







 本文探讨了一种结合卷积神经网络和Transformer的混合模型在基于EEG的情绪分类任务中的应用。实验比较了逻辑回归、支持向量机、随机森林和多层感知机等多种传统机器学习模型,以及深度学习的多层感知机和混合模型在情绪识别上的性能。
本文探讨了一种结合卷积神经网络和Transformer的混合模型在基于EEG的情绪分类任务中的应用。实验比较了逻辑回归、支持向量机、随机森林和多层感知机等多种传统机器学习模型,以及深度学习的多层感知机和混合模型在情绪识别上的性能。
目录
关于
- 本实验利用结合了卷积神经网络 (CNN) 和 Transformer 组件的混合架构,实现基于 EEG 的有效情绪分类。
- 尝试各种机器学习模型,包括逻辑回归、支持向量机 (SVM)、随机森林分类器和多层感知器 (MLP) 神经网络,以比较不同模型的性能。
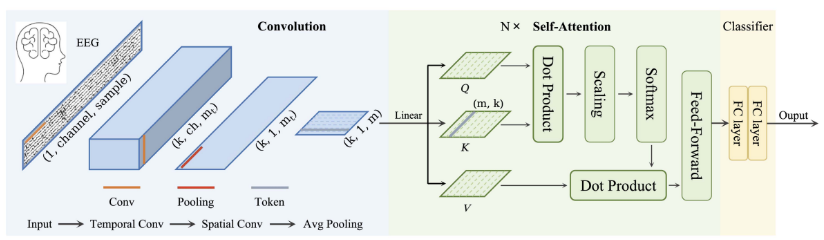
图片来自于: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9991178
工具


数据集

数据集简述
脑电图数据是从两名受试者(1 名男性、1 名女性,年龄 20-22 岁)收集的,针对特定电影剪辑引发的六种情绪状态(积极、消极、中性)中的每一种状态。该数据集包括从脑电波中收集的 324,000 个数据点,这些数据点被重新采样到 150Hz。还收集了中性脑电波数据,作为代表受试者静息情绪状态的第三类数据。从四个电极(TP9、AF7、AF8、TP10)记录 EEG 数据,并进行处理以生成通过 1 秒滑动窗口提取的统计特征数据集。
方法实现
数据读取
raw_eeg_data = pd.read_csv('../data/features_raw.csv')
raw_eeg_data.head()
# plot the F8 column
plt.figure(figsize=(20, 5))
plt.plot(raw_eeg_data['F8'])
plt.title('F8 Electrode Data')
plt.ylabel('Voltage (uV)')
plt.xlabel('Time')
plt.show()
# plot the F7 column
plt.figure(figsize=(20, 5))
plt.plot(raw_eeg_data['F7'])
plt.title('F7 Electrode Data')
plt.ylabel('Voltage (uV)')
plt.xlabel('Time')
plt.show()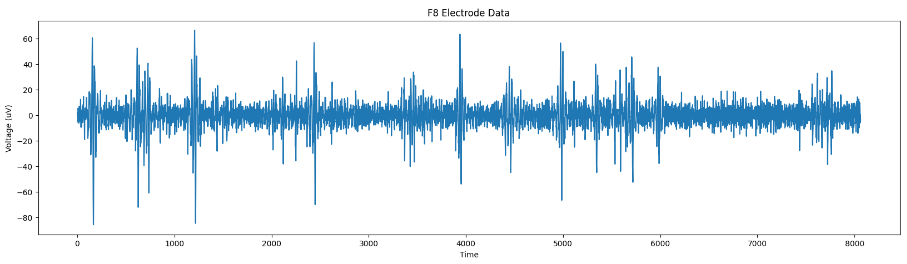 数据预处理
数据预处理
X = eeg_emotions_data.drop(['label'], axis=1)
y = eeg_emotions_data['label']
# Encoding categorical data
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_emotions = LabelEncoder()
y = labelencoder_emotions.fit_transform(y)
# Standardizing the features in the dataset
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)传统机器学习模型(逻辑回归,支持向量机,随机森林)
from sklearn.linear_model import LogisticRegression
import pickle
# Create a logistic regression classifier
model = LogisticRegression(random_state=2003, multi_class='multinomial', max_iter=1000)
# Train the model
model.fit(X_train, y_train)
# Evaluate the model
evaluate_model(y_test, model.predict(X_test))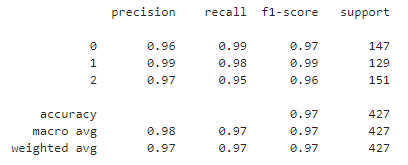
from sklearn.svm import SVC
# Create a model: a support vector classifier
model = SVC(kernel='rbf', gamma='auto', C=1.0, random_state=2003)
# Train the model
model.fit(X_train, y_train)
# Evaluate the model
evaluate_model(y_test, model.predict(X_test))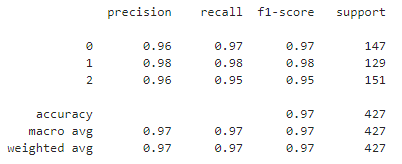
from sklearn.ensemble import RandomForestClassifier
# Create a random forest Classifier.
model = RandomForestClassifier(n_estimators=100, random_state=2003)
# Train the model
model.fit(X_train, y_train)
# Evaluate the model
evaluate_model(y_test, model.predict(X_test))
在传统机器模型,我们可以发现随机森林的性能表现最好;
多层感知机模型
class EEGClassifier(nn.Module):
def __init__(self, input_dim, num_classes, hidden_dim=256):
super(EEGClassifier, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_dim, num_classes)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
input_dim = 2548 # Number of features in EEG signal
num_classes = 3 # Number of classes for classification
model = EEGClassifier(input_dim, num_classes)
loss = nn.CrossEntropyLoss()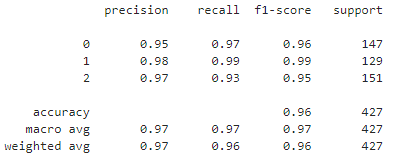
CNN+transfomer模型
class EEGConformer(nn.Module):
def __init__(self, input_dim, num_classes):
super(EEGConformer, self).__init__()
# CNN
self.conv1 = nn.Conv2d(1, 40, kernel_size=(1, 25), stride=(1, 1))
self.conv2 = nn.Conv2d(40, 40, kernel_size=(1, input_dim), stride=(1, 1))
self.batchnorm = nn.BatchNorm2d(40)
# Transformer
self.layernorm1 = nn.LayerNorm(40)
self.multiheadattention = nn.MultiheadAttention(40, 1)
self.layernorm2 = nn.LayerNorm(40)
self.feedworward_block = nn.Sequential(
nn.Linear(40, 32),
nn.GELU(),
nn.Dropout(p=0.1),
nn.Linear(32, 40)
)
# MLP
self.fc1 = nn.Linear(40, 32)
self.fc2 = nn.Linear(32, 32)
self.fc3 = nn.Linear(32, num_classes)
def forward(self, x):
# CNN
x = x.unsqueeze(1).unsqueeze(1)
x = self.conv1(x)
x = self.conv2(x)
x = self.batchnorm(x)
# Transformer
x = x.squeeze()
x = self.layernorm1(x)
attn_out = self.multiheadattention(x, x, x)
x = x + nn.Dropout(0.1)(attn_out[0])
x = self.layernorm2(x)
x = self.feedworward_block(x)
x = nn.Dropout(p=0.1)(x)
# MLP
x = self.fc1(x)
x = F.elu(x)
x = nn.Dropout(p=0.5)(x)
x = self.fc2(x)
x = F.elu(x)
x = nn.Dropout(p=0.3)(x)
x = self.fc3(x)
return x
input_dim = 2524 # Number of features in EEG signal
num_classes = 3 # Number of classes for classification
model = EEGConformer(input_dim, num_classes)
loss = nn.CrossEntropyLoss()代码获取
后台私信,注明来意和文章名称;
其他问题,欢迎沟通交流。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











