







章节引导:至今为止,我们的 LLM 应用主要驰骋在文本数据的世界里。我们学习了如何与 LLM 高效交互,如何利用 RAG 增强其知识,如何构建 Agent 让其采取行动。然而,人类的感知和交互远不止于文本,我们生活在一个充满图像、声音、视频的多彩世界中。本章,我们将一起迈出关键一步,跨越文本的边界,初步探索如何让我们的 AI 应用具备理解和处理多模态 (Multimodal) 信息的能力,特别是视觉信息——图像。我们将了解当前多模态 LLM 的核心能力与集成挑战,学习 LangChain 和 LlamaIndex 如何初步支持这些能力,并通过一个动手实验,构建一个简单的图文结合应用,感受多模态带来的新可能。
重要提示:多模态模型与 API
本章涉及的多模态功能依赖于支持视觉等模态输入的 LLM,如 OpenAI 的 GPT-4V(ision) 系列、Google 的 Gemini Pro Vision 等。使用这些模型通常需要特定的 API 调用方式和相应的 API Key 权限。请确保你已了解并配置好相关模型的访问。
11.1 多模态 LLM:看图说话的智能
近年来,大型语言模型在理解和生成文本方面取得了惊人进展。而最新的前沿突破,正是将这种理解能力扩展到了文本之外的模态,其中视觉模态(图像)是发展最快、应用最广的方向之一。
核心能力概览
当前主流的多模态 LLM(通常指具备视觉理解能力的模型)展现出以下核心能力:

- 图像描述 (Image Captioning): 为给定图像生成简洁或详细的文字描述。(“这张图里有什么?” -> “一只猫懒洋洋地躺在阳光下的窗台上。”)
- 视觉问答 (Visual Question Answering - VQA): 根据图像内容回答用户提出的问题。(“图里那只猫是什么颜色的?” -> “它是橘白相间的。”)
- 物体识别与定位 (Object Recognition/Detection - 基础): 识别图像中的主要物体,有时能大致指出其位置(不一定像专业的目标检测模型那样精确输出边界框)。(“图里有几把椅子?” -> “图里有两把椅子。”)
- 光学字符识别 (Optical Character Recognition - OCR): 读取并识别图像中的文字。(“这张图片里的标语写了什么?” -> “标语上写着 ‘保持创新’。”)
- 图表/图示理解: 理解柱状图、折线图、流程图等图示的内容,并回答相关问题。(“这张柱状图显示哪个季度的销售额最高?”)
这些能力使得 LLM 不再是“只读圣贤书”的书呆子,而开始具备“看图说话”的能力,为构建更丰富、更贴近现实世界的应用打开了大门。
主流模型简介
- OpenAI GPT-4V(ision) 系列: 作为 GPT-4 的多模态版本,具备强大的图文理解和对话能力。通常通过 OpenAI API 访问 (例如模型名称
gpt-4-vision-preview或更新的gpt-4o)。 - Google Gemini Pro Vision: Google 的多模态模型,可以通过 Google AI Studio 或 Vertex AI API 访问,同样具备出色的 VQA 和图像理解能力。
- LLaVA (Large Language and Vision Assistant): 一个流行的开源多模态模型系列,有不同大小和能力的版本,可以在本地部署(需要相应硬件)。
- 其他: Anthropic 的 Claude 3 系列也具备了图像理解能力。还有许多研究性或特定领域的多模态模型不断涌现。
框架集成挑战
将多模态能力集成到现有的 LLM 应用框架(如 LangChain, LlamaIndex)中,并非易事,面临诸多挑战:
- API 异构性: 不同模型提供商接收图像的方式不同(有的接受图像 URL,有的接受 Base64 编码的图像数据),API 的请求/响应结构也各异。框架需要提供统一的抽象层来屏蔽这些差异(
litellm在这方面也有涉及多模态的尝试)。 - 图像表示与嵌入: 如何将图像信息有效地输入给 LLM?简单地将整个图像像素作为输入通常不可行。多模态模型内部通常有专门的“视觉编码器”(Vision Encoder) 来处理图像,将其转换为 LLM 可以理解的嵌入表示。对于 RAG 场景,如何生成既包含文本信息又包含图像信息的多模态嵌入 (Multimodal Embeddings)(如 CLIP 模型产生的嵌入)是关键。
- 成本与效率: 处理图像(尤其是高分辨率、大量图像)比处理文本需要更多的计算资源和时间。API 调用成本通常也更高。需要在效果、成本和响应速度之间做权衡。
- Prompt 工程: 如何设计同时包含文本指令和图像输入的 Prompt?如何引导 LLM 关注图像的特定区域或方面?多模态 Prompt 的设计是新的挑战。
- 多模态 RAG: 这是 RAG 的自然延伸,但复杂度更高:
- 索引: 如何索引包含图文的文档?是单独索引文本和图像,还是生成多模态嵌入?
- 检索: 如何根据文本查询检索相关图像?如何根据图像查询检索相关文本或图像?如何进行图文混合查询?
- 融合: 如何将检索到的文本块和图像信息有效地融合起来,作为上下文提供给 LLM?
框架正在努力解决这些挑战,为开发者提供更便捷的多模态应用构建能力。
11.2 LangChain/LlamaIndex 的多模态支持:连接图文
LangChain 和 LlamaIndex 作为主流框架,都在积极地扩展对多模态能力的支持。
LangChain 实践
LangChain 主要通过扩展其消息类型和集成支持视觉的 ChatModel 来支持多模态(目前以图像为主)。
-
表示图像输入: 在 LangChain 的
ChatMessage体系中,HumanMessage的content字段不再局限于字符串,可以是一个列表 (List),列表中的元素可以是文本块或图像块。图像块通常表示为一个字典,包含type: "image_url"和image_url(包含 URL 或 Base64 数据)。from langchain_core.messages import HumanMessage # 示例:构建包含文本和图像的消息 message = HumanMessage( content=[ {"type": "text", "text": "这张图片里有什么特别之处?"}, { "type": "image_url", "image_url": { # 可以是公开可访问的 URL # "url": "https://example.com/image.jpg", # 或者 Base64 编码的数据 URI "url": "data:image/jpeg;base64,{base64_encoded_image_string}" }, }, ] ) -
使用支持视觉的 ChatModel: 你需要实例化一个明确支持视觉输入的 ChatModel 类,例如
ChatOpenAI并指定视觉模型。from langchain_openai import ChatOpenAI import base64 import requests # 用于获取网络图片或读取本地图片 # 配置视觉模型 # llm_vision = ChatOpenAI(model="gpt-4-vision-preview", max_tokens=1024) llm_vision = ChatOpenAI(model="gpt-4o", max_tokens=1024) # gpt-4o 也支持 # # --- 获取图像数据 (示例) --- # # 方式一:从 URL 获取 # image_url = "https://upload.wikimedia.org/wikipedia/commons/thumb/3/3c/Field_sparrow01.jpg/1280px-Field_sparrow01.jpg" # Example sparrow image # # image_response = requests.get(image_url) # # image_data_uri = f"data:{image_response.headers['Content-Type']};base64,{base64.b64encode(image_response.content).decode('utf-8')}" # 方式二:从本地文件读取 try: with open("sparrow_image.jpg", "rb") as image_file: # 请先下载一张图片并命名为 sparrow_image.jpg image_data_base64 = base64.b64encode(image_file.read()).decode('utf-8') image_data_uri = f"data:image/jpeg;base64,{image_data_base64}" except FileNotFoundError: print("Error: sparrow_image.jpg not found. Please download an image.") image_data_uri = None # Handle error # --- 发送图文消息 --- if image_data_uri: vision_message = HumanMessage( content=[ {"type": "text", "text": "Describe this image in detail."}, {"type": "image_url", "image_url": {"url": image_data_uri}} ] ) print("\n--- Sending image to GPT-4V via LangChain ---") try: response = llm_vision.invoke([vision_message]) print("\nLLM Response:") print(response.content) except Exception as e: print(f"Error invoking vision model: {e}")这段代码展示了如何构建包含 Base64 图像数据的
HumanMessage,并将其发送给配置好的ChatOpenAI视觉模型以获取图像描述。
LlamaIndex 实践
LlamaIndex 在处理多模态数据方面提供了更结构化的支持,特别是针对多模态 RAG。
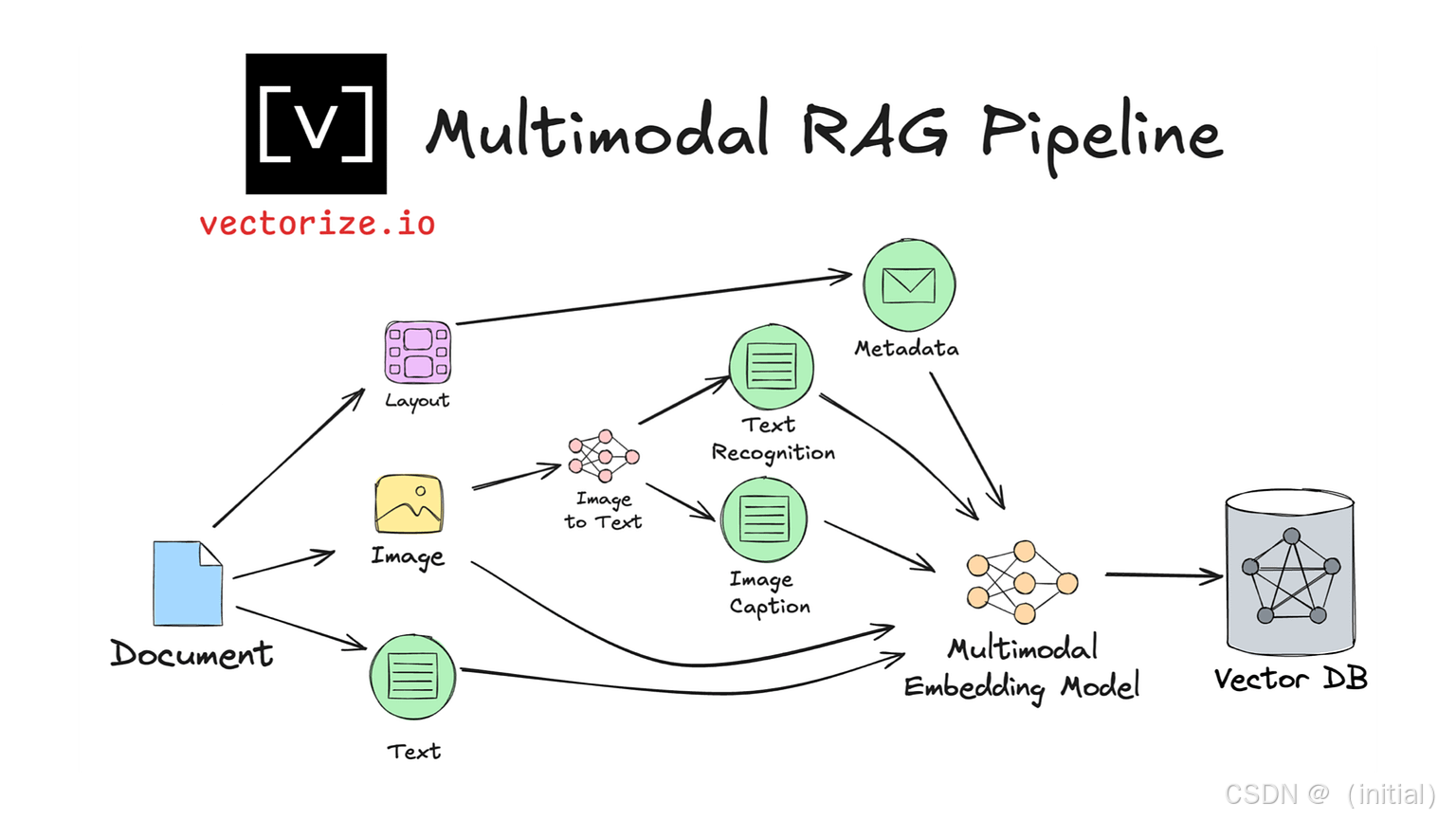
-
ImageDocument: LlamaIndex 提供了ImageDocument类来专门表示包含图像的文档。SimpleDirectoryReader可以配置为自动识别和加载目录中的图像文件。 -
多模态嵌入 (
MultiModalEmbedding): LlamaIndex 集成了支持图文联合嵌入的模型,如 OpenAI 的 CLIP 模型。你需要配置相应的嵌入类(如OpenAIClipEmbedding或更新的MultiModalOpenAIEmbedding)并可能需要安装额外依赖 (pip install llama-index-multi-modal-llms llama-index-embeddings-clip)。 -
MultiModalVectorStoreIndex: 这是 LlamaIndex 中用于构建多模态 RAG 的核心索引。它可以接收包含文本和图像的Document/Node。在索引时,它会:
- 为文本块生成文本嵌入。
- 为图像生成图像嵌入。
- (可选/通常) 可能还会让多模态 LLM 为图像生成文本描述 (caption/summary),并将这个描述的文本嵌入也存入索引。
这样,无论是文本查询还是(未来的)图像查询,都能找到相关的文本或图像信息。
-
多模态 LLM (
MultiModalLLM): LlamaIndex 提供了MultiModalLLM接口(如OpenAIMultiModal)来封装可以处理图文输入的 LLM。
# LlamaIndex 示例:构建多模态索引 (概念代码)
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, Settings
# Assuming necessary multimodal libraries are installed for LlamaIndex
# e.g., pip install llama-index-multi-modal-llms llama-index-embeddings-openai llama-index-vector-stores-chroma chromadb
# from llama_index.embeddings.openai import OpenAIEmbedding # Standard text embedding
# from llama_index.multi_modal_llms.openai import OpenAIMultiModal
# from llama_index.embeddings.clip import ClipEmbedding # Example multimodal embedding
# from llama_index.vector_stores.chroma import ChromaVectorStore
# from llama_index.core import StorageContext
# import chromadb
# # 1. Configure MultiModal LLM and Embedding in Settings
# Settings.llm = OpenAIMultiModal(model="gpt-4o", max_new_tokens=1500) # Or "gpt-4-vision-preview"
# # Settings.embed_model = OpenAIEmbedding() # Or a dedicated MultiModal Embedding like Clip
# # 2. Load data (including images)
# # SimpleDirectoryReader can automatically handle common image types if unstructured is installed well
# # Ensure you have a directory 'image_data/' containing text and image files (e.g., .jpg, .png)
# try:
# image_documents = SimpleDirectoryReader("image_data").load_data()
# print(f"Loaded {len(image_documents)} documents (text and images).")
# except FileNotFoundError:
# print("Error: 'image_data' directory not found. Please create it and add files.")
# exit()
# except ImportError:
# print("Error: Loading images might require 'unstructured' and its dependencies.")
# print("Try: pip install unstructured[local-inference] or see LlamaIndex docs.")
# exit()
# # 3. Build the MultiModal Index
# print("Building MultiModalVectorStoreIndex...")
# try:
# # Persist index to avoid rebuilding every time
# persist_dir = "./mm_vector_index"
# if not os.path.exists(persist_dir):
# # Create Chroma vector store (or other vector store)
# # chroma_client = chromadb.PersistentClient(path=persist_dir)
# # chroma_collection = chroma_client.get_or_create_collection("multimodal_collection")
# # vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# # storage_context = StorageContext.from_defaults(vector_store=vector_store)
# # Build the index (will use Settings.llm and Settings.embed_model)
# mm_index = VectorStoreIndex.from_documents(
# image_documents,
# show_progress=True,
# # storage_context=storage_context # Save to Chroma
# )
# # mm_index.storage_context.persist(persist_dir=persist_dir)
# print(f"Index built and persisted to {persist_dir}")
# else:
# # Load existing index
# # from llama_index.core import load_index_from_storage
# # storage_context = StorageContext.from_defaults(persist_dir=persist_dir)
# # mm_index = load_index_from_storage(storage_context)
# print(f"Loaded index from {persist_dir}")
# print("MultiModalVectorStoreIndex ready.")
# except Exception as e:
# print(f"Error building or loading multimodal index: {e}")
# # Common issues: API keys, dependencies, model access
# --- Indexing done, querying shown in next experiment ---
这段概念性代码展示了使用 LlamaIndex 加载包含图像的文档,并通过 VectorStoreIndex (在配置好多模态组件后,它能处理多模态数据) 来构建索引的过程。
11.3 动手实验:构建图文问答 (Visual QA) 应用
- 目标:使用 LlamaIndex 构建一个简单的应用,能够接收一张图片和用户关于图片内容的问题,并给出回答。
- 技术选型: LlamaIndex (因其多模态 RAG 支持更成熟) + OpenAI GPT-4o (或 GPT-4V)。
# Continue from the previous LlamaIndex example where 'mm_index' is built or loaded
from llama_index.core import load_index_from_storage, StorageContext
from llama_index.multi_modal_llms.openai import OpenAIMultiModal
from llama_index.core import Settings
import os
# --- 1. Ensure Settings are configured ---
# (Assuming Settings.llm and Settings.embed_model were set in the previous step)
# If not, set them here:
# Settings.llm = OpenAIMultiModal(model="gpt-4o", max_new_tokens=1500)
# Settings.embed_model = OpenAIEmbedding() # Or the appropriate embed model used for indexing
# --- 2. Load the MultiModal Index (if not already in memory) ---
persist_dir = "./mm_vector_index"
if 'mm_index' not in locals() or mm_index is None: # Check if index exists in memory
if os.path.exists(persist_dir):
print(f"Loading index from {persist_dir}...")
try:
# Need to load with the correct vector store type used during creation if not default
storage_context = StorageContext.from_defaults(persist_dir=persist_dir)
mm_index = load_index_from_storage(storage_context)
print("Index loaded successfully.")
except Exception as e:
print(f"Error loading index from {persist_dir}: {e}")
exit()
else:
print(f"Error: Index persist directory '{persist_dir}' not found. Please run the indexing step first.")
exit()
# --- 3. Create a Query Engine ---
# The query engine needs to use the MultiModal LLM
print("Creating query engine...")
mm_query_engine = mm_index.as_query_engine(
# Ensure the multimodal LLM is used for synthesis
# If Settings.llm is already the MultiModal LLM, this is automatic.
# Otherwise, specify it: llm=OpenAIMultiModal(model="gpt-4o")
similarity_top_k=3, # Retrieve top 3 relevant nodes (text or image)
)
print("Query engine ready.")
# --- 4. Perform Visual Question Answering ---
# Assume you have an image 'sparrow_image.jpg' in your 'image_data' directory used for indexing
image_path_for_query = "image_data/sparrow_image.jpg" # Path to one of the indexed images
query_text = "What is the main subject of the image?"
# query_text = "What color is the bird's head?"
print(f"\n--- Querying with text: '{query_text}' ---")
# Note: LlamaIndex query engines typically take text queries.
# The MultiModal LLM handles the visual aspect during response synthesis
# based on the retrieved image node(s).
# For direct VQA on a specific image with LlamaIndex (less common via query engine):
# Usually, you'd query based on text, and if an image node is retrieved,
# the MultiModal LLM synthesizes the answer using both text query and image context.
# Let's try a text query that should retrieve the image node
text_query_about_image = "Tell me about the bird in the image data."
try:
response = mm_query_engine.query(text_query_about_image)
print("\nVisual QA Response:")
print(response)
print("\nSource Nodes Used:")
for node in response.source_nodes:
print(f"- Node ID: {node.node_id}, Score: {node.score:.4f}")
# Check if the node contains image information (metadata might indicate)
print(f" Metadata: {node.metadata}")
# print(f" Text: {node.text[:100]}...") # Print text if available
except Exception as e:
print(f"Error during visual query: {e}")
# --- Direct MultiModal LLM Call (Alternative for single image VQA) ---
# If you just want to ask about a *specific* image without RAG:
print("\n--- Direct VQA call using MultiModal LLM ---")
from llama_index.core.schema import ImageDocument
from llama_index.core.llms import ChatMessage, MessageRole
if os.path.exists(image_path_for_query):
try:
# Load the specific image document
img_doc = ImageDocument(image_path=image_path_for_query)
direct_llm = OpenAIMultiModal(model="gpt-4o", max_new_tokens=300)
direct_query = "What is the primary color of the bird in this image?"
response_direct = direct_llm.chat(
messages=[ChatMessage(role=MessageRole.USER, content=direct_query)],
image_documents=[img_doc]
)
print(f"\nDirect VQA Query: {direct_query}")
print("Direct VQA Response:")
print(response_direct.message.content)
except Exception as e:
print(f"Error during direct VQA call: {e}")
else:
print(f"Image file not found for direct VQA: {image_path_for_query}")
代码讲解与分析:
- 我们首先确保配置了多模态 LLM (
OpenAIMultiModal) 和相应的嵌入模型(如果需要特定的多模态嵌入)在Settings中。 - 加载之前构建的
MultiModalVectorStoreIndex。 - 创建查询引擎
mm_query_engine。重要的是,这个引擎在内部进行响应合成时会使用我们配置的多模态 LLM。 - 我们执行了一个文本查询 (
text_query_about_image),这个查询的目标是能够从索引中检索到包含我们目标图像信息的Node。 - 当查询引擎调用多模态 LLM 进行响应合成时,LLM 会同时接收到文本查询和检索到的节点内容(如果检索到了图像节点,LLM 就能“看到”图像)。LLM 基于图文上下文生成最终答案。
- 我们还演示了不通过 RAG,直接使用 LlamaIndex 的
MultiModalLLM接口 (direct_llm.chat),传入文本问题和ImageDocument列表,进行单次图文问答。
11.4 特定多模态框架/库速览 (前沿)
虽然 LangChain 和 LlamaIndex 提供了基础的多模态集成,但某些特定任务或更前沿的研究可能需要更专门的工具:
- 图像/文档处理增强:
unstructured.io: 一个强大的开源库,擅长从各种复杂格式(PDF, HTML, Word, PPT, 图像等)中提取文本、表格、图片标题甚至进行布局分析。它可以作为 LlamaIndex 或 LangChain 数据加载器的底层引擎,显著提升对扫描文档或复杂 PDF 的处理效果。PyMuPDF/Pillow: Python 中处理 PDF 和图像的基础库,用于更底层的图像操作、文本提取或元数据读取。
- 视频/音频处理:
- 挑战: 理解视频(时序视觉+音频)和音频比处理静态图像更复杂。
- 代表性方向:
- 视频理解: 如 Video-LLaMA, Video-ChatGPT 等研究项目,探索将 LLM 与视频编码器结合,实现视频问答、摘要、事件检测等。框架集成仍在早期阶段。
- 音频处理: OpenAI 的
Whisper模型在语音转文本方面非常强大,可以作为将音频输入转换为文本供 LLM 处理的第一步。LangChain 等框架已集成 Whisper。
- 多模态 Agent 前沿:
- 研究热点在于构建能够感知多模态环境(看、听)并基于此进行规划和行动的 Agent。例如,能够根据用户口头指令和看到的场景来操作机械臂的机器人 Agent。这通常需要更复杂的模型架构和框架支持。
11.5 章节总结与潜力展望
本章,我们首次跨越了纯文本的界限,初步探索了多模态 LLM 应用的世界,特别是图文结合的应用。
- 核心回顾: 我们了解了多模态 LLM 的关键能力(图像描述、VQA、OCR 等)和集成挑战(API、表示、成本、Prompt、RAG)。我们学习了 LangChain 如何通过扩展消息类型支持图像输入,以及 LlamaIndex 如何通过
ImageDocument,MultiModalEmbedding,MultiModalVectorStoreIndex提供更结构化的多模态 RAG 支持。通过动手实验,我们构建了一个简单的图文问答应用。 - 价值与潜力: 让 AI 应用能够理解图像,极大地扩展了其应用范围,使其能处理更丰富、更真实世界的信息,例如:视觉辅助、自动化图像标注、图文报告分析、基于视觉的交互等。
- 未来展望: 多模态是 AI 发展的必然趋势。未来我们将看到:
- 更强大的视频和音频理解能力融入 LLM 应用。
- 能够生成图像、视频、音频等多种模态内容的跨模态生成 Agent。
- 具备更强多模态推理和交互能力的 Agent,能够更深入地理解和操作物理世界(具身智能 Embodied AI)。
多模态为 LLM 应用打开了新的想象空间。本章的初步探索为你进入这个激动人心的新领域奠定了基础。下一章,我们将继续探索 Agent 领域的前沿框架和项目。
内容同步在我的公众号:智语Bot




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











