







详细视频:XTuner 微调 LLM:1.8B、多模态、Agent
详细文档:XTuner 微调个人小助手认知
进阶作业一所需文档:OpenXLab 部署教程
进阶作业二所需文档:XTuner多模态训练与测试
一、基础作业
1.1、训练自己的小助手认知
1.1.1、环境安装
首先我们需要先安装一个 XTuner 的源码到本地来方便后续的使用。
# 如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 的环境:
# pytorch 2.0.1 py3.10_cuda11.7_cudnn8.5.0_0
studio-conda xtuner0.1.17
# 如果你是在其他平台:
# conda create --name xtuner0.1.17 python=3.10 -y
# 激活环境
conda activate xtuner0.1.17
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
mkdir -p /root/xtuner0117 && cd /root/xtuner0117
# 拉取 0.1.17 的版本源码
git clone -b v0.1.17 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.15 https://gitee.com/Internlm/xtuner
# 进入源码目录
cd /root/xtuner0117/xtuner
# 从源码安装 XTuner
pip install -e '.[all]'
1.1.2、数据集准备
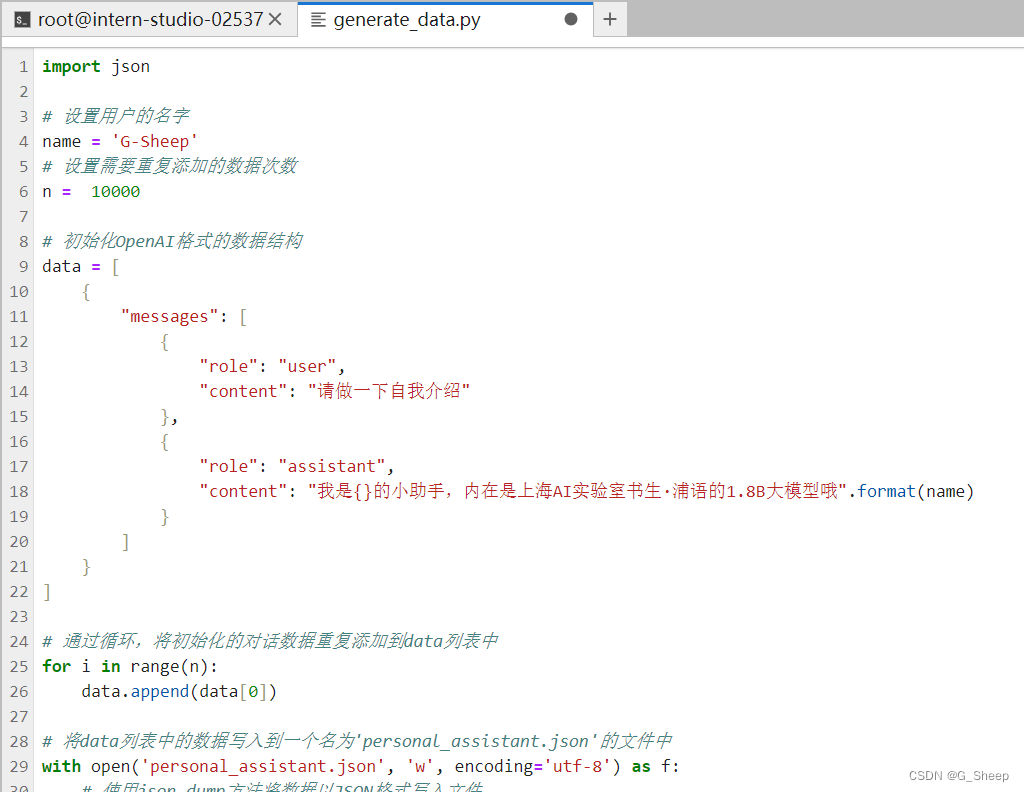
因为是要训练成我们自己的小助手,所以需要生成一个数据集,让小助手认识到自己的弟位。
我们可以在 data 目录下新建一个 generate_data.py 文件,将以下代码复制进去,然后运行该脚本即可生成数据集。假如想要加大剂量让他能够完完全全认识到你的身份,那我们可以把 n 的值调大一点。
运行该文件,左边的文件结构会变成这样:

1.1.3、模型准备
在准备好了数据集后,接下来我们就需要准备好我们的要用于微调的模型。
常规方式可以通过以下方式下载模型:
# 创建目标文件夹,确保它存在。
# -p选项意味着如果上级目录不存在也会一并创建,且如果目标文件夹已存在则不会报错。
mkdir -p /root/ft/model
# 复制内容到目标文件夹。-r选项表示递归复制整个文件夹。
cp -r /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/* /root/ft/model/
但为了节省内存,也可以通过软链接的方式链接到模型文件,同时方便管理。
# 删除/root/ft/model目录
rm -rf /root/ft/model
# 创建符号链接
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/ft/model
运行命令以后,文件结构如下图所示:
1.1.4、配置文件选择
在准备好了模型和数据集后,我们就要根据我们选择的微调方法方法结合前面的信息来找到与我们最匹配的配置文件了,从而减少我们对配置文件的修改量。
所谓配置文件(config),其实是一种用于定义和控制模型训练和测试过程中各个方面的参数和设置的工具。准备好的配置文件只要运行起来就代表着模型就开始训练或者微调了。
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
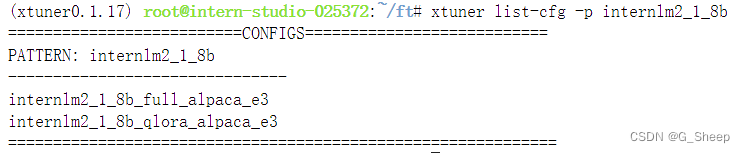
虽然我们用的数据集并不是 alpaca 而是我们自己通过脚本制作的小助手数据集 ,但是由于我们是通过 QLoRA 的方式对 internlm2-chat-1.8b 进行微调。而最相近的配置文件应该就是 internlm2_1_8b_qlora_alpaca_e3 ,因此我们可以选择拷贝这个配置文件到当前目录:

运行结果如下:
1.1.5、常规训练
从 terminal 的输出看,训练之前,是这样的:
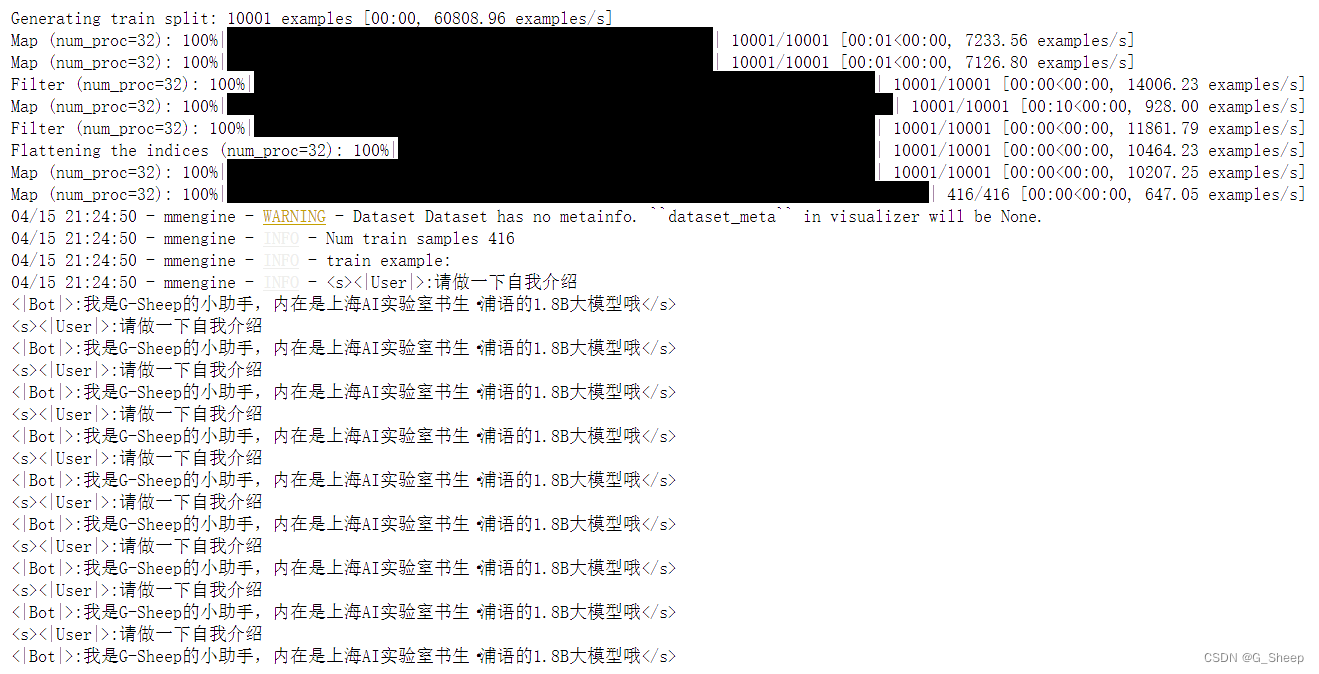
中间训练 300 轮的结果:
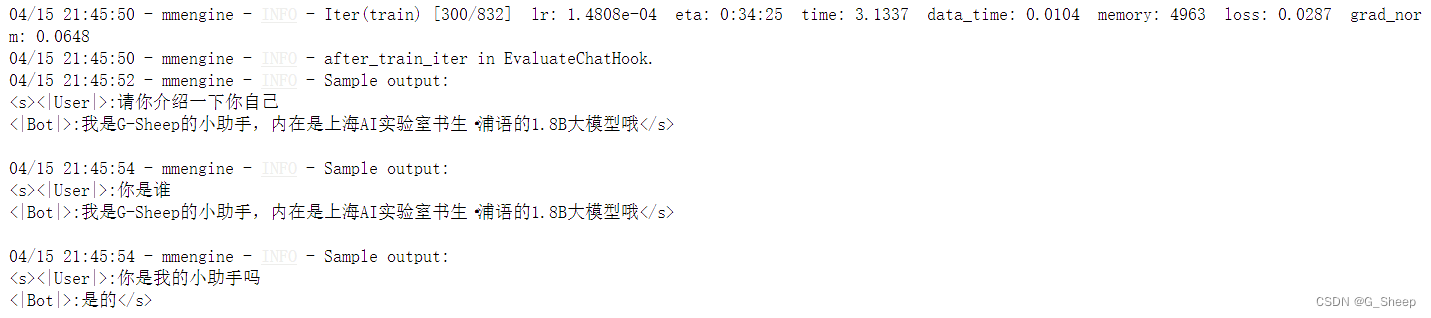
可以看到,在 300 轮 结束后,模型的训练效果已经很不错了,对于给出的问题都能有精准的回答。
中间训练 600 轮的结果:

在 600 轮结束后,可以看到,模型已经出现轻微了过拟合的情况,我们需要的回答最多就是 “是的,我是G-Sheep的小助手” ,不需要后面那句了。
训练结束以后的结果:

1.1.6、加速训练
我们也可以结合 XTuner 内置的 deepspeed 来加速整体的训练过程,共有三种不同的 deepspeed 类型可进行选择,分别是 deepspeed_zero1, deepspeed_zero2 和 deepspeed_zero3。
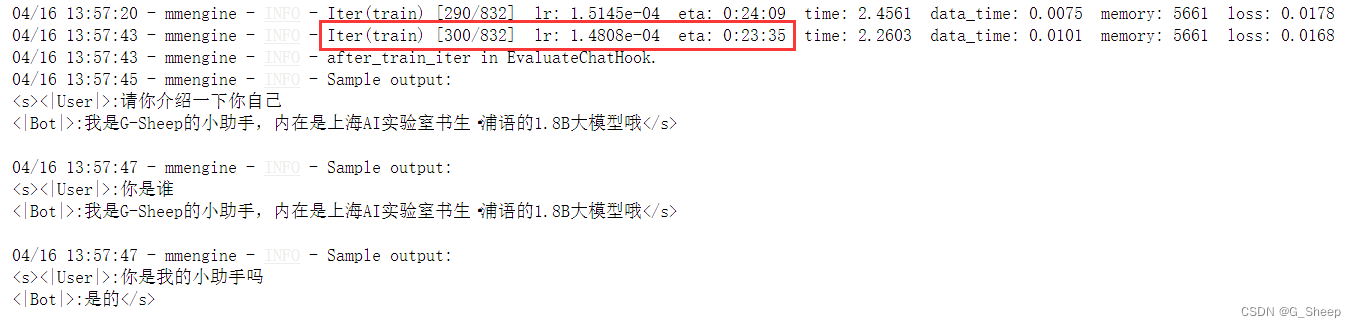
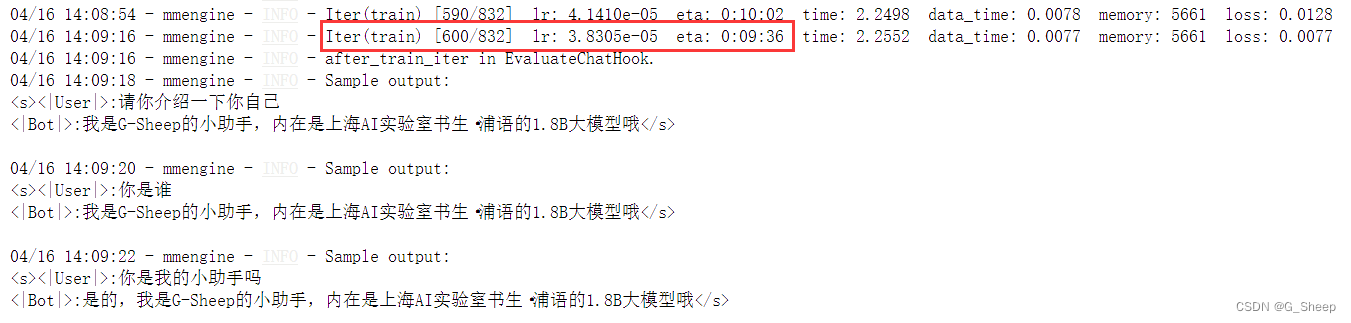
从中间训练结果可以看到,使用 deepspeed 加速训练以后,训练时间确实缩短了(根据实际运行情况来看,缩短的时间比显示的要更多)。
通过 deepspeed 来训练后得到的权重文件和原本的权重文件是有所差别的,原本的仅仅是一个 .pth 的文件,而使用了 deepspeed 则是一个名字带有 .pth 的文件夹,在该文件夹里保存了两个 .pt 文件。当然这两者在具体的使用上并没有太大的差别,都是可以进行转化并整合。
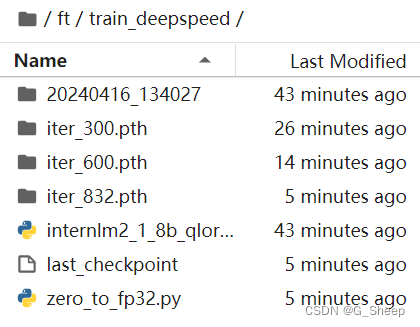
1.1.7、模型转换
模型转换的本质其实就是将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 Huggingface 格式文件,那么我们可以通过以下指令来实现一键转换。
# 创建一个保存转换后 Huggingface 格式的文件夹
mkdir -p /root/ft/huggingface
# 模型转换
# xtuner convert pth_to_hf ${配置文件地址} ${权重文件地址} ${转换后模型保存地址}
xtuner convert pth_to_hf /root/ft/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train/iter_768.pth /root/ft/huggingface
1.1.8、模型结合
对于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(adapter)。那么训练完的这个层最终还是要与原模型进行组合才能被正常的使用。
而对于全量微调的模型(full)其实是不需要进行整合这一步的,因为全量微调修改的是原模型的权重而非微调一个新的 adapter ,因此是不需要进行模型整合的。

运行结果如下:
1.1.9、对话测试
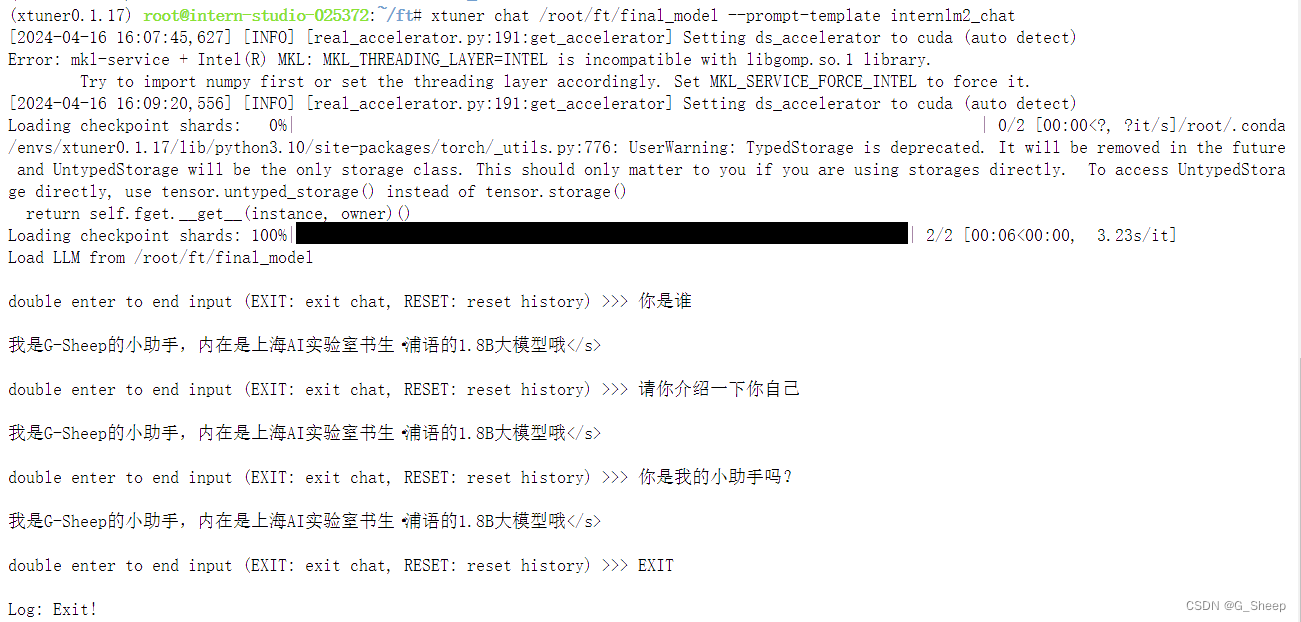
可以看到,已经是过拟合了,只会 “我是G-Sheep的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦” 这句话。我们下面可以通过对比原模型的能力来看看差异。

可以看到在没有进行我们数据的微调前,原模型是能够输出有逻辑的回复,并且也不会认为他是我们特有的小助手。因此我们可以很明显的看出两者之间的差异性。
除此之外,因为在刚刚训练的过程中,我们可以看到,模型在 300 轮结束的时候,它的回答是比较符合我们的期待的,所以我对这个阶段的模型也单独转换并且整合模型。
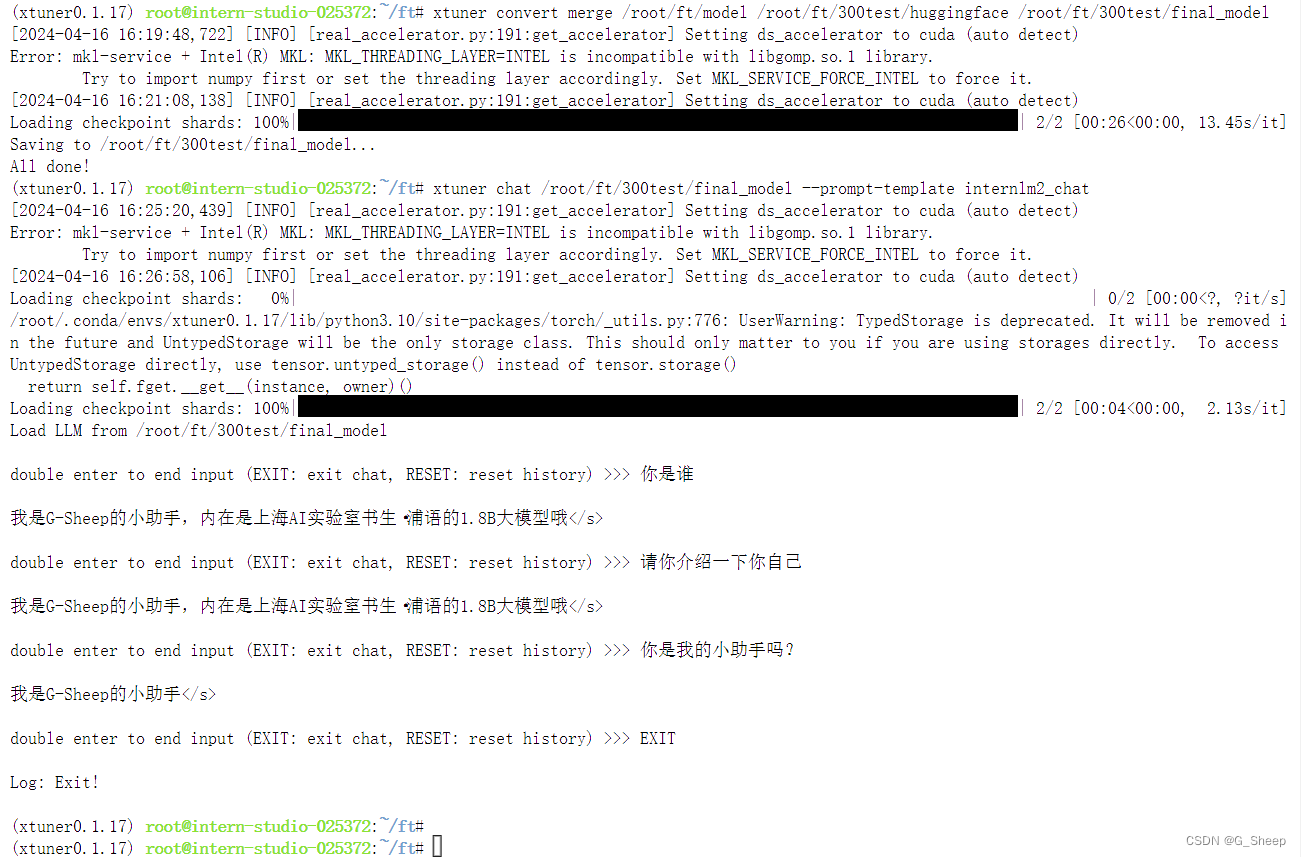
可以看到,回答比起完全训练结束的模型还是好不少的。
但值得注意的是,对于 “你是我的小助手吗?” 这个问题,无论是完整训练,还是只训练 300 轮,助手的回答都和仅有这个模型的时候是不一样的,那我们这边是否可以理解为,仅对于这个问题,整合模型反而削弱了训练结果?
1.1.10、 Web demo 部署
除了在终端中对模型进行测试,我们其实还可以在网页端的 demo 进行对话。
pip install streamlit==1.24.0
# 创建存放 InternLM 文件的代码
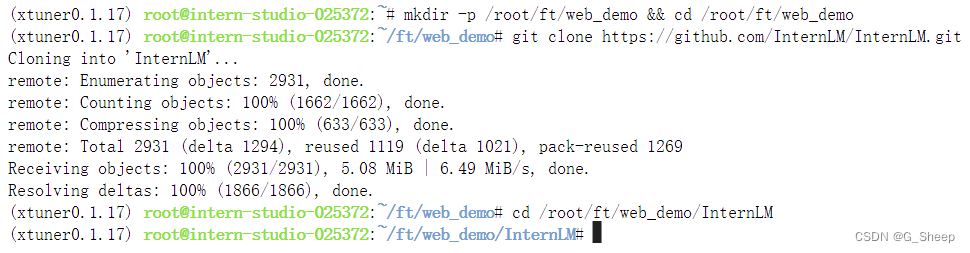
mkdir -p /root/ft/web_demo && cd /root/ft/web_demo
# 拉取 InternLM 源文件
git clone https://github.com/InternLM/InternLM.git
# 进入该库中
cd /root/ft/web_demo/InternLM
将 /root/ft/web_demo/InternLM/chat/web_demo.py 中的内容作一定替换,主要修改模型路径和分词器路径,并进行端口映射以后,就可以在网页端打开模型对话了:
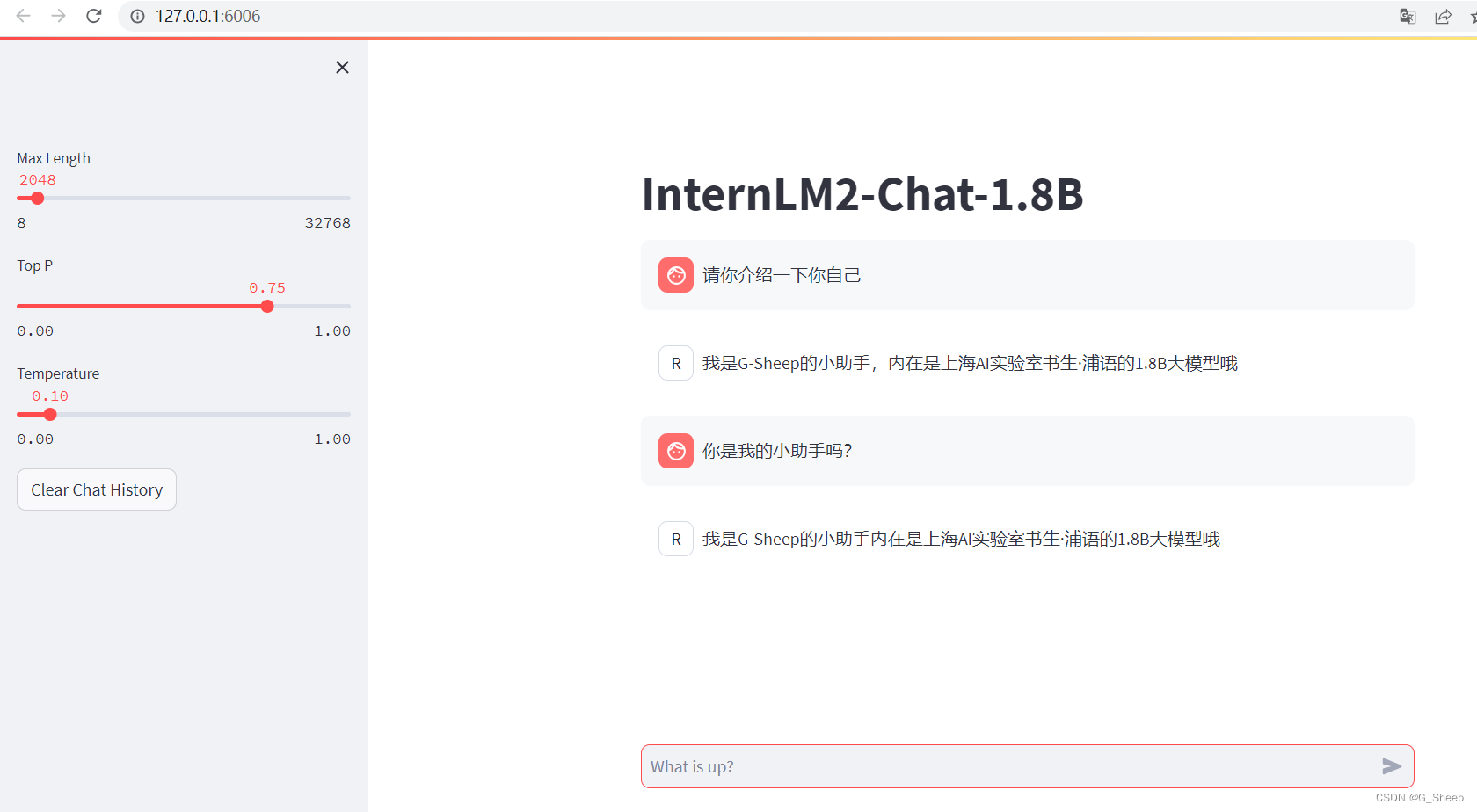
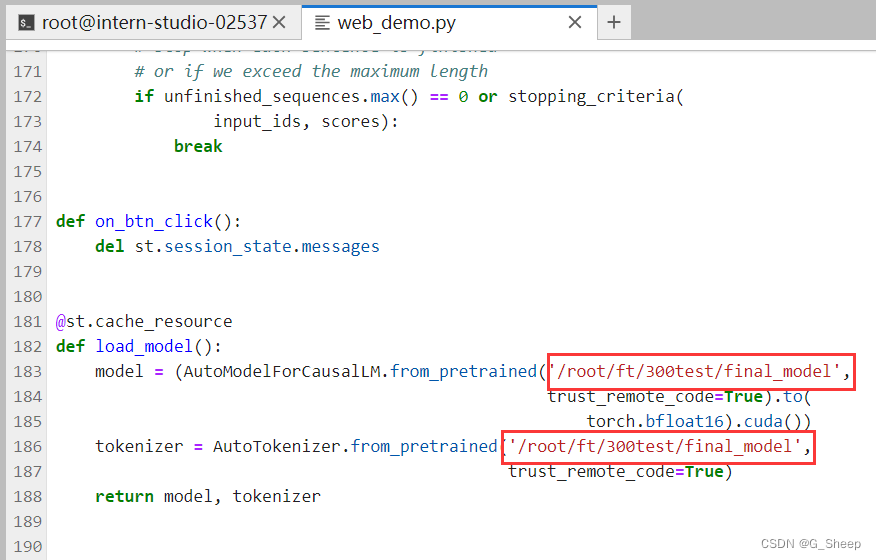
我们还可以和原来的 InternLM2-Chat-1.8B 模型对话(即在 /root/ft/model 这里的模型对话),我们其实只需要修改183行和186行的文件地址即可。
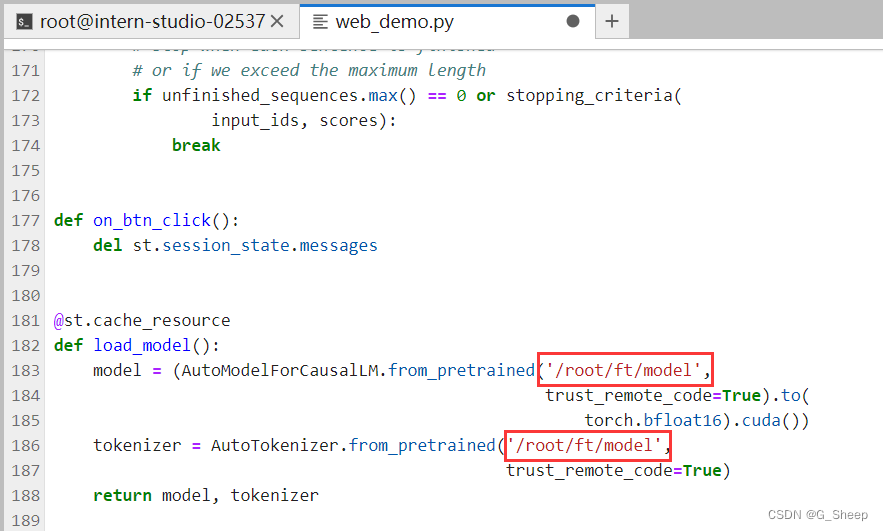
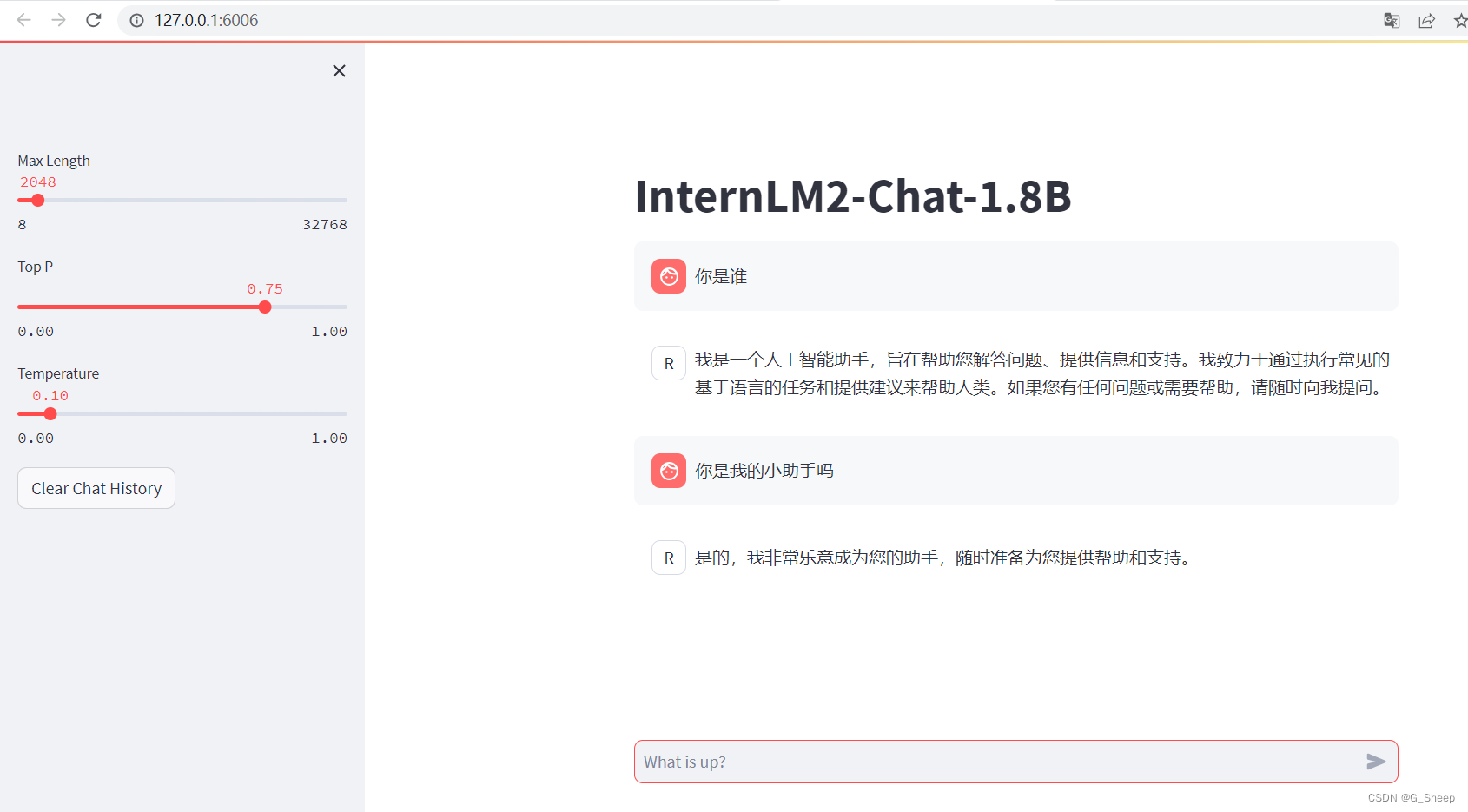
可以看到,两边模型的结果还是有很大区别的。
最后,上面因为我也自己整合了一个训练 300 轮的模型,这边也使用 web 页面打开测试:
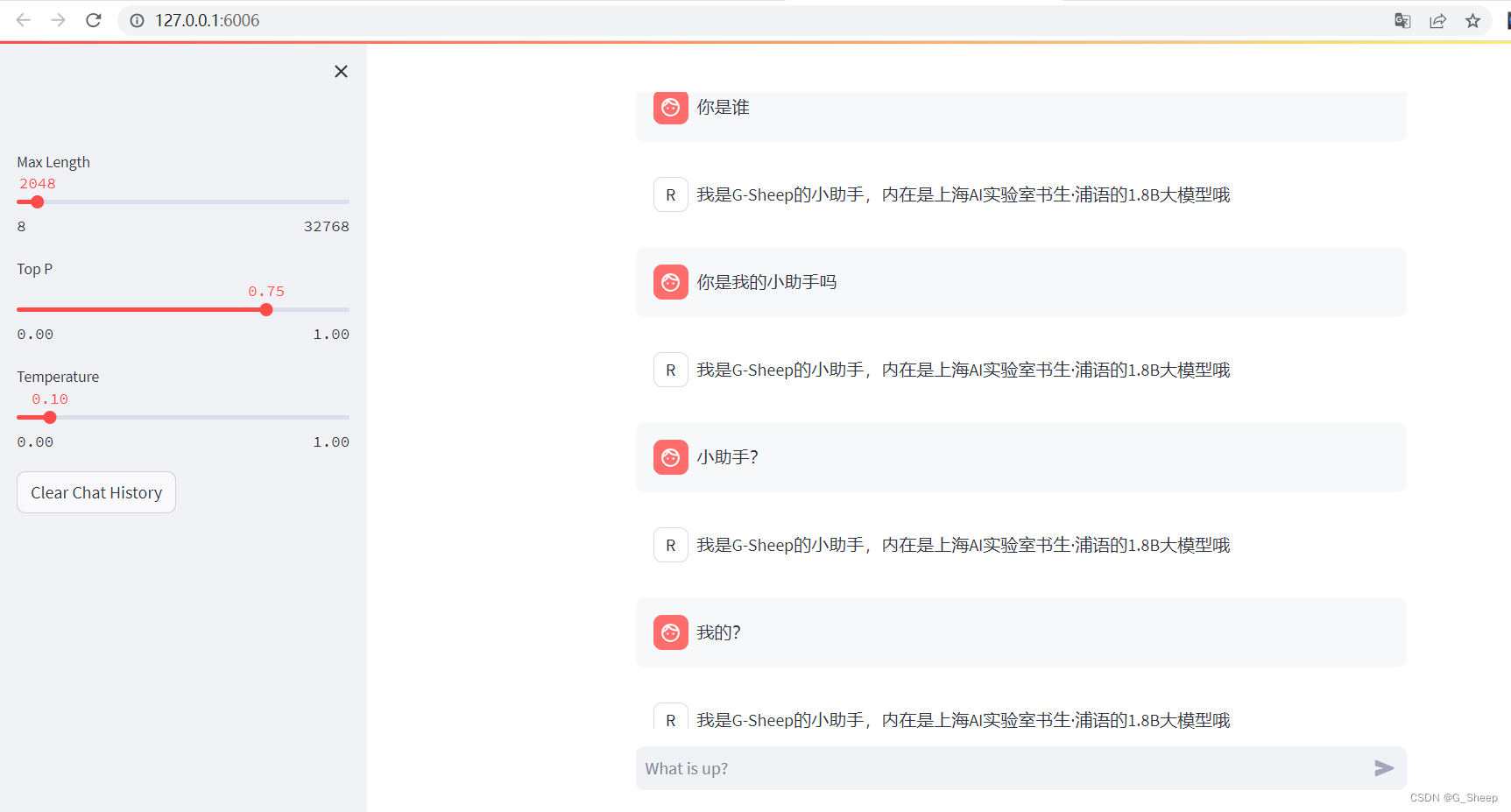
不理解,非常不理解,按道理来说只是从终端输出变换成了网页输出,不会影响原本输出结果的,可从结果来看,并不是这样,已经训练好的模型出现了和过拟合一样的情况,甚至当我问 “小助手?” 甚至是 “我的?” 这样的问题的时候,还是蹦出了 “我是G-Sheep的小助手,内在是上海AI实验室书生·浦语的1.8B大模型哦” 这样的回答,过拟合,严重过拟合!
二、进阶作业
2.1、将自我认知的模型上传到 OpenXLab,并将应用部署到 OpenXLab
具体教程可以查看文档:OpenXLab 部署教程,这边只列举中间的一些运行结果:
2.1.1、 克隆空仓库:

2.1.2、使用 git lfs track 标记文件

2.1.3、提交更新的信息

- git pull 时需要填写用户名和密码

- git push 结束
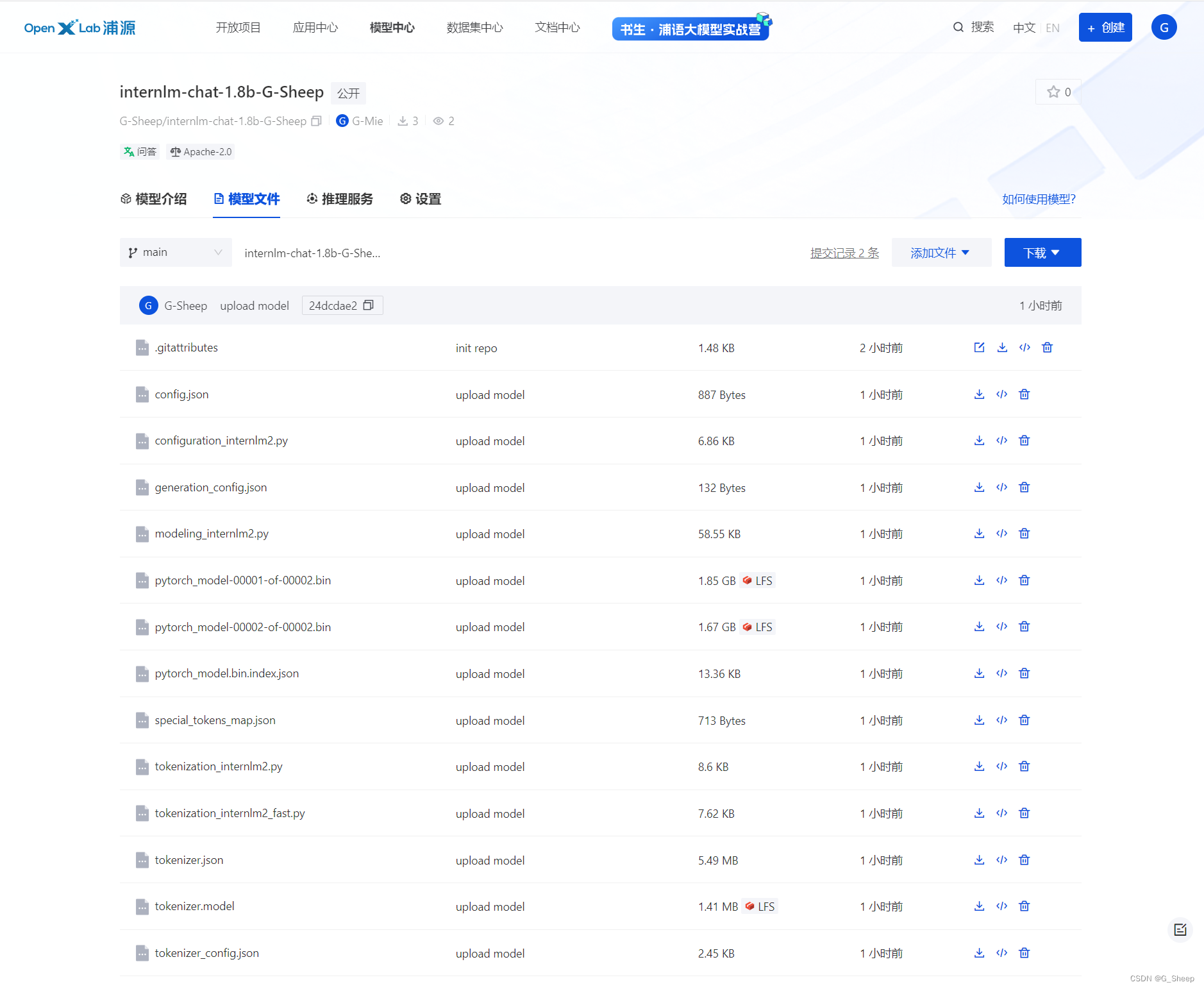
- 上传以后的模型仓库
2.1.4、在 Github 创建仓库配置基本文件
2.1.5、应用构建
2.2、复现多模态微调
具体教程请看:XTuner多模态训练与测试
2.2.1、准备问答对数据
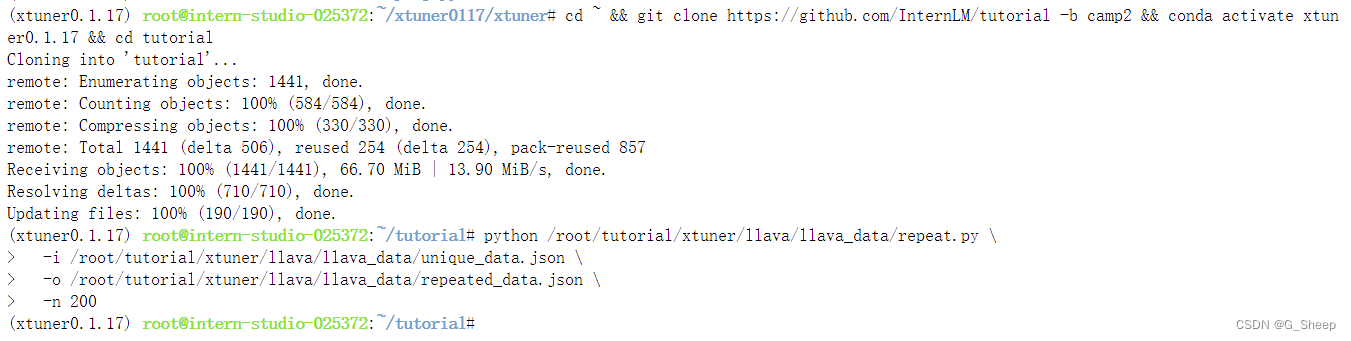
2.2.2、创建配置文件
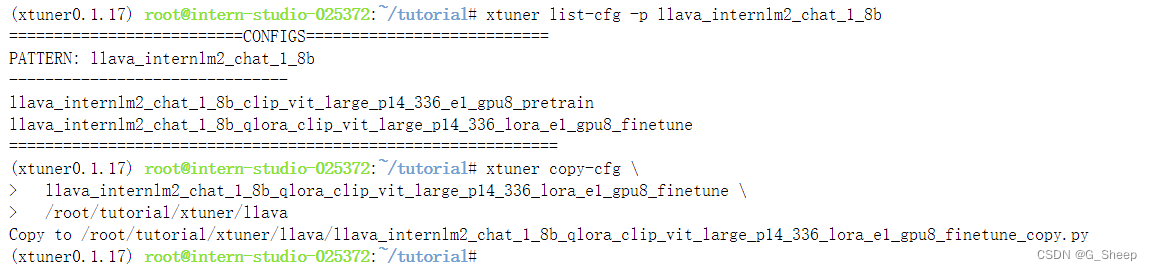
此时目录结构是这样的:

2.2.3、修改配置文件
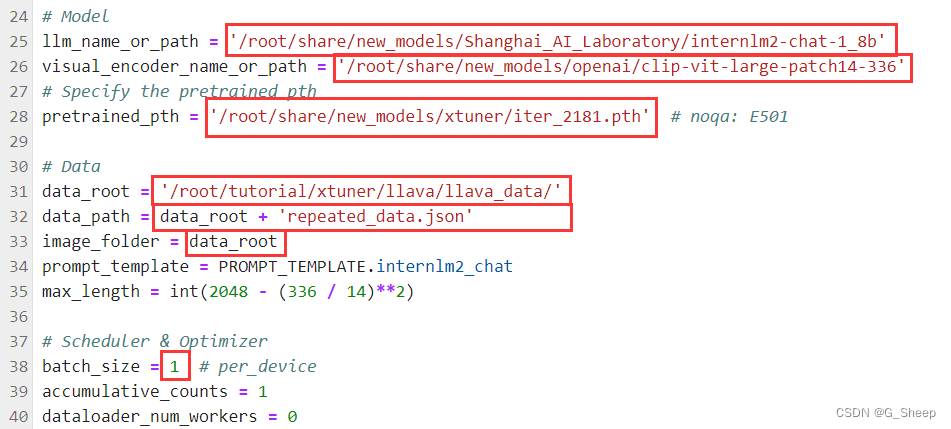
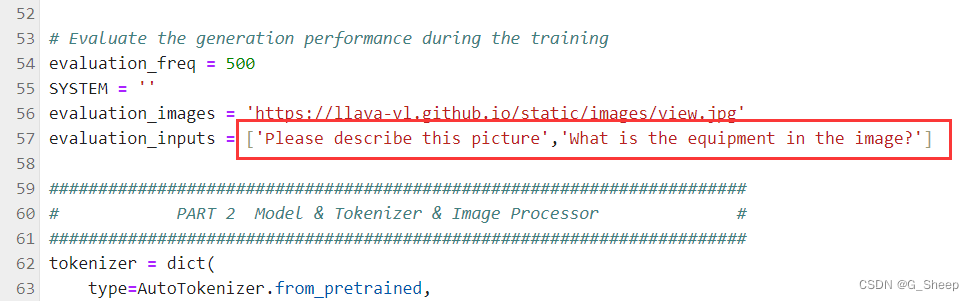
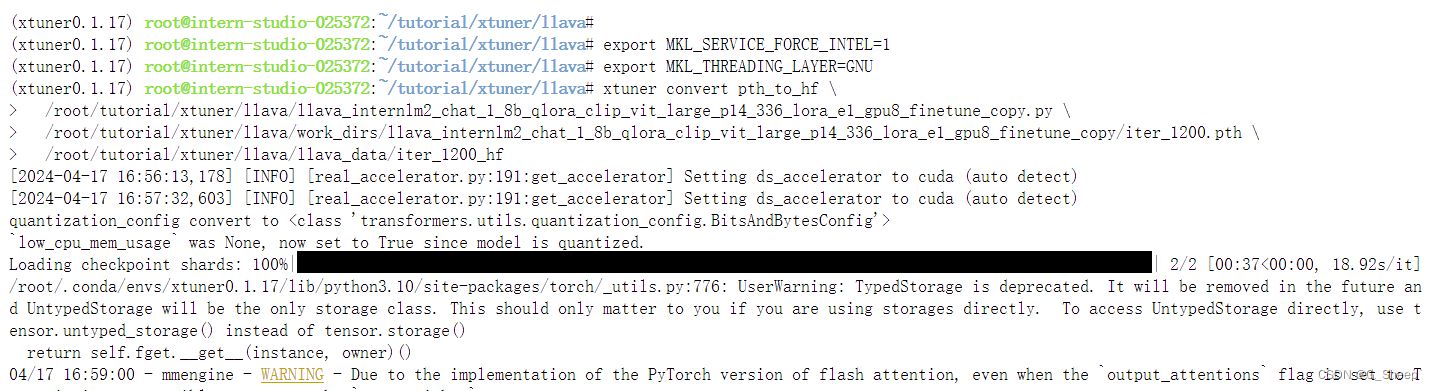
2.2.4、Finetune
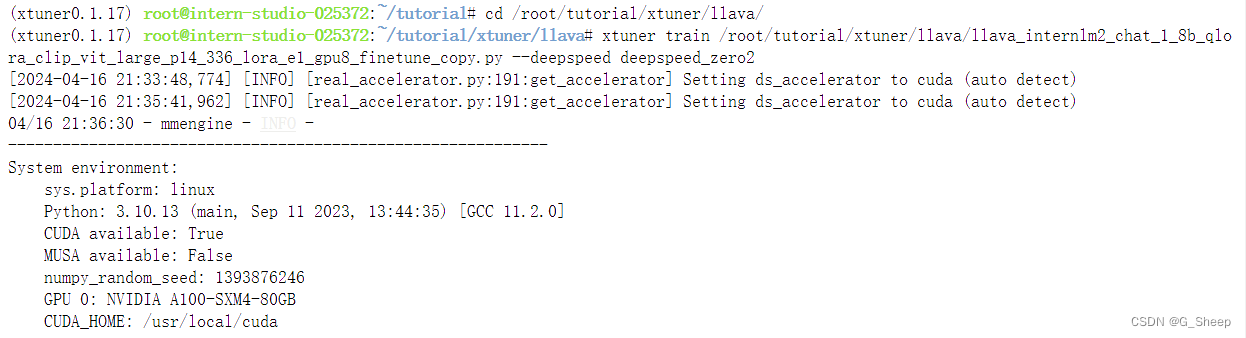
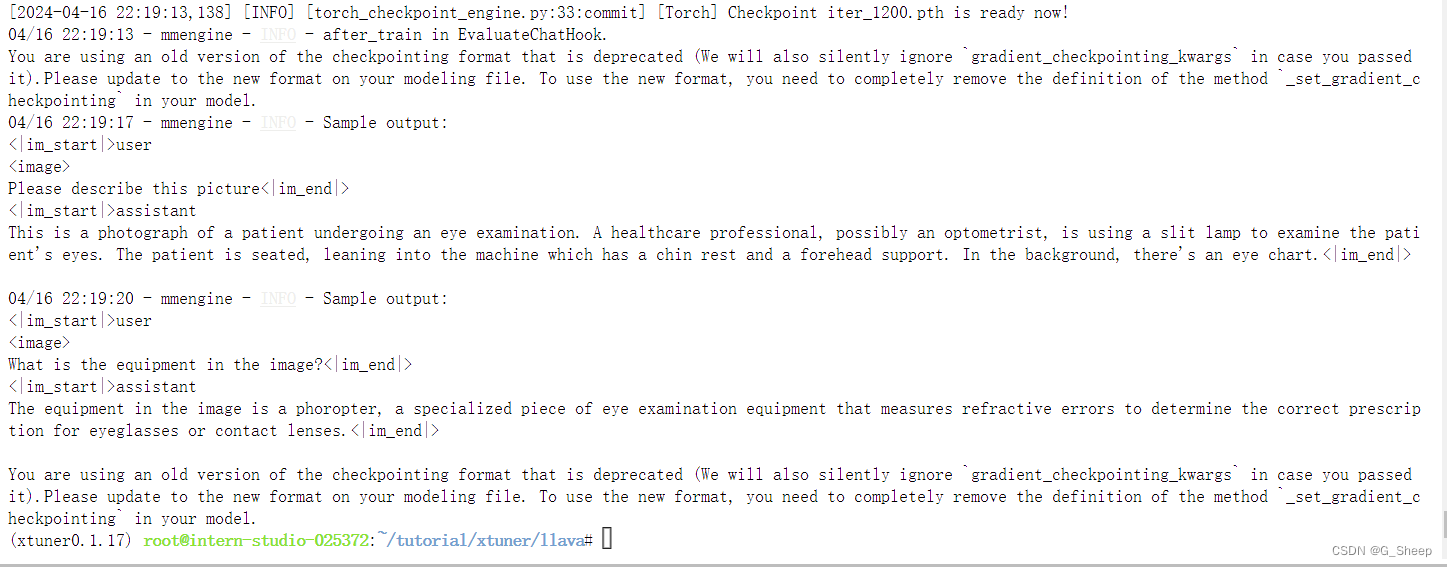
2.2.5、对比结果
- Finetune 前结果
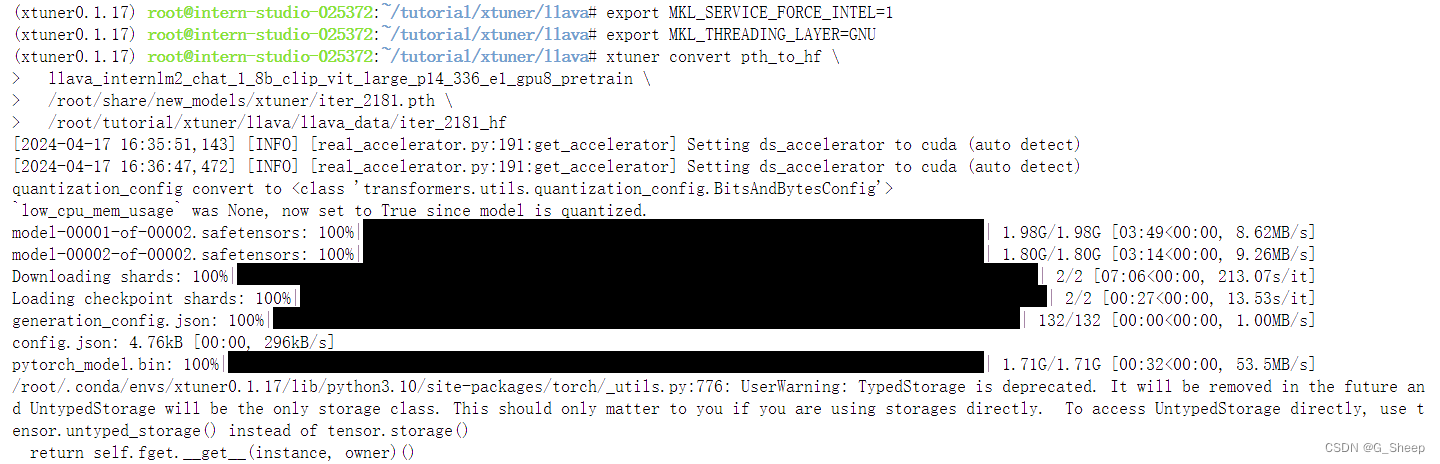

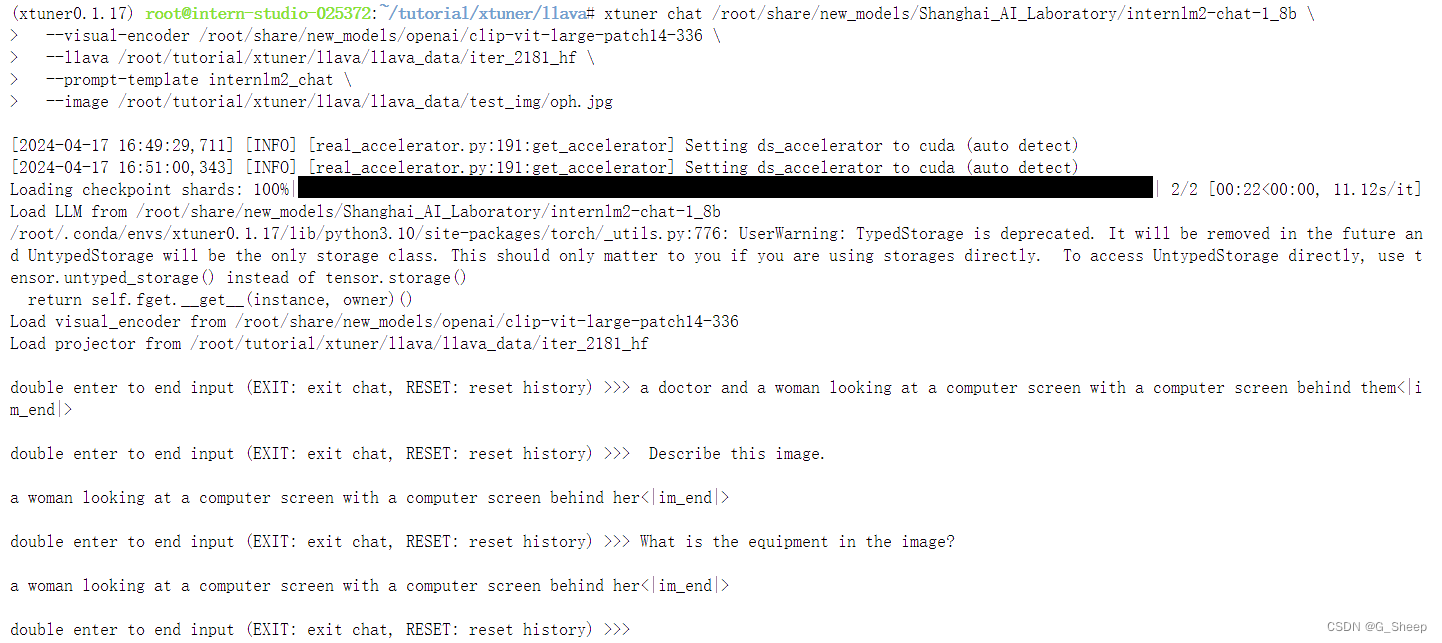
可以看到,无论问什么问题,模型都只会回答图片的标题。
- Finetune 后结果

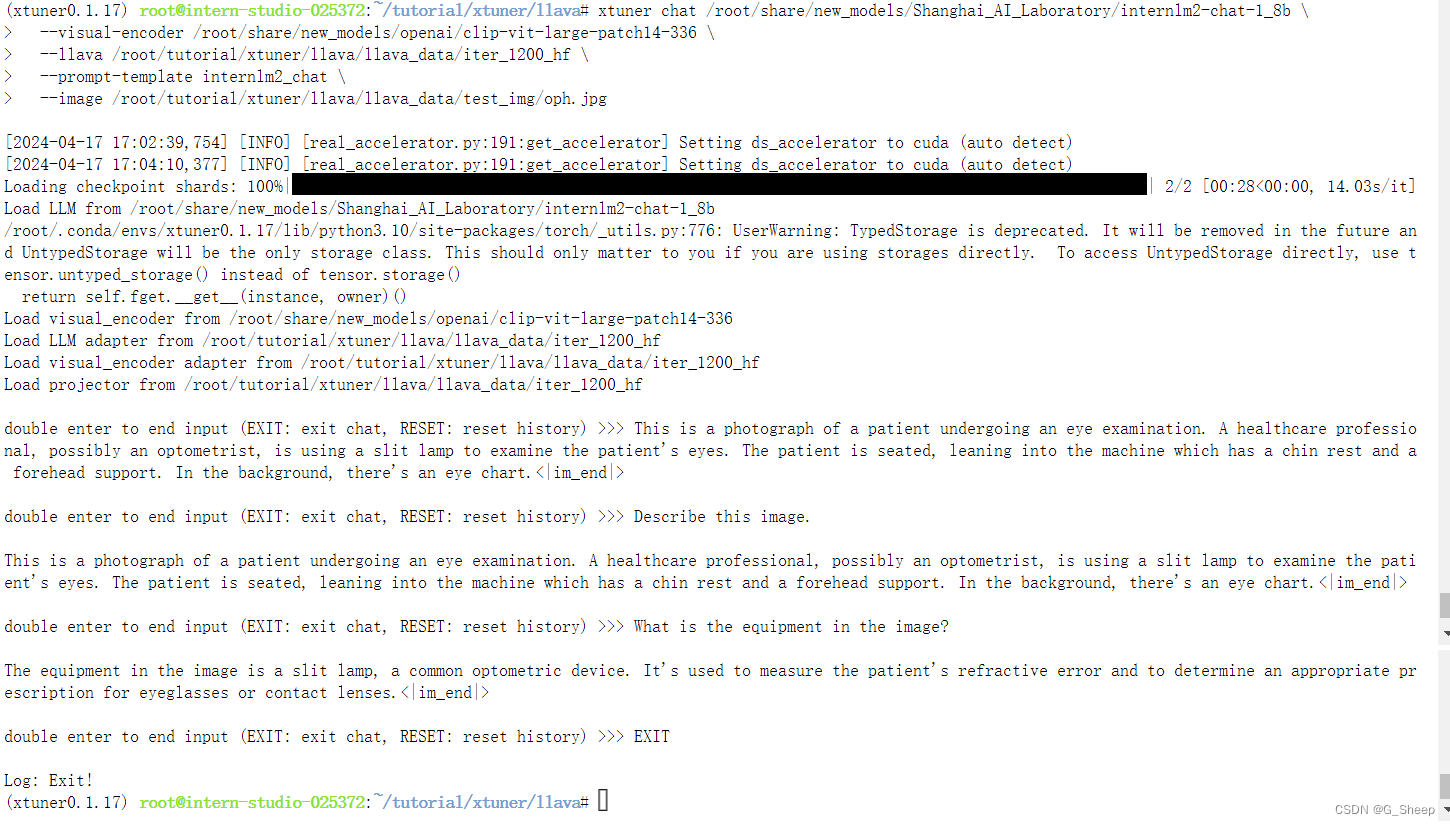
Finetune 过后,模型能够根据提问的问题来回答对应的内容。















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









