









Lucene 简述
Lucene是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。
数据可以三种:
- 结构化数据(具有固定格式或有限长度的数据)
- 非结构化数据
- 半结构化数据
对于结构化数据一般使用SQL语句查询,而非结构化数据有顺序扫描和全文检索。
Lucene 文件结构
层次结构:索引 -> 段 -> 文档 -> 域 -> 词
文档是Lucene索引和搜索的原子单位,文档为包括一个或多个域的容器,域则真正包括被搜索的内容,域值通过分词技术处理,得到多个词元。
Lucene 索引创建
创建索引的三步:需要检索的数据(Document)、分词技术(Analyzer)、索引创建(indexer)
//创建索引关键类
//IndexWrite
IndexWrite indexWrite=new IndexWrite(directory,indexWriteConfig);
//Directory
Directory directory=FSDirectory.open(new File("C://index));
//Analyzer 创建标准分词器
Analyzer analyzer=new StandardAnalyzer(Version.LUCENE_43);
//Document
Document doc=new Document();
//Filed
doc.add(new TextField("filedname","测试",Store.YES));Java实现索引创建
package com.lucene;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.*;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import java.io.File;
import java.io.IOException;
/**
* Created with IntelliJ IDEA.
* User: YEN
* Date: 2016/8/17
* Time: 08:26
*/
/**
* 索引创建
*/
public class IndexCreate {
public static void main(String[] args) throws IOException {
//指定分词技术,这里使用的是标准分词
Analyzer analyzer=new StandardAnalyzer(Version.LUCENE_43);
//indexWriter的配置信息
IndexWriterConfig indexWriterConfig=new IndexWriterConfig(Version.LUCENE_43,analyzer);
//索引的打开方式:没有就创建,有就打开
indexWriterConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
Directory directory=null;
IndexWriter indexWriter=null;
try{
//确定索引文件的位置 这里是本地文件存储
directory= FSDirectory.open(new File("C://index"));
//如果索引处于锁定状态就解锁
if(indexWriter.isLocked(directory)){
indexWriter.unlock(directory);
}
//指定索引的操作对象为indexWrite
indexWriter = new IndexWriter(directory, indexWriterConfig);
}catch ( Exception e ){
e.printStackTrace();
}finally {
indexWriter.close();
directory.close();
}
Document doc1=new Document();
//StringField域
doc1.add(new StringField("id","abc", Field.Store.YES));
//TextField域,采用指定的分词技术
doc1.add(new TextField("content","Lucene测试", Field.Store.YES));
//IntField域
doc1.add(new IntField("num",1, Field.Store.YES));
//将文档写入到索引中
indexWriter.addDocument(doc1);
indexWriter.commit();
}
}
Lucene 索引检索
索引检索的四步:搜索关键字(Keywords)、分词技术(Analyzer)、检索索引(Search)、返回结果。
java实现索引检索
package com.lucene;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import java.io.File;
import java.io.IOException;
/**
* Created with IntelliJ IDEA.
* User: YEN
* Date: 2016/8/17
* Time: 08:42
*/
public class IndexSearch {
public static void main(String[] args) {
Directory directory=null;
try {
//索引硬盘存储路径
directory= FSDirectory.open(new File("C://index"));
//读取索引
DirectoryReader directoryReader=DirectoryReader.open(directory);
//创建索引检索对象
IndexSearcher search=new IndexSearcher(directoryReader);
//分词技术
Analyzer analyzer=new StandardAnalyzer(Version.LUCENE_43);
//创建Query
QueryParser parser=new QueryParser(Version.LUCENE_43,"content",analyzer);
Query query=parser.parse("Lucene案例");
//检索索引,获取符合条件的前10条记录
TopDocs topDocs=search.search(query,10);
if(null!=topDocs){
System.out.println(topDocs.totalHits);
for ( int i = 0; i < topDocs.scoreDocs.length; i++ ) {
Document doc=search.doc(topDocs.scoreDocs[i].doc);
System.out.println("id="+doc.get("id"));
System.out.println("content="+doc.get("content"));
}
}
directory.close();
directoryReader.close();
} catch ( IOException e ) {
e.printStackTrace();
} catch ( ParseException e ) {
e.printStackTrace();
}
}
}
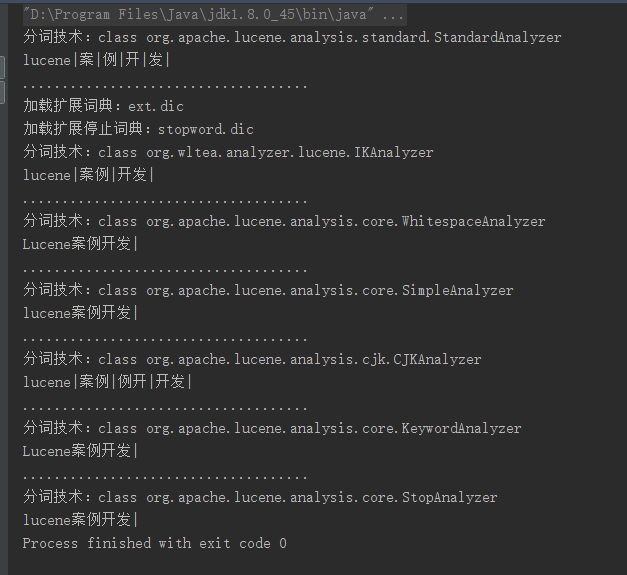
Lucene 分词器
常用分词器:
- StandardAnalyzer 标准分词器
- IKAnalyzer 基于Lucene的第三方中文分词技术
- WritespaceAnalyzer 空格分词器
- SimpleAnalyzer 简单分词器
- CJKAnalyzer 二分法分词器
- KeywordAnalyzer 关键词分词器
- StopAnalyzer 被忽略词分词器
package com.lucene;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cjk.CJKAnalyzer;
import org.apache.lucene.analysis.core.KeywordAnalyzer;
import org.apache.lucene.analysis.core.SimpleAnalyzer;
import org.apache.lucene.analysis.core.StopAnalyzer;
import org.apache.lucene.analysis.core.WhitespaceAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.IOException;
import java.io.StringReader;
/**
* Created with IntelliJ IDEA.
* User: YEN
* Date: 2016/8/17
* Time: 08:57
*/
public class AnalyzerDemo {
private static String str="Lucene案例开发";
public static void main(String[] args) {
//定义分词器对象
Analyzer analyzer=null;
analyzer=new StandardAnalyzer(Version.LUCENE_43);
AnalyzerDemo.Show(analyzer);
System.out.println("\n....................................");
AnalyzerDemo.Show(new IKAnalyzer());
System.out.println("\n....................................");
AnalyzerDemo.Show(new WhitespaceAnalyzer(Version.LUCENE_43));
System.out.println("\n....................................");
AnalyzerDemo.Show(new SimpleAnalyzer(Version.LUCENE_43));
System.out.println("\n....................................");
AnalyzerDemo.Show(new CJKAnalyzer(Version.LUCENE_43));
System.out.println("\n....................................");
AnalyzerDemo.Show(new KeywordAnalyzer());
System.out.println("\n....................................");
AnalyzerDemo.Show(new StopAnalyzer(Version.LUCENE_43));
}
//输出分词结果
public static void Show(Analyzer analyzer){
StringReader stringReader=new StringReader(str);
try {
TokenStream tokenStream=analyzer.tokenStream("",stringReader);
tokenStream.reset();
CharTermAttribute termAttribute=tokenStream.getAttribute(CharTermAttribute.class);
System.out.println("分词技术:"+analyzer.getClass());
while ( tokenStream.incrementToken() ){
System.out.print(termAttribute.toString()+"|");
}
} catch ( IOException e ) {
e.printStackTrace();
}
}
}















 8549
8549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









