







 超级会员免费看
超级会员免费看
微调、预训练显存对比占用
预训练LLaMA2-7B模型需要多少显存?
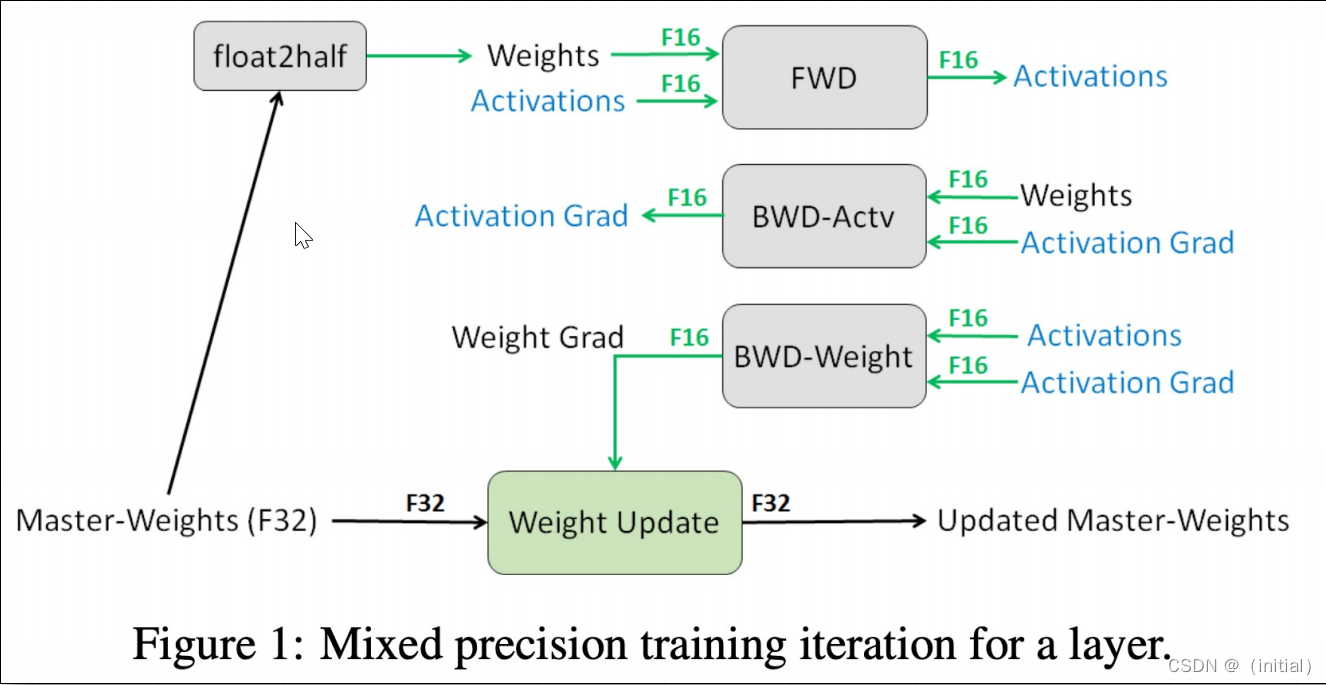
假设以bf16混合精度预训练 LLaMA2-7B模型,需要近120GB显存。即使A100/H100(80GB)单卡也无法支持。
为何比 QLoRA多了100GB?不妨展开计算下显存占用:
- 模型参数:70亿 x 2 Bytes ≈ 14GB;
- 更新梯度:70亿 x 2 Bytes ≈ 14GB;
- 优化器(e.g.AdamW),训练过程默认使用fp32精度:
- 模型参数拷贝:7B x 4Bytes ≈ 28GB
- 倍梯度数量的动量:2x7B x 4Bytes≈ 56GB
- 显存占用总计:14 x 2 + 28 x 3 = 112 GB
- 可简记为:7 x (2+2+12) = 112

使用混合精度训练模型单步流程图

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











