









大数据产业创新服务媒体
——聚焦数据 · 改变商业
我最近在思考这样一个问题——向量数据库是不是数据库版的GPU,如果是,那现在发生在芯片界的故事会不会在数据库领域也重演一遍。
为什么会有这种想法呢?因为引发GPU和向量数据库崛起的是同一个因素,那就是AI,更具体的说是大模型。既然大模型能让芯片的王位易主,那同样的事情为什么不会在数据库领域重演呢?这是一个有意思的话题,接下来我们就这种可能性来展开分析。

从图形处理到AI计算,GPU如何一步步击败CPU?
既然是将向量数据库与GPU进行类比,那在讨论向量数据库之前,我们先来通过英伟达回顾一下GPU的发展历程,并试图从中找到历史前进的方向。
20年前,英伟达主要还是一个做图形处理器的公司,专门为游戏玩家提供高质量的图像体验。谁能想到,这个靠卖显卡起家的公司,竟然成了AI时代的最大赢家?

英伟达的转折点出现在2006年。当时,它推出了CUDA(Compute Unified Device Architecture),一个让GPU不仅仅能处理图像,还能执行复杂计算任务的架构。这是个什么概念?简单来说,CUDA让GPU不仅能画图,还能“动脑子”。突然之间,英伟达的显卡不再只是游戏机,而是可以在科学计算、金融分析、甚至AI领域大展拳脚的强大工具。

英伟达没有停下脚步,它把握住AI兴起的机会,逐步转型为AI计算的核心硬件供应商。从最初的图形处理到如今的AI计算,英伟达一步步走上了巅峰。
那么,英伟达是怎么做到的?答案在于它的产品线。从Tesla到V100,再到A100,以及最新的Blackwell B200,英伟达的每一代GPU都在推动AI技术的进步。

Tesla是英伟达进军AI计算的先锋,它是专为高性能计算设计的GPU,不仅能处理海量数据,还能以极高的效率完成复杂计算任务。
然后是V100,它的出现让深度学习训练速度飙升,尤其是在处理大规模神经网络时,V100表现得非常出色。其核心是数千个CUDA核心,能够同时处理大量并行计算任务。对比传统CPU,V100在执行矩阵运算时的速度优势堪称“碾压级”。
A100不仅继承了V100的所有优点,还进一步提升了AI计算的性能。它支持“多实例GPU”(Multi-Instance GPU,MIG),可以在一个芯片上同时运行多个独立的工作负载。这意味着一块A100可以在多个任务之间无缝切换,大大提升了AI计算的灵活性和效率。
在2024年GTC人工智能大会上,英伟达正式推出了基于的Blackwell架构的B200芯片。这款芯片被誉为世界上最强大的AI芯片之一,设计功率约为700W,能够在现有系统中工作。
需要指出的是,英伟达每隔一段时间就会推出新的技术产品,但这些产品迭代有一个不变的主题,那就是数据并行计算能力的持续提升。
传统的CPU,擅长的是串行计算。它像一个人,专注地做一件事,效率很高。但当你让它同时做几千件事,它就会“抓瞎”。

而GPU则不同。GPU的架构是为了并行计算而生的。它有成千上万个小型处理单元,可以同时处理大量数据。就像你有成千上万个工人,可以同时开工。
举个例子,AI模型的训练过程,离不开矩阵乘法。这种计算需要处理大量的数字,CPU处理起来会显得很吃力。但GPU却能把这些任务“分发”给无数个小型处理单元,让它们同时运作。结果是,GPU可以在几秒钟内完成CPU需要几分钟甚至几小时才能完成的任务。
英伟达的CUDA架构,就是这场“分工合作”的幕后推手。它让每个GPU核心都能独立执行任务,并通过智能调度,确保所有核心都高效运作。这种并行处理能力,让GPU在处理AI任务时展现出了无与伦比的优势。

高维数据的噩梦,为什么传统数据库越来越吃力?
那么,GPU的成功故事与数据库领域的变化有什么关系?很简单。AI改变了数据本身的形态和处理方式,而这不仅改变了硬件的格局,也正在推动数据库领域发生类似的变革。
在AI时代,高维数据成了主角。无论是图片、文本,还是用户行为,它们最终都被转化为高维度的向量。这些向量包含着丰富的信息,但它们的处理却给传统数据库带来了巨大的挑战。
说到数据库,大家首先想到的可能就是Oracle、MySQL和PostgreSQL。这些老牌数据库系统,几十年来一直稳坐数据管理的“铁王座”。它们擅长处理表格数据,能够高效地管理事务、执行复杂的查询,并确保数据的一致性和完整性。

然而,这些数据库的设计初衷是为了解决二维表格里的数据问题。表格数据是有规律的、低维度的,这使得关系型数据库(RDBMS)在处理这些数据时如鱼得水。但当我们需要处理的是成百上千维度的向量数据时,传统数据库的架构就显得有些“老态龙钟”了。
举个例子,当你用MySQL或PostgreSQL存储和查询数千维的文本嵌入或图像特征时,你会发现查询时间变长了,系统资源被迅速耗尽。结果是,传统数据库越来越难以胜任这些复杂的AI任务。
为什么传统数据库不适合处理向量数据?其核心就是所谓的“维度诅咒”。

“维度诅咒”,这个术语听起来很吓人,实际上,它描述的是高维空间中数据处理的复杂性。当数据维度增加时,数据点之间的距离变得越来越均匀,导致传统的索引结构(如B树)在进行相似度搜索时,需要遍历大量数据,导致查询效率急剧下降。
B树索引,尽管在低维空间中表现良好,但在高维度环境下,它的层级结构会迅速膨胀,导致搜索效率大幅降低。传统的关系型数据库并没有针对这种情况进行优化,结果就是它们在处理高维度数据时表现不佳。
哈希索引虽然可以加速某些类型的查询,但它的均匀分布特性并不适合相似度搜索。哈希函数将数据映射到固定长度的值,但在高维向量中,两个相似的向量在哈希值上可能差异巨大,这使得相似度搜索变得低效。

而且,传统数据库的查询优化器是为关系型数据设计的。它们优化的是SQL查询、表连接和磁盘I/O,而非高维向量的“最近邻搜索”,这让传统数据库在面对现代AI应用时显得力不从心。
所以,传统数据库在高维向量数据的处理上遇到了明显的瓶颈,它们的架构、索引机制和优化策略,都不适合处理这些复杂的数据类型,这种性能困境为向量数据库的崛起创造了机会。就像CPU的串行计算逻辑,不能很好的处理这些高维向量数据一样,这催生了GPU这种并行处理器的崛起。
向量数据库异军突起,谁将成为数据界的英伟达?
就像GPU解决了AI计算的问题,向量数据库正试图解决高维度数据的存储和检索问题。它们设计之初就是为了处理这些复杂的向量数据,而不是传统的行列数据。
所以,如果说GPU是AI计算领域的王者,向量数据库可能就是数据存储和检索领域的下一颗“冉冉升起的星”。

那么,这些向量数据库究竟能干什么呢?
举个例子,假设你上传一张风景照片,想要找到类似的图片。传统数据库需要逐个对比,速度慢得让人抓狂。而使用向量数据库,系统能够在数百万张图片中快速定位到最相似的几张,几乎是瞬间完成。这种性能的提升,让图片搜索变得更加智能和高效。

向量数据库的崛起不是偶然,它们解决了传统数据库在高维数据处理上的“痛点”,在许多现代AI应用场景中展现出了强大的潜力。就像英伟达改变了芯片行业的规则,向量数据库也正在重新定义数据存储和检索的未来。
那么,谁将可能成为向量数据库领域的英伟达呢?
我们不得不提到几个“明星选手”:Milvus、Pinecone和Weaviate。这些产品各有千秋,但共同点都是针对高维向量数据进行了优化。

Milvus是一个开源向量数据库,由中国公司Zilliz开发。Milvus的核心在于它对多种索引类型的支持,比如HNSW(Hierarchical Navigable Small World)和IVF(Inverted File)。这些索引可以让Milvus在处理数百万甚至数十亿条向量数据时,依然能够快速地找到相似项。简单来说,Milvus的索引结构使得它在“高维空间”里穿行如飞,特别适合用来处理海量的AI生成数据。
在英伟达的GTC2024大会上,其与Zilliz联合发布了Milvus2.4版本,这也号称是全球首个GPU加速向量数据库。
接着是Pinecone,一个基于云的向量数据库。Pinecone的最大亮点是它的云原生架构,支持自动扩展和无服务器(serverless)操作。Pinecone的低延迟查询和简便的API,让它成为那些需要实时处理高维数据的应用程序的理想选择。
还有Weaviate,这个向量数据库特别擅长与机器学习模型结合。它不仅能存储和检索向量数据,还可以直接集成大语言模型(如BERT),实现智能语义搜索。
需要指出的是,在中国,向量数据库领域正迎来快速发展的黄金时期,众多本土公司纷纷推出了各具特色的向量数据库产品,比较典型的如云创数据、星环科技、爱可生、腾讯云、阿里云等。
云创数据的cVector向量计算一体机,它针对特征向量计算场景进行了深度优化。通过用优化后的CPU代替GPU,cVector有效解决了高维向量计算中的算力不足问题,为大规模特征向量计算提供了强有力的支持。
星环科技的StellarDB是一款图数据库产品,同时配备了向量搜索引擎和向量计算引擎等配套产品。StellarDB不仅具备高效的数据存储和检索能力,还能快速进行向量相似度计算,满足各种AI应用的需求。此外,星环科技还积极与英特尔等国际巨头展开合作,共同推动向量数据库技术的发展。
爱可生的TensorDB是一款向量数据库产品,专门用来处理向量数据的存储和管理需求。它具备快速向量检索和相似度计算的能力,为AI应用提供了数据支持。目前,TensorDB已累计用户超过400家。
除了这些独立向量数据库厂商,科技巨头们也在积极布局。
其中,腾讯云的Tencent Cloud VectorDB是一款全托管的自研企业级分布式数据库服务,专为存储、检索、分析多维向量数据而设计。它支持多种索引类型和相似度计算方法,单索引可支持千亿级向量规模。此外,由Facebook AI Research开发的Faiss,腾讯率先在国内大规模应用。Faiss擅长多线程处理和GPU加速,尤其适合用于图像检索和推荐系统。
再说说阿里巴巴的AnalyticDB,阿里的这款数据库在混合存储架构上进行了创新,不仅支持传统的结构化数据,还集成了向量检索功能。阿里的技术团队通过对向量检索算法的优化,使得AnalyticDB能够在亿级规模的数据中,快速找到相似项,为商家和消费者提供更精准的服务。
剧变总是突然发生的,现在的小不点,也许不久就能掀翻老霸主
不得不承认,向量数据库现在还只是一个小不点,在整个数据库市场的占比还很低。即使最乐观的估计,向量数据库的市场占比都没超过10%。

但是,AI大模型正在以摧枯拉朽之势,急速的改造着很多行业。芯片的市场格局已经被它重塑了,接下来,很可能就会轮到数据库。所以,我们不能因为向量数据库的渗透率不高,就觉得其搅动不了市场格局。
我们需要注意的是,英特尔的没落和英伟达的崛起,都是在跨过某个临界点之后,在短时间内快速发生的。
让我们来看一组数据。
英伟达现在市值2.9万亿美元(8月14日),其市值不是缓慢增长到这么高的,而是在短期内实现了巨大的跃升。2023年10月的时候,其股价才40美元,而8个月之后的2024年6月,其股价最高达到了140美元。也就是说在短短8个月内,英伟达股价飙升了3倍多,黄仁勋也从“小黄”变身“黄教主”。

反观英特尔,其股价也在短时间内经历了剧变。2023年12月,其股价还能接近50美元,在2024年8月,已经跌到20美元了。也是在短短8个月时间内,英伟达股价跌掉了60%。
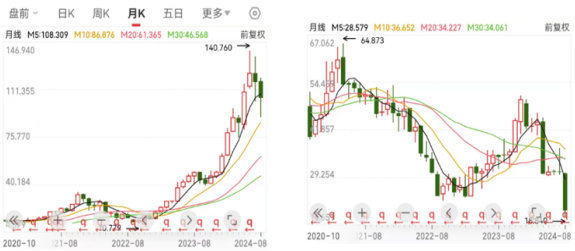
英伟达(左)和英特尔(右)股价走势图(月K) 数据来源:同花顺
如果觉得股价变化太快了,不能很好反映基本面,那我们来看看营收情况。在2023年,英伟达的收入突然暴涨了一倍多。
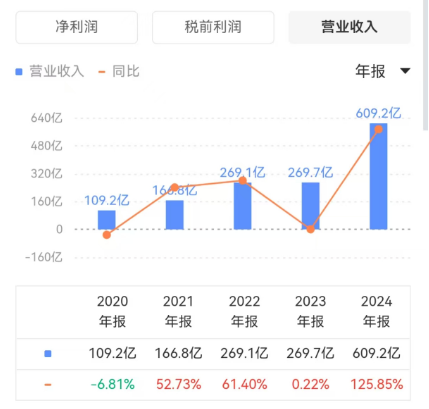
英伟达营收情况 数据来源:同花顺
如果聚焦到英伟达的核心引擎——数据中心业务上,这个态势更明显。在一年以内,其数据中心收入,从150亿美元,突然暴涨3倍,达到470亿美元。
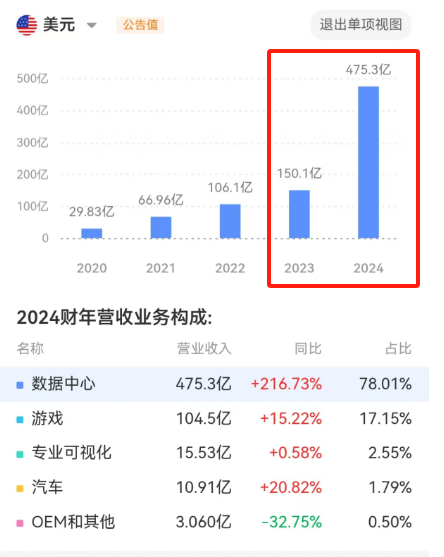
英伟达数据中心业务收入情况 数据来源:同花顺
而其净利润更夸张,在一年之内暴涨了近6倍。
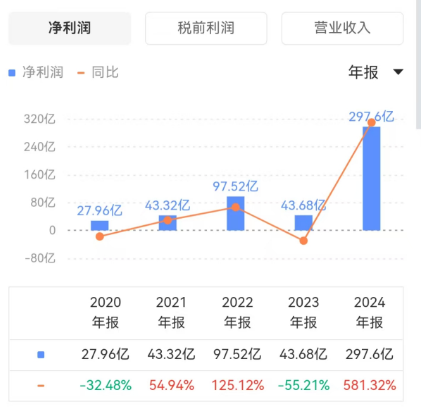
英伟达净利润情况 数据来源:同花顺

再来看看英特尔。其营收在2021年之前还能稳住,略有增长,近两年开始大幅度下跌。
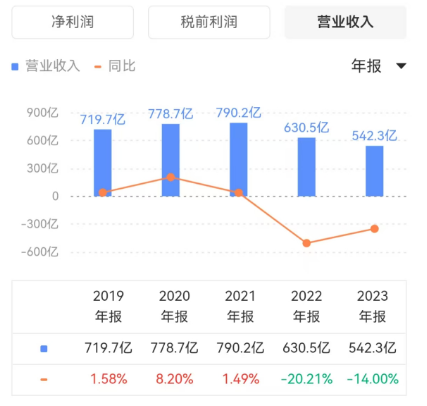
英特尔营收情况 数据来源:同花顺
其净利润情况更明显,在近两年突然断崖式下跌。
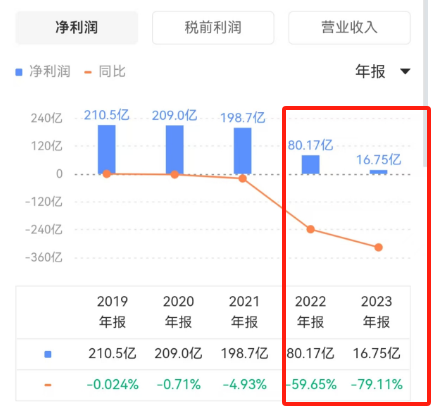
英特尔净利润情况 数据来源:同花顺
无论是从英伟达还是英特尔身上,我们都看到,一个行业的改变,并不是匀速进行的,而是经过一段时间的蓄能,达到某个临界点,被某个因素触发之后,在短时间内发生剧变。这个规律,在智能手机、光伏、电动汽车等产业上,不断得到验证。
以电动汽车为例,从2005年到2015年,中国新能源汽车用了10年,渗透率才突破1%。从2016年到2019年,3年多时间,渗透率提升到了5%。然而,在2021年,新能源车渗透率激增至14.8%,之后开始狂飙,2022年突破27%,2023年突破33%。目前,最新的数据是,中国新能源汽车的渗透率已经超过50%。
那么,数据库行业是不是也走到了那样一个“剧变”时刻呢?如果AI大模型对数据库的影响,像其对芯片的影响一样强烈,那我们将在几年之后见到一个完全不同的数据库市场。也许,那个时候,现在如日中天的巨头们,会像现在的英特尔一样,成为昨日黄花。而现在不起眼的一些向量数据库玩家中,也许能成长出另一个英伟达一样的霸主。

能否构建出英伟达CUDA式的护城河,是问题的关键
决定未来走向的因素很多,对于向量数据库厂商而言,其能否成长为数据版的英伟达,有一个关键变量,那就是能不能发展出一个产业生态。
向量数据库技术的优越性已经显现,但仅有技术并不足以成为最终的赢家。历史告诉我们,生态系统的构建是决定一项技术能否持续发展的关键因素。
某种程度上,谁能率先构建起一个成功的生态系统,谁就能在向量数据库的竞赛中脱颖而出。生态系统的构建,也是成为数据版英伟达的必要条件。
什么是生态系统?简单来说,就是围绕核心技术所构建的一整套支持系统、工具链和合作伙伴网络。英伟达之所以能在AI计算领域称霸,不仅仅是因为它的GPU性能强大,更因为它打造了一个完善的生态系统——CUDA。
CUDA不仅是一个并行计算架构,还是一个巨大的开发者社区和工具链。无数的开发者、科研人员和企业依赖CUDA进行AI开发,这使得英伟达的技术一旦被采用,想要转移到其他平台变得非常困难。这种粘性,是英伟达构筑护城河的关键。
向量数据库厂商想要成为数据管理领域的新霸主,同样需要构建一个强大的生态系统,但这并不容易。当前,向量数据库在生态系统的建设上还处于初级阶段,距离英伟达的水平还有很长的路要走,有一大堆难题需要解决,比如:
工具链的完善:当前,向量数据库的开发工具相对较少。为了让更多的开发者接受和使用,向量数据库需要提供完整的工具链支持,包括易用的查询语言、调试工具、数据可视化工具等。这些工具不仅要满足基本的数据库管理需求,还要适应向量数据的独特特性。
开发者社区的培育:相比于传统数据库,向量数据库的开发者社区还处于起步阶段。如何吸引更多的开发者参与其中,并持续贡献代码和经验,是一个重要的挑战。开放源代码、举办开发者大会、提供激励机制,都是可能的解决方案,但这些都需要时间和资源的投入。
应用集成的广泛性:向量数据库要成功,必须能够与现有的系统无缝集成。这包括与主流编程语言的兼容,与现有数据库系统的互操作性,以及与各种AI模型的集成。目前,向量数据库在这些方面的支持还不够广泛,限制了它们在实际应用中的普及。
教育和培训资源的匮乏:向量数据库是一个相对较新的概念,开发者和企业在这方面的知识储备还不够。要想推广这种技术,必须投入大量资源进行教育和培训,帮助用户理解和掌握这一新技术。没有足够的培训资源和认证体系,用户在转向向量数据库时会面临很高的学习曲线。
合作伙伴网络的建立:与传统数据库不同,向量数据库的合作伙伴网络还不够成熟。它们需要与云服务提供商、数据分析平台、AI模型供应商建立紧密的合作关系。这不仅可以扩大其市场覆盖面,还可以通过这些合作伙伴的资源和客户基础,进一步推动向量数据库的普及。
目前,一些向量数据库公司在试图构建这样的生态系统,但都遇到了不小的问题。
Milvus正在努力构建自己的开源社区,作为开源项目,Milvus的优势在于能够吸引全球开发者的参与和贡献。Zilliz公司也在积极推动Milvus的产业化,通过提供商用版和云服务来增强其市场竞争力。但问题在于,开源项目的生态系统建设需要时间和资源。如何平衡社区的开放性与商业化的需求,是Milvus必须面对的挑战。
Pinecone的策略则是通过云服务建立自己的生态系统,Pinecone提供简便的API接口,使得开发者可以轻松集成向量数据库功能。这种“即插即用”的模式降低了技术门槛,吸引了大量中小企业和开发者的使用。然而,Pinecone的挑战在于如何在大型企业中推广,并与其他云服务竞争,尤其是在AWS、谷歌云等巨头已经推出类似服务的情况下。
Weaviate则通过与机器学习模型的紧密集成,构建自己的生态系统。它不仅提供向量数据库功能,还能直接与NLP模型结合,实现更智能的语义搜索。这种垂直整合的方式,让Weaviate在特定领域中表现得尤为出色。但问题是,这种深度集成也可能限制其在其他领域的扩展性。如何在保持技术优势的同时,扩大应用场景,是Weaviate面临的关键问题。
此外,一些互联网大厂的介入,可能会对向量数据库的生态建设产生深远影响。一方面,它们带来了巨大的资源和市场渠道,能够快速推动技术的普及。另一方面,它们的强势进入也可能对独立的向量数据库厂商构成威胁,尤其是在市场份额和技术标准的争夺战中。
全球范围内,谷歌、AWS等科技巨头也在紧盯向量数据库的崛起。他们的策略往往是通过收购或合作的方式,迅速将这些新兴技术整合到自己的云服务平台中。
例如,谷歌在AI技术上的积累,让它有能力开发自己的向量检索服务,并通过谷歌 云进行推广。而AWS则可能通过收购初创公司或推出自有服务,进一步巩固其在云计算市场的统治地位。
在中国市场,阿里云通过与国内外数据库初创公司的合作,试图将向量数据库的能力集成到其云计算平台中。腾讯云则通过将Faiss与其大数据平台集成,为Faiss的生态系统建设提供支持。
向量数据库的技术优势已经不容忽视,但要真正成为数据管理领域的新霸主,它们还需要构建强大的生态系统。无论是通过开源社区的力量,还是通过云服务的推广,向量数据库的厂商们都在努力寻找属于自己的护城河。然而,面对来自全球大厂的竞争和合作压力,如何在这个快速变化的市场中站稳脚跟,依然是一个巨大的挑战。
传统数据库不甘心,老牌霸主们并不会轻易让位
还有一个重要的问题,向量数据库想要夺取数据库的王座,还要看看老牌的数据库厂商同不同意。
就像人类的帝国一样,任何一个新王朝的建立,都是建立在战胜老帝国的基础上的。而旧王可不会那么轻易交出自己的权柄。
即使在芯片领域,英特尔也不是轻易就把自己的王位交给英伟达的。在这之前,英特尔做了大量的努力。虽然,英特尔的复兴努力失败了,但并不意味着在数据库领域,老牌霸主们不能成功狙击向量数据库新贵。

毕竟,老牌霸主们的实力和资源不可小觑。那么,这些巨头在面对向量数据库的崛起时,采取了哪些应对策略?是选择创新突围,还是通过整合和并购来保持自己的地位?
先说说Oracle和Microsoft SQL Server,这些传统数据库巨头并没有坐以待毙。他们深知,不能忽视AI带来的高维数据处理需求,于是纷纷推出了自己的应对方案。
Oracle近年来加大了对AI的投入。例如,Oracle引入了支持AI的数据库功能,试图通过整合机器学习算法来增强数据库的智能性。虽然Oracle并未完全转型为向量数据库,但它的产品正在逐步扩展,增加对复杂数据类型的支持,比如嵌入向量和图数据。这些努力,意在保持其在企业级数据库市场的领导地位。
再看Microsoft SQL Server。微软的策略是通过Azure平台整合AI能力,将SQL Server与Azure机器学习服务结合。早在SQL Server 2019版,就引入了Big Data Clusters功能,能够处理大规模的数据和复杂的查询任务。这表明,微软也在积极应对AI时代的挑战,试图通过增强其数据库产品的能力,来抵御向量数据库的冲击。
MongoDB则采取了另一种策略。作为NoSQL数据库的代表,MongoDB本身就以灵活性和可扩展性著称。面对向量数据处理的需求,MongoDB选择了多模态进化的路径。
MongoDB在最新版本中引入了多模态数据库的概念,允许用户在同一个数据库中存储和处理多种数据类型,包括文档、图、时间序列数据,甚至是向量数据。这种多模态的设计,旨在提供一个“万能”数据库平台,能够处理从结构化数据到非结构化数据的一切。虽然MongoDB的向量处理能力还不如专门的向量数据库那么强大,但这种“全能”策略使得它在面对复杂应用场景时,依然保持了竞争力。
国内的数据库厂商也在积极应对这一趋势,比如,蚂蚁金服旗下的OceanBase和PingCAP的TiDB。
OceanBase是蚂蚁金服自主研发的分布式关系型数据库,近年来在技术革新方面动作频频。面对向量数据库的崛起,OceanBase也开始探索如何在其现有的强大事务处理能力基础上,加入对向量数据的支持。通过引入AI优化和向量处理插件,OceanBase希望在高维数据处理的战场上找到一席之地。
TiDB则是另一位国产数据库的代表。作为一款HTAP(Hybrid Transactional and Analytical Processing)数据库,TiDB原本就擅长处理混合型的事务和分析任务。面对向量数据的需求,PingCAP也在其数据库架构中引入了新的扩展模块,试图融合向量处理能力,提供一站式的解决方案。虽然这些尝试还在初期,但它们反映了传统数据库厂商在技术创新上的努力。
谈到国产数据库,就不得不提达梦数据、人大金仓、南大通用和神舟通用这“四朵金花”。面对向量数据库的冲击,他们也在想办法应对。其中,达梦数据、人大金仓都在推出支持向量计算和检索的数据库解决方案,南大通用还发布了一款基于云平台的向量数据库产品——GBase Cloud Vector DB。
那么,传统数据库的这些应对策略,能否帮助它们在与向量数据库的竞争中保持优势?或者说,这些老牌霸主是否会像英特尔在面对英伟达时一样,最终只能勉强维持市场份额?
其实,在数据库领域,已经发生过一次老牌霸主成功守住王位的故事。这个故事的主角,就是Oracle。
随着云计算的发展,数据上云成为大势所趋。Oracle作为数据库的老牌霸主,也面临云转型的问题。最开始,不少人并不看好Oracle的云业务,觉得将会有一个新兴的云数据库厂商,将Oracle挑落马下。
然而,故事并没有朝这个方向发展。虽然有不少云数据库厂商发展很好,但Oracle的云转型也比较成功。根据财报数据,2024财年,Oracle的云计算和内部部署软件收入占比,达到了83.96%,且这个比例还在提升。
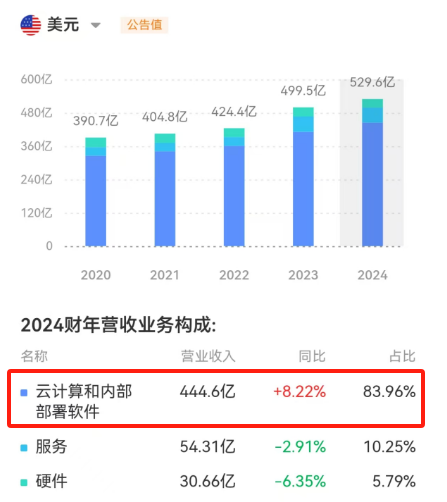
Oracle业务构成 数据来源:同花顺
对于Oracle的云转型努力,资本市场也给出了认可,其股价走势一直很不错,并没有像英特尔一样“跌跌不休”。
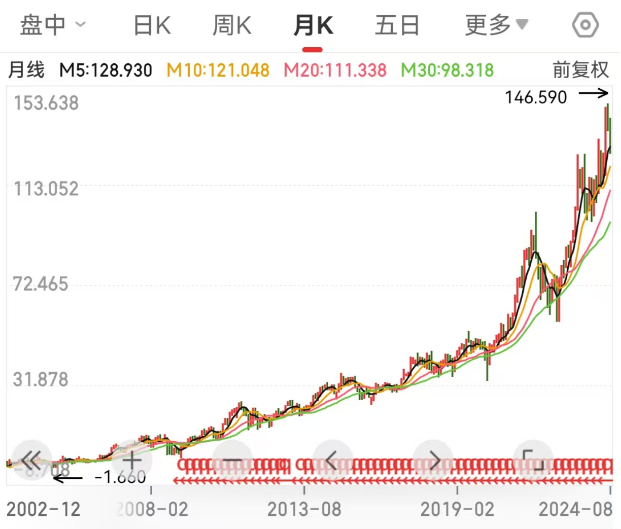
Oracle股价走势 数据来源:同花顺
最终,无论是老牌数据库霸主守擂成功,还是新兴向量数据库厂商抢班夺权,数据的向量化都是一种不可阻挡的时代大势。
为什么?因为各行各业需要处理的,不再是简单的表格数据,而是高维度的向量数据。想象一下,每次你在网上购物时,那些推荐给你的商品背后,都有一个复杂的AI模型在分析你的行为,并生成向量数据。

随着大模型的规模化商用,数据的形式将发生翻天覆地的变化,高维度、非结构化的数据将如潮水般涌来。这些数据需要快速、高效地存储和检索,这正是向量数据库的拿手好戏。

AI模型,特别是那些动辄上亿参数的深度学习模型,生成的向量数据需要在毫秒级内完成相似度计算和匹配。传统数据库就像老黄牛,而向量数据库则是高铁。效率上的差距,决定了它们在未来的竞争中,向量数据库会有多大的发展空间。
可以预见,向量数据库的市场渗透率将稳步增长,并在跨越某个“奇点”之后,快速拉升。不确定的是,这个变化的时间周期是多久,可能一两年,可能三五年,也可能更久。
未来会怎样,让我们拭目以待吧。

文:一蓑烟雨 / 数据猿
责编:凝视深空 / 数据猿



















 837
837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









