







 文章讲述了Transformer模型中位置嵌入的重要性,如何通过正弦和余弦函数生成与词嵌入结合的序列位置表示,以及其实现方法,包括预计算和动态生成两种方式。
文章讲述了Transformer模型中位置嵌入的重要性,如何通过正弦和余弦函数生成与词嵌入结合的序列位置表示,以及其实现方法,包括预计算和动态生成两种方式。
Transformer模型中位置嵌入层的设计目的是为了给输入序列中的每个位置提供一个独特的向量表示,因为Transformer摒弃了循环结构,无法像RNN那样通过递归过程直接捕捉序列的位置信息。在Transformer中,位置嵌入是通过对位置索引进行编码来实现的。
位置嵌入通常采用正弦和余弦函数生成一系列固定大小的向量,这些向量与词嵌入相加后,共同构成序列中每个位置的输入表示:
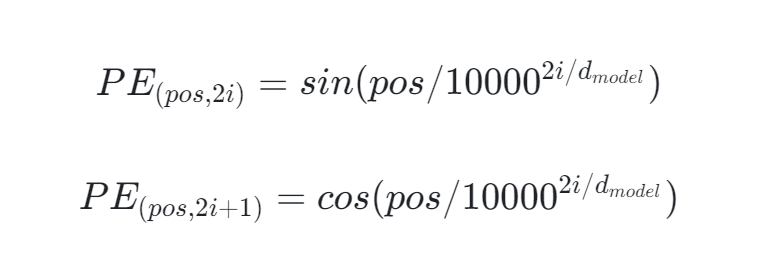
- 上面一行的公式计算的是偶数位置上的位置嵌入。
- 下面一行的公式计算的是奇数位置上的位置嵌入。
- PE(pos,2i) 和PE(pos,2i+1) 分别代表偶数和奇数位置上位置嵌入的第 i 维值。
- pos 表示当前位置的索引。
- dmodel 是模型的维度大小,即输出向量的长度。
- sin 和 cos 分别是正弦函数和余弦函数。
这种编码方式确保了不同的位置会有不同的向量表示,并且在连续的位置之间,位置嵌入的变化体现出一种平滑过渡和周期性的特性,理论上可以覆盖任意长度的序列。最终,每个输入单词的词嵌入加上对应位置的位置嵌入,就构成了Transformer模型实际处理的输入序列。
在实际编程实现中,位置嵌入矩阵可以预先计算并存储,也可以在运行时动态生成,然后与输入序列的词嵌入矩阵相加,得到完整的带有位置信息的输入向量序列。
import math
def get_position_embedding(pos, dim, d_m 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









