







目录
缺失值处理(Missing Data Processing)
数据清洗
错误值处理(Wrong Value Processing)
错误值是指数据集中出现的数值、格式、类型等错误,导致错误的原因包括:
(1)输入错误:录入信息时缺失、错误输入、类型或格式不符等。
(2)设备故障:例如采集设备故障、数据分析工具不够健壮等。
(3)其他原因:因为对数据理解不够导致数据处理失误,比如造成数据重复、错误截断数据等。
错误值需要 结合对业务的理解 以及对多种数据源之间互相对照来发现。要修正错误,需要明确错误产生的原因,这就需要对业务与数据有深入了解,
常用的处理错误值的方法
(1)修正
- 补充正确信息:例如重新导入原始的正确数据。
- 对照其他信息源:例如使用CRM系统中正确的用户年龄替换手工填报的错误年龄。
- 视为空值:将数据清空,等待下一步处理。
(2)删除
- 删除记录。
- 删除特征。
如果通过删除来处理错误值,那么要保证该处理不会对后续工作造成重要影响,删除的记录过多会影响数据的分布,删除的特征也不能是那些重要的字段。
以下是一个通过业务规则发现错误值的例子。
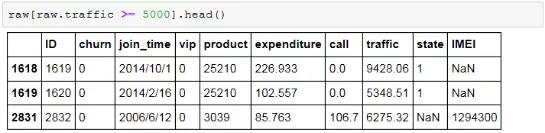
- 对于连续变量
在用户消费的流量“traffic”字段中,有一些是超过5000MB的,而根据业务规则,电信运营商限制了单用户每月消费的流量不得超过5000MB(有些套餐设置不得超过15GB),设置这个规则是为了避免用户在不知情的情况下消耗过多流量而引起投诉。这项规则一般可以通过联系服务商而关闭,而一些用于内部测试的号码则没有这项规则的限制。如果筛选出来的数据经确认是错误的,或者是测试号所为,则可以删除它们,因为分析的目标不应当包含测试号这类特殊用户。因此,删除(或筛选)处理方式如下。

新的数据集“data”将不包含流量消费大于5000MB的用户。
- 对于离散变量
可以采用一定的技术手段去识别错误值,因为错误值通常极少出现,因此可以通过对比分类变量各分类水平之间的数量差异去识别。比如对用户状态“state”进行汇总,代码如下。(用value_counts()更方便)
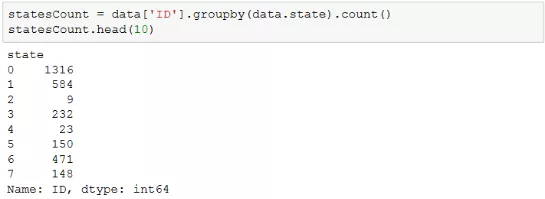
通过汇总,发现用户状态为“2”和“4”的记录非常少,则这两类数据很有可能是错误的。为了更直观地展现数量差异,可以使用饼图来描述数据:
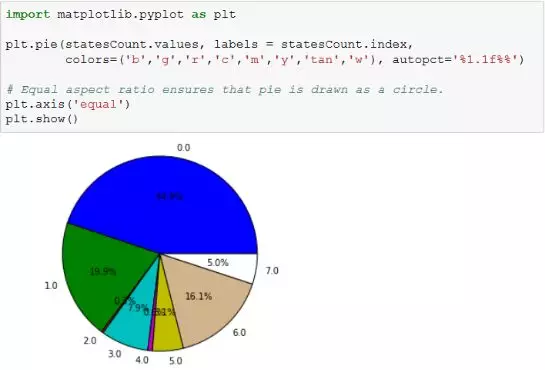
通过图形可以非常容易发现“2”与“4”这两种状态的用户很少
如果对照业务规则,发现这两种状态是不应当出现:
一种可选的方式是删除这些记录。
一种可选的方式是先把这两种状态清空,后期再用合适的方法填补,代码如下。

如果根据业务规则,实际上这两种状态是确实存在的,而且是较少出现的:
实际建模中,我们往往难以区分分类变量中的某些很少的编码到底是这个对应的业务发生地少,还是填报错误,因此对都作为错误进行处理。
去除这类出现较少的分类有两方面考虑:
1)属于这一类的客户太少,单独分类意义不大;
2)数量极少的组在抽样时会出现抽样分布不均匀现象,造成模型无法使用。上例中分组为“2”的客户只有9个,有可能这9个样本在建模时都被随机抽样的到测试数据集,而在训练数据集中没有出现。我们知道分类变量在构建模型时要使用哑编码,因此训练的模型中没有“2”对应的编码,而在打分时,测试数据集有这个编码,因此模型出现报错。
异常值处理(Outlier Processing)
异常值是指那些远远偏离多数样本的数据点。商业数据挖掘中,一般多数样本聚集在中心附近,而少数记录偏离它们,形态上接近正态分布或对数正态分布(对连续变量而言),我们仅讨论这种情况。
根据数据偏离程度的不同,可将异常值分为极端值与离群值(其中极端值偏离得更远一些)。
从单变量的角度看,识别异常值可以采用平均值法、四分位数法等方法;
从多变量角度看,可以使用聚类来识别异常值(某些记录可以在单个变量分布上并无异常),聚类方法会在其他章节进行介绍。
异常值有时意味着错误,有时不是。无论是否代表错误,异常值都应当被处理。通常可以根据对业务的理解来设置异常值的边界,也可以使用一定的技术手段辅助识别异常值。
常用的识别方法包括以下两种。
(1)平均值法:对于正态分布来说,三倍标准差之外的样本仅占所有样本的1%,因此,设置平均值±3×标准差之外的数据为离群值,极端值被定义为平均值±5×标准差之外数据。
(2)四分位数法:设置1.5倍四分位距以外的数据为异常值,即IQR = Q3–Q1,IQR为四分位距,Q3和Q1分别为第三和第一四分位点,定义正常数据在Q1–1.5 ´ IQR ~ Q3 + 1.5 ´ IQR 之间。
例如:绘制月消费额箱线图。
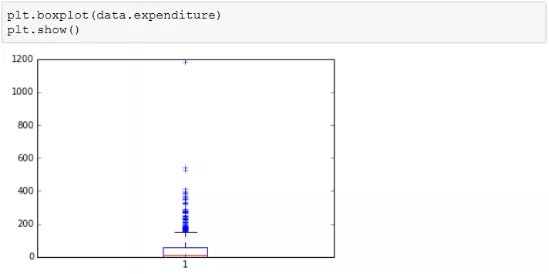
其中上面单独的横线位置代表离开第三个四分位点1.5倍四分位距的数据,超出以外的数据就是异常值。
异常值的处理方法
(1)视为空值:待后期对空值进行处理,如果后期的处理策略是对空值进行填补,则视填补方式的不同会不同程度地改变原有数据的分布。
(2)盖帽法:异常值被重新设定为数据的边界,这种方法同样会改变原有数据的分布,但由于异常值往往是少数,因此可以采用。
(3)变量转换:通过一定的变换改变原有数据的分布,使得异常值不再“异常”,常用的转换是对数变换,这对那些严重右偏的数据非常有用,变换后的数据能够更接近正态分布,如图15-3所示。
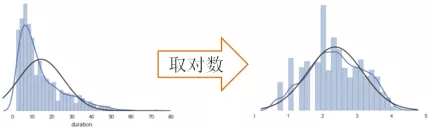
图17-3
(4)考虑分段建模或离散化:分段建模是将那些偏离中心的样本单独进行分段建模,其隐含的商业逻辑为离群点的内在规律与多数不同,例如收入很高的人群,其行为与普通人群必然不同,其行为所反映的内在规律必然也有较大的差异,应当单独进行分析;离散化是通过设置分割点将连续型变量转换为离散型,例如将年龄这一字段离散化,可以通过设置分割点划分为儿童、少年、青年、中年、老年,这样年龄很大的人会被作为单独一类进行分析。值得一提的是,连续型变量往往是模型不稳定的原因,离散化之后通常能提高模型的泛化能力。
使用盖帽法进行异常值处理的示例如下。
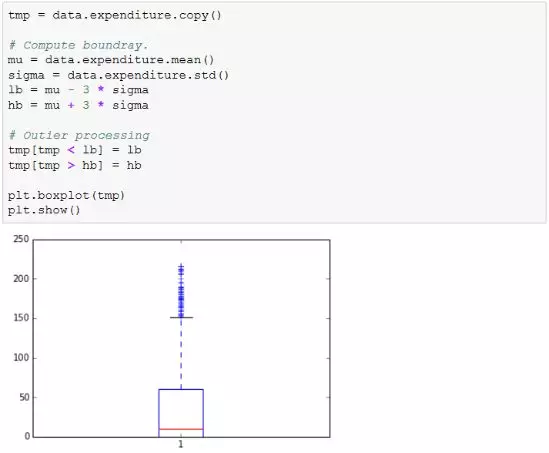
通过将离开中心点三倍标准差之外的数据重新赋值,用户月消费额被限制在了250元以内,尽管新数据使用四分位法或平均值法分析后,又可能出现了“异常值”,但一般不会再次处理。
使用变量转换进行异常值处理的示例如下。
对于月消费额这样的数据绘制直方图,可以发现其明显右偏,代码如下。
![]()
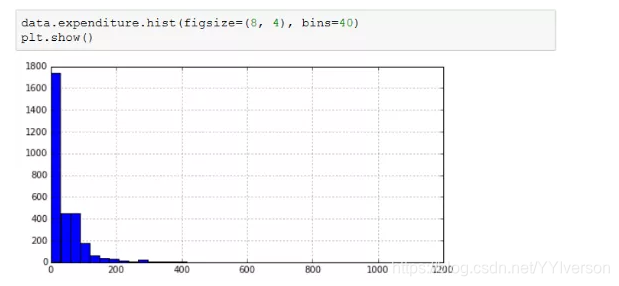
这类数据也可以通过对数转换使其更接近于正态分布,同时消除异常值,由于对数函数的定义域为(0,+∞),而消费额这样的数据往往包括0,因此可以对数据进行加1操作,再进行对数转换,这样的转换可以保证原来为0的数据转换后依然为0,新数据都是非负的,示例代码如下。
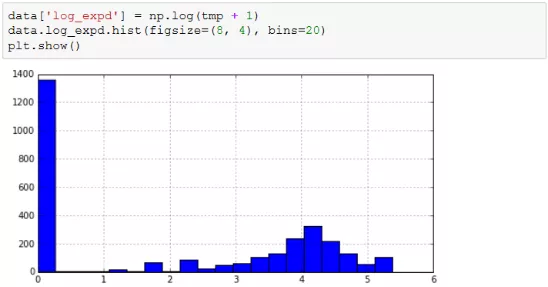
上述代码中使用了np.log函数,传入的参数正是原始数据+1后的结果。numpy中定义了一个函数log1p可以产生同样的效果。
除了使用对数函数直接转换数据之外,scikit-learn提供了preprocessing这样的预处理模块,可以利用其中定义的函数转换器达到同样的效果,示例如下:
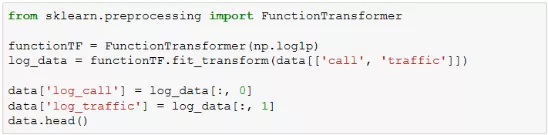
可以看到使用scikit-learn中的函数转换可以一次性对多个字段进行处理。
对数转换后发现存在大量的0值,这些0消费额的账单比较特殊,因此完全可以单独提取出来进行分析。同时,去掉了0值的数据更加接近正态分布,因此对于后续的分析工作更加有利。
缺失值处理(Missing Data Processing)
缺失值在页面上显示为NaN,意味着Not a Number,等价于numpy当中的空值NaN。缺失值的出现是非常普遍的,在pandas当中,对DataFrame进行count计数,不会统计其中的缺失值,因此可以使用该方法来判别哪些字段上有缺失值以及缺失的数量(除非所有字段都有缺失值,这种情况不多见,一般ID识别号是不会有缺失的),如下所示:

为了更加准确的判断缺失值的数量,可以使用isnull函数,如果数值为空返回True,否则为False,再进行求和(True被作为1,False被作为0),就可以统计每个字段缺失值的数量。同样可以使用notnull函数进行类似分析,其返回结果与isnull相反。示例如下:(也可以pd.isnull(df).sum())
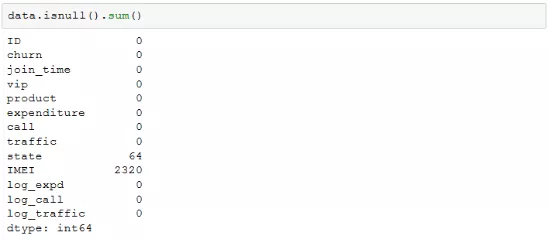
缺失值的数量会影响缺失值处理的策略,同时,缺失值的处理需要根据字段代表的业务内涵来进行,常用的方法包括:
- 通过对比其他数据源填补空值;
- 连续型字段
- 缺失不多:填补中位数或均值;
- 缺失较多,生成一个新字段用于标示哪些记录是被填补的(比如用1表示缺失记录,用0表示非空记录),原字段不再使用;
- 离散型字段
- 对缺失不多(比如少于20%)的离散型字段填补众数或填补为“未知”这样的新分类;
- 对缺失较多(比如多于20%并且少于50%)的离散型字段填补为“未知”这样的新分类,同时生成一个新的字段用于标示哪些记录是被填补的(比如用1表示填补的记录,用0表示之前非空的记录);
- 对缺失很多(比如多于50%并且少于80%)的离散型变量,直接使用新字段标示哪些记录存在缺失,原字段不再使用;
- 对缺失非常多(比如多于80%)的字段(包括离散型与连续型)直接删除;
- 通过建模从其他字段“预测”目标字段的缺失值应当为多少。
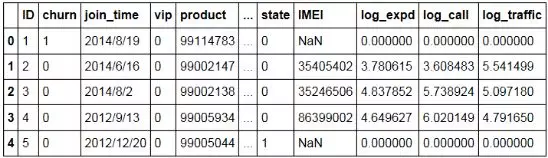
由于业务的多样性,上述方法只是一个参考,以下是一个填补缺失值的例子(见下图):

缺失值的处理可以非常灵活,比如对“营销次数”的填补可以使用众数填补,也可以填为0(如果缺失是因为在营销数据库中没有该记录造成的则填0)。此外,营销活动通常是对满足一定条件的用户开展的,因此也可以通过建模“预测”该用户“被营销”的次数。
以下是对之前的data数据集按照缺失值数量进行记录删除的一个例子。
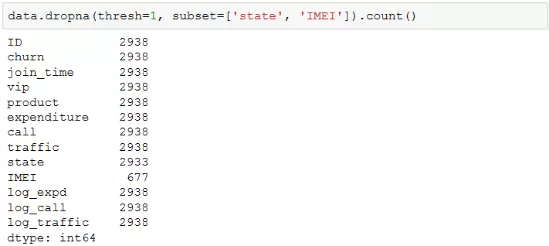
上例使用了dropna方法,对"state"和"IMEI"这两个字段,如果缺失值超过1个(即参数thresh),则删除该条记录,即删除这两个字段都缺失的记录,因此新数据集的记录数减少了。当然了,因为数据集共有10个字段,仅仅两个字段缺失就删除有点过于冒失,因此,这个例子仅为演示代码所用,无需实际保留该结果。
除了按条件删除记录,pandas也提供了对缺失值进行填补的方法fillna,一个使用该方法填补缺失值的例子如下:
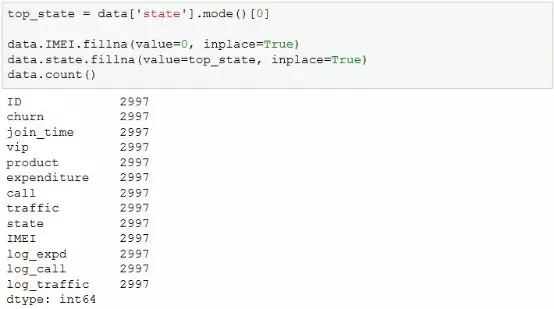
在上例中,使用0来填补手机串码"IMEI"的缺失值,用账户状态"state"的众数来填补自身的缺失值,其中mode方法用于求众数,由于众数可以有多个,因此该方法会返回一个数组,包含所有众数,使用索引取得第一个众数用于填补。fillna中的参数inplace用于指定是否直接替换原缺失值,如果设置为True,会对数据就地进行修改,否则会生成一个填补后的新dataframe对象。
在scikit-learn的preprocessing模块中,也提供了用于缺失值填补的类Imputer,其使用方法如下所示:
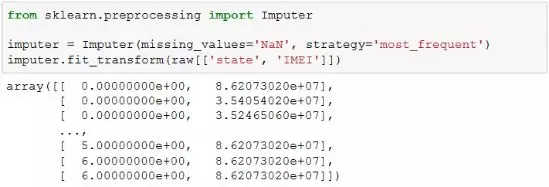
这种方法可以指定用于表示缺失的值,strategy参数则指定了填补策略,比如示例中使用的众数,其它策略包括均值、中位数等,具体可参考帮助或文档。

















 1987
1987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









