










数据获取是进行数据分析与数据挖掘的基础,而数据预处理是影响数据挖掘结果好坏的关键因素。
Python数据获取
数据获取是指从数据源采集数据,微数据分析与数据挖掘做数据准备的工作。
从键盘获取数据
>>>value=input()
>?"YEN"
>>>value
'"YEN"'从文本文件读取数据
#打开文件
# r 只读 w 只写 a 附加到文件末尾 r+读写
# 如果要以二进制的方式打开,需要在mode后面加字符"b" 比如"rb" "wb"
f=open("G:\\PythonTest.txt","r")
# 读取文件数量,括号内不加参数默认全部读取,加参数读取指定数量
print("读取全部内容:"+f.read())
# 关闭文件
f.close()
# 读取文件一行内容
print("读取一行内容:"+f.readline())
# 读取文件所有行到数组里[line1,line2...linen]
print(f.readlines())
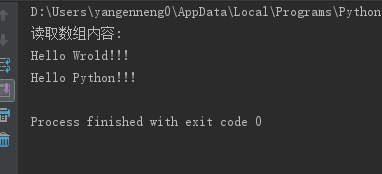
print("读取数组内容:")
lines=f.readlines()
for line in lines:
line=line.strip()
print(line)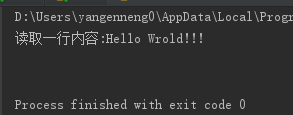
import linecache
#与打开文件方式不同,linecache模块可以进行缓存优化,提高文件的读取效率
print(linecache.getline("G:\\PythonTest.txt",2)) #读取第两行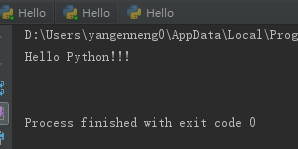
从word读取数据
from win32com import client # 从win32com包引入client包
# import win32com.client
word=client.Dispatch('Word.Application') # 创建对象实例
doc=word.Documents.Open(r'G:\Demo.doc') # 打开
print(doc.content) #打印
doc.Close() #关闭
word.Quit()通过Excel读取数据
# 导入模快
import xlrd
# 打开excel
data=xlrd.open_workbook('G:\datatest.xls')
# 1.查看并打印文件包含的sheet名称
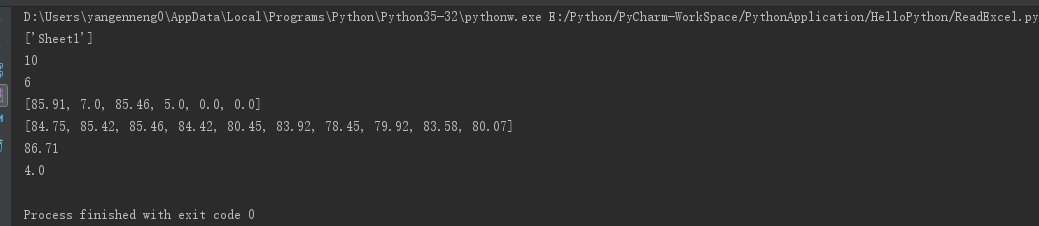
sheet_names=data.sheet_names()
print(sheet_names)
# 通过序列顺序获取
table=data.sheet_by_index(0)
# 2.获取第一张工作表的行数和列数
nrows=table.nrows
print(nrows)
ncols=table.ncols
print(ncols)
# 3.获取第一张工作表的第二行和第二列的值(数组)
print(table.row_values(2))
print(table.col_values(2))
# 4.获取特定单元格的值
print(table.cell_value(0,0))
print(table.cell_value(0,1))表中的数据
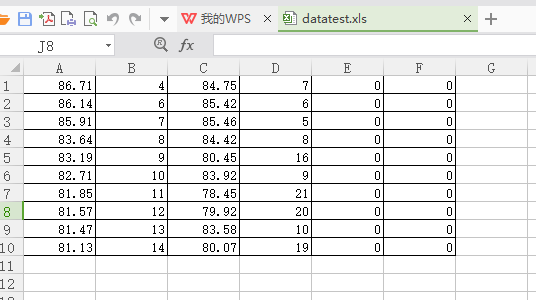
运行结果
从Mysql数据库获取数据
import pymysql
#打开数据库
db=pymysql.connect('localhost','root','admin','messagedb')
#使用cursor()获取操作游标
cursor=db.cursor()
# 使用execute执行sql语句
cursor.execute("select version()")
# 使用fetchone()方法获取一条数据
data=cursor.fetchone()
print("数据库版本:")
print(data)
db.close()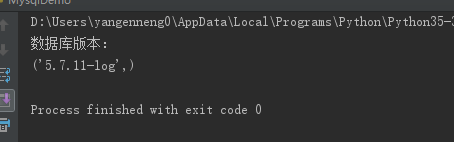
import pymysql
#打开数据库
db=pymysql.connect('localhost','root','admin','messagedb')
#使用cursor()获取操作游标
cursor=db.cursor()
try:
# 使用execute执行sql语句
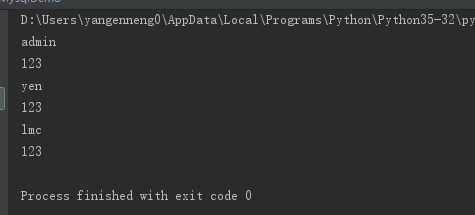
cursor.execute("select * from tb_user")
result=cursor.fetchall()
for row in result:
name=row[1]
password=row[2]
print(name)
print(password)
except:
print("操作异常")
db.close()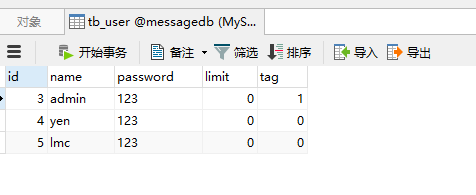
从互联网上获取数据
爬虫,即网络爬虫,自动抓取万维网信息的程序或者脚本。















 918
918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









