







LSM-tree
1.Original LSM-tree
- 优点:LSM-tree得到广泛的研究和应用的原因是:高效的写入和对于SSD低的存储花费。
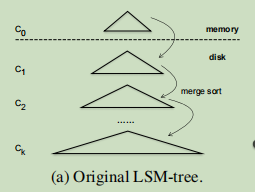
- 组成:两个类似于树的结构:C0和C1,分别在主存中(memery)和磁盘中(disk)。
- 对于快速写入,传入的KV记录被插入到C0中,只访问主存。当C0在主存中充满时,它的部分与磁盘中的C1合并,在主存中为新数据留下空间。 这种合并操作的开销随着C1的大小而增加,因为C0的叶节点可能与C1的许多叶节点重叠。 要限制这样的开销,最好将单个磁盘组件划分为多个组件:C1、C2、…、CK,其中每个组件Ci1大于其前一个Ci。 然而,随着时间的推移,单个KV记录必须在这些组件之间多次合并,从而导致写入放大。 并且,查找还必须访问具有包含键范围的多个组件,这些组件在本工作中被称为读取放大。
2.MOdern LSM-tree

为了限制写入和读取放大,许多研究将LSM-树合并成一个分层存储,具有优化的主存储器数据结构,每个级别的多级磁盘组件由多个文件或细粒度数据块。
- 传入的数据被插入到memtables中(通常以小技巧实现[24]),一旦数据满了,memtables被切换为不可变,并刷新到磁盘中的第一级L0。
- 级别Lk类似于原始设计中的组件Ck,其主要区别在于Lk被划分为许多文件(Sorted Sequence Tables、data blocks)。
- 合并策略: 合并操作有两种策略(即压缩)。The leveling policy: 对于要合并到下一级(或组件)的每个批处理,一种策略是将其与目标级别中的现有数据合并,这种方法以牺牲压缩速度为代价,将数据保持在一个有序的水平上。 The tiering policy:另一种方法是简单地将数据附加到下一个级别而不合并。 这样,压缩本身就是快速的,而牺牲了一个层次内的排序顺序。
















 9009
9009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











