






项目场景:
用自制数据集训练yolov5,数据集是yolo的txt格式。训练完成后需要用coco指标衡量模型的性能。yolov5中的val.py没有带coco的测评,所以需要自己用pycocotools实现。
步骤分解
0. 转换图像命名
由于coco数据集名称都是以0000001.jpg类似格式命名,为了后续好操作,我们沿用这样的命名格式,将图片重命名,代码如下:
import os
# 获取文件列表,并按照你希望的顺序排序
file_dir = "xxxx" #读取文件的地址
file_names = sorted(os.listdir(file_dir))
save_path="xxxxx" #保存文件的地址
# 定义起始编号
start_index = 1
# 遍历文件列表,对每个文件名进行重新命名
for file_name in file_names:
# 获取文件扩展名
_, file_ext = os.path.splitext(file_name)
# 构建新的文件名,使用 str.zfill() 方法填充编号为六位数字
new_file_name = f"{start_index:07d}{file_ext}"
# 拼接原始路径和新的文件名
old_file_path = os.path.join(file_dir, file_name)
new_file_path = os.path.join(save_path, new_file_name)
# 重命名文件
os.rename(old_file_path, new_file_path)
# 增加编号
start_index += 1
上述代码得到的结果是:
1. 需要得到groundtruth的json文件
a.yolo格式的txt标签数据格式如下:
3 0.482528 0.424537 0.00994318 0.0231481
5 0.773295 0.319907 0.00909091 0.0564815
4 0.366903 0.400463 0.0286932 0.0490741
3 0.287642 0.444907 0.0178977 0.106481
5 0.546591 0.199074 0.00852273 0.0703704
5 0.578125 0.198148 0.00965909 0.0740741
4 0.325284 0.421296 0.0568182 0.133333
4 0.152415 0.405556 0.258807 0.32037
(第一位是class_id,然后是xywh坐标,坐标均经过归一化)
b.coco数据集是一个json格式的文件,由info、images、annotations、categories、licenses五部分组成。
{"info": {
"description": "",
"url": "",
"version": "",
"year": 2023,
"contributor": "JeJe",
"date_created": "2023-05-18"
},
"licenses": [
{
"id": 1,
"name": null,
"url": null
}
],
"categories": [
{
"id": 1,
"name": "pedestrian",
"supercategory": "None"
}
],
"images": [
{
"file_name": "0000001.jpg",
"height": 1080,
"width": 3520,
"date_captured": "2022-07-8",
"id": 1,
"license": 1,
"color_url": "",
"flickr_url": ""
},
"annotations": [
{
"id": 0,
"image_id": 1,
"category_id": 4,
"iscrowd": 0,
"area": 237627.56159999993,
"bbox": [
696.9987199999999,
354.00024,
677.0016,
351.0
],
"segmentation": [
[
696.9987199999999,
354.00024,
1374.0003199999999,
354.00024,
1374.0003199999999,
705.00024,
696.9987199999999,
705.00024
]
]
}
}
生成代码如下:
import os
import json
from PIL import Image
coco_format_save_path= "xxxx" #要生成的标准coco格式标签所在文件夹
yolo_format_classes_path= "xxxx" #类别文件,一行一个类
yolo_format_annotation_path= "xxxx" #yolo格式标签所在文件夹
img_pathDir= "xxxx" #图片所在文件夹
with open(yolo_format_classes_path,'r') as fr: #打开并读取类别文件
lines1=fr.readlines()
# print(lines1)
categories=[] #存储类别的列表
for j,label in enumerate(lines1):
label=label.strip()
categories.append({'id':j+1,'name':label,'supercategory':'None'}) #将类别信息添加到categories中
# print(categories)
write_json_context=dict() #写入.json文件的大字典
write_json_context['info']= {'description': '', 'url': '', 'version': '', 'year': 2023, 'contributor': 'JeJe', 'date_created': '2023-05-18'}
write_json_context['licenses']=[{'id':1,'name':None,'url':None}]
write_json_context['categories']=categories
write_json_context['images']=[]
write_json_context['annotations']=[]
#接下来的代码主要添加'images'和'annotations'的key值
imageFileList=os.listdir(img_pathDir) #遍历该文件夹下的所有文件,并将所有文件名添加到列表中
for i,imageFile in enumerate(imageFileList):
imagePath = os.path.join(img_pathDir,imageFile) #获取图片的绝对路径
image = Image.open(imagePath) #读取图片,然后获取图片的宽和高
W, H = image.size
img_context={} #使用一个字典存储该图片信息
#img_name=os.path.basename(imagePath) #返回path最后的文件名。如果path以/或\结尾,那么就会返回空值
img_context['file_name']=imageFile
img_context['height']=H
img_context['width']=W
img_context['date_captured']='2022-07-8'
img_context['id']=i +1 #该图片的id
img_context['license']=1
img_context['color_url']=''
img_context['flickr_url']=''
write_json_context['images'].append(img_context) #将该图片信息添加到'image'列表中
txtFile=imageFile.replace('.jpg', '.txt') #获取该图片获取的txt文件
with open(os.path.join(yolo_format_annotation_path,txtFile),'r') as fr:
lines=fr.readlines() #读取txt文件的每一行数据,lines2是一个列表,包含了一个图片的所有标注信息
for j,line in enumerate(lines):
bbox_dict = {} #将每一个bounding box信息存储在该字典中
# line = line.strip().split()
# print(line.strip().split(' '))
class_id,x,y,w,h=line.strip().split(' ') #获取每一个标注框的详细信息
class_id,x, y, w, h = int(class_id), float(x), float(y), float(w), float(h) #将字符串类型转为可计算的int和float类型
xmin=(x-w/2)*W #坐标转换
ymin=(y-h/2)*H
xmax=(x+w/2)*W
ymax=(y+h/2)*H
w=w*W
h=h*H
bbox_dict['id']=i*10000+j #bounding box的坐标信息
bbox_dict['image_id']=i+1
bbox_dict['category_id']=class_id+1 #注意目标类别要加一
bbox_dict['iscrowd']=0
height,width=abs(ymax-ymin),abs(xmax-xmin)
bbox_dict['area']=height*width
bbox_dict['bbox']=[xmin,ymin,w,h]
bbox_dict['segmentation']=[[xmin,ymin,xmax,ymin,xmax,ymax,xmin,ymax]]
write_json_context['annotations'].append(bbox_dict) #将每一个由字典存储的bounding box信息添加到'annotations'列表中
name = os.path.join(coco_format_save_path,"instances_val2017"+ '.json')#生成json文件的名字
with open(name,'w') as fw: #将字典信息写入.json文件中
json.dump(write_json_context,fw,indent=2)
2. 需要得到predicition的json文件
a. 首先通过yolov5的detect.py得到测试图片的输出坐标的txt文件,然后对txt文件解析、转换成json格式。
$python detect.py --source 图片地址 --weights 所用权重地址 --save-txt --save-conf
上述指令生成的label文件格式如下:
2 0.347301 0.456481 0.00994318 0.0574074 0.256731
5 0.402983 0.336111 0.00539773 0.037037 0.285816
5 0.466761 0.322685 0.00568182 0.0342593 0.484906
3 0.59446 0.443519 0.0389205 0.0333333 0.52279
4 0.672301 0.414815 0.0446023 0.0722222 0.608851
3 0.490767 0.497685 0.0838068 0.241667 0.959559
(第一位是class_id,然后是xywh坐标,坐标均经过归一化,最后一位是score)
得到每张图片对应的坐标txt文件后,再用下面代码转换:
import json
from pathlib import Path
import os
import numpy as np
import cv2
def save_one_json(predn, jdict, path, h, w):
# Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
image_id = int(path.stem) if path.stem.isnumeric() else path.stem
box = predn[:, 1:5] # xywh
box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
box[:,0], box[:,2] = box[:,0]*w, box[:,2]*w
box[:,1], box[:,3] = box[:,1]*h, box[:,3]*h
for p, b in zip(predn.tolist(), box.tolist()):
jdict.append({
'image_id': image_id,
'category_id': int(p[0])+1,#instance_json的id编号从1开始,这里要一致
'bbox': [round(x, 3) for x in b],
'score': round(p[5], 5)})
pred_json="C:/Users/Administrator/Desktop/val2017.json"
label_path="C:/Users/Administrator/Desktop/exp2/labels/"
img_path="C:/Users/Administrator/Desktop/exp2/images/"
jdict=[]
for file in os.listdir(label_path):
f_name=Path(label_path+file)
labels_array = np.loadtxt(f_name, delimiter=' ')
arr_2d_row = labels_array.reshape(-1, 6)
img=cv2.imread(img_path+file.replace(".txt", ".jpg"))
h, w = img.shape[0], img.shape[1]
save_one_json(arr_2d_row, jdict, f_name, h, w)
with open(pred_json, 'w') as f:
json.dump(jdict, f)
上述代码得到的输出格式如下所示:
[{“image_id”: 1, “category_id”: 5, “bbox”: [1557.998, 413.0, 40.0, 61.0], “score”: 0.27124}, {“image_id”: 1, “category_id”: 4, “bbox”: [1419.0, 418.0, 110.0, 89.0], “score”: 0.34028}, {“image_id”: 1, “category_id”: 4, “bbox”: [2115.998, 441.0, 69.0, 30.0], “score”: 0.402}, {“image_id”: 1, “category_id”: 1, “bbox”: [2789.998, 400.0, 62.0, 167.0], “score”: 0.49453}, {“image_id”: 1, “category_id”: 4, “bbox”: [2190.001, 423.0, 104.0, 53.0], “score”: 0.51853}, {“image_id”: 1, “category_id”: 4, “bbox”: [1393.0, 456.0, 98.0, 56.0], “score”: 0.54418}, {“image_id”: 1, “category_id”: 6, “bbox”: [1596.0, 280.999, 18.0, 46.0], “score”: 0.55061}, {“image_id”: 1, “category_id”: 4, “bbox”: [1346.001, 455.0, 76.0, 62.0], “score”: 0.73075}, {“image_id”: 1, “category_id”: 4, “bbox”: [2300.999, 384.0, 222.0, 93.0], “score”: 0.74564}, {“image_id”: 1, “category_id”: 4, “bbox”: [1678.999, 446.0, 102.0, 90.0], “score”: 0.8657}, {“image_id”: 1, “category_id”: 5, “bbox”: [1421.999, 389.0, 135.0, 110.0], “score”: 0.86812}, {“image_id”: 1, “category_id”: 3, “bbox”: [3183.001, 389.0, 248.0, 204.0], “score”: 0.93293}, {“image_id”: 1, “category_id”: 4, “bbox”: [692.0, 357.999, 685.999, 351.0], “score”: 0.97183}]
(是一个list的格式)
2. 输出coco指标
代码如下:
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
from pathlib import Path
import os
anno_json="xxxxx" #gt的json文件地址
pred_json="xxxxx" #pred的json文件地址
img_path="xxxxx" #对应的图像地址
anno = COCO(anno_json) # init annotations api
pred = anno.loadRes(pred_json) # init predictions api
eval = COCOeval(anno, pred, 'bbox')
eval.params.imgIds = [int(Path(x).stem) for x in os.listdir(img_path)] # image IDs to evaluate
eval.evaluate()
eval.accumulate()
eval.summarize()
map, map50 = eval.stats[:2] # update results (mAP@0.5:0.95, mAP@0.5)
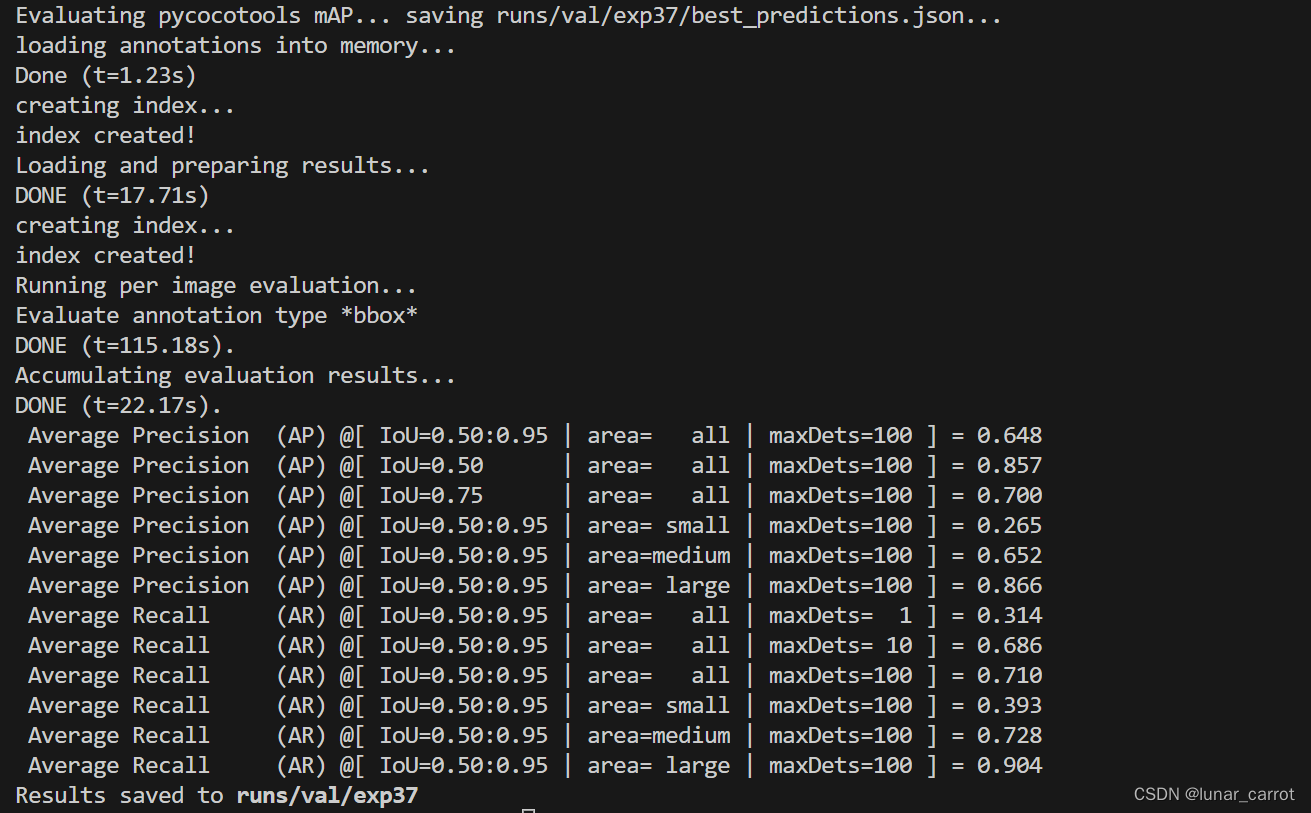
上述代码最后输出的结果如下:
【注】
















 1907
1907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









