






**
Hadoop
**
一、什么是Hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。它允许使用简单的编程模型在计算机集群中对大型数据集进行分布式处理。它被设计成从单一服务器扩展到数千台机器,每台机器都提供本地计算和存储。该库本身不是依靠硬件来提供高可用性,而是用于检测和处理应用层的故障,因此在一组计算机上提供提供了 高可靠性、高扩展性和高吞吐率的数据存储服务
二、 理解hadoop2.0HA的框架
 1.namenode(NN):存储文件的元数据(文件名、文件目录结构、文件属性等等)
1.namenode(NN):存储文件的元数据(文件名、文件目录结构、文件属性等等)
2.datanode(DN):在本地文件系统存储文件块数据,以及块数据的校验
3.secondarynode:用来监控HDFS状态的辅助后台程序,每隔一段时间获取元数据的快照
4.journalnode(JN):用于手动切换namenode,日志管理两台NN,同步数据
5.zookeep(ZK):管理所有结点
6.NN active:正在运行的NN
7.NN Standby:备用的NN
8.FailoverController(FC):监视器
9.Zookeep Failover Controller(ZKFC):自动监视两台NN
四台DN向NN Active汇报数据(此NN Active不固定)。当NN active出现了故障,就会由JN负责使备用机NN Standby与故障机进行替换,这是手动模式。但是在集群极其多的时候,需要用到ZK进行自动管理,ZK下有两个监视器FC监视着两台NN,当NN active出现了故障,FC Active检测到监视的NN处于挂断状态,立即汇报给ZK,由ZK通过另一台FC看NN Standby是否正常,若为正常则自动切换其状态,将两台NN的状态互换。
·在自动模式下,每个NN都有对应的ZKFC监视。在ZK选择NN时,是由其先后顺序决定的,先发送数据的NN就设其为Active。
三、安装软件
准备工作:现在一台机子上安装xshell,xftp,jdk,zopkeeper
时间同步:准备工作完成后,先将几台机子的时间同步,使用-ntpdate time1.aliyun.com 命令,与阿里云的时间相同步再用-date命令查看是否完成同步。

**发送jdk:**几台机子时间同步之后,将第一台机子上的jdk分别发送到另外几台机子,使用–scp jdk-7u67-linux-x64.rpm node04:pwd命领发送到node03,04,05上(我的机子的名称)
 (jdk已发,此命令是我后来输的就不执行了)发送完毕后使用-ll查看,即可看到jdk。
(jdk已发,此命令是我后来输的就不执行了)发送完毕后使用-ll查看,即可看到jdk。
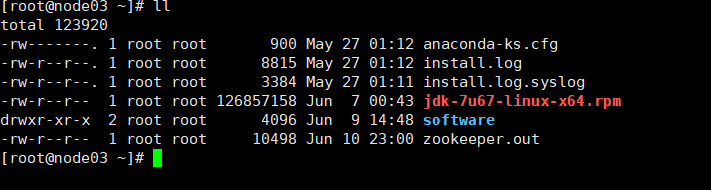
安装jdk:在使用命令-rpm -i jdk-7u67-linux-x64.rpm安装jdk。并在node02上将/etc目录下的被编辑过profile文件使用-scp profile node04:pwd命令分发到node03、04,05上。profile文件编辑如下:

**免秘钥:**使用-cat /etc/sysconfig/network命令查看HOSTNAME是否正确
使用-cat /etc/hosts命令查看IP映射是否正确
入不正确可以查看/etc/sysconfig/selinux文件。
使用-ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa命令实行几台机子免秘钥操作,scp id_dsa.pub node05:pwd/node03.pub命令将公钥发给其他机子。完成后登陆其他机子不需输入密码。exit命令退出。

同理完成其他机子的免秘钥操作。
修改namenode的一些配置信息
修改 hdfs-site.xml,core-site.xml,slaves,先打开自己的文件目录。

hdfs-site.xml:

core-site.xml:
 slaves:
slaves:
并将修改的文件分别发送到其他几台机子node03,04,05.
用xftp将zookeeper传到虚拟机,并安装zookeeper
解压安装zookeeper
tar xf zookeeper-3.4.6.tar.gz -C /opt/yhq
修改zookeeper的配置文件
cd /opt/ldy/zookeeper-3.4.6/conf
给zoo_sample.cfg改名
cp zoo_sample.cfg zoo.cfg (防止修改错误,保留原版)
并修改zoo.cfg :

再把zookeeper分发到其他节点
scp -r zookeeper-3.4.6/ node04:pwd
scp -r zookeeper-3.4.6/ node05:pwd
并用-ll /opt/yhq检查下看分发成功没
给每台机子创建刚配置文件里的路径
mkdir -p /var/yhq/zk
对node03来说:
echo 1 > /var/yhq/zk/myid
cat /var/yhq/zk/myid
对node04来说:
echo 2 > /var/yhq/zk/myid
cat /var/yhq/zk/myid
对node05来说:
echo 3 > /var/yhq/zk/myid
cat /var/yhq/zk/myid
配置好后文件便存放在这里
启动zookeeper
使用-zkServer.sh start命令
接着用zkServer.sh status查看每个zookeeper节点的状态
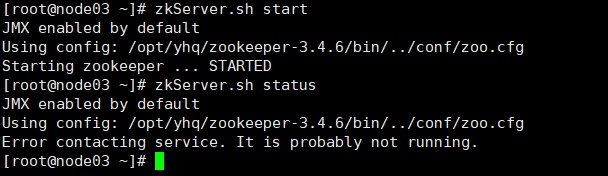
如图为启动失败,则把/etc/profile里的JAVA_HOME改
成绝对路径。改正过后重启成功,此处遇到的小问题很好解决,解决后启动成功如图,状态会显示leader或者follower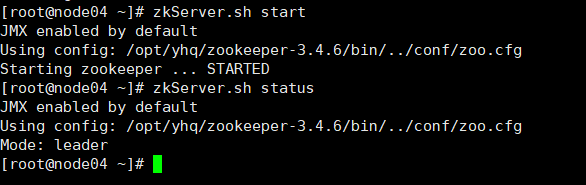
启动journalnode
-使用hadoop-daemon.sh start journalnode命令,启动后使用jps检查是否启动,启动车成功会jps会显示。如果失败则可以去log中查找日志寻找问题,日志在/opt/yhq/hadoop-2.6.5/logs中。日志查看使用tail命令

格式化namenode
随意挑一台namenode上执行hdfs namenode –format另一台namenode不用执行,否则clusterID变了,找不到集群了。然后,启动刚刚格式化的namenode
-hadoop-daemon.sh start namenode,启动后使用jps,即可看到namenode
同步另一台的namenode,-hdfs namenode -bootstrapStandby。此处非常要注意的一点,namenode只能格式化一遍,不然启动namenode会失败而日志找不到任何问题,我找不到解决方法只好重头来过。
格式化zkfc
hdfs zkfc -formatZK
查看hadoop-ha是否打开,输入命令
zkChli.sh
ls /在node02上执行zkCli.sh打开zookeeper客户端看hadoop-ha是否打开

启动集群
1.在node02上启动hdfs集群:start-dfs.sh

用浏览器访问node03:50070和node04:50070

关闭集群命令:stop-dfs.sh
关闭zookeeper命令:zkServer.sh stop。















 2118
2118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









