触发垃圾回收器
System.out.println("cache contains key1: " + cache.containsKey(new Key("key1")));
System.out.println("cache contains key2: " + cache.containsKey(new Key("key2")));
}
static class Key {
private String name;
public Key(String name) {
this.name = name;
}
@Override
public int hashCode() {
return name.hashCode();
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj == null || getClass() != obj.getClass()) {
return false;
}
Key other = (Key) obj;
return name.equals(other.name);
}
}
static class Value {
private String name;
public Value(String name) {
this.name = name;
}
}
}
在上面的例子中,我们创建了一个WeakHashMap实例,并向其中添加两个键值对。然后,我们打印了cache中是否包含两个键,最后将两个键设为null,并手动触发垃圾回收器。在垃圾回收之后,我们又打印了cache中是否包含两个键。可以看到,由于Key是弱引用,因此在key1和key2被设置为null之后,它们很快就被垃圾回收器回收了,所以在最后的打印中,cache中不包含任何键。
需要注意的是,由于WeakHashMap的键是弱引用,因此不能保证键的顺序,也不能对键进行迭代。此外,由于弱引用的特性,WeakHashMap中的键可能随时被回收(即使内存充足),因此在使用时需要特别注意。
IdentityHashMap实现类
IdentityHashMap是Java集合框架中的一种特殊的Map实现,它与普通的HashMap不同之处在于,它在比较键时使用的是引用相等(Reference Equality)而不是值相等(Value Equality)。换句话说,只有当两个键引用同一个对象时,它们才被视为相等。
下面是一个简单的IdentityHashMap的例子:
import java.util.IdentityHashMap;
import java.util.Map;
public class IdentityHashMapExample {
public static void main(String[] args) {
Map<String, Integer> map = new IdentityHashMap<>();
String key1 = "key";
String key2 = new String("key");
map.put(key1, 1);
map.put(key2, 2);
System.out.println("map contains key1: " + map.containsKey(key1));
System.out.println("map contains key2: " + map.containsKey(key2));
System.out.println("value for key1: " + map.get(key1));
System.out.println("value for key2: " + map.get(key2));
}
}
在上面的例子中,我们创建了一个IdentityHashMap实例,并向其中添加两个键值对。其中,key1和key2的值相同,但是key2是通过new关键字创建的新对象,因此它的引用与key1并不相等。然后,我们打印了map中是否包含两个键以及它们对应的值。可以看到,由于IdentityHashMap使用引用相等来比较键,所以map中只包含一个键,而不是两个键。
需要注意的是,由于IdentityHashMap使用引用相等来比较键,因此它在比较键时不会调用键的equals方法,也不会调用键的hashCode方法。因此,如果使用IdentityHashMap作为缓存或映射,需要非常小心,以避免由于对象引用相等而产生的意外结果。
EnumMap实现类
EnumMap是一个与枚举类一起使用的Map实现,EnumMap中的所有key都必须是单个枚举类的枚举值。创建EnumMap时必须显式或隐式指定它的对应枚举类。具有如下特征:
- 以数组形式保存,紧凑且高效;
- 会根据key的自然顺序(枚举值在枚举类中的定义顺序)来维护key-value对的顺序。
- 不允许使用null作为key但可以作为value
import java.util.EnumMap;
import java.util.Map;
public class EnumMapExample {
enum Day {
MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY
}
public static void main(String[] args) {
Map<Day, String> map = new EnumMap<>(Day.class);
map.put(Day.MONDAY, "Monday");
map.put(Day.TUESDAY, "Tuesday");
map.put(Day.WEDNESDAY, "Wednesday");
map.put(Day.THURSDAY, "Thursday");
map.put(Day.FRIDAY, "Friday");
map.put(Day.SATURDAY, "Saturday");
map.put(Day.SUNDAY, "Sunday");
System.out.println("map contains MONDAY: " + map.containsKey(Day.MONDAY));
System.out.println("value for MONDAY: " + map.get(Day.MONDAY));
System.out.println("map contains SATURDAY: " + map.containsKey(Day.SATURDAY));
System.out.println("value for SATURDAY: " + map.get(Day.SATURDAY));
}
}
在上面的例子中,我们定义了一个枚举类型Day,然后创建了一个EnumMap实例,并向其中添加了七个键值对。其中,键是Day枚举类型的值,值是与之对应的字符串。然后,我们打印了map中是否包含两个键以及它们对应的值。
需要注意的是,由于EnumMap使用数组来表示键值对,因此在创建EnumMap实例时,需要指定枚举类型的Class对象。另外,由于枚举类型的值是有限的,因此EnumMap的大小和性能都是有限制的,如果枚举类型的值非常大,就不适合使用EnumMap。
各Map实现类的性能分析
对于Map常用实现类而言,HashMap比Hashtable快。
TreeMap比HashMap、Hashtable慢,因为其以红黑树为基础,但它的key-value对总是处于有序状态,所以当TreeMap被填充完成后就可以直接查看已排序好的Map。
一般来说使用HashMap,需要排序就用TreeMap。
总需要增删改使用LinkedHashMap。
EnumMap性能最好,但只适用于枚举类。
HashSet和HashMap的性能选项
对于HashSet及其子类而言,它们采用hash算法来决定集合中元素的存储位置,并通过hash算法来控制集合大小;对于HashMap、Hashtable及其子类而言,它们采用hash算法来决定Map中key的存储,并通过hash算法来增加key集合的大小。
hash表可以存储元素的位置被称为“桶”,在通常情况下,单个“桶”里存储一个元素,此时拥有最好的性能:hash算法可以根据hashCode值计算出“桶”的存储位置,接着从“桶”中取出元素。但hash表的状态时open的:在发生“hash”冲突的情况下,单个桶会存储多个元素,这些元素以链表形式存储,必须按顺序搜索。
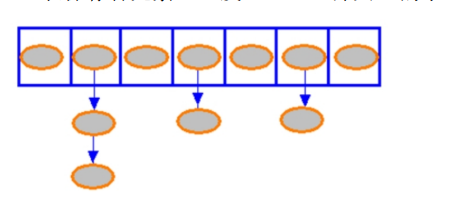
因为HashSet和HashMap,Hashtable都使用hash算法来决定其元素的存储,因此HashSet、HashMap的hash表包含如下属性:
- 容量(capacity):hash表中桶的数量。
- 初始化容量(initial capacity):创建hash表时桶的数量。HashMap和HashSet都允许在构造器中指定初始化容量。
- 尺寸(size):当前hash表中记录的数量。
- 负载因子(load factor):负载因子等于“size/capacity”。负载因子为0,表示空的hash表,0.5表示半满的hash表,以此类推。轻负载的hash表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时比较慢)。
除此之外,hash表里还有一个“负载极限”,”负载极限“是一个0~1的数值,”负载极限决定了hash表的最大填满成都。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这成为rehashing。
HashSet和HashMap、Hashtable的构造器允许指定一个负载极限,默认的负载极限都为0.75,这表明当该hash表的3/4被填满的时候,hash表会发生rehashing。
“负载极限”的默认值是时间和空间成本上的一种折中:较高的负载极限可以降低hash表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作(HashMap的get与put方法都要用到查询);较低的负载极限会提高查询数据的性能,但会增加hash表所占用的内存开销。
如果开始时就知道会保存很多记录,则可以在创建的时候就用较大的初始化容量,如果初始化容量始终大于需要保存的最大记录数除以负载极限,就不会发生rehashing。使用足够大的初始化容量创建,可以更高效的增加记录。
操作集合的工具类:Collections
Java提供了一个操作Set、List和Map等级和的工具类:Collections,该工具类里提供了大量方法对集合元素进行排序、查询和修改等操作,还提供了将集合对象设为不可变、对集合对象实现同步控制等方法。
排序操作
Collections提供类如下常用的类方法对List集合元素进行排序:
- reverse(List list):反转指定List集合中元素的顺序。
- shuffle(List list):对List集合元素进行随机排序(模拟洗牌)。
- sort(List list):根据元素的自然顺序对指定List集合元素进行升序排序。
- sort(List list, Comparator c):根据指定Comparator产生的顺序对List集合元素进行排序。
- swap(List list int i, int j):将指定List集合中的i处元素和j处元素进行交换。
- rotate(List list, int distance):当distance为正数时,将list集合的后distance各元素”整体“移到前面;当distance为负数时,将list集合的前distance个元素“整体”移到后面。
查找、替换操作
- int binarySearch(List list, Object key):使用二分搜索法搜索指定的List集合,以获得对象在List集合中的索引,要是用这个方法,需保证list中的元素已经处于有序状态。
- Objet max(Collection coll):根据元素的自然顺序,返回给定集合中的最大元素。
- Object max(Collection coll, Comparator c):根据Comparator指定的顺序,返回给定集合中的最大元素。
- Object min(Collection coll):根据元素的自然顺序,返回 给定集合中的最小元素。
- Object min(Collection coll, Comparator comp) : 根 据 Comparator指定的顺序,返回给定集合中的最小元素。
- void fill(List list, Object obj):使用指定元素obj替换List集合中的所有元素。
- int frequency(Collection c, Object o):返回指定集合中指定元素出现的次数。
- int indexOfSubList(List source, List target):返回子List对象在父List对象中第一次出现的位置索引;如果父List中没有子List,则返回-1;
- int lastIndexOfSubList(List source, List target):返回 子List对象在父List对象中最后一次出现的位置索引;如果父 List中没有出现这样的子List,则返回-1。
- boolean replaceAll(List list, Object oldVal, Object newVal):使用一个新值newVal替换List对象的所有旧值oldVal。
同步控制
Collections类中提供了多个synchronizedXxx()方法,该方法可 以将指定集合包装成线程同步的集合,从而可以解决多线程并发访问 集合时的线程安全问题。 Java 中 常 用 的 集 合 框 架 中 的 实 现 类 HashSet 、 TreeSet 、 ArrayList、ArrayDeque、LinkedList、HashMap和TreeMap都是线程不 安全的。如果有多个线程访问它们,而且有超过一个的线程试图修改 它们,则存在线程安全的问题。Collections提供了多个类方法可以把 它们包装成线程同步的集合。

设置不可变集合
Collections提供了如下三类方法来返回一个不可变的集合。
- emptyXxx():返回一个空的、不可变的集合对象,此处的集合 既可以是List,也可以是SortedSet、Set,还可以是Map、 SortedMap等。
- singletonXxx():返回一个只包含指定对象(只有一个或一项 元素)的、不可变的集合对象,此处的集合既可以是List,还 可以是Map。
- unmodifiableXxx():返回指定集合对象的不可变视图,此处 的集合既可以是List,也可以是Set、SortedSet,还可以是 Map、SorteMap等。
上面三类方法的参数是原有的集合对象,返回值是该集合的“只 读”版本。通过Collections提供的三类方法,可以生成“只读”的 Collection或Map。看下面程序。

上面程序的三行粗体字代码分别定义了一个空的、不可变的List 对象,一个只包含一个元素的、不可变的Set对象和一个不可变的Map 对象。**不可变的集合对象只能访问集合元素,不可修改集合元素。**所 以 上 面 程 序 中 ① ② ③ 处 的 代 码 都 将 引 发 UnsupportedOperationException异常。
Java 9新增的不可变集合
未看。
烦琐的接口:Enumeration
感觉没必要,扫了一眼。
第九章 泛型
泛型是在Java5增加的,在很大程度上都是为了让集合能记住其元素的数据类型。
在没有反省之前,一旦把一个对象“丢进”Java集合中,集合就会忘记对象的类型,把所有的对象当成Object类型处理。当程序从集合中取出对象后,就需要进行强制类型转换,这种强制类型转换不仅臃肿,而且还容易出现ClassCastExeception异常。
增加了泛型支持后的集合,完全可以记住集合中元素的类型,并可以在编译时检查集合中元素的类型,如果试图像集合中添加不满足类型要求的对象,编译器就会提示错误,泛型可以让代码更简洁,程序更加健壮。
泛型入门
使用泛型
如List,这表明该List只能保存字符串类型的对象。Java的参数化类型被称为泛型。
深入泛型
所谓反省,就是允许在定义类、接口、方法时使用类型形参,这个类型形参(泛型)将在声明变量、创建对象、调用方法时动态的指定,用传入的类型替代。
定义泛型接口、类
public interface List<E>{
void add(E x);
Iterator<E> iterator();
...
}
public interface Map<K,V> {
Set<k> keySet();
V put(K key, V value);
}
允许在定义接口、类时使用泛型形参,泛型形参在整个接口、类体内可当成类型使用,几乎所有可使用普通类型的地方都可以使用这种泛型形参。
除此之外,返回值类型为Set这表明Set是一种特殊的数据类型,是一种与Set不同的数据类型——可以认为是Set类型的子类。
也就是说在很多情况下:虽然程序只定义了一个List但实际使用时可以产生无数多个List接口,只要传入不同的类型实参。系统就会多出一个新的List子接口。
可以为任何类、接口增加泛型声明。
当创建带泛型生命的自定义类,为该类定义构造器时,构造器名哈市原来的类名,不要增加泛型声明。
class class1<T>{
private final T data;
public class1 (T data) {
this.data = data;
}
public T getData(){
return this.data;
}
}
从泛型类派生子类
当创建了带泛型声明的接口、父类之后,可以为该接口创建是西安类,或从该接口派生子类,当使用这些接口、父类时不能再包含泛型形参
调用方法时必须为所有的数据形参传入参数值,与调用方法时不同的是,使用类、接口时也可以不为泛型形参传入实际的类型参数
public class A extends class1;//未传入实际的类型参数
public class A extends class1<String>;//传入实际的类型参数
public class A extends class1<>;//不允许这样声明
省略泛型的形式被称为原始类型。
如果从class1类派生子类,则在class1类中所有使用T类型的地方都将被替换成String类型,即它的子类将会继承到父类中使用泛型定义的String返回值类型的方法。
并不存在泛型类
前面提到的可以把ArrayList类当成ArrayList的子类,事 上,ArrayList类也确实像一种特殊的ArrayList类:该ArrayList对象只能添加String对象作为集合元素。但实际上,系统并没有为ArrayList生成新的class文件,而且也不会把ArrayList当成新类来处理。
不管泛型的实际类型参数是什么,它们在运行时总有同样的类(class)
不管为泛型形参传入哪一种类型实参,对于Java来说,它们依然被当成同一个类处理,在内存中也只占用一块内存空间,因此在静态方法、静态初始化块或者静态变量(它们都是类相关的)的声明和初始化中不允许使用泛型形参。
由于系统中并不会真正生成泛型类,所以instanceof运算符后不 能使用泛型类。
类型通配符
如果Foo是Bar的一个子类型(子类或者子接口),而G是具有泛型声明的类或接口,G并不是G的子类型!这一点非常值得注意,因为它与大部分人的习惯认为是不同的。
假设现在需要定义一个方法,该方法里有一个集合形参,集合形参的元素类型是不确定的,应该如何定义?
使用类型通配符
为了表示各种泛型List的父类,可以使用类型通配符,类型通配符是一个问号"?",讲一个问号作为类型实参传给List集合,写作List<?>意思是元素类型未知的List。它可以匹配任何类型。
public void test (List<?> c) {
for (int i = 0; i < c.size(); i++) {
System.out.println(c.get(i));
}
}
现在使用任何List来调用它,程序依然可以访问集合c中的元素,其类型是Object,则会永远是安全的,因为Object是所有类的父类。
上面程序中使用的List,其实这种写法可以适应于任何支持泛型声明的接口和类,比如写成 Set<?> Collection<?>、Map<?>等。
但这种带通配符的List仅表示它是各种泛型List的父类,并不能把元素加入到其中。因为程序无法确定集合中元素的类型,所以不能像其中添加对象。唯一的例外是null,它是所有引用类型的实例。
另一方面,程序可以调用get()方法来返回List集合指定索引 处的元素,其返回值是一个未知类型,但可以肯定的是,它总是一个 Object。因此,把get()的返回值赋值给一个Object类型的变量,或者 放在任何希望是Object类型的地方都可以。
设定类型通配符的上限
在Java泛型中,可以使用类型通配符来表示未知类型,并限制通配符的范围,以便提高代码的类型安全性。**通配符的上限用于限制通配符的类型必须是指定类型或者指定类型的子类。**下面是设定类型通配符上限的语法:
public void myMethod(List<? extends MyClass> myList) {
// method body
}
在上面的例子中,List<? extends MyClass>表示一个类型为MyClass或MyClass的子类的列表。这个通配符的上限是MyClass,它限制了通配符的类型必须是MyClass或MyClass的子类。在方法中,可以使用这个通配符来接受任何类型为MyClass或MyClass的子类的列表。
需要注意的是,通配符的上限只能限制通配符的类型必须是指定类型或者指定类型的子类,不能限制通配符的类型必须是指定类型的父类或者其他无关类型。因此,在使用通配符的上限时需要注意类型的继承关系。
**这种指定通配符上限的集合只能从集合中取元素,不能向集合中添加元素。**这是因为在Java泛型中,通配符的上限用于限制通配符的类型必须是指定类型或者指定类型的子类,但编译器无法确定集合元素实际是哪种子类型。
例如,如果有一个List<? extends Number>集合,这个集合可能是一个List<Integer>、List<Double>或者List<Number>等类型的集合。如果向这个集合中添加一个Integer类型的元素,编译器无法确定这个元素的确切类型,因此会报错。
但是,如果从这个集合中取出一个元素,则可以确定这个元素的类型必须是Number或者Number的子类。因此,取出的元素总是上限的类型或其子类。
需要注意的是,Java泛型中的通配符上限和下限只适用于泛型类型参数,而不适用于泛型类或泛型方法的类型参数。因此,在使用通配符上限和下限时需要注意它们的适用范围。
这种形式通常被用于方法参数或返回类型中,以限制参数或返回值的类型范围,提高代码的类型安全性。用于方法参数的时候要注意只能作为设置好的父类使用,因为程序无法判定使用的是哪种子类;
例如,假设有一个方法需要接受一个只包含Number或Number的子类的列表作为参数,可以使用List<? extends Number>作为方法参数类型,以限制参数的类型范围,例如:
public void myMethod(List<? extends Number> myList) {
// method body
}
在这个方法中,可以安全地访问列表中的元素,并且可以确保每个元素的类型是Number或者Number的子类。
另外,如果一个方法返回一个只包含Number或Number的子类的列表,可以使用List<? extends Number>作为返回值类型,例如:
public List<? extends Number> myMethod() {
// method body
}
在这个方法中,可以返回任何类型为Number或者Number的子类的列表,例如List<Integer>、List<Double>或者List<Number>等类型的列表。
设置类型通配符的下限
设置通配符的下限就是为了支持类型型变,比如Foo是Bar的子类,当程序需要一个A<? super Foo>变量时,程序可以将A< Bar >、A< Object >赋值给A<? super Foo>类型的变量,这种型变方式被称为逆型变。
对于逆变的泛型集合来说,编译器只知道集合元素是下显得父类型,但具体是哪种父类型则不确定。因此,这种逆变的泛型集合能向其中添加元素(因为实际赋值的集合元素总是逆变声明的父类),从集合中取元素时只能被当成Object类型处理,因为无法确定取出的到底是哪个父类的对象。
对于逆变的泛型而言,它只能调用泛型类型作为参数的方法;而不能调用泛型类型作为返回值类型的方法。
假设自己实现一个工具方法:实现将src集合中的个元素复制到dest集合的功能,因为dest集合可以保存src集合中的所有元素,所以dest集合元素的类型应该是src集合元素类型的父类。
对于上面的从copy方法,可以认为两个集合参数之间的依赖关系是:不管src集合元素的类型是什么,只要dest集合元素的类型与前者相同或者是前者的父类即可,此时通配符的下限就有了用武之地。
设置泛型形参的上限
Java泛型不仅允许在使用通配符形参时设定上限,而且可以在定义泛型形参时设定上限,用于表示传给该形参的实际类型要么是该上限类型,要么是该上限类型的子类
举个例子,假设我们有一个泛型类 Pair,其中包含两个类型参数 T1 和 T2。我们可以使用 extends 关键字来限定 T1 的类型必须是某个指定类型的子类型或本身。例如:
public class Pair<T1 extends Number, T2> {
private T1 first;
private T2 second;
public Pair(T1 first, T2 second) {
this.first = first;
this.second = second;
}
public T1 getFirst() {
return first;
}
public void setFirst(T1 first) {
this.first = first;
}
public T2 getSecond() {
return second;
}
public void setSecond(T2 second) {
this.second = second;
}
public static void main(String[] args) {
Pair<Integer, String> pair1 = new Pair<>(1, "one"); // 正确:Integer 类型是 Number 的子类
Pair<String, String> pair2 = new Pair<>("hello", "world"); // 错误:String 类型不是 Number 的子类
}
}
在上面的代码中,我们使用 extends 关键字来限定 T1 的类型必须是 Number 的子类型或本身。然后,我们创建了一个 Pair<Integer, String> 类型的对象,其中 Integer 类型是 Number 的子类型,因此这是合法的。然而,当我们尝试创建一个 Pair<String, String> 类型的对象时,由于 String 类型不是 Number 的子类型,因此会出现编译错误。
需要注意的是,通过设置泛型形参的上限,我们可以在编译时检查泛型类型的实际类型是否符合要求,这可以避免在运行时出现类型转换异常等错误。同时,设置泛型形参的上限也可以提高代码的可读性和可维护性,使代码更加健壮和安全。
多个上限
在 Java 中,我们可以为泛型形参设定多个上限,即使用 & 符号连接多个类型。这种方式称为类型限定(bounded type parameter),它可以限制泛型形参的类型必须是多个指定类型的子类型或本身。
举个例子,假设我们有一个泛型方法 max,它接受两个类型参数 x 和 y,并返回这两个参数中的最大值。我们想要限制 x 和 y 的类型必须是 Number 类型或其子类型,同时还要限制它们必须实现 Comparable 接口。我们可以使用类型限定来实现这一要求。
public static <T extends Number & Comparable<T>> T max(T x, T y) {
return x.compareTo(y) >= 0 ? x : y;
}
在上面的代码中,我们使用类型限定 <T extends Number & Comparable> 来限定 T 的类型必须是 Number 类型或其子类型,同时还要求 T 必须实现 Comparable 接口。然后,我们定义了一个泛型方法 max,它接受两个参数 x 和 y,类型都为 T,并返回这两个参数中的最大值。在方法中,我们使用 compareTo 方法来比较 x 和 y 的大小,然后返回较大的值。
需要注意的是,类型限定中的第一个类型必须是一个类或抽象类,而不是一个接口,这是因为 Java 中一个类只能继承一个父类,因此**在限定多个类型时必须将类放在第一位。**另外,如果一个泛型形参有多个上限,那么这些上限必须用 & 符号连接,而不能使用逗号分隔。
泛型方法
在一些情况下,定义类、接口时没有使用泛型形参,但定义方法时想自己定义泛型形参,这也是允许的。
定义泛型方法
假设需要实现这样一个方法——该方法负责将一个Object数组的所有元素添加到一个Collection集合中。考虑采用如下代码来实现该方法。
import java.util.Collection;
public class CollectionUtils {
public static <T> void addAll(Collection<T> collection, T[] array) {
for (T obj : array) {
collection.add(obj);
}
}
}
在上面的代码中,我们使用泛型类型 T 来代替 Object 类型,在方法的参数和返回值中使用 T 作为类型参数。这样,我们就可以在调用方法时指定集合和数组的类型,使方法更加通用。
方法中的泛型参数无需显式传入实际类型参数,因为编译器根据实参推断出泛型所代表的类型。
泛型方法和类型通配符的区别
使用泛型方法(在方法签名中显式声明泛型形参)
**大多时候都可以使用泛型方法来代替类型通配符。**例如,对于Java的Collection接口中两个方法定义:
public interface Collection<E> {
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
...
}
上面集合中两个方法的形参都采用了类型通配符的形式,也可以采用泛型方法的形式。如下所示:
public interface Collection<E> {
<T> boolean containsAll(Collection<T> c);
<T extends E> boolean addAll(Collection<T> c);
...
}
上面方法采用了< T extends E >泛型形式,这是定义泛型形参时设定上限。
上面两个方法中泛型形参T只使用了一次,泛型形参T产生的唯一效果是可以在不同的调用点传入不同的实际类型。对于这种情况,应该使用通配符:通配符就是被设计用来支持灵活的子类化的。
泛型方法允许泛型形参被用来表示方法的一个或多个参数之间的类型依赖关系,或者方法返回值与参数之间的类型依赖关系,如果没有这样的类型依赖关系,就不应该使用泛型方法。
如果某个方法中的一个形参a的类型或返回值类型依赖于另一个形参b的而类型,则形参b的类型声明不应该使用通配符——因为形参a或返回值的类型以来于该形参b的类型,如果形参b的类型无法确定,程序就无法定义形参a的类型了,在这种情况下,只能考虑使用在方法签名中声明泛型,也就是泛型方法。
如果有需要,也可以同时使用泛型方法和通配符,如Java的Collections.copy方法。
publlic class Cllections{
public static <T> void copy (List<T> dest, List<? extends T> src){...}
...
}
上面的copy方法中的dest和src存在明显的依赖关系,从源List中复制出来的元素,必须可以丢进目标List中,所以原List集合元素的的类型只能是目标集合元素的类型的子类型或者它本身。但JDK定义形参时使用的是类型通配符,而不是泛型方法。这是因为:该方法无需向src集合中添加元素,也无需修改src集合中的元素,所以可以使用类型通配符,无需使用泛型方法。
当然,也可以使用只是用泛型方法
publlic class Cllections{
public static <T, S extends T> void copy (List<T> dest, List<S> src){...}
...
}
这个方法签名可以代替前面的方法签名。但注意上面的泛型形参S,它仅使用了一次,其他参数的类型、方法返回值的类型都不依赖于它,那泛型形参S就没有存在的必要,即可以使用通配符来代替S。使用通配符比使用泛型方法(在方法签名中显式声明泛型形参)更加清晰和准确,因此Java设计该方法是采用了通配符,而不是泛型方法。
类型通配符与泛型方法(在方法签名中显式声明泛型形参)还有一个显著的区别:类型通配符既可以在方法签名中定义形参的类型,也可以用于定义变量的类型;但泛型方法中的泛型形参必须在对应方法中显式声明。
菱形语法与泛型构造器
Java 7新增的“菱形”语法,它允许调用构造器时在构造器后使用一对尖括号来代表泛型信息。但如果程序显式指定了泛型构造器中声明的泛型形参的实际类型,则不可以使用“菱形”语 法。
类型判断
Java8改进了泛型方法的类型判断能力,类型推断主要有如下两方面:
- 可通过调用方法的上下文来推断泛型的目标类型。
- 可在方法调用链中,将推断得到的泛型传递到最后一个方法。
擦除和转换
在严格的泛型代码里,带泛型声明的类总应该带着类型参数。但为了与老的Java代码保持一致,也允许在使用带泛型声明 的类时不指定实际的类型。如果没有为这个泛型类指定实际的类型,此时被称作raw type(原始类型),默认是声明该泛型形参时指定的第一个上限类型。
当把一个具有泛型信息的对象赋给另一个没有泛型信息时,所有在尖括号之间的类型信息都将被扔掉。比如一个 List< String>类型被转换为Lsit,则该List对集合元素的类型检查变成了泛型参数的上限(即Object)。下面程序示范了种种擦除:

上面程序中定义了一个带泛型声明的Apple类,其泛型形参的上限 是Number,这个泛型形参用来定义Apple类的size变量。程序在①处创 建了一个Apple对象,该Apple对象的泛型代表了Integer类型,所以调用a的getSize()方法时返回Integer类型的值。当把a赋给一个不带泛型信息的b变量时,编译器就会丢失a对象的泛型信息,即所有尖括号里的信息都会丢失—因为Apple的泛型形参的上限是Number类,所以编译器依然知道b的getSize()方法返回Number类型,但具体是Number的哪个子类就不清楚了。
泛型与数组
Java泛型有一个很重要的设计原则——如果一段代码在编译时没有提出“[unchecked]未经检查的转换”警告,则程序在运行时不会引发ClassCastException异常。正是基于这个原因,所以数组元素的类型不能包含泛型变量或泛型形参,除非是无上限的类型通配符。但可以声明包含泛型变量或泛型形参的数组。也就是说,只能声明List< String>[]形式的数组,但不能创建ArrayList< String>[10]这样的数组对象。
泛型数组指的是包含泛型类型参数的数组。在 Java 中,我们可以创建泛型数组,但是需要注意一些细节和限制。
首先,**由于 Java 中的泛型是类型擦除的,即在运行时泛型类型信息被擦除,因此我们不能直接创建泛型数组。**例如,下面的代码是不允许的:
List<String>[] array = new List<String>[10]; // 编译错误
在上面的代码中,我们试图创建一个包含 10 个 List 类型元素的数组,但是由于泛型类型信息被擦除,因此编译器无法确定数组元素的类型,从而导致编译错误。
为了解决这个问题,Java 提供了一种泛型数组的替代方法,即使用通配符或原始类型来代替泛型类型参数。例如,下面的代码就是合法的:
List<?>[] array = new List<?>[10]; // 使用通配符
List[] array = new List[10]; // 使用原始类型
在上面的代码中,我们分别使用通配符和原始类型来创建了包含 10 个 List 类型元素的数组。使用通配符或原始类型可以避免泛型类型信息被擦除的问题,但是同时也会导致一些类型安全问题和限制,需要根据具体的需求来选择合适的方式。
需要注意的是,由于 Java 中的数组是协变类型,即可以将子类型的数组分配给父类型的数组引用,因此我们需要特别注意泛型数组的类型安全问题。例如,下面的代码就可能会导致类型安全问题:
List<String>[] array1 = new List[10];
List[] array2 = array1; // 编译通过,但是运行时会出现 ClassCastException 异常
array2[0] = new ArrayList<Integer>(); // 运行时出现 ClassCastException 异常
在上面的代码中,我们分别定义了两个数组,其中 array1 是一个包含 10 个 List 类型元素的数组,而 array2 是一个包含 List 类型元素的数组。虽然 Java 中的数组是协变类型,我们可以将 array1 分配给 array2,但是这样会导致类型安全问题,因为我们可以在运行时将一个不同类型的列表赋值给数组元素,从而导致 ClassCastException 异常。
总的来说,泛型数组是一种包含泛型类型参数的数组,需要注意一些细节和限制。由于泛型类型信息被擦除,我们**不能直接创建泛型数组,需要使用通配符或原始类型来代替泛型类型参数。**同时需要注意泛型数组的类型安全问题,避免出现 ClassCastException 异常等问题。
第十章 异常处理
异常机制可以使程序中的异常处理代码和正常业务代码分离,保证程序代码更加优雅,并可以提高程序的健壮性。
Java的异常机制主要依赖于try、catch、finally、throw和throws五个关键字,其中try关键字后紧跟一个花括号(不可省略)包含的代码块,简称try块,它里面放置可能引发异常的代码。
catch后对应异常类型和一个代码块,用于表示该catch块用于处理这种类型的代码块。多个catch块后还可以跟一个finally块,finally块用于回收try块里打开的物理资源,异常机制会保证finally块总被执行。
throws关键字主要在方法签名中使用,用于声明该方法可能抛出的异常;而throw用于抛出一个实际的异常,throw可以单独作为语句使用,抛出一个具体的异常对象。
开发者都希望所有的错误都能在编译阶段被发现,就是在试图运行程序之前排除所有错误,但这是不现实的,余下的问题必须在运行期间发得到解决。Java将异常分为两种,Checked异常和Runtime异常,Java认为Checked异常都是可以在编译阶段被处理的异常,所以它强制程序处理所有的Checked异常;而Runtime异常则无需处理。Checked异常可以提醒程序员需要处理所有可能发生的异常,但Checked异常也给编程带来一些繁琐之处,所以Checked异常也是Java领域一个备受争议的话题。
异常概述
提供一个代码块可以让只要程序出现异常就自动跳进去,然后可以分块处理
异常处理机制
当程序运行出现意外情形时,系统会自动生成一个Exception对象来通知程序,从而实现将“业务功能实现代码”和“错误处理代码”分离。
使用try…catch捕获异常
try {
// 可能抛出异常的代码段
} catch (异常类型1 e1) {
// 异常处理代码段1
} catch (异常类型2 e2) {
// 异常处理代码段2
} finally {
// 可选的finally语句块
}
如果执行try块中的业务逻辑代码出现异常,形同会自动生成一个异常对象,该异常对象被提交给Java运行时环境,这个过程被称为抛出(throw)异常。
异常类的继承体系
当Java运行时环境接收到异常对象后,会以此判断该异常对象是否是catch块后异常类或其子类的实例,如果是,Java运行时环境将调用该catch块来处理该异常;否则再次拿该异常对象和下一个catch块里的异常类进行比较。Java异常捕获流程示意图:
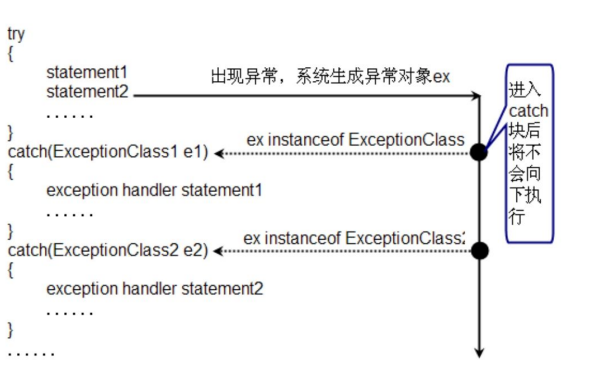
当程序进入负责异常处理的catch块的时候,系统生成的异常对象ex将会呈给catch块后的异常形参,从而允许catch块通过该对象来获得异常的详细信息。
try块执行一次后只有一个catch块会被执行。
try块与if语句不一样,try快后的或括号({…})不可以省略,catch也是。
Java提供了丰富的异常类,这些异常类之间有严格的继承关系。如下:
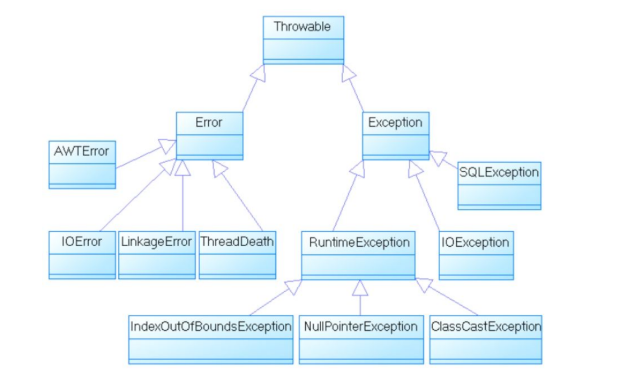
Java把所有的非正常情况分为两种:异常(Exception)和错误(Error),它们都继承Throwable父类。
- Error:一般是指与虚拟机有关的问题,如系统崩溃、虚拟机错误、动态链接失败等,这种错误无法恢复或不可能捕获,将导致应用程序中断。通常应用程序无法处理这些错误,因此应用程序不应该试图使用catch块来捕获Error对象,在定义该方法时,也无需在其throws子句中生命该方法可能抛出Error即其任何子类。
进行异常捕获时应该将所有的父类异常catch块排放在子类异常catch块的后面,否则将出现编译错误。
多异常捕获
从Java7开始,一个catch块可以捕获多种类型的异常。
- 捕获多种类型的异常时,多种异常类型之间用 | 隔开。
- 捕获多种类型的异常时,异常变量有隐式的final修饰,因此程序不能对异常变量重新赋值,
访问异常信息
如果程序需要在catch块中访问异常对象的相关信息,则可以通过访问catch块的后异常形参来获得。当Java运行时决定调用某个catch块来处理该异常对象时,会将异常对象赋给catch块后的异常参数,程序即可通过该参数来获得异常的相关信息。
所有的异常对象都包含了如下几个常用方法:
- getMessage():但会该异常的详细描述字符串。
- printStackTrace():将该异常的追踪栈信息输入到指定输出流。
- getStackTrace():返回该异常的追踪栈信息。
使用finally回收资源
有些时候,程序在try块里打开了一些物理资源(例如数据库连接、网络连接和磁盘文件等),这些物理资源都必须显式回收。
为了保证一定能回收try块中打开的物理资源,异常处理机制提供了finally块。不管try块中的代码是否出现异常,也不管哪一个catch块会被执行,甚至在try块或catch块中执行了return语句finally块总会被执行。
异常处理语法结构中只有try块是必需的,也就是说,如果没有try块,就不能有后面的块;catch块和finally块都是可选的,但是必至少存在其中之一;可以有多个catch块,捕获父类异常的catch块必须位于捕获子类异常的后面;多个catch块必须位于try块之后,finally块必须位于所有的catch块之后。
除非在try块、catch块中给调用了退出虚拟机的方法,否则不管在try块、catch块中执行怎样的代码,出现怎样的情况,异常处理的finally块总会被执行。
在通常情况下,不要在finally块中使用如return或throw等导致方法终止的语句,一旦在finally块中使用了return或throw语句,将会导致try块、catch块中的return、throw语句失效。
异常处理的嵌套
异常处理流程代码可以放在任何能放可执行性代码的地方,因此完整的异常处理流程即可以放在try块里,也可放在catch块里,还可放在finally块里。
Java9增强的自动关闭资源的try语句
Java 7 引入了自动关闭资源的 try 语句,也称为 try-with-resources 语句。这个语句可以用来自动关闭在 try 语句块中打开的资源,无论是正常关闭还是异常关闭。
使用 try-with-resources 语句,需要满足以下条件:
- 资源必须实现了 java.lang.AutoCloseable 接口或者 java.io.Closeable 接口;
- 该资源必须在 try-with-resources 语句中初始化;
- try 语句块退出后,资源将自动被关闭。
下面是一个使用 try-with-resources 语句的例子,其中我们使用了 FileWriter 类来写入文件:
try (FileWriter writer = new FileWriter("file.txt")) {
writer.write("Hello, World!");
} catch (IOException e) {
e.printStackTrace();
}
在这个例子中,我们使用了一个 FileWriter 对象来写入文件。在 try-with-resources 语句中,我们将该资源初始化为 writer 对象,并在代码块结束时自动关闭。如果在写入文件时出现异常,catch 块将会捕获该异常并进行处理。
需要注意的是,如果同时打开多个资源,可以使用分号将它们分隔开。例如:
try (FileReader reader = new FileReader("file.txt");
BufferedReader br = new BufferedReader(reader)) {
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
在这个例子中,我们同时打开了一个 FileReader 对象和一个 BufferedReader 对象,并在 try-with-resources 语句中进行初始化。当代码块结束时,这两个资源将自动关闭。
Checked异常和Runtime异常体系
Java的异常被分为两大类:Checked异常和Runtime异常(运行时异常)。所有的RuntimeException类及其子类的实例被称为Runtime异常;不是RuntimeException类及其子类的一场失利则被称为Checked异常。
只有Java语言提供了Checked异常,其他语言都没有提供Checked异常。Java认为Checked异常都是可以被处理(修复)的异常,所以Java程序必须显式处理Checked异常,如果程序没有处理Checked异常,则程序在编译时就会发生错误无法通过编译。
对于Checked异常的处理方式有如下两种。
- 当前方法明确知道如何处理该异常,程序应该使用try…catch块来捕获该异常,然后在对应的catch块中修复该异常。
- 当前方法不知道如何处理这种异常,应该在定义该方法时抛出异常。
Runtime异常则更加灵活,Runtime异常无需显式声明抛出,如果程序需要捕获Runtime异常,也可以使用try…catch块来实现。
使用throws声明抛出异常
使用throws声明抛出异常的思路是,当前方法不知道如何处理这种类型的异常,该异常应该由上一级调用者处理;如果main方法也不知道如何处理这种类型的异常,也可以使用throws声明抛出异常,该异常将交给JVM处理。JVM对异常的处理方法是,打印异常的跟踪栈信息,并终止程序运行,这就是前面程序在遇到异常后自动结束的原因。
在 Java 中,可以使用 throws 关键字声明一个方法可能会抛出的异常。这样做的作用是将异常的处理责任交给方法的调用者,使得方法的实现者可以不必处理所有的异常,从而让代码更加简洁清晰。
语法格式如下:
[访问修饰符] 返回类型 方法名(参数列表) throws 异常类型1, 异常类型2, ... {
// 方法实现
}
其中,throws 关键字后面可以跟一个或多个异常类型,用逗号分隔。这些异常类型必须是方法可能抛出的受检查异常或其父类。
下面是一个例子:
public void readFile(String fileName) throws FileNotFoundException, IOException {
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(fileName));
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
在这例子中,readFile 方法可能会抛出 FileNotFoundException 和 IOException 两种异常,因此在方法声明中使用了 throws 关键字声明了这两种异常。
需要注意的是,如果一个方法声明了可能抛出异常,但并没有在方法内部捕获或处理这些异常,那么在方法的调用处也必须进行异常处理,否则编译器会报错。可以使用 try-catch 语句进行异常处理,或者在调用方法的地方再次使用 throws 关键字将异常继续向上抛出。
方法重写时声明抛出异常的限制
使用throws声明抛出异常时有一个限制,就是方法重写时“两小”中的一条原则:子类方法声明抛出的异常类型应该是父类方法声明抛出的异常类型子类或相同,子类方法声明抛出的异常不允许比父类方法声明抛出的异常多。
在 Java 中,如果子类重写(override)了父类的方法,那么子类方法声明抛出的异常类型应该是父类方法声明抛出的异常类型的子类或相同。
这是因为 Java 中的异常处理是基于多态实现的。当一个方法声明抛出某种异常时,意味着该方法可能会抛出该异常或该异常的子类。如果子类方法声明抛出的异常类型比父类方法声明抛出的异常类型多,那么在子类中调用该方法时,可能会出现无法处理的异常类型,从而导致程序出错。
下面是一个例子:
class Parent {
public void doSomething() throws IOException {
// 父类方法可能抛出 IOException 异常
}
}
class Child extends Parent {
@Override
public void doSomething() throws FileNotFoundException {
// 子类方法声明抛出 FileNotFoundException 异常,是 IOException 异常的子类
}
}
在这个例子中,父类方法 doSomething 声明抛出 IOException 异常,而子类方法 doSomething 声明抛出 FileNotFoundException 异常,是 IOException 异常的子类。这样做是允许的,因为在子类方法中抛出 FileNotFoundException 异常时,也会同时满足父类方法可能抛出的 IOException 异常。
需要注意的是,如果子类方法抛出的异常类型比父类方法抛出的异常类型少,那么这样做是不合法的,因为这会导致在父类方法中可能会抛出的异常在子类中无法处理。如果子类方法中确实不需要抛出任何异常,可以在方法声明中省略 throws 关键字,或者声明抛出 RuntimeException 或其子类异常。
使用Checked异常至少存在如下两大不便之处:
- 对于程序中的Checked异常,Java要求必须显式捕获并处理该异常,或者显式声明抛出该异常。这样就增加了编程复杂度。
- 如果在方法中显式声明抛出Checked异常,将会导致方法签名与异常耦合,如果该方法是重写父类的方法,则该方法抛出的异常还会受到被重写方法所抛出异常的限制。
在大部分时候推荐使用Runtime异常,而不使用Checked异常。尤其当程序需要自行抛出异常时,使用Runtime异常将更加简洁。
当使用Runtime异常时,程序无需再方法中声明抛出Checked异常,一旦发生了自定义错误,程序只管抛出Runtime异常即可。
如果程序需要在合适的地方捕获异常并对异常进行处理,则一样可以使用try…catch块来捕获Runtime异常。
使用throw抛出异常
当程序出现错误时,系统会自动抛出异常;除此之外,Java也允许程序自行抛出异常,自行抛出异常使用throw语句来完成。
抛出异常
很多时候系统是否要抛出异常可能需要根据应用的业务需求来决定,如果程序中的数据、执行与既定的业务需求不符,这就是一种异常。由于与业务需求不符而产生的异常,必须由程序员来决定抛出。
如果需要在程序中仔细ing抛出异常,则应使用throw语句,throw语句可以单独使用,throw语句抛出的不是异常类,二四一个异常实例,而且每次只能抛出一个异常实例。
throw 语句的语法格式如下:
throw 异常对象;
其中,异常对象 是一个已经创建好的、合法的异常对象。这个异常对象可以是 Java 内置的异常类,也可以是自定义的异常类。
下面是一个例子:
public int divide(int a, int b) {
if (b == 0) {
throw new ArithmeticException("除数不能为0");
}
return a / b;
}
在这个例子中,divide 方法用于计算两个数的商,如果除数为 0,则抛出一个 ArithmeticException 异常。在抛出异常时,使用了 throw 语句将异常对象抛出。
如果throw语句抛出的异常是Checked异常,则该语句要么处于try块里,显式捕获该异常,要么放在一个带throws声明抛出的方法中,即把该异常交给该方法的调用者处理,如果throw语句抛出的异常时Runtime异常,则该语句无需放在try块里,也无需放在带throws声明抛出的方法中;程序集可以显示使用try…catch来捕获并处理该异常,亦可以完全不理会该异常,把该异常交给方法调用者处理。
自定义异常类
在通常情况下,程序很少会自行抛出系统异常,因为异常的类名通常也包含了该异常的有用信息。所以在选择抛出异常时,应该选择合适的异常类,从而可以明确地描述该异常情况。在这种情况下,应用程序常常需要抛出在自定义异常。
用户自动以一场都应该继承Exception基类,如果希望自定义Runtime异常,则应该继承RuntimeException基类。定义异常时通常需要提供两个构造器:一个是无参数的构造器;另一个是带一个字符串参数的构造器,这个字符串将作为该异常对象的描述信息。
在 Java 中,可以通过继承 Exception 或其子类来自定义异常类。自定义异常类可以根据具体的业务需求来定义异常类型,从而使程序的异常处理更加精确和可读性更强。
自定义异常类通常需要满足以下要求:
- 继承
Exception或其子类; - 定义一个无参构造方法;
- 定义一个带有异常信息的构造方法。
下面是一个自定义异常类的例子:
public class MyException extends Exception {
public MyException() {
super();
}
public MyException(String message) {
super(message);
}
}
在这个例子中,MyException 继承了 Exception 类,并定义了两个构造方法。第一个构造方法是无参的默认构造方法,第二个构造方法接受一个异常信息字符串作为参数。
可以在程序中抛出自定义异常类,例如:
public void doSomething() throws MyException {
// ...
if (someErrorOccurred) {
throw new MyException("发生了自定义异常");
}
// ...
}
在这个例子中,doSomething 方法可能会抛出一个自定义的异常类 MyException。当程序运行到 throw 语句时,会创建一个 MyException 对象并将其抛出,然后程序会寻找最近的异常处理器来处理这个异常。
需要注意的是,当自定义异常类继承了 RuntimeException 或其子类时,可以不用在方法声明中使用 throws 关键字声明该异常。这是因为 RuntimeException 异常以及其子类都是非检查异常,不需要在方法声明中声明或捕获。但是,对于继承了 Exception 的受检查异常类,必须在方法声明中声明该异常或捕获该异常。
异常链
对于一个三层架构的应用程序来说,当业务逻辑层出现异常时,程序不应该把底层的异常直接呈现到UI界面用户的眼前,对于普通用户来说知道底层异常毫无作用,对于恶意用户来说暴露底层则是很危险。
所以通常的做法是:程序先捕获原始异常,然后抛出一个新的业务异常,新的业务异常中包含了对用户的提示信息,这种处理方式称为异常转译。
这种捕获一个异常然后接着抛出一个异常,并把原始异常信息保存下来,是一种典型的链式处理,也被称为异常链。
在 Java 中,可以使用带有 Throwable 类型参数的构造方法来创建一个新的异常对象,并将原始异常作为参数传递进去。这样就可以将原始异常和当前异常关联起来,形成一个异常链。
所有的Throwable的子类在构造器中都可以接受一个cause对象作为参数。这个cause参数就用来表示原始异常,这样就可以把原始异常传给新的异常。
下面是一个使用异常链的例子:
public void doSomething() throws MyException {
try {
// 执行某些操作,可能会抛出 IOException
// ...
} catch (IOException e) {
throw new MyException("发生了自定义异常", e);
}
}
在这个例子中,doSomething 方法中可能会抛出一个自定义异常类 MyException。当程序运行到 catch 块时,会捕获到一个 IOException 异常。然后,使用带有 Throwable 类型参数的构造方法创建一个新的 MyException 异常对象,并将原始异常 e 作为参数传递进去。这样就将原始异常和当前异常关联起来,形成一个异常链。
需要注意的是,当使用异常链时,需要确保原始异常和当前异常都是合法的异常对象。否则,如果原始异常为 null,或者当前异常为原始异常的父类异常,那么异常链就会失效。
**在使用异常链时,可以通过 getCause() 方法获取原始异常对象,从而获得更多的异常信息。**例如:
try {
doSomething();
} catch (MyException e) {
if (e.getCause() != null) {
e.getCause().printStackTrace();
}
}
在这个例子中,当捕获到 MyException 异常时,可以通过 getCause() 方法获取原始异常对象,并打印其堆栈信息。
Java的异常跟踪栈
异常对象的printStackTrace方法用来打印异常的跟踪栈信息,根据输出的结果,可以找到异常的源头,并跟踪到异常衣裤触发的过程。
在 Java 中**,异常跟踪栈(stack trace)是一个记录了异常发生时调用栈的信息的对象。当异常被抛出时,Java 虚拟机会自动创建一个异常对象,并将当前调用栈的信息保存在该异常对象中。这个调用栈包含了所有方法的调用轨迹,从抛出异常的位置开始,一直到程序的入口处。**
可以使用异常对象的 printStackTrace() 方法来打印异常跟踪栈的信息。这个方法会将异常跟踪栈的信息输出到标准错误流(System.err)中,通常用于调试和排查异常。
下面是一个例子:
public void doSomething() {
try {
// 执行某些操作,可能会抛出异常
// ...
} catch (Exception e) {
e.printStackTrace();
}
}
在这个例子中,doSomething() 方法中可能会抛出一个异常。当程序运行到 catch 块时,会捕获到该异常,并使用 printStackTrace() 方法打印异常跟踪栈的信息。
打印出来的异常跟踪栈的信息通常包含以下几部分:
- 异常类型和异常信息;
- 调用栈信息,即从异常抛出的位置开始,到程序入口处的调用栈信息;
- 异常发生的具体代码行数和文件名。
异常跟踪栈的信息能够帮助开发者定位异常发生的位置和原因,从而更快地进行异常处理和调试。需要注意的是,在生产环境中不应该将异常跟踪栈的信息输出到标准错误流中,应该使用日志框架记录异常信息,并在必要时将异常信息发送给开发者进行调试和处理。
异常处理原则
成功的异常处理应该实现四个目标 :
- 使程序代码混乱最小化
- 捕获并保留诊断信息
- 通知合适的人员
- 采用合适的方式结束异常活动
不要过度使用异常
异常只应该用于处理非正常的情况,不要使用异常处理来代替正常的流程控制。对于一些完全可预知,而且处理方式清楚的错误,程序应该提供相应的错误处理代码,而不是笼统的称为异常。
不要使用过于庞大的try块
当try块中的代码量过大时,业务过于复杂,出现异常的概率也会大大增加,而这样就会势必要在try块后跟大量的catch块来处理其中的异常,这会大大增加复杂度,而且可读性很差且难以理解。
所以应该将大块的try块分割成多个可能出现异常的程序段落,并单独放在try块中,从而分别捕获并处理异常。
避免使用Catch All语句
在 Java 中,可以使用 catch 块来捕获异常并进行处理。通常情况下,一个 try 块可以包含多个 catch 块,每个 catch 块用于捕获一种特定类型的异常。但是,有时候我们可能希望捕获所有类型的异常,这时可以使用 catch 块中的 CatchAll 语句。
CatchAll 语句使用 catch 关键字后跟一个圆括号,其中圆括号内不需要指定异常类型。例如:
try {
// 执行某些操作,可能会抛出异常
// ...
} catch (Throwable e) {
// 处理所有类型的异常
}
在这个例子中,catch 块中的圆括号内不指定异常类型,这意味着该 catch 块可以捕获所有类型的异常。如果在 try 块中抛出了任何类型的异常,都会被这个 catch 块捕获,并进行相应的异常处理。
需要注意的是,使用 CatchAll 语句来捕获所有类型的异常可能会导致异常处理不够精确,无法对不同类型的异常进行特定的处理。因此,建议在捕获异常时尽可能地使用精确的异常类型,避免过度使用 CatchAll 语句。
另外,如果一个 try 块中包含多个 catch 块,那么 CatchAll 语句应该放在最后一个 catch 块中。这是因为 CatchAll 语句会捕获所有类型的异常,如果将其放在前面的 catch 块中,可能会导致后面的 catch 块失去作用。
不要忽略捕获到的异常
不要忽略异常!既然已捕获到异常,那catch块理应做些有用的事情——处理并修复这个错误。catch块整个为空,或者仅仅打印出错信息都是不妥的! catch块为空就是假装不知道甚至瞒天过海,这是最可怕的事情 ——程序出了错误,所有的人都看不到任何异常,但整个应用可能已经彻底坏了。仅在catch块里打印错误跟踪栈信息稍微好一点,但仅仅比空白多了几行异常信息。
通常建议对异常采取适当措施,比如:
➢ 处理异常。对异常进行合适的修复,然后绕过异常发生的地方继续执行;或者用别的数据进行计算,以代替期望的方法返回 值;或者提示用户重新操作……总之,对于Checked异常,程序应该尽量修复。
➢ 重新抛出新异常。把当前运行环境下能做的事情尽量做完,然后进行异常转译,把异常包装成当前层的异常,重新抛出给上层调用者。
➢ 在合适的层处理异常。如果当前层不清楚如何处理异常,就不要在当前层使用catch语句来捕获该异常,直接使用throws声明抛出该异常,让上层调用者来负责处理该异常。
第十三章 MySQL数据库与JDBC编程
通过使用JDBC,Java程序可以非常方便地操作各种主流数据库,程序使用JDBC API以统一的方式来连接不同的数据库,然后通过Statement对象来执行标准的SQL语句,并可以获得SQL语句访问数据库的结果。
JDBC简介
JDBC是一种可以执行SQL语句的Java API。程序可通过JDBC API连接到关系数据库,并使用结构化查询语言(SQL,数据库标准的查询语言)来完成对数据库的查询、更新。
与其他数据库变成环境相比,JDBC为数据库开发提供了标准的API,所以使用JDBC开发的数据库应用可以跨平台运行,而且可以跨数据库。
JDBC简介
通过使用JDBC们就可以使用同一种API访问不同的数据库系统。开发人员面向JDBC API编写应用程序,然后根据不同的数据库,使用不同的数据库驱动程序即可。

JDBC可以完成三个基本工作:
- 建立与数据库的连接。
- 执行SQL语句。
- 获得SQL语句的执行结果。
JDBC驱动程序
数据库驱动程序是JDBC程序和数据库之间的转换层,数据库驱动程序负责将JDBC调用映射成特定的数据库调用。
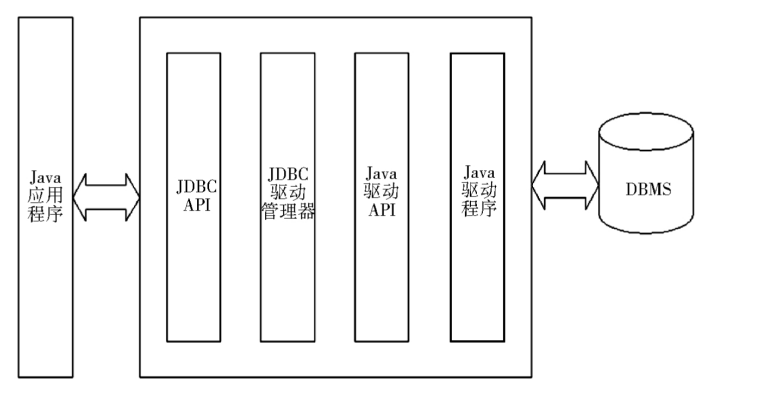
大部分的数据库系统,例如Oracle和Sybase等,都有相应的JDBC驱动程序,当需要链接某个特定的数据库时,必须有相应的数据库驱动程序。
JDBC驱动通常有如下4种类型:
- JDBC-ODBC 桥,这种驱动是最早实现JDBC驱动程序,主要目的是为了快速推广JDBC。这种驱动将JDBC API映射到ODBC API。这种方式在Java8中已经被删除。
- 第二种JDBC驱动,直接将JDBC API映射成数据库特定的客户端API。这种驱动包含特定数据库的本地代码,用于访问特定数据库的客户端。
- 第三种JDBC驱动,支持三层结构的JDBC访问方式,主要用于Applet阶段,通过Applet访问数据库。
- 第四种JDBC驱动:是纯Java的,直接与数据库实例交互。这种驱动是智能的,它知道数据库使用的底层协议。这种驱动是目前最流行的JDBC驱动。
对于ODBC而言,JDBC更加简单。总结起来,JDBC比ODBC多了如下几个优势:
- ODBC更复杂,ODBC中有几个命令需要配置很多复杂的选项,而JDBC则采用简单、直观的方式来管理数据库连接。
- JDBC比ODBC安全性更高,更易部署。
MySQL支持的数据类型
数值类型
| 类型 | 大小 | 范围,有符号 | 范围,无符号 | 用途 |
|---|---|---|---|---|
| TINYINT | 1 Bytes | -128, 127 | 0,255 | 小整数值 |
| SMALLINT | 2 | -32768,32767 | 0,65535 | 大整数值 |
| MEDIUMINT | 3 | -8388608,8388607 | 0,16777215 | 大整数值 |
| INT或INTEGER | 4 | -2 147 483 648,2 147 483 647 | 0,4 294 967 295 | 大整数值 |
| BIGINT | 8 | -9,223,372,036,854,775,808,9 223 372 036 854 775 807 | 0,18 446 744 073 709 551 615 | 极大整数值 |
| FLOAT | 4 | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度浮点数值 |
| DOUBLE | 8 | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度浮点数值 |
| DECIMAL | 对DECIMAL(M,D),如果M > D,为M+2,否则为D + 2。 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
MySQL支持的条件
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| BETWEEN … AND … | 在某个范围内(含最小、最大值) |
| IN(…) | 在IN之后的列表中的值,多选一 |
| LIKE 占位符 | 模糊匹配(_匹配单个字符,%匹配任意个字符) |
| IS NULL | 是NULL |
| 逻辑运算符 | 功能 |
|---|---|
| AND 或 && | 并且(多个条件同时成立) |
| OR 或 || | 或者(多个条件任意一个成立) |
| NOT 或 ! | 非,不是 |
SQL语法
关系数据库的基本概念和MySQL基本命令
严格来说,数据库仅仅是存放用户数据的地方。当用户访问、操作数据库中的数据时,就需要数据库管理系统的帮助。数据库管理系统的全称是Database Management System,简称DBMS。习惯上常常把数据库和数据库管理系统笼统地称为 数据库,通常听说的数据库既包括存储用户数据的部分,也包括管理数据库的管理系统。
DBMS是所有数据的知识库,它负责管理数据的存储、安全、一致性、并发、回复和访问等操作。DBMS有一个数据字典(有时也被称为系统表), 用于存储它拥有的每个事务的相关信息,例如名字、结构、位置和类型,这种关于数据的数据也被称为元数据。
在数据库发展历史中,按时间舒徐主要出现了如下几种类型的数据库系统
- 网状型数据库
- 层次性数据库
- 关系数据库
- 面向对象数据库
关系型数据库是理论最成熟、应用最广泛的数据库。从20世纪70年代末开始,关系型数据库理论逐渐成熟,随之涌现出大量商用的关系数据库。
面向对象数据库则是由面向对象编程语言催生的新型数据库。
关系型数据库最基本的数据存储单元就是数据表,因此可以简单地把数据库想象成大量数据表的集合(但数据库并不仅仅是由数据表组成)。
数据表是存储数据的逻辑单元,可以把数据表想象成由行和列组成的表格,期中每一行也被称为一条记录,每一列也被称为一个字段。为数据库建表时,通常需要指定该表包含多少列,每一列的数据类型信息,无需指定该数据表包含多少行——因为数据库表的行是动态改变的,每行用于保存一条用户数据。除此之外,还应该为每个数据表指定一个特殊列,该特殊列的值乐意唯一地表示此行的记录,则该特殊列被称为主键列。
客户端连接
mysql [-h 127.0.0.1] [-p 3306] -u root -p;
//-h是IP,-p是端口
SQL通用语法:
- SQL语句可以单行或多行书写,以分号结尾。
- SQL语句可以使用空格/缩进来增强语句的可读性。
- MySQL数据库的SQL语句不区分大小写。
- 注释:
- 单行注释:–注释内容或 # 注释内容(MySQL特有)
- 多行注释:/* 注释内容 */。
SQL语句的分类:
- DDL:数据定义语言,用来定义数据库对象(数据库,表,字段)
- DML:数据操作语言,用来对数据库表中的数据进行增删改。
- DQL:数据查询语言,用来查询库中表的记录
- DCL:数据控制语言,用来创建数据库用户、控制数据库的访问权限。
DDL
数据库操作
查询
查询所有数据库:
SHOW DATABASES;
查询当前数据库
SELECT DATABASE();
创建
CREATE DATABASE [IF NOT EXISTS] 数据库名 [DFFAULT CHARSET字符集] [COLLATE 排序规则];
删除
DROP DATABASE [IF EXISTS]数据库名;
使用
USE 数据库名;
表操作
查询
#查询当前数据库所有表
SHOW TABLES;
#查询表结构
DESC 表名;
#查询指定表的建表语句
SHOW CREATE TABLE 表名;
创建
CREATE TABLE 表名(
字段1 字段1类型 [COMMENT 字段1注释],
字段2 字段2类型 [COMMENT 字段2注释],
.
.
.
字段n 字段n类型 [COMMENT 字段n注释]
)[COMMENT 表注释];
修改
#添加字段
ALTER TABLE 表名 ADD 字段名 类型(长度)[COMMENT 注释] [约束];
#修改数据类型
ALTER TABLE 表名 MODIFY 字段名 新数据类型(长度);
#修改字段名和字段类型
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度)[COMMENT 注释][约束];
#删除字段
ALTER TABLE 表名 DROP 字段名;
#修改表名
ALTER TABLE 表名 RENAME TO 新表名;
#删除表
DROP TABLE 表名;
#删除指定表,并重新创建该表
TRUNCATE TABLE 表名;
DML
DML是数据操作语言,用来对数据库中表的数据记录进行增删改操作。
- 增加:INSERT
- 修改:UPDATA
- 删除:DELETE
添加数据
#给指定字段添加数据
INSERT INTO 表名(字段名1,字段名2...) VALUES(值1,值2...);
#给全部字段添加数据
INSERT INTO 表名 VALUES (值1,值2,...);
#批量添加数据
INSERT INTO 表名 (字段名1,字段名2,...) VALUES(值1,值2...),(值1,值2...),(值1,值2...);
INSERT INTO 表名 VALUES (值1,值2,...),(值1,值2,...),(值1,值2,...);
修改数据
#修改数据
UPDATE 表名 SET 字段名 = 值1, 字段名 = 值2,...[WHERE 条件];//无条件则修改整张表的数据
删除数据
#删除数据
DELETE FROM 表名 [WHERE 条件];//无条件则删除整张表的数据
DQL
DQL是数据查询语言,用来查询数据库中表的记录。
语法
SELECT
#字段列表
FROM
#表名列表
WHERE
#条件列表
GROUP BY
#分组字段列表
HAVING
#分组后条件列表
ORDER BY
#排序字段列表
LIMIT
#分页参数
基本查询
查询多个字段
SELECT 字段1,字段2...FROM 表名;
SELECT * FROM 表名;
设置别名
SELECT 字段1[AS 别名1],字段2[AS 别名2] ... FROM 表名;
#AS可省略
去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;
条件查询
SELECT 字段列表 FROM 表名 WHERE 条件列表;
聚合函数
介绍
将一列数据作为一个整体,进行纵向计算。
常见聚合函数
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
语法
SELECT 聚合函数(字段列表) FROM 表名;
注意
null值不参与聚合函数的运算,所以在统计数量时一般使用:
SELECT COUNT(*) FROM 表名;
分组查询
SELECT 字段列表 FROM 表名 [WHERE 条件] GROUP BY 分组字段名[HAVING 分组后过滤条件];
WHERE与HAVING的区别
- 执行时机不同:WHERE是分组之前进行过滤,不满足WHERE条件,不参与分组;而HAVING是分组之后对结果进行过滤。
- 判断条件不同:WHERE不能对聚合函数进行判断,而HAVING可以
执行顺序:
WHERE > 聚合函数 > HAVING
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
排序查询
ORDER BY
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1,字段2,排序方式2;
/*
ASC:升序(默认)
DESC:降序
*/
如果是多字段排序,当第一个字段值相同时,才会根据第二个字段值排序。
分页查询
SELECT 字段列表 FROM 表名 LIMIT 起始索引,查询记录数;
注意:
- 起始索引从0开始,起始索引 = (查询页码 - 1) * 每页显示记录数。
- 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT。
- 如果查询的是第一页的数据,起始索引可以省略,直接简写为LIMIT 10;
执行顺序
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后条件列表
SELECT
字段列表
ORDER BY
排序字段列表
LIMIT
分页参数
DCL
数据控制语言,主要用于管理数据库用户,控制数据库的访问权限。
管理用户
#查询用户
USE mysql;
SELECT * FROM user;
#创建用户
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
#修改用户密码
ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码';
#删除用户
DROP USER '用户名'@'主机名';
#主机名可以用%通配,表示任意主机都可以访问;
权限控制
| 权限 | 说明 |
|---|---|
| ALL,ALL PRIVILEGES | 所有权限 |
| SELECT | 查询数据 |
| INSERT | 插入数据 |
| UPDATE | 修改数据 |
| DELETE | 删除数据 |
| ALTER | 修改表 |
| DROP | 删除数据库/表/图 |
| CRAETE | 创建数据库/表 |
#查询权限
SHOW GRANTS FOR '用户名'@'主机名';
#授予权限
GRANT 权限列表 ON 数据库.表名 TO '用户名'@'主机名';
#撤销权限
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名'
函数
函数是指一段可以直接被另一段程序调用的程序或代码。
字符串函数
| 函数 | 功能 |
|---|---|
| CONCAT | 字符串连接函数 |
| LOWER | 将字符串全部化为小写 |
| UPPER | 将字符串全部化为大写 |
| LPAD | 在左侧补齐 |
| RPAD | 在右侧补齐 |
| TRIM | 去掉字符串左右两端的空格 |
| SUBSTRING | 字符串截取函数 |
数值函数
| 函数 | 功能 |
|---|---|
| CEIL | 向上取整 |
| FLOOR | 向下取整 |
| MOD | 取余 |
| RAND | 随机数 |
| ROUND | 四舍五入 |
日期函数
| 函数 | 功能 |
|---|---|
| CURDATE | 获取当前日期 |
| CURTIME | 获取当前时间 |
| NOW | 获取当前日期时间 |
| YEAR | 从时间中获取年份 |
| MONTH | 从时间中获取月份 |
| DAY | 从时间中获取日 |
| DATE_ADD | 添加指定的时间周期 |
| DATEDIFF | 判断两端日期之间相隔的天数 |
流程控制函数
| 函数 | 功能 |
|---|---|
| IF | 判断第一个参数中的条件表达式是否为true,是则返回第一个参数,否则返回第二个参数 |
| IFNULL | 判断第一个参数是否为null,不为null则返回第一个参数,为null则返回第二个参数 |
| CASE WHEN…THEN…ELSE…END | 条件分支判断 |
| CASE…WHEN…THEN…ELSE…END | 条件分支判断 |
约束
概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。
目的:保证数据库中数据的正确性、有效性和完整性。
分类:
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段的数据不能为null | NOT NULL |
| 唯一约束 | 保证该字段的所有数据都是唯一、不重复的 | UNIQUE |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | PRIMARY KEY |
| 默认约束 | 保存数据时,如果未指定该字段的值,则采用默认值 | DEFAULT |
| 检查约束 | 保证字段值满足某一个条件 | CHECK |
| 外键约束 | 用来让两张表的数据之间建立链接,保证数据的一致性和完整性 | FOREIGN KEY |
注意:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束。
使用主键时可以选择自增:AUTO_INCREMENT
外键约束
外键是用来让两张表的数据之间建立连接,从而保证数据的一致性和完整性。
添加/删除 外键
#创建表时添加外键
CRAETE TABLE 表名(
[CONSTRAINT] [外键名称] FOREIGN KEY (外键字段名) REFERENCES 主表(主表列名)
);
#已存在表后添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表(主表列名)
#删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称
删除/更新行为
| 行为 | 说明 |
|---|---|
| NO ACTION | 当在父表中删除/更新对应记录时,首先检查该纪录是否有对应外键,如果有则不允许删除/更新 |
| RESTRICT | 当在父表中删除/更新对应记录时,首先检查该纪录是否有对应外键,如果有则不允许删除/更新 |
| CASCASE | 当在父表中删除/更新对应记录时,如果有对应外键,则同时删除/更新外键在子表中的记录 |
| SET NULL | 当在父表中删除/更新对应记录时,如果有对应外键,则设置为null |
| SET DEFAULT | 父表有变更时,子表将外键列设置成一个默认的值 |
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY(外键字段) REFERENCES 主表名(主表字段名)ON UPDATE CASCADE ON DELETE CASCADE;
多表查询
多表关系
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务板块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
- 一对多(多对一)
- 多对多
- 一对一
一对多(多对一)
案例:部门与员工的关系
关系:一个部门对应多个员工,一个员工对应一个部门
实现:在多的一方建立外键,指向一的一方的主键
多对多
案例:学生与课程的关系
关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
一对一
案例:用户与用户详情的关系
关系:一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提升操作效率
实现:在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的。
多表查询概述
多表查询分类
-
连接查询
内连接:相当于查询A、B交集部分数据。
外连接:
左外连接:查询左表所有数据,以及两张表交集部分数据
右外链接:查询右表所有数据,以及两张表交集部分数据
自连接:当前表与自身的连接查询,自连接必须使用表别名
-
子查询
内连接
-
隐式内连接
SELECT 字段列表 FROM 表1,表2 WHERE 条件...; -
显式内连接
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 连接条件...;
外连接
-
左外连接
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 连接条件...; -
右外连接
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 连接条件...;
自连接
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件...;
#自连接查询可以是内连接查询,也可以是外连接查询
联合查询
就是把多次查询的结果合并起来,形成一个新的查询结果集。
SELECT 字段列表 FROM 表A ...
UNION[ALL]
SELECT 字段列表 FROM 表B ...
对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
UNION ALL 会将全部的数据直接合并在一起,UNION会对合并之后的数据去重。
子查询
-
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用操作符:> < >= <= != =
-
列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询
常用操作符:IN、NOT IN、ANY 、SOME、ALL
操作符 描述 IN 在指定的集合范围之内,多选一 NOT IN 不在指定的集合范围之内 ANY 子查询返回列表中,有任意一个满足即可 SOME 与ANY等同,使用SOME的地方都可以使用ANY ALL 子查询返回列表的所有制都必须满足 -
行子查询
子查询返回的结果时一行(可以是多列的),这种子查询称为行子查询。
常用的操作符: = 、<> 、IN 、NOT IN
-
表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:IN
事务
事务是一组操作的集合,是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
默认MySQL的事务是自动提交的,也就是说,当执行一条DML语句,MySQL会立即隐式的提交事务。
事务操作
-
查看/设置事务提交方式
SELECT @@autocommit; SET @@autocommit = 0; -
提交事务
COMMIT; -
回滚事务
ROLLBACK; -
开启事务
START TRANSACTION 或 BEGIN;
事务四大特性
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中数据的改变就是永久的。
并发事务问题
| 问题 | 描述 |
|---|---|
| 脏读 | 一个事务读到另外一个事务还没有提交的数据。 |
| 不可重复读 | 一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。 |
| 幻读 | 一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了“幻影”。 |
事务隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted(读未提交) | 1 | 1 | 1 |
| Read committed(读已提交) | 0 | 1 | 1 |
| Repeatable Read(默认)(可重复读) | 0 | 0 | 1 |
| Serializable(串行化) | 0 | 0 | 0 |
-- 查看事务隔离级别
SELECT @@TRANSACTION_ISOLATION
-- 设置事务隔离级别
SELECT [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL {隔离级别};
事务隔离级别越高,数据越安全,但是性能越低。
存储引擎
MySQL体系结构
-
连接层
最上层是一些用户端和链接服务,主要完成一些类似于连接处理、授权认证、及相关的安全方案。服务器也会为安全接入的每个用户端验证它所具有的操作权限。
-
服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化,部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程、函数等。
-
引擎层
存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通信。不同的存储引擎具有不同的功能,这样我们可以根据自己的需要来选取合适的存储引擎。
-
存储层
主要是讲数据存储在文件系统之上,并完成与存储引擎的交互。
存储引擎简介
MySQL默认存储引擎为 InnoDB。
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。
-- 在创建表时指定存储引擎
CREATE TABLE 表名{
//
} ENGINE = INNODB;
-- 查看当前数据库支持的存储引擎
SHOW ENGINES;
InnoDB
-
介绍
InnoDB是一种兼顾高可靠性和高性能的通用存储引擎,在MySQL5.5之后,InnoDB就是默认的存储引擎。
-
特点
- DML 操作遵循ACID模型,支持事务
- 行级锁,提高并发访问性能
- 支持外键FOREIGN KEY约束,保证数据的完整性和正确性
-
文件
xxx.ibd:xxx代表的是表名,InnoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结构、数据和索引。
参数:innodb_file_per_table
MyISAM
-
介绍
是早期MySQL的默认存储引擎
-
特点
不支持事务,不支持外键
支持表锁,不支持行锁
访问速度快
-
文件
xxx.sai:存储表结构信息
xxx.MYD:存储数据
xxx.MYI:存储索引
Memory
-
介绍
Memory引擎的表数据存储在内存中,由于受到硬件问题、或断电问题的影响,只能将这些表作为临时表或缓存使用。
-
特点
内存存放
hash索引(默认)
-
文件
xxx.sdi:存储表结构信息
区别
| 特点 | InnoDB | MySQL | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 |
| 事务安全 | 支持 | - | - |
| 锁机制 | 行锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | - | 支持 |
| 全文索引 | 支持 | 支持 | - |
| 空间使用 | 高 | 低 | N/A |
| 内存使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外键 | 支持 | - | - |
选择
- InnoDB:是MySQL主要应用的存储引擎,如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作。
- MyISAM:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对食物的完整性、并发性要求不是很高。
- MEMORY:将所有的数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。
一般来说在MySQL数据库的应用中,我们只会采用默认的InnoDB存储引擎,如果有其他的需求,另外的存储引擎做到的事,会有更好的非MySQL数据库可以做到。
索引
-
介绍
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。
-
优缺点
优势 劣势 提高数据检索的效率,降低数据库的IO成本 索引列也是要占用空间的 通过的索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗 索引大大提高了查询效率,同时也降低了更新表的速度,如对表进行INSERT、UPDATE 、DELETE是,效率降低
索引结构
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的结构,主要包含以下几种:
| 索引结构 | 描述 |
|---|---|
| B+Tree索引 | 最常见的索引类型,大部分引擎都支持B+树索引 |
| Hash索引 | 底层数据结构使用哈希表实现的,只有精确匹配索引项的查询才有效,不支持范围查询 |
| R-tree(空间索引) | 空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 |
| Full-text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式。类似于Lucene,Solr,ES |
支持情况
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | - | 支持 |
| R-tree | - | 支持 | - |
| Full-text | 5.6之后支持 | 支持 | - |
B+tree
是B树的变种
- 所有的数据都会出现在叶子节点
- 叶子节点形成一个单向链表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RXQRaq0V-1685084507247)(D:\Document\md\java\图片\image-20230515100136251.png)]
MySQL索引数据结构对经典的B+Tree做了优化,在原B+Tree的基础上,增加了一个指向相邻叶子结点的链表指针,就形成了带有顺序指针的B+Tree,提高区间的访问性能。
B+tree的优点
- 相对于二叉树,层级更少,搜索效率高
- 对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低;
- 相对Hash索引,B+tree支持范围匹配及排序操作
索引分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(Clustered Index) | 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引(Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一索引作为聚集索引
- 如果表没有主见,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
回表查询:先通过二级索引查找到对应的主键,然后通过聚集索引查询相应数据。

索引语法
-
创建索引
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name (index_col_name,...); -
查看索引
SHOW INDEX FROM table_name; -
删除索引
DROP INDEX index_name ON table_name;
SQL性能分析
-
SQL执行频率
MySQL客户端连接成功后,通过 show [session|global] status 命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT访问频次。
SHOW GLOBAL STATUS LIKE 'Com_______'; -
慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。
MySQL的慢查询日志默认没有开启,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
#开启MySQL慢查询日志开关 slow_query_log = 1; #设置慢日志的时间为2秒,SQL语句执行超过2秒,就会视为慢查询,记录慢查询日志 long_query_time = 2; -
profile详情
执行一系列的业务SQL的操作,然后通过如下指令查看指令的执行耗时:
#查看每一条SQL的耗时基本情况 show profile; #查看指定query_id的SQL语句各个阶段的耗时情况 show profile for query query_id; #查看指query_id的SQL语句CPU的使用情况 show profile cpu for query query_id; -
explain执行计划
EXPLAIN或者DESC命令获取MySQL如何执行SELECT语句的信息,你包括在SELECT语句执行过程中表如何连接和连接的顺序。
#直接在SELECT语句之前加上关键字EXPLAIN/DESC EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件;EXPLAIN执行计划各字段含义:
-
id
SELECT查询的序列号,表示查询中执行SELECT子句或者是操作表的顺序(id相同,执行顺序从上到下;id不同,值越大越先执行
-
select_type
表示SELECT的类型,常见的取值有SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION中的第二个或者后面的查询语句)、SUBQUERY(SELECT/WHERE之后包含了子查询)等
-
type
表示连接类型,性能由好到差的连接类型为NULL、system、const、eq_ref、ref、range、index、all。
-
possible_key
显示可能应用在这张表上的索引,一个或多个
-
key
实际使用的索引,如果为NUL,则没有使用索引
-
key_len
表示索引中使用的字节数,改制为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好。
-
rows
MySQL认为必须要执行查询的行数,在innodb引擎的表中,是一个估计值,可能并不总是准确的。
-
filtered
表示返回结果的行数占需读取行数的百分比,filtered的值越大越好。
-
索引使用
-
最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果条约某一列,索引将部分失效(后面的字段索引失效)。
-
范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效 ,
所以在业务允许的情况下,尽量使用 >= <= 这样的符号来防止索引失效
-
索引列运算
不要在索引列上进行运算操作,索引将失效
-
字符串不加引号
字符串类型字段使用时,不加引号,索引将失效
-
模糊查询
如果仅仅是尾部模糊查询,索引不会失效,如果是头部模糊查询,索引失效
-
or连接的条件
用or分隔开的条件,如果or前的条件中的列有索引,后面的列中没有索引,那么涉及的索引都不会被用到。
-
数据分布影响
如果MySQL评估使用索引比全表更慢,则不使用索引。
SQL提示
SQL提示,是优化数据库的一个重要手段,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
-
use index
explain select * from 表名 use index(索引名) where (条件); -
ignore index
explain select * from 表名 ignore index(索引名) where (条件); -
force index
explain select * from 表名 force index(索引名) where (条件);
覆盖索引
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引中已经全部能找到),减少select * 。
前缀索引
当字段类型为字符串时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率。此时可以只将字符串的而一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
create index idx_xxxx on table_name(column(n));
-
前缀长度n
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
单列索引和联合索引
- 单列索引:即一个索引只包含单个列
- 联合索引:即一个索引包含了多个列
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
索引设计原则
- 针对数据量较大,且查询比较频繁的表建立索引
- 针对于常作为查询条件(WHERE)、排序(ORDER BY)、 分组(GROUP BY)操作的字段建立索引
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高
- 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的待见也就越大,会影响增删改的效率
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器直到每列是否包含NULL值时,他可以更好地确定哪个索引最有效地用于查询。
SQL优化
插入数据
insert优化
- 批量插入
- 手动事务提交:减少事务的开启与提交
- 主键顺序插入
大批量插入数据
如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令进行插入。
load是直接将一个文件的数据插入进表中。

#客户端连接服务端时,加上参数--local-infile
mysql--local-infile -u root -p; -- 连接数据库时要加载本地的文件
#设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
#执行load指令将准备好的数据,加载到表结构中
load data local infile '文件名' into table '表名' fields terminated by '字段分隔符' lines terminated by '行分隔符';
主键优化
数据组织方式
在innodb存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT)。
页分裂
页可以为空,也可以填充一半,也可以填充100%。每个页包含了2-N行数据(如果一行数据过大,会行溢出),根据主键排列。
页合并
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用。
当页中删除记录达到MERGE_THRESHOLD(默认为页的50%),innodb会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用。
MERGE_THRESHOLD:合并页的阈值,可以自己设置,在创建表或者创建索引时指定。
主键设计原则
- 满足业务需求的情况下,尽量减低主键的长度。
- 插入数据时,尽量选择顺序插入,选择使用用AUTO_INCREMENT自增主键。
- 尽量不要使用UUID作为主键或者是其他自然主键,如身份证号。 因为它们都是无序的,尽量使用有序主键
- 业务操作时,避免对主键的修改。
order by优化
- Using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫FileSort排序。
- Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为using index,不需要额外排序,操作效率高。
使用索引:
-
尽量使用覆盖索引
-
在根据联合索引中的多个字段进行排序时,如果都为同一方向排序则只使用索引进行扫描,如果方向不一致会使用一部分的全表扫描。
-
可以在创建联合索引的时候指定排序次序,可以是顺序排序也可以指定逆序排序。这样就可以解决上一条提出的顺序不同不会使用索引排序的情况。
-
在使用联合索引的时候还需要注意规则,比如最左前缀
如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小sort_buffer_size(默认256k)
group by优化
- 建立索引
- 最左前缀法则
limit优化
一个常见有非常头疼的问题就是limit(2000000,10),此时MySQL需要排序前2000010记录,仅仅返回2000000-2000010的记录,其他记录丢弃,查询排序的代价非常大。
优化思路:一般分页查询时,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化
explain select * from tb_sku t,(select id from tb_sku order by id limit 2000000,10) a where t.id = a.id;
count优化
count的几种用法
-
count(主键)
innodb引擎会遍历整张表,把每一行的主键id都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键不可能为null)
-
count(字段)
没有not null约束:innodb引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为null,计数累加。
有not null约束:innodb引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加
-
count(1)
innodb引擎遍历整张表,但不取值。服务器对于返回的每一行,放一个数字“1”进去,直接按行进行累加。
-
count(*)
innodb引擎并不会把全部的字段都取出来,而是做了专门优化,不取值,服务层直接按行进行累加。
按照效率从大到小:
count(*) count(1) count(主键) count(字段)
所以日常使用时,尽量使用count(*)来计数
update优化
innodb的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则会从行锁升级为表锁。降低并发性能
视图
视图是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。
理解:视图即是用于暂存某些经常使用的字段的名称,以便于下一次直接以整体使用,不保存真实数据。
通俗的讲,视图只保存了查询的SQL逻辑,不保存查询结果,所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
基本操作
-
创建
CREATE [OR REPLACE] VIEW 视图名称[{列名列表}] AS SELECT语句 [WITH [CASCADED | LOCAL] CHECH OPTION]; -
查询
查看创建视图语句:SHOW CREATE VIEW 视图名称; 查看视图数据:SELECT * FROM 视图名称; -
修改
#方式一 CREATE [OR REPLACE] VIEW 视图名称[{列名列表}] AS SELECT语句 [WITH [CASCADED | LOCAL] CHECK OPTION]; #方式二 ALTER VIEW 视图名称[{列名列表}] AS SELECT语句 [WITH [CASCADED | LOCAL] CHECK OPTION]; -
删除
DROP VIEW [IF EXISTS] 视图名称 [视图名称]...
检查选项
当使用WITH CHECK OPTION子句创建视图时,MySQL会通过视图检查正在更改的每个行,例如 插入,更新,删除,以使其符合视图的定义。MySQL允许基于另一个视图创建视图,它还会检查依赖视图中的规则以保持一致性。为了确定检查的范围,mysql提供了两个选项:CASCADED 和 LOCAL,默认值为 CASCADED。
CASCADED
一旦在某个视图使用了CASCADED选项来创建视图,在更改的时候就会检查其本身包含的限制条件和它所依赖的所有视图的限制条件是否满足
LOCAL
只在使用了LOCAL的视图中生效,也就是说会回溯检查上一条的条件,但如果上一条并未使用LOCAL修饰,那么还是可以修改成功。
更新及应用
视图的更新
要使视图可更新,视图中的行与基础表中的行之间必须存在一对一的关系。如果视图包含以下任何一项,则该视图不可更新:
- 聚合函数或窗口函数(SUM(),MIN(),MAX(),COUNT()等)
- DISTINCT
- GROUP BY
- HAVING
- UNION或者UNION ALL
视图的作用
-
简单
视图不仅可以简化用户对数据理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视图,从而使用户不必为以后的操作每次指定全部的条件
-
安全
数据库可以授权,但不能授权到数据库特定行和特定列上。通过视图用户只能查询和修改他们所能见到的数据。
-
数据独立
试图可帮助用户屏蔽真实表结构变化带来的影响。
存储过程
存储过程是事先经过编译并存储在数据库中的一段SQL语句的集合,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。
存储过程思想上很简单,就是数据库SQL语言层面的代码封装与重用。
特点
- 封装,复用
- 可以接收参数,也可以返回数据
- 减少网络交互,效率提升
语法
-
创建
CREATE PROCEDURE 存储过程名称 {[参数列表]} BEGIN -- SQL语句 END; #在命令行中,执行创建存储过程的SQL时,需要通过关键字dilimiter指定SQL语句的结束符 -
调用
CALL 存储过程名称(); -
查看
#查询指定数据库的存储过程及状态信息 SELECT * FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUNTINE_SCHEMA = 'xxx'; #查询某个存储过程的定义 SHOW CREATE PROCEDURE 存储过程名称; -
删除
DROP PROCEDURE [IF EXISTS] 存储过程名称;
变量
系统变量
系统变量是MySQL服务器提供的,属于服务器层面,分为全局变量(GLOBAL)、会话变量(SESSION)。
-
查看系统变量
#查看所有系统变量 SHOW [SESSION | GLOBAL] VARIABLES; #通过LIKE模糊匹配方式查找变量 SHOW [SESSION | GLOBAL] VARIABLES LIKE '......'; #查看指定变量的值 SELECT @@[SESSION | GLOBAL] 系统变量名; -
设置系统变量
SET [SESSION | GLOBAL] 系统变量名 = 值; SET @@[SESSION | GLOBAL] 系统变量名 = 值; -
注意:
如果没有指定SESSION/GLOBAL,默认是SESSION,会话变量。
mysql服务器重新启动之后,所设置的全局参数会失效,要想不失效,可以在/etc/my.cnf中配置。
用户定义变量
是用户根据需要自己定义的变量,用户变量不用提前声明,在用的时候直接用“@用户名”使用就可以,
用户定义变量不用提前声明,只不过获得的值是null
其作用域为当前连接。
-
赋值
SET @var_name = expr [,@var_name = expr]...; SET @var_name := expr [,@var_name := expr] ...; -
使用
SELECT @var_name;
局部变量
局部变量时需要定义在局部生效的变量,访问之前,需要DECLARE声明。可用作存储过程内的局部变量和输入参数,局部变量的范围是在其声明内的BEGIN…END块。
-
声明
DECLARE 变量名 变量类型 [DEFAULT ...]变量类型就是数据库字段类型
-
赋值
SET 变量名 = 值; SET 变量名 := 值; SELECT 字段名 INTO 变量名 FROM 表名...;
IF
IF 条件1 THEN
......
ELSEIF 条件2 THEN
......
ELSE
......
END IF;
参数
| 类型 | 含义 | 备注 |
|---|---|---|
| IN | 该类参数作为输入,也就是需要调用时传入值 | 默认 |
| OUT | 该类参数作为输出,也就是该参数可以作为返回值 | |
| INOUT | 即可以作为输入参数,也可以作为输出参数 |
用法
CREATE PROCEDURE 存储过程名称([IN/OUT/INOUT] 参数名 参数类型)
BEGIN
--SQL语句;
END;
case
-
语法一
CASE case _value WHEN when_value1 THEN statement_list1; [WHEN when_value1 THEN statement_list2]...; [ELSE statement_list] END CASE; -
语法二
CASE WHEN search_condition1 THEN statement_list1; [WHEN search_condition2 THEN statement_list2]...; [ELSE statement_list] END CASE;
while循环
while循环是有条件的循环控制语句。满足条件后再执行循环体中的SQL语句。
#先判断条件,如果条件为true,则执行逻辑,否则,不执行逻辑。
WHILE 条件 DO
SQL逻辑...;
END WHILE;
repeat循环
repeat是有条件的循环控制语句,当满足条件的时候退出循环。
#先执行一次逻辑,然后判断逻辑是否满足,如果满足,则退出。如果不满足,则继续下一次循环
REPEAT
SQL逻辑...;
UNTIL 条件
END REPEAT;
loop循环
loop实现简单的循环,如果不在SQL逻辑中增加退出循环的条件,可以用其来实现简单的死循环。
loop可以配合以下两个语句使用:
- LEAVE:配合循环使用,退出循环
- ITERATE:必须用在循环中,作用是跳过循环剩下的语句,直接进入下一次循环。
基本语法
[begin_lable:] LOOP
SQL逻辑;
END LOOP [end_lable];
LEAVE lable; -- 退出指定标记的循环体
ITERATE LABLE; -- 直接进入下一次循环
游标
游标(CURSOR)是用来存储查询结果集的数据类型,在存储过程和函数中可以使用游标对结果集进行循环的处理。游标的使用包括游标的声明、OPEN、FETCH和CLOSE 。
-
声明游标
DECLARE 游标名称 CURSOR FOR 查询语句; -
打开游标
OPEN 游标名称; -
获取游标记录
FETCH 游标名称 INTO 变量[,变量]; -
关闭游标
CLOSE 游标名称;
条件处理程序
条件处理程序(Handler)可以用来定义在流程控制结构执行过程中遇到问题时相应的处理步骤。具体语法为:
DECLARE handler_action HANDLER FOR condition_value [,condition_value] ... statement;
#handler_action
# CONTINUE:继续执行当前程序
# EXIT:终止执行当前程序
#condition_value
# SQLSTATE sqlstate_value:状态码,如02000
# SQLWARNING:所有以01开头的SQLSTATE代码的简写
# NOT FOUND:所有以02开头的SQLSTATE代码的简写
# SQLEXCEPTION:所有没有被SQLWARNING 或 NOT FOUND 捕获的SQLSTATE代码的简写
存储函数
存储函数是有返回值的存储过程,存储函数的参数只能是IN类型的。
CREATE FUNCTION 存储函数名称([参数列表])
RETURNS type [characteristic...]
BEGIN
--SQL语句
RETURN ...;
END;
characteristic说明:
- DETERMINISTIC:相同的输入参数总是产生相同的结果
- NO SQL:不包含SQL语句
- READS SQL DATA:包含读取数据的语句,但不包含写入数据的语句。
触发器
触发器是与表有关的数据库对象,指在insert/update/delete之前或之后,触发并执行触发器中定义的SQL语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性,日志记录,数据校验等操作。
使用别名OLD和NEW来引发触发器中发生变化的记录内容,这与其他数据库是相似的。现在触发器还只支持行级触发,不支持语句级触发。
| 触发器类型 | NEW 和 OLD |
|---|---|
| INSERT 型触发器 | NEW 表示将要或者已经新增的数据 |
| UPDATE 型触发器 | OLD 表示修改之前的数据, NEW 表示将要或已经修改后的数据 |
| DELETE 型触发器 | OLD 表示将要或者已经删除的数据 |
语法
-
创建
CREATE TRIGGER trigger_name BEFORE/AFTER INSERT/UPDATE/DELETE ON tbl_name FOR EACH ROW -- 行级触发器 BEGIN tigger_stmt; END; -
查看
SHOW TRIGGERS; -
删除
DROP TRIGGER [schema_name.]trigger_name;
锁
锁是计算机协调多个进程或线程并发访问某一资源的机制。在数据库中,除传统的计算资源(CUP、RAM、I/O)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。
全局锁
全局锁就是对整个数据库实例加锁,加锁后整个实例就处于只读状态,后续的DML的写语句,DDL语句,已经更新操作的事务提交语句都将被阻塞。
其典型的使用场景是做全库的逻辑备份,对所有的表进行锁定,从而获取一致性试图,保证数据的完整性。
#上锁
flush tables with read lock;
#备份
mysqldump -uroot -p1234 itcast>itcast.sql;
#开锁
unlock tables;
特点
数据库中加全局锁,是一个比较重的操作,存在以下问题:
- 如果从主库上备份,那么在备份期间都不能执行更新,业务基本上就得停摆
- 如果在从库上备份,那么在备份期间从库不能执行从主库同步过来的二进制日志(binlog),会导致主从延迟
在innodb引擎中,我们可以在备份时加上参数 --single-transaction 参数来完成不加锁的一致性数据备份
mysqldump --single-transaction -uroot -p123456 itcast > itcast.sql
表级锁
表级锁,每次操作锁住整张表。锁定力度大,,发生锁冲突的概率最高,并发度最低。
对于表级锁,主要分为以下三类:
- 表锁
- 元数据锁(meta data lock, MDL)
- 意向锁
表锁
对于表锁,分为两类
-
表共享读锁(read lock)
当前客户端和其他客户端都可以读,但都不能写
-
表独占写锁(write lock)
当前客户端可以读也可以写,其他客户端不能读也不能写
语法:
- 加锁:lock tables 表名 …read/write
- 释放锁:unlock tables / 客户端断开连接
元数据锁
MDL加锁过程是系统自动控制,无需显式使用,在访问同一张表的时候会自动加上。MDL锁的主要作用是维护表元数据的一致性,在表上有活动事务的时候,不可以对元数据进行写入操作。这是为了避免DML与DDL冲突,保证读写的正确性。
在MySQL5.5中引入了MDL,当对一张表进行增删改查的时候,加MDL读锁(共享);当对表结构进行变更操作的时候,加MDL写锁(排他)。
| 对应SQL | 锁类型 | 说明 |
|---|---|---|
| lock tables xxx read / write | SHARED_READ_ONLY / SHARED_NO_READ_WRITE | |
| select / sekect…lock in share mode | SHARED_READ | 只与EXCLUSIVE互斥 |
| insert / update / delete / select … for update | SHARED_WRITE | 只与EXCLUSIVE互斥 |
| alter table… | EXCLUSIVE | 与其它的MDL都互斥 |
意向锁
- 意向共享锁(IS) :由语句 select … lock in share mode添加
- 意向排他锁(IX) :由insert、update、delete、select … for update添加
兼容情况:
- 意向共享锁(IS) :与表锁共享锁(read)兼容,与表锁排他锁(write)互斥
- 意向排他锁(IX) :与表锁共享锁(read)及排它锁(write)都互斥。意向锁之间不会互斥
行级锁
行级锁,指的是每次操作锁住对应的行数据。锁定粒度最小,发生锁冲突的概率最低,并发度最高。
innodb的数据是基于索引组织的,行锁是通过对索引上的索引项加锁来实现的,而不是对记录加锁。
对于行级锁,主要分为以下三类:
- 行锁(Record Lock):锁定单个行记录的锁,防止其他事务对此行进行update和delete。在RC、RR隔离级别下都支持。
- 间隙锁(Gap Lock):锁定索引记录间隙(不含该记录),确保索引记录间隙不变,防止其他事务在这个间隙进行insert,产生幻读。在RR隔离级别下都支持。
- 临键锁(Next-Key Lock):行锁和间隙锁组合,同时锁住数据,并锁住数据前面的间隙Gap。在RR隔离级别下支持。
行锁
共享锁(S):允许一个事务去读一行,组织其他事务获得相同数据集的排它锁。
排它锁(X):允许获取排它锁的事务更新数据,组织其他事务获得相同数据集的共享锁和排它锁。
| 当前锁类型 \ 请求锁类型 | S | X |
|---|---|---|
| S | 兼容 | 冲突 |
| X | 冲突 | 冲突 |
| SQL | 行锁类型 | 说明 |
|---|---|---|
| INSERT | 排它锁 | 自动加锁 |
| UPDATE | 排它锁 | 自动加锁 |
| DELETE | 排它锁 | 自动加锁 |
| SELECT | 不加任何锁 | |
| SELECT … LOCK IN SHARE MODE | 共享锁 | 需要手动在SELECT之后加LOCK IN SHARE MODE |
| SELECT … FOR UPDATE | 排它锁 | 需要手动在SELECT之后加FOR UPDATE |
默认情况下,innodb在RR隔离级别运行,innodb或使用next-key锁进行搜索和索引扫描,以防止幻读。
- 针对唯一索引进行检索时,对已存在的纪录进行等值匹配时,将会自动优化为行锁。
- innodb的行锁是针对于索引加锁,不通过索引条件检索数据,那么innodb将对表中的所有记录加锁,此时就会升级为表锁。
间隙锁/临键锁
默认情况下,innodb在RR隔离级别运行,innodb或使用next-key锁进行搜索和索引扫描,以防止幻读。
- 索引上的等值查询(唯一索引),给不存在的记录加锁时,优化为间隙锁。
- 索引上的等值查询(普通索引),向右遍历时最后一个值不满足查询需求时,next-key lock退化为间隙锁。
- 索引上的范围查询(唯一索引),或访问到不满足条件的第一个值为止。
注意:间隙锁的唯一目的是防止其他事务插入间隙,间隙锁可以共存,一个事务采用的间隙锁不会阻止另一个事务在同一间隙上采用间隙锁。
InnoDB引擎
逻辑存储结构
- 表空间(ibd文件),一个mysql实例可以对应多个表空间,用于存储记录、索引等数据。
- 段,分为数据段、索引段、回滚段,InnoDB是索引组织表,数据段就是B+树的叶子节点,索引段即为B+树的非叶子节点。段用来管理多个Extent(区)
- 区,表空间的单元结构,每个区的大小为1M。默认情况下,InnoDB存储引擎页大小为16k,即一个区中共有64个连续的页。
- 页,是InnoDB存储引擎磁盘管理的最小单元,每个页的大小默认为16kb。为了保证页的连续性,InnoDB存储引擎每次从磁盘申请4-5个区。
- 行,InnoDB引擎数据是按行进行存放的,
架构
分为内存架构和磁盘架构
内存架构
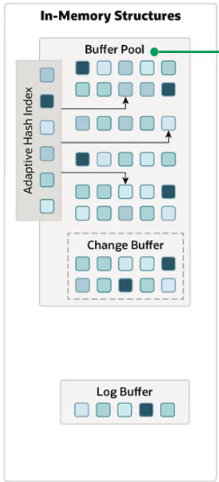
-
Buffer Pool:缓冲池
是主内存中的一个区域,里面可以缓存磁盘上经常操作的真实数据,在执行增删改查操作时,先操作缓冲池内的数据(若缓冲池没有数据,则从磁盘加载并缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
缓冲池以Page页为单位,底层采用链表数据结构管理Page。根据状态,将Page分为三种类型:
- free page:空闲page,未被使用
- clean page:被使用page,数据没有被修改过
- dirty page:脏页,被使用page,数据被修改过,页中数据与磁盘数据产生了不一致
-
Change Buffer:更改缓冲区
(针对于非唯一 二级索引页),再执行DML语句时,如果这些数据Page没有再Buffer Pool中,不会直接操作磁盘,而会将数据变更存在更改缓冲区Change Buffer中,在未来数据被读取时,在将数据合并恢复到Buffer Pool中,再将合并后的数据刷新到磁盘中。
意义:
与聚集索引不同,二级索引通常都是非唯一的,并且以相对随机的顺序插入二级索引。同样,删除和更新可能会影响索引树种不相邻的二级索引页,如果每一次都操作磁盘,会造成大量的磁盘IO。有了Change Buffer以后,我们可以在缓冲池中进行合并处理,减少磁盘IO。
-
Adaptive Hash Index:自适应hash索引
用于优化对Buffer Pool数据的查询。Innodb存储引擎如果观察到hash索引可以提升查询速度,则建立hash索引,称之为自适应hash索引。
自适应哈希索引,无需人工干预,是系统根据情况自动完成的。
参数:adaptiv_hash_index
-
Log Buffer:日志缓冲区
用来保存要写入到磁种的log日志数据(redo log、undo log),默认大小为16MB,日志缓冲区的日志会定期刷新到磁盘当中。如果需要更新、插入或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘I/O。
参数
- innodb_log_buffer_size:缓冲区大小
- innodb_flush_log_at_trx_commit:日志刷新到磁盘时机
- 1:日志在每次事务提交时写入并刷新到磁盘
- 0:每秒将日志写入并刷新到磁盘一次
- 2:日志在每次事务提交后写入,并每秒刷新到磁盘一次
磁盘结构
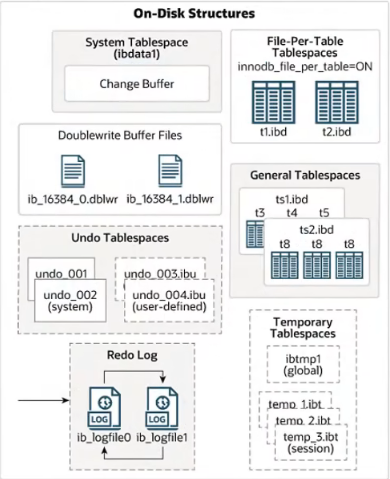
-
System Tablespace:系统表空间
是更改缓冲区存储区域。如果表是在系统表空间而不是每个表文件或通用表空间种创建的,它也有可能包含表和索引数据。(在MySQL5.x版本中还包含Innodb数据字典、undolog等);
参数:innodb_data_file_path
-
File-Per-Table Tablespaces:独立表空间
每个表的文件表空间包含单个InnoDB表的数据和索引,并存储在文件系统上的单个数据文件中。
参数:innodb_file_per_table
-
General Tablespace:通用表空间
需要通过CREATE TABLESPACE 语法创建通用表空间,在创建表时,可以指定该表空间。
-
Undo Tablespace:撤销表空间
MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储undo log日志。
-
Temporary Tablespaces:临时表空间
innodb使用会话临时表空间和全局临时表空间,存储用户创建的临时表等数据
-
Doublewrite Buffer Files:双写缓冲区
innodb引擎将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双写缓冲区文件种,便于系统异常时恢复数据。
-
Redo Log:重做日志
是用来实现事务的持久性,该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log),前者是在内存中,后者是在磁盘中。当事务提交之后会把所有修改信息都会存到该日志种,用于在刷新脏页到磁盘时,发生错误时,进行数据恢复使用。
以循环方式写入重做日志文件,涉及两个文件:ib_logfile0 和 ib_logfile1
后台线程
-
Master Thread
核心后台线程,负责调度其他线程,还负责将缓冲池中的数据异步刷新到磁盘中,保证数据的一致性,还包括脏页的刷新、合并插入缓存、undo页的回收
-
IO Thread
在innodb存储引擎中大量使用了AIO来处理IO 请求,这样可以极大地提高数据库的性能,而IO Thread主要负责这些IO请求的回调。
线程类型 默认个数 职责 Read thread 4 负责读操作 Write thread 4 负责写操作 Log thread 1 负责将日志缓冲区刷新到磁盘 Insert buffer thread 1 负责将写缓冲区内容刷新到磁盘 -
Purge Thread
主要用于回收事务已经提收了的undo log,在事务提交之后,undo log可能不用了,就用它来回收。
-
Page Cleaner Thread
协助Master Thread刷新脏页到磁盘的线程,它可以减轻 Master Thread 的工作压力,减少阻塞。
事务原理
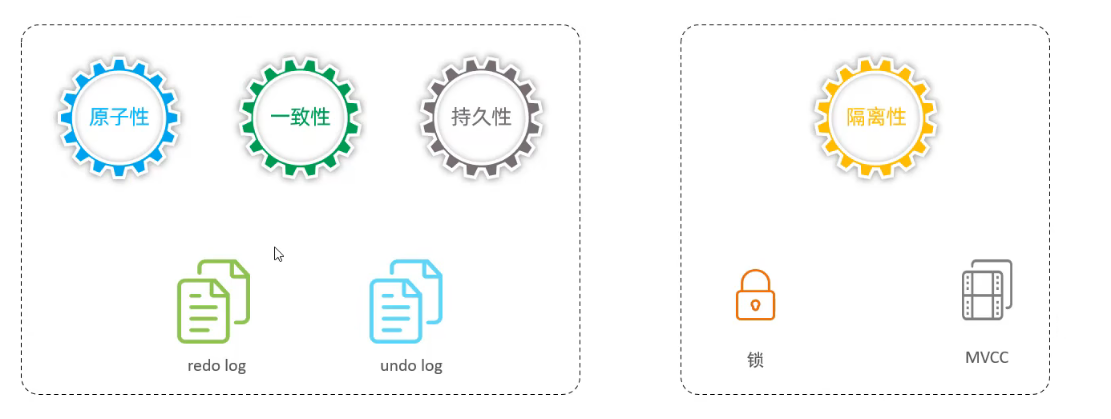
-
redo log 重做日志
记录的是事务提交时数据页的物理修改,是用来实现事务的持久性,
该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log file),前者是在内存种,后者在磁盘中,当事务提交后会把所有修改信息都存到该日志文件中,用于在刷新脏页到磁盘,发生错误时,进行数据恢复使用。
-
undo log 回滚日志
用于记录数据被修改前的信息,作用包含两个:回滚和 MVCC(多版本并发控制)。
undo log和redo log记录物理日志不一样,它是逻辑日志。可以认为**当delete一条记录时,undo log中会记录一条相应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。**当执行rollback时,就可以从undo log中的逻辑记录读取到相应的内容进行回滚。
undo log销毁:undo log在事务执行时产生,事务提交时,并不会立即删除undo log,因为这些日志可能还用于MVCC
undo log存储:undo log采用段的方式进行管理和记录,存放在前面介绍的rollback segment回滚段中,内部包含1024个undo log segment。
MVCC 多版本并发控制
-
当前读
读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。对于我们日常的操作,如:
select … lock in share mode(共享锁)、select … for update 、update 、insert、delete(排他锁)都是一种当前读。 -
快照读
简单的select(不加锁)就是快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读。
- Read Committed:每次select,都生成一个快照读
- Repeatable Read:开启事务后第一个select语句才是快照读的地方。
- Serializable:快照读会退化为当前读。
-
MVCC
多版本并发控制,指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读功能。MVCC的具体实现,还需要依赖于数据库记录中的三个隐式字段、undo log日志、readView。
记录中的隐藏字段
| 隐藏字段 | 含义 |
|---|---|
| DB_TRX_ID | 最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID |
| DB_ROLL_PTR | 回滚指针,指向这条记录的上一个版本,用于配合undo log,指向上一个版本 |
| DB_ROW_ID | 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段 |
undo log
回滚日志,在insert、update、delete的时候产生的便于数据回滚的日志
当insert的时候,产生的undo log日志只在回滚时需要,在事务提交后,可被立即删除。
当update、delete时,产生的undo log日志不仅在回滚时需要,在快照读时也需要,不会被立即删除
readview 读视图
-
readview是快照读SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id。
readview中包含了四个核心字段
字段 含义 m_ids 当前活跃的事务id min_trx_id 最小活跃事务id max_trx_id 预分配事务ID,当前最大事务ID+1(事务ID是自增的) creator_trx_id readview创建者的事务ID -
规则
trx_id:代表当前事务ID
- trx_id == creator_trx_id ? 可以访问该版本 :成立,说明数据是当前这个事务更改的
- trx_id < min_trx_id ? 可以访问该版本 :成立,说明数据已经提交了
- trx_id > max_trx_id ? 不可以访问该版本:成立,说明该事务是在readview生成之后才开启
- min_trx_id <= trx_id <= max_trx_id ? 如果trx_id不在m_ids中是可以访问该版本的:成立,说明数据已经提交
-
不同的隔离级别,生成readview的时机不同
- RC:在事务中每一次执行快照读时生成readview
- RR:仅在事务中第一次执行快照读时生成readview,后续复用该readview。
MySQL管理
MySQL数据库自带了四个数据库
| 数据库 | 含义 |
|---|---|
| mysql | 存储MySQL服务器正常运行所以需要的各种信息(时区、主从、用户、权限等) |
| information_schema | 提供了访问数据库元数据的各种表和视图,包含数据库、表、字段类型及访问权限等 |
| performance_chema | 为MySQL服务器运行时状态提供了一个底层监控功能,主要用于手机数据库服务器性能参数 |
| sys | 包含了一系列方便DBA和开发人员利用performance_schema性能数据库进行性能调优和诊断的视图 |
常用工具
-
mysql
指的是mysql的客户端工具
#语法: mysql [options] [database] #选项 -u, --user=name #指定用户名 -p,-password[=name] #指定密码 -h,--host=name #指定服务器IP或域名 -p,--port=port #指定连接端口 -e,--execute=name #执行SQL语句并退出-e选项可以在MySQL客户端执行SQL语句,而不用连接到MySQL数据库再执行,对于一些批处理脚本,这种方式尤其方便。
-
mysqladmin
是一个执行管理操作的客户端程序。可以用它来检查服务器的配置和当前状态、创建并删除数据库等。
#通过帮助文档查看选项 mysqladmin --help; -
mysqlbinlog
由于服务器生成的二进制日志文件以二进制格式保存,所以如果想要检查这些文本的文本格式,就会使用到mysqlbinlog日志管理工具。
#语法 mysqlbinlog [options] log-files1 log files2 ... #选项 -d,--database=name #指定数据库名称,只列出指定数据库相关操作 -o,--offset=# #忽略掉日志文件中的前n行命令 -r,--result-file=name #将输出的文本格式日志输出到指定文件。 -s,--short-form #显示简单格式,省略掉一些信息 --start-datatime=data1 --stop-datetime=date2 #指定日期间隔内的所有日志 --start-position=pos1 --stop-position=pos2 #指定位置间隔内的所有日志 -
mysqlshow
客户端对象查找工具,用来很快的地查找存在哪些数据库、数据库中的表、表中的列或者索引
#语法 mysqlshow [options] [db_name [table_name[col_name]]] #选项 --count 显示数据库及表的统计信息(数据库,表均可以不指定) -i 显示指定数据库或者指定表的状态信息 -
mysqldump
客户端工具用来备份数据库或在不同数据库之间进行数据迁移。备份内容包含创建表,及插入表的SQL语句。
#语法 mysqldump [options] db_name [tables] mysqldump [options] --database/-B db1 [db2 db3 ...] mysqldump [options] --all-databases/-A #输出选项 --add-drop-database #在每个数据库创建语句前加上drop database语句 --add-drop-table #在每个表创建语句前加上drop table语句,默认开启;不开启(--skip-add-drop-table) -n,-no-create-db #不包含数据库的创建语句 -t,--no-create-info #不包含数据库的创建语句 -d,--no-data #不包含数据 -T,--tab=name #自动生成两个文件:一个.sql文件,创建表结构的语句;一个.txt文件,数据文件 -
mysqlimport / source
客户端数据导入工具,用来导入mysqldump加-T参数后导出的文本文件
#语法: mysqlimport [options] db_name textfile1 [textfile2 ...] #示例 mysqlimport -uroot -p1234 test/tmp/citty.text如果需要导入sql文件,可以使用mysql中的source指令:
#语法: source/root/xxxxx.sql
JDBC
步骤
-
创建工程,导入驱动jar包
-
注册驱动
Class.forName("com.mysql.jdbc.Driver"); -
获取连接
Connection conn = DriverManager.getConnection(url,username,password); -
定义SQL语句
String sql = "update..."; -
获取执行SQL对象
Statement stmt = conn.createStatement(); -
执行SQL
stmt.executeUpdate(sql); -
处理返回结果
-
释放资源
DriverManager 驱动管理类
作用:
- 注册驱动
- 获取数据库连接
获取连接:
Connection conn = DriverManager.getConnection(url,username, password);
参数:
-
url:连接路径
//语法 jdbc:mysql://ip地址(域名):端口号/数据库名称?参数键值对1&参数键值对2... //示例 jdbc:mysql://127.0.0.1:3306/db1;-
如果连接的是本机mysql服务器,并且mysql服务器默认端口是3306,则url可以简写为
jdbc:mysql:///数据库名称?参数键值对 -
配置useSSL = false参数,禁用安全连接方式,解决警告提示
-
-
user:用户名
-
password:密码
Connection 数据库库连接对象
作用:
- 获取执行SQL的对象
- 管理事务
获取执行SQL的对象
-
普通执行SQL对象
Statement createStatement() -
预编译SQL的执行SQL对象:防止SQL注入
PreparedStatement prepareStatement(sql) -
执行存储过程的对象
CallableStatement prepareCall(sql)
事务管理
JDBC事务管理:Connection及口中定义了3个对应的方法
开启事务:setAutoCommit(boolean autoCommit):true为自动提交事务;false为手动提交事务,即为开启事务。
提交事务: commit()
回滚事务:rollbake()
Statement
执行SQL语句
int executeUpdate(sql):执行DML、DDL语句
- 返回值:DML语句影响的行数
DDL语句执行后,执行成功也可能返回0
ResultSet executeQuery(sql):执行DQL语句
- 返回值:ResultSet结果集对象
ResultSet
结果集对象
作用:
封装了DQL查询语句的结果
ResultSet stmt.executeQuery(sql) 执行DQL语句,返回Result对象
获取查询结果
boolean next()://将光标从当前位置向前移动一行,并判断当前行是否为有效行。
返回值:
- true:有效行,当前行有数据
- false:无效行,当前行没有数据
xxx getXxx(参数)://获取数据
- xxx:数据类型;如: int getInt(参数);String getString(参数)
参数:
- int:列的标号,从1开始
- String:列的名称
PreparedStatement
作用:
-
获取PreparedStatement对象
//SQL语句中的参数值,使用?代替 String sql = "select * from user where username = ? and password = ?"; //通过Connection对象获取,并传入相应的sql语句 PreparedStatement pstmt = conn.preoareStatement(sql); -
设置参数值
PreparedStatement对象:setXxx(参数1,参数2):给?赋值
原理
预编译:
- 在获取PreparedStatement对象时,将sql语句发送给mysql服务器进行检查,编译。
- 执行时就不用再执行这些步骤了,速度很快
- 如果sql模板一样,则只需要一次检查、编译。
预编译功能是默认关闭的,需要手动开启:useServerPreStmts = true。
SQL注入:将敏感字符进行转义。
数据库连接池
- 数据库连接池是个容器,负责分配、管理数据库连接(Connection)
- 它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;
- 释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏
- 好处
- 资源重用
- 提升系统响应速度
- 避免数据库连接遗漏
- 官方接口:DataSource
Druid(德鲁伊)
- Druid连接池是阿里巴巴开源的数据库连接池项目
- 功能强大,性能优秀,是Java语言最好的数据库连接池之一
使用步骤:
- 导入jar包
- 定义配置文件
- 加载配置文件
- 获取数据库连接池对象
- 获取连接
反射
反射概述
Java反射机制就是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能狗调用它的任意一个方法和属性;这种动态获取信息以及动态调用对象的方法的功能称为Java语言的反射机制。
要想解剖一个类,必须先要获取到该类的字节码文件对象。而解剖使用的就是Class类中的方法,所以下药获取到每一个字节码文件对应的Class类型的对象。
反射就是把Java类中的各种成分映射成一个个的Java对象
如图是类的正常加载过程:反射的原理在于class对象。
Class对象的由来是将class文件读入内存,并为之创建一个Class对象。
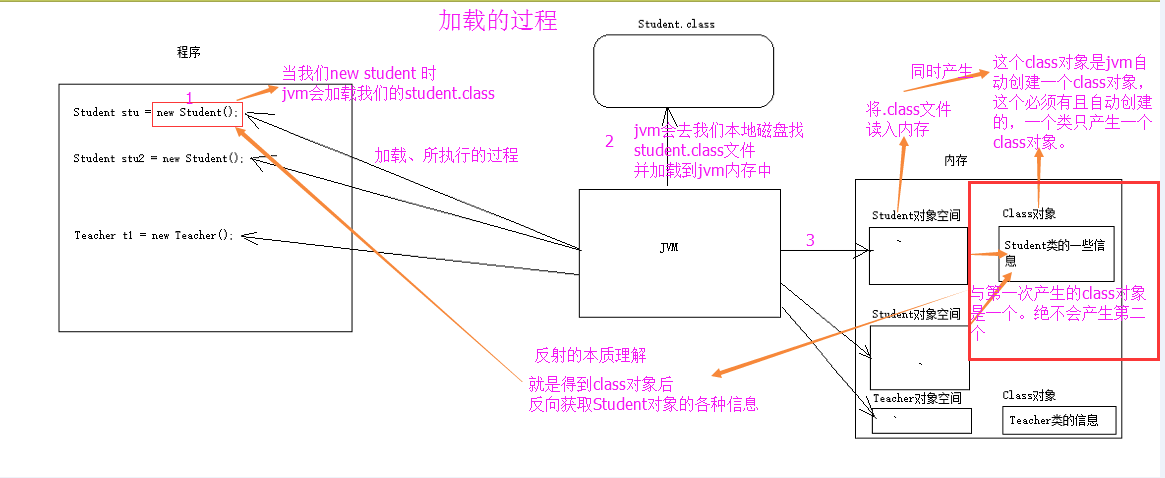
Class类的实例表示正在运行的Java应用程序中的类和接口。基本类型和关键字void也表示为类对象。
Class没有公共构造函数,类对象由Java虚拟机自动创建,加载了类并通过调用类加载器中的defineClass方法自动构造。
反射的使用
获取Class对象三种方式
- Object --> getClass();
- 任何数据类型都有一个”静态“的class属性
- 通过Class类的静态方法:forName(String className)
import Fanshe.Person;
/*
获取Class对象的三种方式
1. Object --> getClass();
2. 任何数据类型都有一个”静态“的class属性
3. 通过Class类的静态方法:forName(String className)
*/
public class Main {
public static void main(String[] args) throws ClassNotFoundException {
//第一种
Person person1= new Person();//将产生一个Person对象和一个Class对象
Class cl1 = person1.getClass();//获取Class对象
System.out.println(cl1.getName());
//二
Class cl2 = Person.class;
System.out.println(cl1 == cl2);
//三
Class cl3 = Class.forName("Fanshe.Person");//此处的字符串必须是真实路径,是包含包名的类路径,包名.类名
System.out.println(cl3 == cl2);
}
}
在运行期间,一个类,只有一个Class对象产生。
三种方式常用第三种,第一种已经有了实例就不需要反射了,第二种需要导入类的包,依赖太强。第三种一个字符床可以传入也可卸载配置文件中等多种方法。
通过反射获取构造方法并使用
student类
package fanshe;
public class Student {
//---------------构造方法-------------------
//(默认的构造方法)
Student(String str){
System.out.println("(默认)的构造方法 s = " + str);
}
//无参构造方法
public Student(){
System.out.println("调用了公有、无参构造方法执行了。。。");
}
//有一个参数的构造方法
public Student(char name){
System.out.println("姓名:" + name);
}
//有多个参数的构造方法
public Student(String name ,int age){
System.out.println("姓名:"+name+"年龄:"+ age);//这的执行效率有问题,以后解决。
}
//受保护的构造方法
protected Student(boolean n){
System.out.println("受保护的构造方法 n = " + n);
}
//私有构造方法
private Student(int age){
System.out.println("私有的构造方法 年龄:"+ age);
}
}
测试
package fanshe;
import java.lang.reflect.Constructor;
/*
* 通过Class对象可以获取某个类中的:构造方法、成员变量、成员方法;并访问成员;
*
* 1.获取构造方法:
* 1).批量的方法:
* public Constructor[] getConstructors():所有"公有的"构造方法
public Constructor[] getDeclaredConstructors():获取所有的构造方法(包括私有、受保护、默认、公有)
* 2).获取单个的方法,并调用:
* public Constructor getConstructor(Class... parameterTypes):获取单个的"公有的"构造方法:
* public Constructor getDeclaredConstructor(Class... parameterTypes):获取"某个构造方法"可以是私有的,或受保护、默认、公有;
*
* 调用构造方法:
* Constructor-->newInstance(Object... initargs)
*/
public class Constructors {
public static void main(String[] args) throws Exception {
//1.加载Class对象
Class clazz = Class.forName("fanshe.Student");
//2.获取所有公有构造方法
System.out.println("**********************所有公有构造方法*********************************");
Constructor[] conArray = clazz.getConstructors();
for(Constructor c : conArray){
System.out.println(c);
}
System.out.println("************所有的构造方法(包括:私有、受保护、默认、公有)***************");
conArray = clazz.getDeclaredConstructors();
for(Constructor c : conArray){
System.out.println(c);
}
System.out.println("*****************获取公有、无参的构造方法*******************************");
Constructor con = clazz.getConstructor(null);
//1>、因为是无参的构造方法所以类型是一个null,不写也可以:这里需要的是一个参数的类型,切记是类型
//2>、返回的是描述这个无参构造函数的类对象。
System.out.println("con = " + con);
//调用构造方法
Object obj = con.newInstance();
// System.out.println("obj = " + obj);
// Student stu = (Student)obj;
System.out.println("******************获取私有构造方法,并调用*******************************");
con = clazz.getDeclaredConstructor(char.class);
System.out.println(con);
//调用构造方法
con.setAccessible(true);//暴力访问(忽略掉访问修饰符)
obj = con.newInstance('男');
}
}
//输出
/*
**********************所有公有构造方法*********************************
public fanshe.Student(java.lang.String,int)
public fanshe.Student(char)
public fanshe.Student()
************所有的构造方法(包括:私有、受保护、默认、公有)***************
private fanshe.Student(int)
protected fanshe.Student(boolean)
public fanshe.Student(java.lang.String,int)
public fanshe.Student(char)
public fanshe.Student()
fanshe.Student(java.lang.String)
*****************获取公有、无参的构造方法*******************************
con = public fanshe.Student()
调用了公有、无参构造方法执行了。。。
******************获取私有构造方法,并调用*******************************
public fanshe.Student(char)
姓名:男
进程已结束,退出代码0
*/
获取成员变量并调用
package fanshe.field;
public class Student {
public Student(){
}
//**********字段*************//
public String name;
protected int age;
char sex;
private String phoneNum;
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + ", sex=" + sex
+ ", phoneNum=" + phoneNum + "]";
}
}
package fanshe.field;
import java.lang.reflect.Field;
/*
* 获取成员变量并调用:
*
* 1.批量的
* 1).Field[] getFields():获取所有的"公有字段"
* 2).Field[] getDeclaredFields():获取所有字段,包括:私有、受保护、默认、公有;
* 2.获取单个的:
* 1).public Field getField(String fieldName):获取某个"公有的"字段;
* 2).public Field getDeclaredField(String fieldName):获取某个字段(可以是私有的)
*
* 设置字段的值:
* Field --> public void set(Object obj,Object value):
* 参数说明:
* 1.obj:要设置的字段所在的对象;
* 2.value:要为字段设置的值;
*
*/
public class Fields {
public static void main(String[] args) throws Exception {
//1.获取Class对象
Class stuClass = Class.forName("fanshe.field.Student");
//2.获取字段
System.out.println("************获取所有公有的字段********************");
Field[] fieldArray = stuClass.getFields();
for(Field f : fieldArray){
System.out.println(f);
}
System.out.println("************获取所有的字段(包括私有、受保护、默认的)********************");
fieldArray = stuClass.getDeclaredFields();
for(Field f : fieldArray){
System.out.println(f);
}
System.out.println("*************获取公有字段**并调用***********************************");
Field f = stuClass.getField("name");
System.out.println(f);
//获取一个对象
Object obj = stuClass.getConstructor().newInstance();//产生Student对象--》Student stu = new Student();
//为字段设置值
f.set(obj, "刘德华");//为Student对象中的name属性赋值--》stu.name = "刘德华"
//验证
Student stu = (Student)obj;
System.out.println("验证姓名:" + stu.name);
System.out.println("**************获取私有字段****并调用********************************");
f = stuClass.getDeclaredField("phoneNum");
System.out.println(f);
f.setAccessible(true);//暴力反射,解除私有限定
f.set(obj, "18888889999");
System.out.println("验证电话:" + stu);
}
}
/*
************获取所有公有的字段********************
public java.lang.String fanshe.field.Student.name
************获取所有的字段(包括私有、受保护、默认的)********************
public java.lang.String fanshe.field.Student.name
protected int fanshe.field.Student.age
char fanshe.field.Student.sex
private java.lang.String fanshe.field.Student.phoneNum
*************获取公有字段**并调用***********************************
public java.lang.String fanshe.field.Student.name
验证姓名:刘德华
**************获取私有字段****并调用********************************
private java.lang.String fanshe.field.Student.phoneNum
验证电话:Student [name=刘德华, age=0, sex=
*/
获取成员方法并调用
package fanshe.method;
public class Student {
//**************成员方法***************//
public void show1(String s){
System.out.println("调用了:公有的,String参数的show1(): s = " + s);
}
protected void show2(){
System.out.println("调用了:受保护的,无参的show2()");
}
void show3(){
System.out.println("调用了:默认的,无参的show3()");
}
private String show4(int age){
System.out.println("调用了,私有的,并且有返回值的,int参数的show4(): age = " + age);
return "abcd";
}
}
package fanshe.method;
import java.lang.reflect.Method;
/*
* 获取成员方法并调用:
*
* 1.批量的:
* public Method[] getMethods():获取所有"公有方法";(包含了父类的方法也包含Object类)
* public Method[] getDeclaredMethods():获取所有的成员方法,包括私有的(不包括继承的)
* 2.获取单个的:
* public Method getMethod(String name,Class<?>... parameterTypes):
* 参数:
* name : 方法名;
* Class ... : 形参的Class类型对象
* public Method getDeclaredMethod(String name,Class<?>... parameterTypes)
*
* 调用方法:
* Method --> public Object invoke(Object obj,Object... args):
* 参数说明:
* obj : 要调用方法的对象;
* args:调用方式时所传递的实参;
):
*/
public class MethodClass {
public static void main(String[] args) throws Exception {
//1.获取Class对象
Class stuClass = Class.forName("fanshe.method.Student");
//2.获取所有公有方法
System.out.println("***************获取所有的”公有“方法*******************");
stuClass.getMethods();
Method[] methodArray = stuClass.getMethods();
for(Method m : methodArray){
System.out.println(m);
}
System.out.println("***************获取所有的方法,包括私有的*******************");
methodArray = stuClass.getDeclaredMethods();
for(Method m : methodArray){
System.out.println(m);
}
System.out.println("***************获取公有的show1()方法*******************");
Method m = stuClass.getMethod("show1", String.class);
System.out.println(m);
//实例化一个Student对象
Object obj = stuClass.getConstructor().newInstance();
m.invoke(obj, "刘德华");
System.out.println("***************获取私有的show4()方法******************");
m = stuClass.getDeclaredMethod("show4", int.class);
System.out.println(m);
m.setAccessible(true);//解除私有限定
Object result = m.invoke(obj, 20);//需要两个参数,一个是要调用的对象(获取有反射),一个是实参
System.out.println("返回值:" + result);
}
}
/*
***************获取所有的”公有“方法*******************
public void fanshe.method.Student.show1(java.lang.String)
public final void java.lang.Object.wait(long,int) throws java.lang.InterruptedException
public final native void java.lang.Object.wait(long) throws java.lang.InterruptedException
public final void java.lang.Object.wait() throws java.lang.InterruptedException
public boolean java.lang.Object.equals(java.lang.Object)
public java.lang.String java.lang.Object.toString()
public native int java.lang.Object.hashCode()
public final native java.lang.Class java.lang.Object.getClass()
public final native void java.lang.Object.notify()
public final native void java.lang.Object.notifyAll()
***************获取所有的方法,包括私有的*******************
public void fanshe.method.Student.show1(java.lang.String)
private java.lang.String fanshe.method.Student.show4(int)
protected void fanshe.method.Student.show2()
void fanshe.method.Student.show3()
***************获取公有的show1()方法*******************
public void fanshe.method.Student.show1(java.lang.String)
调用了:公有的,String参数的show1(): s = 刘德华
***************获取私有的show4()方法******************
private java.lang.String fanshe.method.Student.show4(int)
调用了,私有的,并且有返回值的,int参数的show4(): age = 20
返回值:abcd
*/
反射main方法
package fanshe.main;
public class Student {
public static void main(String[] args) {
System.out.println("main方法执行了。。。");
}
}
package fanshe.main;
import java.lang.reflect.Method;
/**
* 获取Student类的main方法、不要与当前的main方法搞混了
*/
public class Main {
public static void main(String[] args) {
try {
//1、获取Student对象的字节码
Class clazz = Class.forName("fanshe.main.Student");
//2、获取main方法
Method methodMain = clazz.getMethod("main", String[].class);//第一个参数:方法名称,第二个参数:方法形参的类型,
//3、调用main方法
// methodMain.invoke(null, new String[]{"a","b","c"});
//第一个参数,对象类型,因为方法是static静态的,所以为null可以,第二个参数是String数组,这里要注意在jdk1.4时是数组,jdk1.5之后是可变参数
//这里拆的时候将 new String[]{"a","b","c"} 拆成3个对象。。。所以需要将它强转。
methodMain.invoke(null, (Object)new String[]{"a","b","c"});//方式一
// methodMain.invoke(null, new Object[]{new String[]{"a","b","c"}});//方式二
} catch (Exception e) {
e.printStackTrace();
}
}
}
反射方法的其他使用之一——通过反射运行配置文件内容
public class Student {
public void show(){
System.out.println("is show()");
}
}
配置文件以txt文件为例子(pro.txt):
className = cn.fanshe.Student
methodName = show
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.lang.reflect.Method;
import java.util.Properties;
/*
* 我们利用反射和配置文件,可以使:应用程序更新时,对源码无需进行任何修改
* 我们只需要将新类发送给客户端,并修改配置文件即可
*/
public class Demo {
public static void main(String[] args) throws Exception {
//通过反射获取Class对象
Class stuClass = Class.forName(getValue("className"));//"cn.fanshe.Student"
//2获取show()方法
Method m = stuClass.getMethod(getValue("methodName"));//show
//3.调用show()方法
m.invoke(stuClass.getConstructor().newInstance());
}
//此方法接收一个key,在配置文件中获取相应的value
public static String getValue(String key) throws IOException{
Properties pro = new Properties();//获取配置文件的对象
FileReader in = new FileReader("pro.txt");//获取输入流
pro.load(in);//将流加载到配置文件对象中
in.close();
return pro.getProperty(key);//返回根据key获取的value值
}
}
反射方法的其它使用之—通过反射越过泛型检查
泛型用在编译期,编译过后泛型擦除(消失掉)。所以是可以通过反射越过泛型检查的
import java.lang.reflect.Method;
import java.util.ArrayList;
/*
* 通过反射越过泛型检查
*
* 例如:有一个String泛型的集合,怎样能向这个集合中添加一个Integer类型的值?
*/
public class Demo {
public static void main(String[] args) throws Exception{
ArrayList<String> strList = new ArrayList<>();
strList.add("aaa");
strList.add("bbb");
// strList.add(100);
//获取ArrayList的Class对象,反向的调用add()方法,添加数据
Class listClass = strList.getClass(); //得到 strList 对象的字节码 对象
//获取add()方法
Method m = listClass.getMethod("add", Object.class);
//调用add()方法
m.invoke(strList, 100);
//遍历集合
for(Object obj : strList){
System.out.println(obj);
}
}
}
/*
aaa
bbb
100
*/
第十四章 注解
从JDK 5开始,Java增加了对元数据 (MetaDate)的支持,也就是Annotation(即注解),注解其实是代码中的特殊标记,这些标记可以在编译、类加载、运行时被读取,并执行相应的处理,通过使用注解,可以在不改变原有逻辑的情况下,在源文件中嵌入一些补充的信息。代码分析工具、开发工具和部署工具可以通过这些补充信息进行验证或者进行部署。
注解提供了一种为程序元素设置元数据的方法,从某些方面来看,注解就像修饰符一样,可用于修饰包、类、构造器、方法、成员变量、参数、局部变量的生命,这些信息被存储在注解的"name = value"对中。
注解不影响程序代码的执行,无论增加、删除注解,代码都始终如一地执行。如果希望让程序中的注解在运行时其一定的作用,只有通过其配套的APT工具对注解中的信息进行访问和处理。
基本注解
注解必须使用工具来处理,工具负责提取注解里包含的元数据,还会根据这些元数据增加额外的功能。
Java提供了5个基本注解,用法是在其前面增加@符号,并把该注解当成一个修饰符使用吗,用于修饰它支持的程序元素。
- @Override
- @Deprecated
- @SuppressWarning
- @SafeVarargs
- @FunctionalInterface
这些基本注解都定义在java.lang包下。
限定重写父类方法:@Override
用来指定方法覆载的,它可以强制一个子类必须覆盖父类的方法。
如果一个方法被标记为@Override,但是它并没有重写父类中的任何方法,那么编译器就会报错。
以下是一个简单的示例,演示了如何使用@Override注解来重写父类中的方法:
class Animal {
public void makeSound() {
System.out.println("The animal makes a sound");
}
}
class Dog extends Animal {
@Override
public void makeSound() {
System.out.println("The dog barks");
}
}
@override只能修饰方法,不能修饰其他程序元素
过时 @Deprecated
用于表示某个程序元素(类,方法等)已过时,当其他程序使用已过时的类、方法时,编译器将会给出警告。
Java9为@Deprecated注解增加了如下两个属性:
- forRemoval:该boolean类型的属性指定该API在将来是否会被删除。
- since:该String类型的属性指定该API从哪个版本被标记为过时。
抑制编译器警告@SuppressWarnings
@SuppressWarningszhi是被该注解修饰的程序元素(以及该程序元素中的所有子元素)取消显示指定的编译器警告。@SuppressWarnings会抑制作用于该程序元素的所有子元素,例如,使用@SuppressWarning修饰某个类取消显示某个编译器警告,同时又修饰该类里的某个方法取消显示另一个编译器警告,那么该方法将会同时取消显示这两个编译器警告。
以下是一个示例,演示了如何同时取消显示多个编译器警告:
@SuppressWarnings({"unchecked", "rawtypes"})
public class MyClass {
@SuppressWarnings("unused")
public void myMethod() {
List myList = new ArrayList();
Object myObject = myList.get(0);
}
}
在上面的示例中,我们使用了两个参数的@SuppressWarnings注解来取消显示未经检查的警告和原始类型的警告。这个注解应用于整个MyClass类,因此这些警告将在整个类中被取消显示。
我们还在MyClass类的myMethod()方法中使用了一个单参数的@SuppressWarnings注解来取消显示未使用变量的警告。由于这个注解只应用于该方法,因此只会在该方法中取消显示未使用变量的警告。
“堆污染”警告与@SafeVarargs
如下代码可能导致运行时异常
List list = new ArrayList<Integer>();
list.add(20);//添加元素时引发unchecked异常
//下面代码引起“胃镜检查的转换”的警告,编译、运行时完全正常
List<String> ls = list;
//但只要访问ls里的元素,如下面代码就会引起运行时异常
System.out.println(ls.get(0));
Java把这种引发错误的原因称为“堆污染”,当把一个不带泛型的对象赋给一个带泛型的变量时,往往就会发生这种“堆污染”。
对于形参个数可变的方法,该形参的类型又是泛型,浙江更容易导致“堆污染”
public class ErrorUtils{
public static void faultyMethod(List<String>... ListStrArray) {
//Java语言不允许创建泛型数组,因此ListArray只能被当成List[]处理
//此时相当于把List<String>赋给了List,已经发生了“堆污染”
List[] listArray = listStrArray;
List<Integer> myList = new ArrayList<>();
myList.add(new Random().nextInt(100));
//把listArray第一个元素赋为myArray
listArray[0] = myList;
String s = ListStrArray[0].get(0);
}
}
上面程序中的 List[] listArray = listStrArray; 已经发生了 “堆污染”。由于该方法有个形参是List…类型,个数可变的形参相当于数组,但Java又不支持泛型数组,因此程序只能把List…当成List[]处理,这里就发生了“堆污染”。
有些时候,开发者不希望看到堆污染警告,则可以使用如下三种方式来“抑制”这个警告。
- 使用@SafeVarargs修饰引发该警告的方法或构造器。Java 9增强了该注解,允许使用该注解修饰私有实例方法。
- 使用@SuppressWarnings(“unchecked”)修饰。
- 编译时使用-Xlint:varargs选项
第三种方式一般比较少用,通常可以选择第一种或第二种方式,尤其是使用@SafeVarargs修饰引发警告的方法或构造器,它是Java 7专门为抑制“堆污染”警告提供的。
函数式接口与@FunctionalInterface
如果接口中只有一个抽象方法,该接口就是函数式接口。
@FunctionalInterface就是用来指定某个接口必须是函数式接口。
JDK的元注解
JDK除在java.lang下提供了5个基本注解之外,还在java.lang.annotation包下提供了6个Meta注解,其中有5个元注解都用与修饰其他的注解定义。
使用@Retention
@Retention只能用于修饰注解定义,用于指定被修饰的注解可以保留多长时间,@Retention包含一个RetentionPolicy类型的value成员变量,所以使用@Retention时必须为该value成员变量指定值。
value成员变量的值只能是如下三个:
- RetentionPolicy,CLASS:编译器将把注解记录在class文件中。当运行Java程序时,JVM不可获取注解信息。这是默认值。
- RetentionPolicy.RUNTIME:编译器将把注解记录在class文件中。当运行Java程序时,JVM也可获取注解信息,程序可以通过反射获取该注解信息。
- RetentionPolicy.SOURCE:注解只保留在源代码中,编译器直接丢弃这种注解。
如果需要通过反射获取注解信息,就需要使用value属性值为Retention.RUNTIME的@Retention。使用@Retention原直接可采用如下代码为value指定值。
//定义下面的@Testable注解保留到运行时
@Retention(value = RetentionPolicy.RUNTIME)
public @interface Testable{}
也可采用如下代码来为value指定值
@Retention(RetentionPolicy.SOURCE)
public @interface Testable{}
如过使用注解时只需要为value成员变量指定值,则使用该注解时可以直接在该注解后的括号里指定value成员变量的值,无需使用"value = 变量值"的形式。
使用@Target
@Target也只能修饰注解定义,它用于指定被修饰的注解能用于修饰哪些程序单元。@Target元注解也包含一个value成员变量
- ElementType.ANNOTATION_TYPE:指定该策略的注解只能修饰注解
- ElementType.CONSTRUCTOR:指定该策略的注解只能修饰构造器
- ElementType.FIELD:指定该策略的注解只能修饰成员变量
- ElementType.LOCAL_VARIABLE:指定该策略的注解只能修饰局部变量。
- ElementType.METHOD:只能修饰方法定义
- ElementType.PACKAGE:只能修饰包定义
- ElementType.PARAMETER:可以修饰参数
- ElementType.TYPE:可以修饰类、接口(包括注解类型)或枚举定义
如下段代码指定@ActionListenerFor注解只能修饰成员变量
@Target(ElementType.FIELD)
public @interface ActionListenerFor{}
使用@Documented
@Documented用于指定被修饰的注解类将被javadoc工具提取成文档,如果定义注解类时使用了@Decument修饰,则所有使用该注解修饰的程序元素的API文档中将会包含该注解说明。
下面代码定义了一个Testable注解,使用@Decumented修饰,所以该注解将被javadoc工具所提取。
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Documented //javadoc工具生成的API文档将提取@Testable的使用信息。
public @interface Testable{}
加
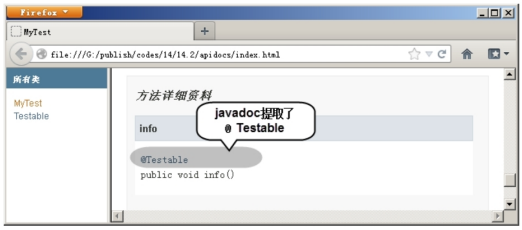
不加
使用@Inherited
@Inherited元注解执行被它修饰的注解将具有继承性——如果某个类使用了@Xxx注解(定义该注解时使用了@Inherited修饰)修饰,则其子类将自动被@Xxx修饰。
自定义注解
定义注解
定义新的注解类型使用@interface关键字定义一个新的注解类型与定义一个接口非常像,如下代码可定义一个简单的注解类型
public @interface Test{}
定义了该注解之后,就可以再程序的任何地方使用该注解,使用注解的语法非常类似于public、final这样的修饰符,通常可用于修饰程序中的类、方法、变量、接口等定义。通常会把注解放在所有修饰符之前,并将注解另放一行。
在默认情况下,注解可用于修饰任何程序元素,包括类、接口、方法等。
注解不仅可以是这种简单的注解,还可以带成员变量,成员变量在注解定义中以无形参的方法形式来声明,其方法名和返回值定义了该成员变量的名字和类型。如下代码可以定义一个有成员变量的注解
public @interface MyTag{
//定义带两个成员变量的注解
//注解中的成员变量以方法的形式来定义
String name();
int age();
}
使用@interface定义的注解的确非常像定义了一个注解接口,这个注解接口继承了java.lang.annotation.Annotation接口,这一点可以通过反射看到MyTag接口里包含了java.lang.annotation.Annotation接口里的方法。
一旦再注解里定义了成员变量之后,使用该注解时就应该为它的成员变量指定值,如下面代码:
public class Test{
@MyTag(name = "xx", age = 4)
public void info(){
}
}
也可以定义注解的成员变量时为其指定初始值(默认值),指定成员变量的初始值可以使用default关键字。
public @interface MyTag{
//定义带两个成员变量的注解
//注解中的成员变量以方法的形式来定义
String name() defalult "yeeku";
int age() default 32;
}
如果为注解的成员变量指定了默认值,使用该注解时可以不指定成员变量值,直接使用默认值。
根据注解是否可以包含成员变量,可以把注解分为如下两类:
- 标记注解:没有定义成员变量的注解类型被称为标记。这种注解仅利用自身的存在与否来提供信息,如前面介绍的@Override注解
- 元数据注解:包含成员变量的注解,因为它们可以接受更多的元数据,所以也被称为元数据注解
提取注解信息
使用注解修饰了类、方法、成员变量等成员之后,这些注解必须使用由开发者提供的工具来提取并处理注解信息
Java使用java.lang.annotation.Annotation接口来代表程序元素前面的注解,该接口时所有注解的父接口。Java5在java.lang.reflect包下新增了AnnotationElement接口,该接口代表程序中可以接受注解的程序元素。该接口主要有如下几个实现类:
- Class:类定义
- Constructor:构造器定义
- Filed:类的成员变量定义
- Method:类的方法定义
- Package:类的包定义
java.lang.reflect包下主要包含一些实现反射功能的工具类,从Java5开始,java.lang.reflect包所提供反射API增加了读取运行时注解的能力。只有当定义注解时使用了**@Retention(RetentionPolicy,RUNTIME)修饰**,该注解才会在运行时可见,JVM才会在装载 *.class 文件时读取保存在class文件中的注解信息。
AnnotatedElement接口是所有程序元素的父接口,所以程序通过反射获取了某个类的AnnotatedElement对象(如Class、Method、Constructor等)之后,程序就可以调用该对象的如下几个方法来访问注解信息
- getAnnotation(Class annotationClass):返回该程序元素上存在的、指定类型的注解,如果该类型的注解不存在,则返回null
- getDeclaredAnnotation(Class annotationClass) : 这 是 Java 8新增的方法,该方法尝试获取直接修饰该程序元素、指定类型的注解。如果该类型的注解不存在,则返回null。
- Annotation[] getAnnotations():返回该程序元素上存在的所有注解。
- Annotation[] getDeclaredAnnotations():返回直接修饰该程序元素的所有注解。
- boolean isAnnotationPresent(Class< ?extends Annotation> annotationClass):判断该程序元素上是否存在 指定类型的注解,如果存在则返回true,否则返回false。
- < A extens Annotation > A[] getAnnotationsByType(Class< A > annotationClass) : 该 方 法 的功能与前面介绍的getAnnotation()方法基本相似。但由于 Java 8增加了重复注解功能,因此需要使用该方法获取修饰该程序元素、指定类型的多个注解。
- < A extens Annotation > A[] getDeclaredAnnotationsByType(Class< A > annotationClass) : 该 方 法 的 功 能 与 前 面 介 绍 的 getDeclaredAnnotations()方法基本相似。但由于Java 8增加了重复注解功能,因此需要使用该方法获取直接修饰该程序元素、指定类型的多个注解。
下面的程序片段用于获取Test类的info方法里的所有注解
//获取Test类的info方法的所有注解
Annotation[] aArray = Class.forName("Test").getMethod("info").getAnnotations();
需要获取某个注解里的元数据时,可以将注解强制类型转换成所需的注解类型,然后通过注解对象的抽象方法来访问这些元数据。
Annotation[] annotation = tt.getClass().getMethod("info").getAnnotations();
for (Annotation tag:annotation) {
if (tag instanceof MyTag1) {
System.out,printIn("Tag is:" + tag);
System.out,printIn("tag.name():" + ((Method1)tag).method1());
}
if (tag instanceof MyTag2) {
System.out,printIn("Tag is:" + tag);
System.out,printIn("tag.name():" + ((Method2)tag).method1());
}
}
使用注解的实例
第一个注解@Testable没有任何成员变量,仅是一个标记注解,它的作用是标记哪些方法是可测试的。
package test;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
import java.lang.reflect.Method;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Testable {
}
上面程序定义了一个@Testable注解,定义该注解时使用了 @Retention和@Target两个JDK的元注解,其中@Retention注解指定 Testable注解可以保留到运行时(JVM可以提取到该注解的信息),而 @Target注解指定@Testable只能修饰方法。
如下MyTest测试用例中定义了8个方法,这8个方法没有太大的区 别,其中4个方法使用@Testable注解来标记这些方法是可测试的。
package test;
public class MyTest {
@Testable
public static void m1(){}
public static void m2(){}
@Testable
public static void m3(){
throw new IllegalArgumentException("参数出错了");
}
public static void m4(){}
@Testable
public static void m5(){}
public static void m6(){}
@Testable
public static void m7(){
throw new RuntimeException("程序业务出现异常!");
}
public static void m8(){}
}
正如前面提到的,仅仅使用注解来标记程序元素对程序是不会有 任何影响的,这也是Java注解的一条重要原则。为了让程序中的这些 注解起作用,接下来必须为这些注解提供一个注解处理工具
下面的注解处理工具会分析目标类,如果目标类中的方法使用了 @Testable注解修饰,则通过反射来运行该测试方法。
package test;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class ProcessorTest {
public static void process(String clazz) throws ClassNotFoundException {
int passed = 0;
int failed = 0;
for (Method m : Class.forName(clazz).getMethods()) {
if (m.isAnnotationPresent(Testable.class)) {
try {
m.invoke(null);
passed++;
} catch (Exception e) {
System.out.println("方法" + m + "运行失败,异常:" + e.getCause());
failed++;
}
}
}
System.out.println("共运行了:" + (passed + failed) + "个方法, 其中: \n" + "失败了:" + failed + "个,\n" + "成功了:" + passed + "个");
}
}
ProcessorTest类里只包含一个process(String clazz)方法,该 方法可接收一个字符串参数,该方法将会分析clazz参数所代表的类, 并运行该类里使用@Testable修饰的方法。 该程序的主类非常简单,提供主方法,使用ProcessorTest来分析 目标类即可。
package test;
public class RunTest {
public static void main(String[] args) throws ClassNotFoundException {
ProcessorTest.process("test.MyTest");
}
}
运行上面程序,会看到如下运行结果:
方法public static void test.MyTest.m3()运行失败,异常:java.lang.IllegalArgumentException: 参数出错了
方法public static void test.MyTest.m7()运行失败,异常:java.lang.RuntimeException: 程序业务出现异常!
共运行了:4个方法, 其中:
失败了:2个,
成功了:2个
通过这个运行结果可以看出,程序中的@Testable起作用了, MyTest类里以@Testable注解修饰的方法都被测试了。
其实注解十分简单,它是对源代码增加的一些特殊标记,这些特殊标记可通过反射获取,当程序获取这些特殊标记后,程序可以做出相应的处理(当然也可以完全忽 略这些注解)。
重复注解
在Java8之前,同一个程序元素前最多只能使用一个相同类型的注解;如果需要在同一个元素前使用多个相同类型的注解,则必须使用注解“容器”。例如在Struts 2开发中,有时需要在Action类上使 用多个@Result注解。在Java 8以前只能写成如下形式:
@Results({@Result(name = "failure", location = "failed.jsp"),@Result(name = "success",location = "succ.jsp")})
public Action FooAction{...}
实质是,@Results注解只包含一个名字为 value、类型为Result[]的成员变量,程序指定的多个@Result将作为 @Results的value属性(数组类型)的数组元素
从Java 8开始,上面语法可以得到简化:Java 8允许使用多个相 同类型的注解来修饰同一个类,因此上面代码可能(之所以说可能, 是因为重复注解还需要对原来的注解进行改造)可简化为如下形式:
@Result(name = "failure", location = "failed.jsp")
@Result(name = "success",location = "succ.jsp")
public Action FooAction{...}
开发重复注解需要使用**@Repeatable修饰**
下面通过示例来示范如 何开发重复注解。首先定义一个FKTag注解。
package Fk;
import java.lang.annotation.*;
@Repeatable(FkTags.class)
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface FkTag {
String name();
int age();
}
使用@Repeatable时必须为value成员变量指定值,该成员变量的值应该是一个“容器”注解——该“容器”注解可包含多个@FkTag,
package Fk;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface FkTags {
FkTag[] value();
}
该代码定义了一个FkTag[]类型的value成员变量,这意味着 @FkTags注解的value成员变量可接受多个@FkTag注解,因此@FkTags注 解可作为@FkTag的容器。
“容器”注解的保留期必须比它所包含的注解的保留期更长, 否则编译器会报错。
package Fk;
@FkTag(name = "666", age = 5)
@FkTag(name = "疯狂java",age = 9)
public class FkTagTest {
public static void main(String[] args) {
Class<FkTagTest> clazz = FkTagTest.class;
/*
使用Java 8新增的getDeclaredAnnotationsByType方法获取
*/
FkTag[] tags = clazz.getDeclaredAnnotationsByType(FkTag.class);
for (FkTag tag: tags) {
System.out.println(tag.name() + "--->" + tag.age());
}
/*
使用传统的getDeclaredAnnotation方法获取@FkTags注解
*/
FkTags container = clazz.getDeclaredAnnotation(FkTags.class);
System.out.println(container);
/*
虽然上面源代码中并未显式使用@FkTags注解,但由于
程序使用了两个@FkTag注解修饰该类,因此系统会自动将两个@FkTag
注解作为@FkTags的value成员变量的数组元素处理。因此,代码将可以成功地获取到@FkTags注解。
*/
}
}
重复注解只是一种简化写法,这种简化写法是一种假象:多个 重复注解其实会被作为“容器”注解的value成员变量的数组元素。 例如上面的重复的@FkTag注解其实会被作为@FkTags注解的value成 员变量的数组元素处理。
类型注解
Java8为ElementType枚举增加了TYPE_PARAMETER、TYPE_USE两个枚举值,这样就允许定义注解时使用@Target(Element.TYPE_USE)修饰,这种注解被称为类型注解,类型注解可用于修饰在任何地方出现的类型。
在Java8之前,只能在定义各种程序元素(定义类、定义接口、定义方法、定义成员变量……)时使用注解。从Java8开始,类型注解可以修饰任何地方出现的类型。比如,允许在如下位置使用类型注解:
- 创建对象(用new关键字创建)
- 类型转换
- 使用implements实现接口
- 使用throws声明抛出异常
上面这些情形都会用到类型,因此都可以使用类型注解来修饰
package TAT;
import javax.swing.*;
import java.io.FileNotFoundException;
import java.lang.annotation.ElementType;
import java.lang.annotation.Target;
import java.util.List;
@Target(ElementType.TYPE_USE)
@interface NotNull{}
public class TypeAnnotationTest{
public static void main(@NotNull String[] args) throws @NotNull FileNotFoundException {
Object obj = "fkjava.org";
String str = (@NotNull String) obj;
Object win = new @NotNull JFrame("疯狂软件");
}
public void foo(List<@NotNull String> info){}
}
/*
上面的代码都是可正常使用类型注解的例子,从这个示例
可以看到,Java程序到处“写满”了类型注解,这种“无处不在”的
类型注解可以让编译器执行更严格的代码检查,从而提高程序的健壮
性。
*/
编译时处理注解
APT是一种注解处理工具,它对源代码文件进行检测,并找出源文件所包含的注解信息,然后针对注解信息进行额外的处理。
使用APT工具处理注解时可以根据源文件中的注解生成额外的源文件和其他的文件(文件的具体内容由注解处理器的编写者决定),APT还会编译生成的源代码文件和原来的源文件,将它们一起生成class文件。
使用APT的主要目的是简化开发者的工作量,因为APT可以在编译程序源代码的同时生成一些负数文件(比如源文件、类文件、程序发布描述文件等),这些附属文件的内容也都与源代码相关。换句话说,使用APT可以代替传统的对代码信息和附属文件的维护工作。
通过注解可以在Java源文件中放置一些注解,然后使用APT工具就可以根据该注解生成令一份XML文件,这就是注解的作用。
第十五章 输入/输出
Java的IO通过java.io包下的类和接口来支持,在包下主要包括输入、输出两种IO,每种输入、输出流又可以分为字节流和字符流两大类,其中字节流以字节为单位来处理输入、输出操作,而字符流则以字符来处理输入、输出操作。
Java的IO流使用了一种装饰器设计模式,它将IO流分成底层节点流和上层处理流,其中节点流用于和底层的物理存储节点直接关联——不同的物理节点获取节点流的方式可能存在一定的差异,但程序可以把不同的物理节点流包装成统一的处理流,从而允许程序使用统一的输入、输出代码来读取不同的物理存储节点的资源。
File类
File类是java.io包下代表与平台无关的文件和目录,也就是说,如果希望在程序中操作文件和目录,都可以通过File类来完成。值得指出的是,不管是文件还是目录都是使用File来操作的,File能新建、删除、重命名文件和目录,File不能访问文件内容本身。
访问文件和目录
File类可以使用文件路径字符串来创建File实例,该文件路径字符串既可以是句对路径,也可以是相对路径。在默认情况下,系统总是依据用户的工作路径来解释相对路径。这个路径由系统属性"user.dir"指定,通常也就是运行Java虚拟机时所在的路径。
一旦创建了File对象后,就可以调用File对象的方法来访问,File类提供了很多方法来操作文件和目录。
-
访问文件名相关方法
- String getName():返回此File对象所表示的文件名或路径名
- String getPath():返回此File对象所对应的路径名
- File getAbsoluteFile():返回此File对象的绝对路径
- String getAbsolutePath():返回此File对象所对应的绝对路径名
- String getParent():返回此File对象所对应目录(最后一级子目录)的父目录名
- boolean renameTo(File newName):重命名此File对象所对应的文件或目录,返回值是成功与否
-
文件检测相关方法
- boolean exists():判断File对象所对应的文件或目录是否存在
- boolean canWrite():判断File对象所对应的文件和目录是否可写
- boolean canRead():判断File对象所对应的文件和目录是否可读
- boolean isFile():判断File对象所对应的是否是文件,而不是目录
- boolean isDirectory():判断File对象所对应的是否是目录,而不是文件
- boolean isAbsolute():判断File对象所对应的文件或目录是否是绝对路径。该方法消除了不同平台的差异,可以直接判断 File对象是否为绝对路径。在UNIX/Linux/BSD等系统上,如果 路径名开头是一条斜线(/),则表明该File对象对应一个绝对 路径;在Windows等系统上,如果路径开头是盘符,则说明它是 一个绝对路径。
-
获取常规文件信息
- long lastModified():返回文件的最后修改时间
- long length():返回文件内容的长度
-
文件操作相关方法
- boolean createNewFile():当此File对象所对应的文件不存在时,该方法将新建一个该File对象所指定的新文件,如果创建成功则返回true,否则返回false
- boolean delete():删除File对象所对应的文件或路径
- static File createTempFile(String prefix, String suffix):在默认的临时文件目录中创建一个临时的空文件,时用给定前缀、系统生成的随机数和给定后缀作为文件名。这是一个静态方法,可以直接通过File类来调用。prefix参数必须至少是3字节长。建议前缀使用一个短的、有意义的字符串,suffix参数可以为null,在这种情况下,将使用默认的后缀".tmp"
- static File createTempFile(String prefix, String suffix, File directory):在directory所指定的目录中创建一个临时的空文件。
- void deleteOnExit():注册一个删除钩子,指定当Java虚拟机退出时,删除File对象所对应的文件和目录
-
目录操作相关方法
- boolean mkdir():试图创建一个File对象所对应的目录,如果创建成功,则返回true;否则返回false。调用该方法时File对象必须对应一个路径,而不是一个文件。
- String[] list():列出File对象的所有子文件名和路径名,返回String数组。
- File[] listFiles():列出File对象的所有子文件和路径,返回File数组。
- static File[] listRoots():列出系统所有的根路径。这是一个静态方法,可以直接通过File类来调用。
import java.io.File;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
File file = new File(".");
System.out.println(file.getName());
System.out.println(file.getParent());
System.out.println(file.getAbsoluteFile());
System.out.println(file.getAbsoluteFile().getParent());
File tempFile = File.createTempFile("aaa",".txt",file);
tempFile.deleteOnExit();
File newFile = new File(System.currentTimeMillis() + "");
System.out.println("newFile对象是否存在:" + newFile.exists());
System.out.println(newFile.createNewFile());
System.out.println(newFile.mkdir());
String[] fileList = file.list();
System.out.println("====当前路径下所有文件和路径如下====");
for (String fileName: fileList) {
System.out.println(fileName);
}
File[] roots = File.listRoots();
System.out.println("====系统所有的根路径如下====");
for (File root: roots) {
System.out.println(root);
}
}
}
文件过滤器
在File类的list()方法中可以接收一个FilenameFilter参数,通过该参数可以只列出符合条件的文件。
FilenameFilter接口里包含了一个accept(File dir,String name)方法,该方法将依次对指定File的所有子目录或者文件进行迭代,如果该方法返回true,则list()方法会列出该子目录或者文件。
package FFT;
import java.io.File;
public class FilenameFilterTest {
public static void main(String[] args) {
File file = new File(".");
String[] nameList = file.list((dir, name) -> name.endsWith(",java") || new File(name).isDirectory());
for (String name : nameList) {
System.out.println(name);
}
}
}
上面程序中的file.list中代码实现了accept()方法,实现accept方法就是指定自己的规则,指定哪些文件应该由list方法列出。
上面的程序将会列出当前路径下所有的*.java文件以及文件夹。
理解Java的IO流
Java的IO流是实现输入输出的基础,在Java中把不同的输入输出源(键盘、文件网络连接等)抽象表述为流(stream),通过流的方式允许Java程序使用相同的方式来访问不同的输入输出源,stream时从起源(source)到接收(sink)的有序数据。
Java把所有的传统流类型(类或抽象类)都放在java.io包中,用以实现输入输出功能。
流的分类
-
输入流和输出流
按照流的流向来分,可以分为输入流和输出流
- 输入流:只能从中读取数据,而不能向其写入数据
- 输出流:只能向其写入数据,而不能从中读取数据
这里的输入输出都是从程序运行所在内存的角度来划分的。
Java的输入流主要由InputStream和Reader作为基类,而输出流则主要由OutputStream和Writer作为基类。都是抽象基类,无法创建实例。
-
字节流和字符流
字节流和字符流的用法几乎完全一样,区别在于字节流和字符流所操作的数据单元不同
- 字节流:操作的数据单位是8位的字节
- 字符流:操作的单位是16位的字符
字节流主要由InputStream和OutputStream作为基类,而字符流主要由Reader和Writer作为基类
-
节点流和处理流
- 节点流:可以从/向一个特定的IO设备(磁盘、网络等)读写的流,也被称为低级流,当使用节点流进行输入输出时,程序直接连接到实际的数据源,和实际的输入输出节点连接
- 处理流:用于对一个已存在的流进行连接或封装,通过封装后的流来实现数据读写功能。也被称为高级流。当使用处理流进行输入输出时,程序并不会直接连接到实际的数据源,没有和输入输出节点连接。使用处理流的好处是只要使用相同的处理流,程序就可以采用完全相同的个输入输出代码来访问不同的数据源,随着处理流所包装的节点流的变化,程序实际所访问的数据源也相应地发生变化。
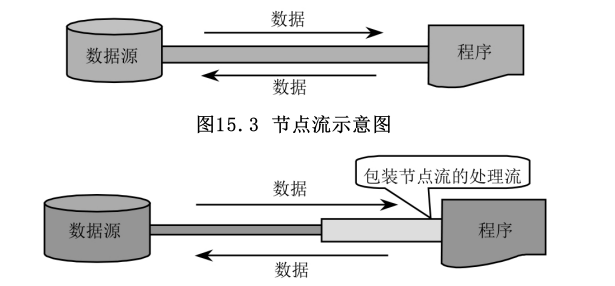
流的概念模型
Java把所有设备里的有序数据抽象成流模型,简化了输入/输出处理,理解了流的概念模型也就了解了Java IO。
Java的IO流共涉及40多个类,这些类看上去芜杂而凌乱,但实际 上非常规则,而且彼此之间存在非常紧密的联系。Java的IO流的40多 个类都是从如下4个抽象基类派生的。
➢ InputStream/Reader:所有输入流的基类,前者是字节输入 流,后者是字符输入流。
➢ OutputStream/Writer:所有输出流的基类,前者是字节输出 流,后者是字符输出流。
对于InputStream和Reader而言,它们把输入设备抽象成一个“水 管”,这个水管里的每个“水滴”依次排列,如图15.5所示。
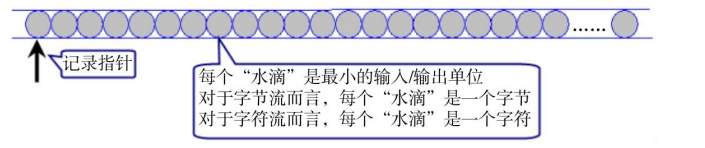
图15.5 输入流模型图
从图15.5中可以看出,字节流和字符流的处理方式其实非常相似,只是它们处理的输入/输出单位不同而已。
输入流使用隐式的记录指针来表示当前正准备从哪个“水滴”开始读取,每当程序从 InputStream或Reader里取出一个或多个“水滴”后,记录指针自动向后移动;除此之外,InputStream和Reader里都提供一些方法来控制记录指针的移动。
对于OutputStream和Writer而言,它们同样把输出设备抽象成一 个“水管”,只是这个水管里没有任何水滴,如图15.6所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MC928Xv1-1685084507253)(D:\Document\md\java\图片\image-20230521132052302.png)]
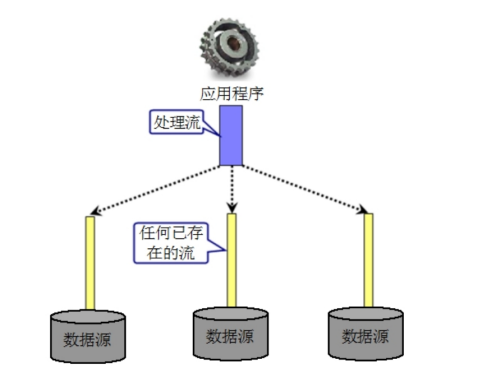
当执行输出时,程序相当于依次把“水滴”放入到输出流的水管中,输出流同样采用隐式的记录指针来标识当前水滴即将放入的位置,每当程序向OutputStream或Writer里输出一个或多个水滴后,记录指针自动向后移动。
除此之外, Java的处理流模型则体现了Java输入/输出流设计的灵活性。处理流的功能主要体现在以下两个方面。
➢ 性能的提高:主要以增加缓冲的方式来提高输入/输出的效率。
➢ 操作的便捷:处理流可能提供了一系列便捷的方法来一次输入/输出大批量的内容,而不是输入/输出一个或多个“水 滴”。 处理流可以“嫁接”在任何已存在的流的基础之上,这就允许 Java应用程序采用相同的代码、透明的方式来访问不同的输入/输出设备的数据流。
通过使用处理流,Java程序无须理会输入/输出节点是磁盘、网络还是其他的输入/输出设备,程序只要将这些节点流包装成处理流,就 可以使用相同的输入/输出代码来读写不同的输入/输出设备的数据
字节流和字符流
InputStream和Reader
它们是所有输出流的抽象基类,会成为所有输入流的模板,它们的方法是所有输入流都可使用的方法
由于两种抽象基类的方法几乎完全相同只是单位不同,下面就以Reader作为例子
- int read():从输入流中读取单个字符,返回所读取的字符数据
- int read(char[] cbuf):从输入流中最多读取cbuf.length个字符的数据,并将其存储在字符数组cbuf中,返回实际读取的字符数。
- int read(char[] cbuf, int off ,int len):从输入流中最多读取len个字符的数据,并将其存储在字符数组cbuf中,放入数组cbuf中时没并不是从数组起点开始,而是从off位置开始,返回实际读取的字符数。
package IN;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class FileInputStreamTest {
public static void main(String[] args) {
try(FileInputStream fr = new FileInputStream("123.txt")) {
byte[] cbuf = new byte[1024];
int hasRead = 0;
while((hasRead = fr.read(cbuf)) > 0){
System.out.println(new String(cbuf,0,hasRead));
}
}catch (IOException ex) {
ex.printStackTrace();
}
/*
显式关闭
fr.close();
*/
}
}
上面的程序是一个简单的读取的例子,与JDBC编程一样,程序里打开的文件IO不属于内存里的资源,垃圾回收机制无法回收该资源,所以应该显式关闭文件IO资源(使用.close)。或者使用可以自动关闭资源的try语句来关闭,就像上面程序就一样。
还支持如下几个方法来移动记录指针:
- void mark(int readAheadLimit):在记录指针当前位置记录一个标记(mark)。
- boolean markSupported():判断此输入流是否支持mark()操作,即是否支持记录标记
- void reset():将此流的记录指针重新定位到上一次记录标记(mark)的位置。
- long skip(long n):记录指针向前移动n个字节/字符
OutputStream和Writer
- void write(int c):将指定的字节/字符输出到输出流中。
- void write(byte[] / char[] buf):将字节数组/字符数组的数据输出到指定输出流中
- void write(byte[] / char[] buf, int off, int len):将数组中从off位置开始,长度为len的数据输出到输出流中。
因为字符流直接以字符作为操作单位,所以Writer可以用字符串来代替字符数组,即以String对象作为参数
package put;
import java.io.*;
public class FOST {
public static void main(String[] args) {
try (
FileInputStream fis = new FileInputStream("D:\\java\\IO\\src\\put\\FOST.java");
FileOutputStream fos = new FileOutputStream("newFile.txt");
) {
byte[] bbuf = new byte[32];
int hasRead = 0;
while ((hasRead = fis.read(bbuf)) > 0) {
fos.write(bbuf,0,hasRead);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
运行上面的程序会产生一个newFile.txt文件,该文件的内容与上面的代码的内容完全相同。
使用Java的IO流执行输出时,不要忘记关闭输出流,关闭输出客流除了可以保证流的物理资源被回收之外,可能还可以将输出流缓冲区中的数据flush到物理节点里(因为在执行close方法之前,自动执行输出流的flush方法)。Java的输出流大部分都默认提供了缓冲功能,其实没有必要去记有哪些流有缓冲功能,只要正常关闭所有的输出流即可以保证程序正常。
如果希望直接输出字符串内容,使用Writer会有更好的结果
package put;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
public class Wt {
public static void main(String[] args) {
try (FileWriter fos = new FileWriter("poem.txt")) {
String s1 = "为伊消得人憔悴";
fos.write(s1);
} catch (IOException ex) {
throw new RuntimeException(ex);
}
}
}
输入/输出流体系
处理流的用法
处理流可以隐藏底层设备上节点流的差异,并对外提供更加方便地输入/输出方法。
- 对开发人员来说使用处理流进行输入输出更简单
- 使用处理流的执行效率更高
使用处理流的典型思路是:使用处理流来包装节点流,程序通过处理流来执行输入/输出功能,让节点流与底层的IO设备、文件交互。
只要流的构造器参数不是一个物理节点,而是已经存在的流,那么这种流就一定是处理流,所有的节点流都是直接以物理节点作为构造器参数的。
package PST;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.PrintStream;
public class PrintfStreamTest {
public static void main(String[] args) {
try (
FileOutputStream fos = new FileOutputStream("test.txt");
PrintStream ps = new PrintStream(fos);
) {
ps.println("dadsadsdsa");
ps.println(new PrintfStreamTest());
}catch (IOException ex){
ex.printStackTrace();
}
}
}
上 面 程 序 中 的 两 行 粗 体 字 代 码 先 定 义 了 一 个 节 点 输 出 流 FileOutputStream,然后程序使用PrintStream包装了该节点输出流,最后使用PrintStream输出字符串、输出对象……PrintStream的输出功能非常强大,前面程序中一直使用的标准输出System.out的类型就是PrintStream。
由于PrintStream类的输出功能非常强大,通常如果需要输出文本内容,都应该将输出流包装成PrintStream后进行输出。
在使用处理流包装了底层节点流之后,关闭输入/输出流资源时,只要关闭最上层的处理流即可。关闭最上层的处理流时,系统会自动关闭被该处理流包装的节点流。
输入/输出流体系
Java的输入/输出流体系提供了近40个类,这些类看上去杂乱而没 有规律,但如果将其按功能进行分类,则不难发现其是非常规律的。显示了Java输入/输出流体系中常用的流分类。
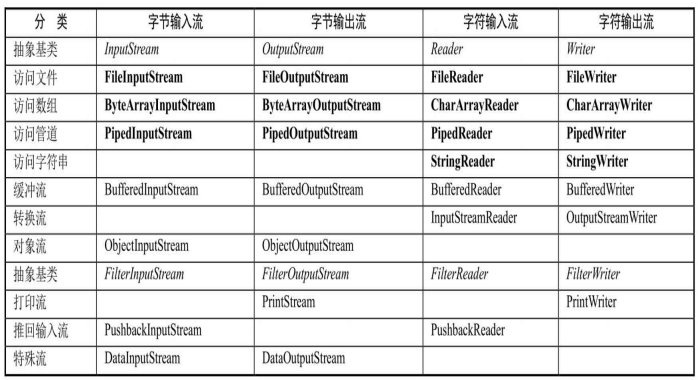
通常来说,字节流的功能比字符流的功能要强大,因为计算机里所有的数据都是二进制的,字节流可以处理所有的二进制文件,但如果使用字节流来处理文本文件,就需要使用合适的方式来把字节转换成字符,所以通常来说:
如果进行输入输出的内容是文本内容,就应该使用字符流,如果是二进制内容,就用字节流。
一种以数组为物理节点的节点流,字节流以字节数组为节点,字符流以字符数组为节点;这种以数组为物理节点的节点流除在创建节点流对象时需要传入一个字节数组或者字符数组之外,用法上与文件节点流完全相似。与此类似的是,字符流还可以使用字符串作为物理节点,用于实现从字符串读取内容,或将内容写入字符串(用StringBuffer充当字符串)的功能。
在创建StringReader和StringWriter对象时传入的是字符串节点,而不是文件节点。由于String是不可变的字符串对象,所以 StringWriter使用StringBuffer作为输出节点。
StringReader类实现了一个可用于读取String的字符流。它提供了读取单个字符、读取字符数组、跳过字符、查看下一个字符等方法。例如,以下代码片段演示了如何使用StringReader从字符串中读取字符:
String str = "Hello World";
StringReader reader = new StringReader(str);
int c;
while ((c = reader.read()) != -1) {
System.out.print((char) c);
}
StringWriter类提供了一个可用于将字符写入字符串的字符流。它提供了写入单个字符、写入字符数组、刷新缓冲区等方法。例如,以下代码片段演示了如何使用StringWriter将字符写入字符串:
StringWriter writer = new StringWriter();
writer.write("Hello");
writer.write(" ");
writer.write("World");
String result = writer.toString();
System.out.println(result); // 输出 "Hello World"
StringReader和StringWriter类在处理字符串时非常方便,特别是在需要快速读取和写入字符串时。它们可以用于处理文本文件、网络数据、XML数据等操作中。此外,它们还可以与其他字符流类一起使用,例如BufferedReader和BufferedWriter,来提高读写效率。
转换流
输入/输出流体系中还提供了两个转换流,这两个转换流用于实现将字节流转换成字符流,其中InputStreamReader将字节输入流转换成字符输入流,OutputStreamWriter将字节输出流转换成字符输出流。
下 面 以 获 取 键 盘 输 入 为 例 来 介 绍 转 换 流 的 用 法 。 Java 使 用 System.in 代 表 标 准 输 入 , 即 键 盘 输 入 , 但 这 个 标 准 输 入 流 是 InputStream类的实例,使用不太方便,而且键盘输入内容都是文本内容,所以可以使用InputStreamReader将其转换成字符输入流,普通的 Reader读取输入内容时依然不太方便,可以将普通的Reader再次包装成BufferedReader,利用BufferedReader的readLine()方法可以一次读取一行内容。如下程序所示。
package KT;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class KeyinTest {
public static void main(String[] args) {
try (
InputStreamReader reader = new InputStreamReader(System.in);
BufferedReader br = new BufferedReader(reader);
) {
String line = null;
while ((line = br.readLine()) != null) {
if (line.equals("exit")){
System.exit(1);
}
System.out.println("输入内容为:" + line);
}
}catch (IOException ioException) {
ioException.printStackTrace();
}
}
}
上 面 程 序 中 的 粗 体 字 代 码 负 责 将 System.in 包 装 成 BufferedReader,BufferedReader流具有缓冲功能,它可以一次读取 一行文本——以换行符为标志,如果它没有读到换行符,则程序阻塞,等到读到换行符为止。运行上面程序可以发现这个特征,在控制台执行输入时,只有按下回车键,程序才会打印出刚刚输入的内容。
推回输入流
PushbackInputStream和PushbackReader,他们都提供了(以Reader为例):
- void unread(char[] buf):将一个字符数组的内容推回到缓冲区内,从而允许重复读取刚刚读取的内容。
- void unread(char[] b, int off, int len):将一个字符数组里从off开始,长度为len字符的内容推回到缓冲区内
- void unread(int b):将一个字符推回
这两个推回输入流都带有一个推回缓冲区,当程序调用unread方法时,系统会将指定数组的内容推回到该缓冲区内,而推回输入流每次调用read方法时总是先从推回缓冲区读取,只有完全读取了推回缓冲区的内容后,才会从原输入流中读取。
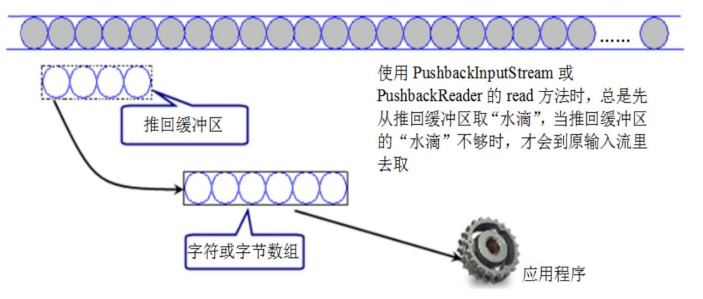
当程序创建一个推回流的时候需要制定推回缓冲区的大小,默认为1,如果程序推回的内容超出,将会引发Pushback buffer overflow的IOException异常。
package PbT;
import java.io.FileReader;
import java.io.IOException;
import java.io.PushbackReader;
public class PushbackTest {
public static void main(String[] args) {
try(
PushbackReader pr = new PushbackReader(new FileReader("src/PbT/PushbackTest.java"),64);
){
char[] buf = new char[32];
String lastContent = "";
int hasRead = 0;
while ((hasRead = pr.read(buf)) > 0) {
String content = new String(buf,0,hasRead);
int targetIndex = 0;
if ((targetIndex = (lastContent + content).indexOf("new PushbackReader")) > 0) {
pr.unread((lastContent + content).toCharArray());
if (targetIndex > 32) {
buf = new char[targetIndex];
}
pr.read(buf,0,targetIndex);
System.out.println(new String(buf,0,targetIndex));
System.exit(0);
}else {
System.out.println(lastContent);
lastContent = content;
}
}
}catch (IOException ioException) {
ioException.printStackTrace();
}
}
}
上面程序中的粗体字代码实现了将指定内容推回到推回缓冲区,于是当程序再次调用read()方法时,实际上只是读取了推回缓冲区的部分内容,从而实现了只打印目标字符串前面内容的功能
重定向标准输入输出
Java的标准输入输出分别通过System.in和System.out来代表,在默认的情况下它们分别代表键盘和显示器。
在System类里提供了如下三个重定向标准输入输出的方法:
- static void setErr(PrintStrem err):重定向”标准“错误输出流
- static void setIn(InputStream in):重定向标准输入流
- static void setOut(PrintStream out):重定向标准输出流
下面是一个简单的例子,演示如何将标准输入和输出重定向到文件:
import java.io.*;
public class RedirectExample {
public static void main(String[] args) throws IOException {
// 保存标准输入和输出
InputStream stdIn = System.in;
PrintStream stdOut = System.out;
try {
// 重定向标准输入和输出
InputStream inputStream = new FileInputStream("input.txt");
System.setIn(inputStream);
PrintStream outputStream = new PrintStream(new FileOutputStream("output.txt"));
System.setOut(outputStream);
// 读取输入并输出
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line.toUpperCase());
}
} finally {
// 恢复标准输入和输出
System.setIn(stdIn);
System.setOut(stdOut);
}
}
}
在上面的例子中,我们首先保存了标准输入和输出的引用,然后使用setIn和setOut方法将它们重定向到文件"input.txt"和"output.txt"中。程序读取"input.txt"中的内容并将其全部大写后输出到"output.txt"中。最后,我们使用setIn和setOut方法将标准输入和输出设置回原来的值,以防止对其他部分的程序造成影响。
假设"input.txt"中的内容为:
hello
world
则程序将输出以下内容到"output.txt"中:
HELLO
WORLD
需要注意的是,一旦重定向了标准输入和输出,就必须在程序运行结束后将其设置回来,否则可能会影响其他部分的程序执行。可以使用System类的restoreIn和restoreOut方法来恢复标准输入和输出:
System.setIn(System.in);
System.setOut(System.out);
这些方法通常用于测试目的,例如将标准输入输出重定向到文件以便于测试程序的输入输出是否符合预期。此外,它们还可以用于实现一些高级功能,例如从网络连接或管道中读取数据,或将输出写入日志文件等
Java虚拟机读写其他进程的数据
使用Runtime对象的exec方法可以运行平台上的其他程序,该方法产生一个Process对象,Process对象代表由该Java程序启动的子进程。Process类提供了如下三个方法,用于让程序和其子进程进行通信
- InputStream getEroorStream():获取子进程的错误流
- InputStream getInputSrteam():获取子进程的输入流
- OutputStream getOutputStream():获取子进程的输出流
RandomAccessFile
RandomAccessFile是Java输入输出流体系中功能最丰富的文件内容访问类,它提供了众多的方法来访问文件内容,它既可以读取文件内容,也可以向文件输出数据。与普通的输入输出流不同的是,RandomAccessFile支持随机访问的方式,程序可以直接跳转到文件的任意地方来读写数据。
如果只需要访问文件的部分内容,或者是向已存在的文件后追加内容,使用RandomAccessFile。
RandomAccessFile有一个最大的缺陷就是只能操作文件,不能操作其他IO节点。
RandomAccessFile对象包含了一个记录指针,用以表示当前读写处的位置,当程序新创建一个RandomAccessFile对象时,该对象的文件记录指针位于文件头(也就是0处),当读写了n个字节后,文件记录指针将会向后移动n个字节。除此之外,RandomAccessFile可以自由移动该记录指针,既可以向前移动,也可以向后移动。RandomAccessFile包含了如下两个方法来操作文件记录指针
- long getFilePointer():返回文件记录指针的当前位置
- void seek(long pos):将文件记录指针定位到pos位置
RandomAccessFile包含了类似于InputStream的三个read方法和InputStream的三个write方法,除此之外,还包含了一系列的readXxx()和writeXxx()方法来完成输入输出。
RandomAccessFile类有两个构造器,一个使用String参数来指定文件名,一个使用File参数来指定文件本身,除此之外,创建RandomAccessFile对象时还需要一个mode参数,该参数指定RandomAccessFile文件的访问模式,该参数有如下四个值
- “r”:以只读的方式打开指定文件,如果试图写入将抛出异常
- “rw”:以读写方式打开指定文件,如果文件不存在,则尝试创建该文件
- “rws”:以读写方式打开指定文件。相对与rw,还要求对文件的内容或元数据的每个更新都同步写入到底层存储设备
- “rwd”:以读写方式打开指定文件。相对于rw,还要求对文件内容的每个更新都同步写入到底层存储设备
下面程序使用了RandomAccessFile来访问指定的中间部分数据。
package RAFT;
import java.io.IOException;
import java.io.RandomAccessFile;
public class RandomAccessFileTest {
public static void main(String[] args) {
try(RandomAccessFile raf = new RandomAccessFile("src/RAFT/RandomAccessFileTest.java","r")){
System.out.println("文件指针初始位置:" + raf.getFilePointer());
raf.seek(500);
byte[] bbuf = new byte[1024];
int hasRead = 0;
while ((hasRead = raf.read(bbuf)) > 0) {
System.out.println(new String(bbuf, 0, hasRead));
}
}catch (IOException ioException) {
ioException.printStackTrace();
}
}
}
下面程序示范了如何向指定文件后追加内容,为了追加内容,程序应该先将记录指针移动到文件最后,然后开始向文件中输出内容。
package RAFT;
import java.io.IOException;
import java.io.RandomAccessFile;
public class AppendContent {
public static void main(String[] args) {
try (RandomAccessFile raf = new RandomAccessFile("aaa.txt", "rw")) {
raf.seek(raf.length());
raf.write("新追\r\n".getBytes());
} catch (IOException ioException) {
ioException.printStackTrace();
}
}
}
RandomAccessFile依然不能向文件的指定位置插入内容,如果直接将文件记录指针移动到中间某位置后开始输出,则新输出的内容会覆盖文件中原有的内容。如果需要向指定位置插入内容,程序需要先把插入点后面的内容读入缓冲区,等把需要插入的数据写入文件后,再将缓冲区的内容追加到文件后面。
package RAFT;
import java.io.*;
public class InsertContent {
public static void insert(String fileName,long pos,String insertContent) throws IOException {
File tmp = File.createTempFile("tmp",null);
tmp.deleteOnExit();
try (
RandomAccessFile raf = new RandomAccessFile(fileName, "rw");
FileOutputStream write = new FileOutputStream(tmp);
FileInputStream read = new FileInputStream(tmp);
) {
raf.seek(pos);
byte[] buf = new byte[1024];
int hasRead = 0;
while ((hasRead = raf.read(buf)) > 0) {
write.write(buf, 0, hasRead);
}
raf.seek(pos);
raf.write(insertContent.getBytes());
hasRead = 0;
while ((hasRead = read.read(buf)) > 0) {
raf.write(buf,0,hasRead);
}
}
}
public static void main(String[] args) throws IOException {
String fileName = "D:\\zhanGuo\\temp\\ztg.txt";
String insertContant = "tian";
long pos = 5;
insert(fileName,pos,insertContant);
}
}
上面程序中使用File的createTempFile(String prefix, String suffix)方法创建了一个临时文件(该临时文件将在JVM退出时被删除),用以保存被插入文件的插入点后面的内容。程序先将文件中插入点后的内容读入临时文件中,然后重新定位到插入点,将需要插入的内容添加到文件后面,最后将临时文件的内容添加到文件后面,通过这个过程就可以向指定文件、指定位置插入内容。
Java9改进的对象序列化
对象序列化的目标是将对象保存到磁盘中,或允许在网络中直接传输对象。对象序列化机制允许把内存中的Java对象装换成平台无关的二进制流,从而允许把这种二进制流持久地保存在磁盘上,通过网络将这种二进制流传输到另一个网络节点。其他程序一旦获得了这种二进制流,都可以将这种二进制流恢复成原来的Java对象
序列化的含义和意义
序列化机制使得对象可以脱离程序的运行而独立存在。
对象的序列化指将一个Java对象写入IO流中,对象的反序列化是指从IO流中恢复该Java对象。
Java9增强了对象序列化机制,它允许对读入的序列化数据进行过滤,这种过滤可以在反序列化之前对数据执行校验,从而提高安全性和健壮性。
如果需要让某个对象支持序列化机制,则必须让它的类是可序列化的。这要求该类必须实现如下两个接口之一:
- Serializable
- Externalizable
Java的很多类已经实现了Serializable,该接口是一个标记接口,实现该接口无需实现任何方法,它只是表明该类的实例是可序列化的。
使用对象流实现序列化
如果需要将某个对象保存到磁盘上或者通过网络传输,那么这个类应该事先Serializable接口或者Externalizable接口之一。
使用Serializable实现序列化只需要让目标类实现Serializable接口就好,无需实现任何方法。
程序可以通过如下两个步骤序列化一个已经实现了Serializable接口的可序列化类:
- 创建一个ObjectOutputStream处理流
- 调用处理流的writeObject方法输出可序列化对象
这是一个准备好的可序列化的Person对象:
package xuliehua.Sz;
public class Person implements java.io.Serializable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Person(String name, int age) {
System.out.println("有参数的构造器");
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
这是将其序列化:
package xuliehua.Sz;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.nio.file.Files;
import java.nio.file.Paths;
public class WriteObject {
public static <e> void main(String[] args) throws FileNotFoundException {
try (ObjectOutputStream oos = new ObjectOutputStream(Files.newOutputStream(Paths.get("object.txt")))) {
Person per = new Person("孙悟空", 500);
oos.writeObject(per);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
如果想要回复Java对象,就需要使用反序列化,反序列化步骤如下:
- 创建一个ObjectInputStream输入处理流
- 调用readObject方法并强制转换
package xuliehua.Sz;
import java.io.FileInputStream;
import java.io.FilterInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.nio.file.Files;
import java.nio.file.Paths;
public class ReadObject {
public static void main(String[] args) {
try(ObjectInputStream ois = new ObjectInputStream(Files.newInputStream(Paths.get("object.txt")))){
Person p = (Person) ois.readObject();
System.out.println(p.toString());
}catch (IOException ioException) {
ioException.printStackTrace();
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
}
反序列化读取的仅仅是Java对象的数据,而不是Java类,因此采用反序列化恢复Java对象时,必须提供该对象所属类的class文件,否则会引发ClassNotFoundException异常
Person类只有一个有参数的构造器,没有无参数的构造器,而且该构造器内有一个普通的打印语句。当反序列化读取Java对象时,并没有看到程序调用该构造器,这表明反序列化机制无须通过构造器来初始化Java对象。
如果使用序列化机制像文件中写入了多个Java对象,使用反序列化机制回复对象时必须按实际写入的顺序读取。
当一个可序列化类由多个父类时(包括直接父类和间接父类),这些父类要么有无参数的构造器,要么是可序列化的——否则将会抛出InvalidClassException异常。如果父类是不可序列化的,只是带有无参数的构造器,则该父类中定义的成员变量值不会被序列化到二进制流中。
对象引用的序列化
如果某个类的成员变量的类型不是基本类型或String类型,而是另一个引用类型,那么这个引用类必须是可序列化的,否则拥有该成员变量的类也是不可序列化的。
Java序列化机制的特殊序列化算法:
- 所有保存到磁盘中的对象都有一个序列化编号
- 当程序试图序列化一个对象时,程序将会先检查该对象是否已经被序列化过,只有该对象从未(本次虚拟机中)被序列化过,系统才会将该对象转换为字节序列并输出。
- 如果某个对象已经序列化过,程序将只是直接输出一个序列化编号,而不是重新序列化该对象。
但这会造成一个后果,就是当使用序列化时,只有第一次调用writeObject方法输出对象时才会将对象转换成字节序列,并写入到ObjectOutputStream;在后面程序中即使该对象的实例变量发生了改变,再次调用writeObject方法输出该对象时。改变后的实例变量也不会被输出。
当某个对象进行序列化时,系统会自动把该对象的所有实例变量依次进行序列化,如果某个实例变量引用到另一个对象,则被引用的对象也会被序列化;如果被引用的对象的实例变量也引用了其他对象,则被引用的对象也会被序列化,这种情况被称为递归序列化。
Java9增加的过滤功能
Java 9为ObjectInputStream增加了setObjectInputFilter()和getObjectInputFilter()两个方法,它们用于为对象输入流设置过滤器和获取当前设置的过滤器。
setObjectInputFilter()方法的签名如下:
public final void setObjectInputFilter(ObjectInputFilter filter)
该方法用于为ObjectInputStream设置过滤器,以便在反序列化对象时进行额外的验证和处理操作。ObjectInputFilter是一个函数接口,它定义了一个accept方法,用于接受或拒绝序列化的对象。
当程序通过ObjectInputStream反序列化对象时,过滤 器的checkInput()方法会被自动激发,用于检查序列化数据是否有 效。
使用checkInput()方法检查序列化数据时有3种返回值。
➢ Status.REJECTED:拒绝恢复。
➢ Status.ALLOWED:允许恢复。
➢ Status.UNDECIDED:未决定状态,程序继续执行检查。
ObjectInputStream将会根据ObjectInputFilter的检查结果来决定是否执行反序列化,如果checkInput()方法返回Status.REJECTED, 反序列化将会被阻止;如果checkInput()方法返回Status.ALLOWED, 程序将可执行反序列化。
例如,下面是一个简单的ObjectInputFilter实现,它只接受版本号为1的对象:
ObjectInputFilter filter = obj -> {
if (obj instanceof Person) {
int version = ((Person) obj).getVersion();
if (version != 1) {
return ObjectInputFilter.Status.REJECTED;
}
}
return ObjectInputFilter.Status.UNDECIDED;
};
在上面的代码中,我们定义了一个ObjectInputFilter,它首先判断序列化的对象是否是Person类型,如果是,则获取其版本号并判断是否为1。如果版本号不为1,则返回ObjectInputFilter.Status.REJECTED,表示拒绝接受该对象;否则返回ObjectInputFilter.Status.UNDECIDED,表示接受该对象。
然后,我们可以使用setObjectInputFilter方法将过滤器设置到ObjectInputStream中,例如:
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream("person.ser"));
inputStream.setObjectInputFilter(filter);
在上面的代码中,我们首先创建了一个ObjectInputStream,然后使用setObjectInputFilter方法将过滤器filter设置到ObjectInputStream中。
getObjectInputFilter()方法的签名如下:
public final ObjectInputFilter getObjectInputFilter()
该方法用于获取当前设置的ObjectInputFilter。例如:
ObjectInputFilter currentFilter = inputStream.getObjectInputFilter();
在上面的代码中,我们使用getObjectInputFilter方法获取了当前设置的过滤器currentFilter。
需要注意的是,ObjectInputFilter仅在Java 9及更高版本中可用,而且只适用于ObjectInputStream。如果使用其他序列化格式或库,可能需要使用其他方式进行过滤和验证。
自定义序列化
如果因为某些实例变量是敏感信息或者其类型是不可序列化的引用类型,需要避开该对象序列化,
可以使用transient关键字修饰,可以指定Java序列化时无需例会该实例变量。(transient只能修饰实例变量,不能修饰Java程序中的其他成分)
使用transient关键字修饰的实例变量将被完全隔离在序列化机制之外,这样导致在反序列化时Java对象无法取得该实例变量值。
Java的自定义序列化机制,可以让程序控制如何序列化各实例变量,甚至完全不序列化某些实例变量。
在序列化和反序列化过程中需要特殊处理的类应该提供如下签名的方法,这些方法用于实现自定义反序列化。
- private void writeObject(java.io.ObjectOutputStream out) throws IOException
- private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException;
- private void readObjectNotData() throws ObjectStreamException;
writeObject方法负责写入特定类的实例状态,通过重写该方法,可以控制需要序列化的变量以及如何序列化变量,在默认情况下该方法会调用 out.defaultWriteObject来保存Java对象的各实例变量。
readObject方法负责从流中读取并恢复对象的实例变量,通过重写该方法,可以决定如何反序列化。在默认情况下,该方法会调用in.defaultReadObject来恢复Java对象的非瞬态实例变量。一般来说,改写了writeObject方法后应该对应地改变readObject方法,以便正确恢复该对象,
当序列化流不完整时,readObjectNoData()方法可以用来正确地 初始化反序列化的对象。例如,接收方使用的反序列化类的版本不同 于发送方,或者接收方版本扩展的类不是发送方版本扩展的类,或者 序列化流被篡改时,系统都会调用readObjectNoData()方法来初始化 反序列化的对象。
package xuliehua.Sz;
import java.io.*;
public class Person implements java.io.Serializable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Person(String name, int age) {
System.out.println("有参数的构造器");
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
private void writeObject(java.io.ObjectOutputStream out) throws IOException {
out.writeObject(new StringBuffer(name).reverse());
out.writeInt(age);
}
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException {
this.name = (((StringBuffer) in.readObject()).toString());
this.age = in.readInt();
}
}
该类重写了两个方法,这样做的话,序列后的对象流即使有Cracker截获到Person对象流,看到的也是加密后的数据,提高了序列化的安全性。
还有一种更彻底的自定义序列化机制:
它可以在序列化对象时将该对象替换成其他对象。如果需要实现序列化某个对象时替换该对象,则应为序列化类提供如下特殊方法。
-
ANY-ACCESS-MODIFIER Object writeReplace() throws ObjectStreamException;
此方法将由序列化机制调用,只要改方法存在。因为该方法可以拥有private、protected、package-private等访问权限,所以其子类有可能获得该方法。
下面的例子时使用该方法将写入Person对象时将该对象替换成List;
package xuliehua.Sz;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
public class Person implements java.io.Serializable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Person(String name, int age) {
System.out.println("有参数的构造器");
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
private Object writeReplace(){
List<Object> list = new ArrayList<>();
list.add(name);
list.add(age);
return list;
}
}
这是调用:
package xuliehua.Sz;
import java.io.*;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
public class ReplaceTest {
public static void main(String[] args) {
final Path path = Paths.get("object.txt");
try(
ObjectInputStream read = new ObjectInputStream(Files.newInputStream(path));
ObjectOutputStream write = new ObjectOutputStream(Files.newOutputStream(path))
) {
Person person = new Person("猪八戒",500);
write.writeObject(person);
List list = (List) read.readObject();
System.out.println(list);
} catch (IOException | ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
}
这是结果
有参数的构造器
[猪八戒, 500]
Java的序列化机制保证在序列化某个对象之前,先调用该对象的writeReplace方法,如果该方法返回另一个Java对象,则系统转为序列化另一个对象,如果还有writeReplace方法,则继续递归,知道没有另一个对象时,调用最后一个对象的writeObject方法来保存该对象的状态。
序列化机制里还有一个特殊的方法可以实现保护性的复制整个对象
该方法可以实现保护性的复制整个对象。
ANY-ACCESS-MODIFIER Object readResolve() throws ObjectStreamException;
这个方法会紧接着readObject之后被调用,该方法的返回值将会代替原来反序列化的对象,而原来的readObject反序列化的对象将会被立即丢弃。
该方法可以解决一些老版本代码的遗留问题,但其本身的缺点很明显且不好避免,以后如果有可能用到再仔细看。
另一种自定义序列化机制
通过实现Externalizable接口实现自定义序列化,该接口包含两个方法:
-
void readExternal(Object in); /* 该方法是实现反序列化的,调用DataInput(ObjectInput的父接口)的方法来恢复基本类型的实例变量值, 调用ObjectInput的readObject方法来恢复引用类型的实例变量值 */ -
void writeExternal(Object out); /* 保存对象的状态。该方法调用DataOutput(ObjectOutput的父接口)的方法来保存基本类型的实例变量值, 调用ObjectOutput的writeObject()方法来保存引用类型的实例变量值。 */
这种序列化方式与前面的Serializable的自定义序列化方式基本相同,只是该接口会强制自定义序列化。
当使用Externalizable机制反序列化对象时,程序会先调用public的无参数构造器创建实例,然后执行readExternal方法进行反序列化,因此实现Externalizable序列化类必须提供无参数构造器。

对象序列化需要注意的点
- 对象的类名、实例变量(包括基本类型、数组、对其它对象的引用)都会被序列化;方法、类变量、transient实例变量都不会被序列化
- 实现Serializable接口的类如果需要让某个实例变量不被序列化,则可在该实例变量前加transient修饰符,而不是加static关键字,虽然效果相同,但不够准确,不能胡用。
- 保证序列化对象的实例变量类型也是可序列化的,否则需要使用transient关键字修饰,不然该类就不可序列化。
- 反序列化对象时必须要有序列化对象的class文件
- 当通过文件、网络来读取序列化后的对象时,必须按实际写入的顺序读取。
版本
Java的序列化机制允许为序列化类提供一个private static final serialVersionUID值,该类变量的值用于表示该Java类的序列化版本,也就是说,如果一个类升级后,只要它的serialVersionUID类变量值保持不变,序列化机制也会把它们当成同一个序列化版本。
如果不显式指定该类变量的值,该类变量的值酱油JVM根据类的相关信息计算,修改后的类的计算结果与修改前的类的计算结果往往不同,从而造成对象的反序列化因为i版本不兼容而失败。
可以通过JDK安装路径下的serialver.exe工具获得该类的serialVersionUID类变量的值,命令如下:
-
serialver (类名)
不显式指定serialVersionUID的值的另一个缺点是因为不同的JVM之间的对该类变量的计算策略可能不同,从而造成类没有改变但该值会不同然后导致无法正确反序列化。
如果类的修该会导致该类的反序列化失败,则应该为该类的serialVersionUID变量重现分配值。一共有下面几种情况:
- 如果修改类时仅仅修改了方法,则反序列化不受任何影响。
- 如果修改类时仅修改了静态变量或瞬态实例变量,则反序列化不受任何影响。
- 如果修改类时修改了非瞬态的实例变量,则可能导致序列化版本不兼容。如果对象流中的对象和心累中包含同名的实例变量,而实例变量的类型不同,则反序列化失败,类定义中应该修改serialVersionUID值,如果对象流中的对象比新类包含更多的实例变量,则多出的实例变量被忽略,序列化版本可以兼容。如果新类比对象流多出更多的实例变量,版本也可以兼容。
NIO
Java新IO概述
新IO和传统的IO有相同的目的,都是用于进行输入输出,但新IO采用内村映射文件的方式来处理输入输出,将文件或文件的一段区域映射到内存中,这样就可以像访问内存一样访问文件了,通过这种方式会比传统的输入输出快得多。
Java中与新IO有关的包如下
- java.nio:主要包含各种与Buffer有关的类
- java.nio.channels:包含与Channel和Selector有关的类
- java.nio.charset:包含与字符集相关的类
- java.nio.channels.spi:包含Channel相关的服务提供者编程接口
- java.nio.charset.spi:包含与字符集相关的服务提供者编程接口
Channel(通道)和Buffer(缓冲)是新IO中两个核心对象,Channel是对传统输入输出的模拟,在新IO系统中所有的数据都要通过通道传输
Channel与InputStream和OutputStream的最大区别在于它提供了一个map方法,通过该方法可以直接将一块数据映射到内存中。
可以说传统的输入输出系统是面向流的处理,新IO是面向块的处理。
Buffer可以被理解成一个容器,本质是一个数组,发送到Channel的所有对象必须首先放到Buffer中,从C看呢了中读取数去也必须先放到Buffer中。
除Channel和Buffer外,新IO还提供了用于将Unicode字符串映射成字节序列以及逆映射操作的Charset类,也提供了用于支持非阻塞式输入输出的Selector类。
使用Buffer
Buffer的内部结构就像一个数组,可以保存多个类型的数据。Buffer是一个抽象类,最常用的子类是ByteBuffer,它可以在底层字节数组上进行get/set操作。除Byte外,对应于其他基本数据类型(除Boolean)都有对应的Buffer类。
上面的Buffer类都采用相同或相似的方法来管理数据,Byte会有区别。这些Buffer没有构造器,铜鼓哟使用如下方法来得到一个Buffer对象。
static XxxBuffer allocate(intr capacity)://创建一个容量为capacity的XxxBuffer对象。
实际使用较多的是ByteBuffer和CharBuffer,其他Buffer子类较少用到,ByteBuffer类还有一个子类:MappedByteBuffer,它用于表示Channel将磁盘文件的部分或全部内容映射到内存中后得到的结果,通常其对象由Channel的map方法返回。
在Buffer中有三个重要的概念:容量(capacity)、界限(limit)、和位置(position)。
- 容量:缓冲区的容量表示该Buffer的最大数据容量,即最多能存储多少数据。缓冲区的容量不能为负值,创建后不可改变。
- 界限:第一个不应该被读出或者写入的缓冲区位置索引,也就是说,位于limit后的数据既不可被读也不可被写。
- 位置:用于指明下一个可以被读出或者写入的缓冲区位置索引(类似于IO流中的记录指针)。当使用Buffer从Channel中读取数据时,position的值恰好等于读到了多少数据。当刚刚新建一个Buffer对象时,其position为0;从Channel中读取了两个数据到该Buffer中,则position为2,指向Buffer中第三个位置。
除此之外,Buffer里还支持一个可选的标记mark,Buffer允许直接将position定位到该mark处。这些值满足如下关系:
0 <= mark <= position <= limit <= capacity
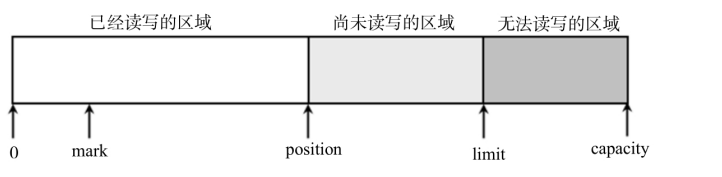
Buffer的主要作用就是装入数据,然后输出数据,开始时Buffer的position为0,limit为capacity,程序可通过put方法像Buffer中放入一些数据(或者从Channel中获取一些数据),每放入一些数据,Buffer的position相应的向后移动一些位置。
当Buffer装入数据结束后,调用Buffer的flip方法,该方法将limit设置为position所在位置,并将position设为0,这就使得Buffer的读写指针又移动到了开始位置。也就是说,Buffer调用flip方法之后,Buffer为输出数据做好准备;当Buffer输出数据结束后,Buffer调用clear方法,clear方法会将position设为0,将limit设为capacity,再次为装入数据做好准备。
除此之外,Buffer中还包含如下一些常用的方法:
- int capacity():返回Buffer的capacity大小。
- boolean hasRemaining():判断当前位置(position)和界限 (limit)之间是否还有元素可供处理。
- int limit():返回Buffer的界限(limit)的位置。
- Buffer limit(int newLt):重新设置界限(limit)的值,并返回一个具有新的limit的缓冲区对象。
- Buffer mark():设置Buffer的mark位置,它只能在0和位置 (position)之间做mark。
- int position():返回Buffer中的position值。
- Buffer position(int newPs):设置Buffer的position,并返 回position被修改后的Buffer对象。
- int remaining():返回当前位置和界限(limit)之间的元素个数。
- Buffer reset():将位置(position)转到mark所在的位置
- Buffer rewind():将位置(position)设置成0,取消设置的 mark。
Buffer的所有子类还提供了两个重要的方法:put和get,用于向Buffer中放入数据和取出数据。当使用它们时,Buffer既支持对单个数据的访问,也支持对批量数据的访问(以数据作为参数)
方式用put和get访问数据时,分为绝对和相对两种。
- 相对:从Buffer当前的position处开始读取或写入数据,然后将位置的值按元素的个数增加
- 绝对:直接根据索引像Buffer中读取或写入数据,使用绝对的方式访问Buffer里的数据时,并不会影响位置的值。
下面的程序示范了一些常规操作:
package _1;
import java.nio.CharBuffer;
public class BufferTest {
public static void main(String[] args) {
CharBuffer buff = CharBuffer.allocate(8);
System.out.println("capacity:" + buff.capacity());
System.out.println("limit:" + buff.limit());
System.out.println("position:" + buff.position());
buff.put('a');
buff.put('b');
buff.put('c');
System.out.println("加入三个元素后position" + buff.position());
buff.flip();
System.out.println("此时limit:"+ buff.limit());
System.out.println("position = " + buff.position());
System.out.println("one = " + buff.get());
System.out.println("position = " + buff.position());
buff.clear();
System.out.println("clear; limit = " + buff.limit());
System.out.println("position = " + buff.position());
System.out.println("执行clear后,缓冲区内容并没有被清除,three = " + buff.get(2));
System.out.println("position = " + buff.position());
}
}
通过allocate创建的Buffer对象是普通的Buffer,ByteBuffer还提供了一个allocateDirect方法来创建直接Buffer,直接Buffer的创建成本比普通的要高,但读取效率更高。
使用Channel
Channel类似于传统的流对象,但有两个主要区别:
- Channel可以直接将指定文件的部分或全部直接映射成Buffer。
- 程序不能直接访问Channel中的数据,包括读取、写入都不行,Channel只能和Buffer进行交互。
Channel接口有很多实现类,接下来主要介绍的是FileChannel的用法,还有其他供线程通信和网络通信的,以后了解。
所有的Channel都不应该通过构造器直接创建,而是通过传统节点的getChannel方法来获得对应的Channel,不同的节点流获得的Channel不一样,
Channel中最常用的三类方法是map、read、write,其中map用来将Channel对应的部分或全部数据映射为ByteBuffer;read和write都用来从Buffer中读取或写入数据。
map的方法签名:
MappedByteBuffer map(FileChannel.MapMode mode, long position, long size)
第一个参数执行映射时的模式,分别有只读、读写等模式;第二个、第三个参数控制将Channel的哪些数据映射成ByteBuffer。
下面是一些简单的应用:
package _2;
import java.io.*;
import java.nio.CharBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.Charset;
import java.nio.charset.CharsetDecoder;
public class FileChannelTest {
public static void main(String[] args) {
File f = new File("src/_2/FileChannelTest.java");
try(
FileInputStream in = new FileInputStream(f);
FileChannel inChannel = in.getChannel();
FileOutputStream out = new FileOutputStream("a.txt");
FileChannel outChannel = out.getChannel()
){
MappedByteBuffer buffer = inChannel.map(FileChannel.MapMode.READ_ONLY,0,f.length());
Charset charset = Charset.forName("GBK");
outChannel.write(buffer);
buffer.clear();
CharsetDecoder decoder = charset.newDecoder();
CharBuffer charBuffer = decoder.decode(buffer);
System.out.println(charBuffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
这个Java程序演示了使用FileChannel从文件读取和写入到另一个文件的方法。程序读取一个Java文件“FileChannelTest.java”的内容并将其写入到一个新文件“a.txt”中。它还使用CharsetDecoder将MappedByteBuffer的内容解码为字符缓冲区,并将其打印到控制台。
package _2;
import java.io.*;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
public class RandomFileChannelTest {
public static void main(String[] args) {
File f = new File("a.txt");
try(RandomAccessFile randomAccessFile = new RandomAccessFile(f,"rw");
FileChannel channel = randomAccessFile.getChannel();
) {
MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_WRITE,0,f.length());
channel.position(f.length());
channel.write(buffer);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
演示了怎么使用RandomAccessFile来向一个文件后追加数据。
package _2;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.Charset;
import java.nio.charset.CharsetDecoder;
public class ReadFile {
public static void main(String[] args) {
File f = new File("src/_2/ReadFile.java");
try(FileInputStream in = new FileInputStream(f);
FileChannel channel = in.getChannel();
){
ByteBuffer buffer = ByteBuffer.allocate(256);
while (channel.read(buffer) != -1) {
buffer.flip();
Charset charset = Charset.forName("GBK");
CharsetDecoder decoder = charset.newDecoder();
CharBuffer charBuffer = decoder.decode(buffer);
System.out.println(charBuffer);
buffer.clear();
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
演示了如何使用像传统方式一样一点点取出数据的方法。
字符集和Charset
对于文件来讲,之所以能显现字符,是因为系统将底层的二进制序列转换成字符的缘故。在这个过程中涉及两个概念:编码和解码。
- 编码(Encode):把字符序列转换成二进制序列
- 解码(Decode):把二进制序列转换成字符序列
Java默认使用的是Unicode字符集,但很多操作系系统并不使用Unicode字符集。
Charset就是用来处理字节序列和字符序列之间的转换关系,该类包含了用于创建解码器和编码器的方法,还提供了获取Charset所支持字符集的方法,Charset类是不可变的。
Charset类提供了一个availableCharsets静态方法来获取当前JDK所支持的所有字符集。

每个字符集都有一个字符串名称,也被称为字符串别名。
- GBK:简体中文字符集
- BIG5:繁体中文字符集
- ISO-8859-1:ISO拉丁字母表No.1,也叫做ISO-LATIN-1
- UTF-8:8位UCS转换格式
- UTF-16BE:16位UCS转换格式,Big-endian(最低地址存放高位字节)字节顺序。
- UTF-16LE:16位UCS转换格式,Little-endian(最高地址存放低位字节)字节顺序。
- UTF-16:16位UCS转换格式,字节顺序由可选的字节顺序标记标识。
创建Charset对象
Charset cs = Charset.forName("GBK");
创建完之后就可以通过该对象的newDecoder()、 newEncoder()这两个方法分别返回CharsetDecoder和CharsetEncoder 对象,代表该Charset的解码器和编码器。
如果只是进行简单的编码、解码操作只需要使用以下几个方法就好了:
- CharBuffer decode(ByteBuffer bb):将ByteBuffer中的字节序列转换成字符序列的便捷方法
- ByteBuffer encode(CharBuffer cb):将CharBuffer中的字符序列转换成字节序列的便捷方法
- ByteBuffer encode(String str):将String中的字符序列转换成字节序列的便捷方法
在String类里也提供了一个getBytes(String charset)方法, 该方法返回byte[],该方法也是使用指定的字符集将字符串转换成字节序列。
文件锁
文件锁是是用来阻止多个进程并发修改同一个文件。
文件锁控制文件的全部或部分字节的访问。
在NIO中,Java提供了FileLock来支持文件锁定功能,在FileChannel中提供的lock和tryLock方法获得文件锁FileLock对象,从而锁定文件。当lock试图锁定某个文件时,如果无法获得文件锁,则程序一直阻塞,tryLock会直接返回。
如果FileChannel只是想多顶文件的部分内容,使用下列的:
- lock(long position, long size, boolean shared):对文件从position开始,长度为size的内容加锁,该方法是阻塞式 的。
- tryLock(long position, long size, boolean shared):非阻塞式的加锁方法。参数的作用与上一个方法类似。
当参数shared为true时,表明该锁是一个共享锁,它将允许多个进程读取文件,但阻止获得排他锁。当 shared为false时,表明该锁是一个排他锁,它将锁住对该文件的读写。程序可以通过调用FileLock的isShared来判断它获得的锁是否为共享锁。
直接用lock或tryLock获取的文件锁是排他锁。
处理完文件后通过FileLock的release()方法释放文件锁

上面程序中的第一行粗体字代码用于对指定文件加锁,接着程序调用Thread.sleep(10000)暂停了10秒后才释放文件锁(如程序中第 二行粗体字代码所示),因此在这10秒之内,其他程序无法对a.txt文件进行修改
文件锁虽然可以用于控制并发访问,但对于高并发访问的情形,还是推荐使用数据库来保存程序信息,而不是使用文件。
- 在某些平台上,文件锁仅仅是简易性的,并不是强制性的。这意味着即使一个程序不能获得文件锁,也可以对该文件进行读写/
- 在某些平台上,不能同步得锁定一个文件并把它映射到内存中。
- 文件锁是由Java虚拟机所持有的,如果两个Java程序使用同一个Java虚拟机运行,则它们不能对同一个文件加锁。
- 在某些平台上关闭FileChannel的时候,会释放Java虚拟机在该文件上的所有锁,所以应该避免对同一个被锁定的文件打开多个FileChannel。
NIO.2的功能和用法
Java7对原有的NIO进行了改进,主要包括下面两方面:
- 提供了全面的文件IO和文件系统访问支持
- 基于异步的Channel的IO
Path、Paths和Files核心API
NIO.2提供了Path接口,它代表一个平台无关的平台路径。还提供了Files和Paths两个工具类。
Files包含了大量操作文件的静态工具方法。
Paths包含了两个返回Path的静态工厂方法。
Paths 提 供 了 get(String first, String…more)方法来获取Path对象,Paths会将给定的多个字符串连 缀 成 路 径 , 比 如 Paths.get(“g:”, “publish”, “codes”) 就 返 回 g:\publish\codes路径。
使用FileVisitor遍历文件和目录
多线程
线程概述
几乎所有的操作系统都支持同时运行多个任务,一个任务通常是一个程序,每个运行中的程序就是一个进程。当一个程序运行时,内部可能包含了多个顺序执行流,每个顺序执行流就是一个线程。
线程和进程
所有运行中的任务通常对应一个进程(Process)。当一个程序进入内存运行时,就变成一个进程。进程是处于运行过程中的程序,并且具有一定的福利宫娥能,晋城市系统进行资源分配和调度的一个独立单位,进程是系统进行资源分配和调度的一个独立单位,进程包含三个特征:
- 独立性:进程是系统中独立存在的实体,她可以拥有自己独立的资源,每一个进程都拥有自己私有的地址空间。在没有经过进程本是允许的情况下,一个用户进程不可以直接访问其他进程的地址空间
- 动态性:进程与程序的区别就是程序只是一个静态的指令集和,进程是一个正在系统中活动的指令集和。在进程中加入了时间的概念。进程具有自己的生命周期和各种不同的状态,这些概念在程序中都是不具备的。
- 并发性:多个进程可以在单个处理器上并发执行,多个进程之间不会互相影响。
并发性和并行性不同,并发性是在同一时刻只有一条指令执行,但多个进程指令被快速轮换执行,使得在宏观上便想出多个进程同时执行的效果。并行性是指在同一时刻,有多条指令在多个处理器上同时执行。
线程(Thread)是进程的执行单元,也被称为轻量级进程。就像进程在系统中的地位一样,线程在程序中是独立的、并发的执行流。当进程初始化之后,主线程就被创建了。
线程是进程的组成部分,一个进程可以拥有多个线程,一个线程必须有一个父进程。线程可以拥有自己的堆栈、自己的程序计数器和自己的局部变量,但不拥有系统资源,它与父线程的其他线程共享该进程所拥有的全部资源。因为多个线程共享父线程中的全部资源,所以还要确保线程不会妨碍统一进程中的其他线程。
线程是独立运行的,并不知道进程中是否还有其他线程存在。线程的执行是抢占式的,也就是说,当前运行的线程在任何时候都可能被挂起,以便另外一个线程可以运行。
一个线程可以创建和撤销另一个线程,同一个进程中的多个线程之间可以并发执行。
操作系统可以同时执行多个任务,每个任务就是进程;进程可以同时执行多个任务,每个任务就是线程
多线程编程的优点
- 进程之间不能共享内存,但线程之间可以
- 系统创建进程需要为该进程重新分配系统资源,但创建线程代价小得多。
线程的创建和启动
Java使用Thread类代表线程,所有的线程对象都是Thread类或其子类的实例。每个线程实际上就是执行一段顺序执行的代码。Java使用线程执行体来代表这段程序流。
继承Thread类创建线程类
- 定义Thread的类的子类,并重写该类的run方法,该run方法的方法体就代表了线程需要完成的任务。因此run方法也叫做线程执行体。
- 创建Thread子类的实例
- 调用线程对象的start方法来启动该线程。
package _1;
public class FirstThread extends Thread{
private int i;
@Override
public void run() {
for (;i < 100;i++) {
System.out.println(getName() + "__" + i);
}
}
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + "" + i);
if (i == 20) {
new FirstThread().start();
new FirstThread().start();
}
}
}
}
该程序中包含三个线程:主线程和创建的两个线程,主线程的线程执行体就是main
- Thread.currentThread():该方法返回的是正在执行的线程对象
- getName():该方法返回调用该方法的线程名字
程序可以通过setName为线程设置名字,在默认情况下,主线程的名字是main,其他用户启动的依次为:Tread-0、Tread-1…;
使用继承Thread类的方法来创建线程类时,多个线程之间无法共享线程类的实例变量。
实现Runnable接口创建线程类
- 定义Runnable接口的实现类,并重写run
- 创建实例,并以此实例作为Thread的target创建Thread对象。
- 调用线程对象的start来启动线程
package _1;
public class second implements Runnable{
private int i;
@Override
public void run() {
for (; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
}
}
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
if (i == 20) {
second st = new second();
new Thread(st,"新线程1").start();
new Thread(st,"新线程2").start();
}
}
}
}
在采用Runnable接口的方式下创建的多个线程可以共享线程类的实例变量。
因为在这种方式下,程序所创建的Runnable对象只是线程的target,而多个线程可以共享一个target,所以多个线程可以共享一个线程类的实例变量。
使用Callable和Futurn创建线程
- 创建Callable接口的实现类,并实现call方法,该call方法将作为线程执行体,且该call方法有返回值,再创建Callable实现类的实例。
- 使用FuturnTask类来包装Callable对象,该FutrueTask对象封装了该Callable对象的call方法的返回值。
- 使用FutureTask对象作为Thread对象的target创建并启动线程
- 调用FutureTask对象的get方法获得子线程执行结束后的返回值。
package _1;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class Third {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Integer> task = new FutureTask<>(() ->{
int i = 0;
for (;i < 100; i++) {
System.out.println(Thread.currentThread().getName() + "的循环变量i的值:" + i);
}
return i;
});
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + "的循环变量i的值:" + i);
if (i == 20) {
new Thread(task,"有返回值的线程").start();
}
}
System.out.println("子线程的返回值:" + task.get());
}
}
创建线程的三种方式对比
实现Runnable、Callable接口的方式创建多线程的优缺点:
- 线程类只是实现了Runnable接口或Callable接口,还可以继承其他类
- 在这种方式下,多个线程可以共享同一个target对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU、代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
- 劣势是,编程稍复杂,如果需要访问当前线程需要使用Thread.currentThread()方法
采用实现Thread类方式创建多线程的优缺点:
- 优点:编写简单,可以直接使用getName
- 劣势:线程已经继承Thread类,无法继承其他父类
线程的生命周期
线程的生命周期中有新建(New)、就绪(Ready)、运行(Running)、阻塞(Blocked)和死亡(Dead)五种状态。
新建和就绪状态
当使用new创建了一个线程之后,该线程就处于新建状态,此时和其他Java对象一样,仅由JVM为其分配内存,并初始化成员变量的值。
当执行了start之后,就处于就绪状态。运行取决于JVM中线程调度器的调度。
**启动线程的正确方法是调用Thread对象 的start()方法,而不是直接调用run()方法,**否则就变成单线程程序 了。 需要指出的是,调用了线程的run()方法之后,该线程已经不再处 于新建状态,不要再次调用线程对象的start()方法。
运行和阻塞状态
处于就绪状态的线程获得了CPU,开始执行run方法的线程执行体,就处于运行状态。
当一个线程开始运行后,它不可能一直处于运行状态(除非它的 线程执行体足够短,瞬间就执行结束了),线程在运行过程中需要被中断,目的是使其他线程获得执行的机会,线程调度的细节取决于底层平台所采用的策略。对于采用抢占式策略的系统而言,系统会给每个可执行的线程一个小时间段来处理任务;当该时间段用完后,系统就会剥夺该线程所占用的资源,让其他线程获得执行的机会。在选择下一个线程时,系统会考虑线程的优先级。
当如下情况,线程进入阻塞状态:
- 线程使用sleep方法主动放弃所占用的处理器资源
- 线程调用了一个阻塞式IO方法,在该方法返回之前,该线程被阻塞。
- 线程试图获得一个同步监视器,但该同步监视器整备其他线程所持有
- 线程在等待某个通知(notify)
- 程序调用了现成的suspend方法将线程挂起,但这个方法容易导致死锁,所以应该避免使用。
当前正在执行的线程被阻塞之后,其他的线程就可以获得只能够的机会。被阻塞的线程会在合适的时候重新进入就绪状态。
线程从阻塞状态只能进入就绪状态,无法直接进入运行状态。
线程死亡
线程会以如下三种方式结束,结束后就处于死亡状态
- run或call执行完成之后,正常结束
- 线程抛出一个未捕获的Exception或Error
- 直接调用该线程的stop方法来结束,该方式容易引起死锁
调用线程对象的isAlive方法,当线程处于新建和死亡时,该方法返回false,其他返回true。
控制线程
join线程
Thread提供了让一个线程等待另一个线程完成的方法——join方法。当在某个程序执行流中调用其他线程的join方法时,调用线程将被阻塞,直到join方法加入的join线程执行完为止。
join方法通常由使用线程的程序调用,以将大问题划分为许多小问题,每个小问题分配一个线程。当所有的小问题都得到处理后,再调用主线程来进一步操作。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









