







决策树模型
举例解释决策树是如何工作的——猫分类。
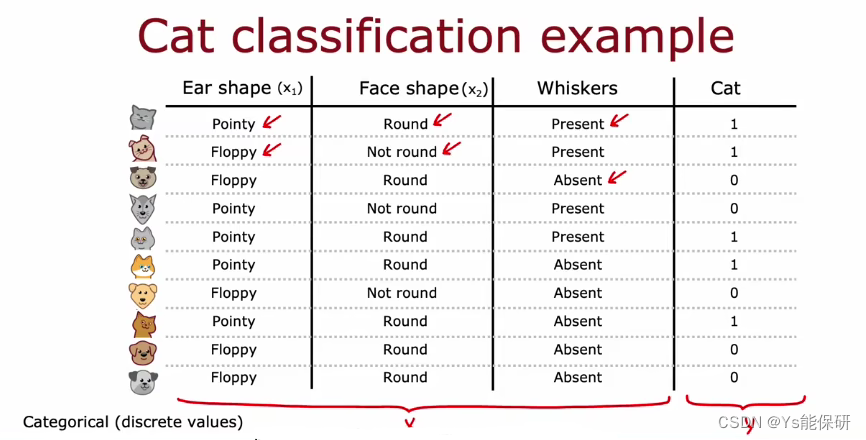
这是一个二元分类任务,并且每个特征也只能取两个离散值,下面是训练决策树模型可能得到获得的模型示例。
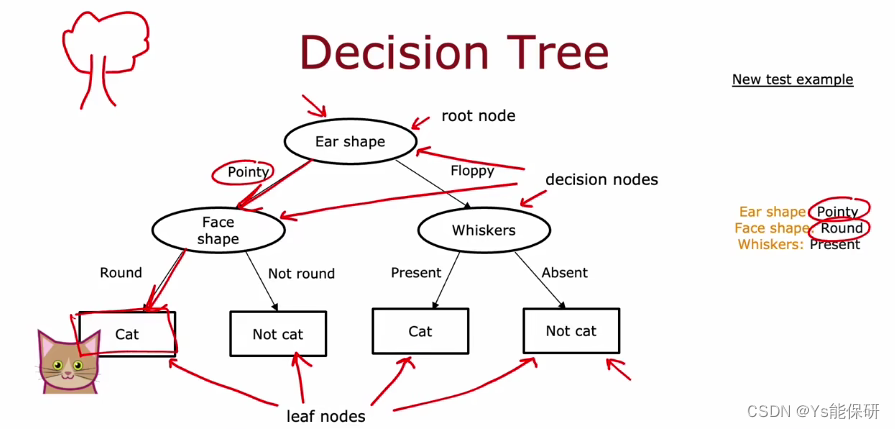
根节点:树中最顶层的节点。
决策节点:图中的椭圆节点。
叶子节点:图中的矩形节点。
学习过程
在构建决策树的过程中,我们需要做出几个关键决定。
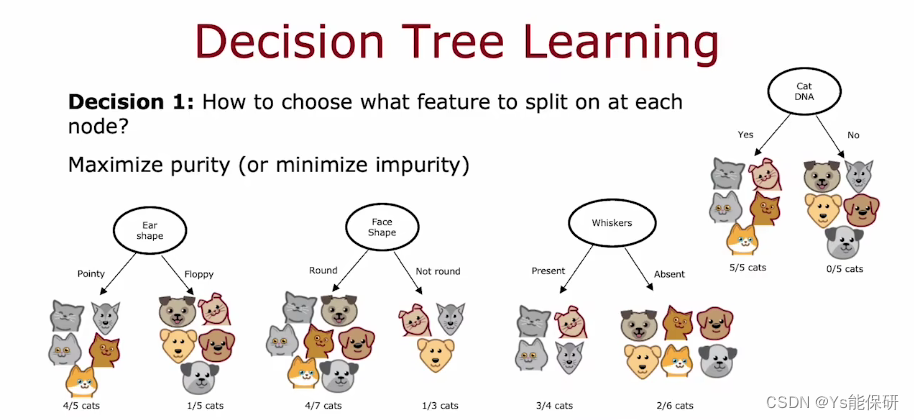
第一个关键决定是,如何选择在每个节点上使用哪些特征进行拆分。原则就是最大化纯度(使每个节点中尽量都是猫或者狗)。
第二个关键决定是,何时停止拆分。

- 当一个节点只属于一类时;
- 当拆分节点导致超过树的最大深度时,限制决策树深度的一个原因是为了确保我们的树不会变得太大或者笨重,并且保持树小使它不太容易过拟合;
- 当拆分节点对纯度得改善很小时;
- 当节点的示例数低于某个阈值时;
纯度
熵是衡量一组数据是否不纯的指标。
我们定义 p1 是样本中猫的比例,则熵和 p1 的函数图像如下:

定义 p0 为样本中不为猫的比例,则熵函数的实际方程如下:
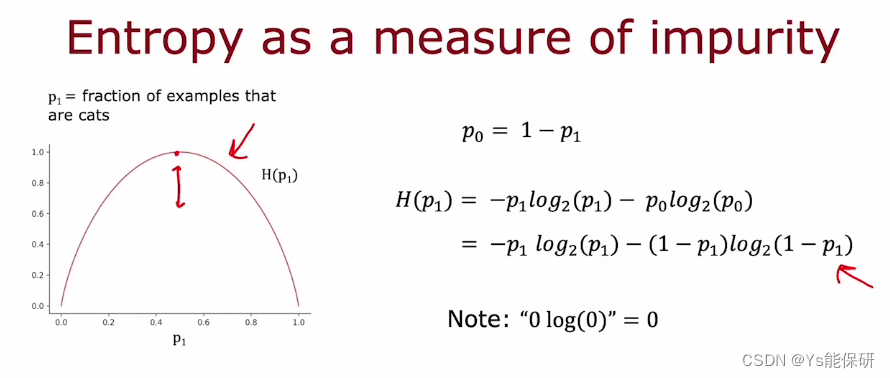
注意,计算熵时采用的是以 2 为底而不是以 e 为底的对数,是为了让曲线的峰值等于 1,便于解释曲线的意义(杂质含量)。
选择拆分:信息增益
构建决策树时,在一个节点使用什么特征进行拆分取决于选择什么特征可以最大程度地减少熵。
熵的减少成为信息增益,下面来看看如何计算信息增益。

我们分别计算左右分支的熵之后,会发现每种分法有两个熵值,那么如何进行比较呢,事实上,如果一个节点上有很多高熵的样本往往比一个节点上只有几个高熵的样本更糟糕,所以通常计算一个加权平均,然后使用根节点的熵减去这个加权平均,即求出了熵的减少,即信息增益。
为什么要计算熵的减少?因为决定何时不进行拆分的标准之一就是如果熵减少的太小,增益太小,而拆分还会增加过拟合的风险,就停止拆分。

这就是信息增益的一般公式。
整合
决策树构造过程如下:

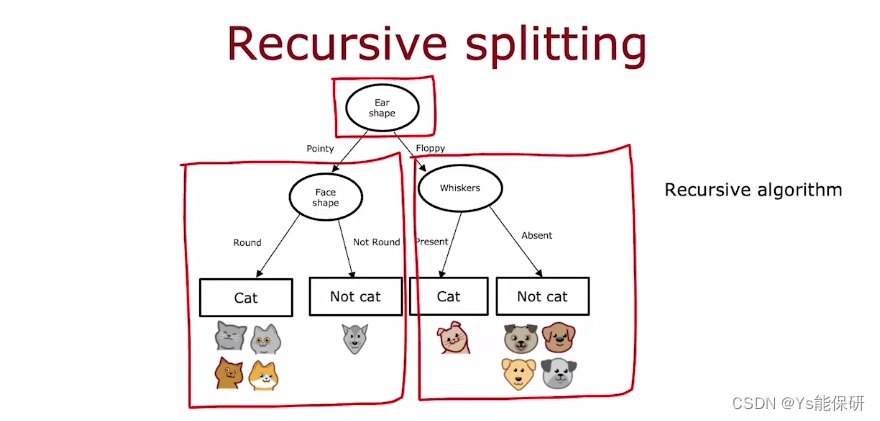
构造决策树是一个递归的过程。
One-hot 编码
在之前的样例中,每个特征只有两个离散的取值,那么当取值大于两个时,我们怎么构建决策树呢?此时就需要使用 One-hot 编码。
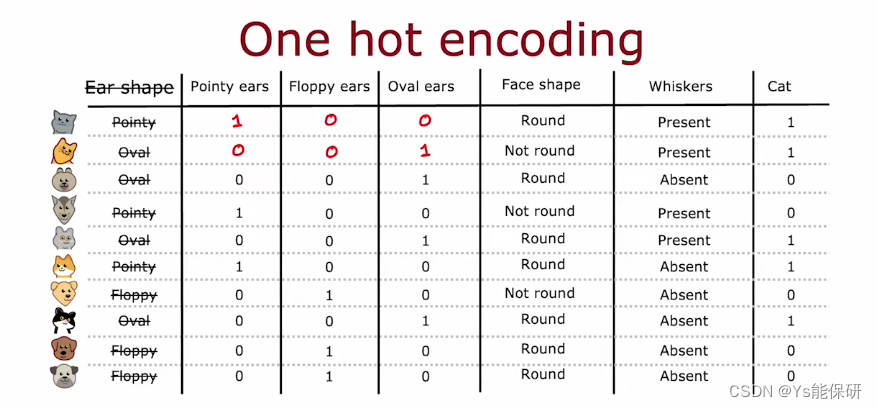
当耳型特征有三个离散取值时,我们把它拆开,创建三个新的特征,三个特征中只有一个能取 1,因此得名。
更详细一点,如果一个分类特征可以取 k 个值,那么我们将创建 k 个二进制特征来代替它。
这样每个特征就只能取两个离散的值,回到了之前的情况。
One-hot 编码不仅仅适用于决策树,它也适用于神经网络(使用 0、1 对特征进行编码,以便作为输入)。
连续值特征
当我们面临一个具有连续值的特征时,通常对其拆分的方式是设置一个阈值,根据是否小于等于阈值进行拆分。
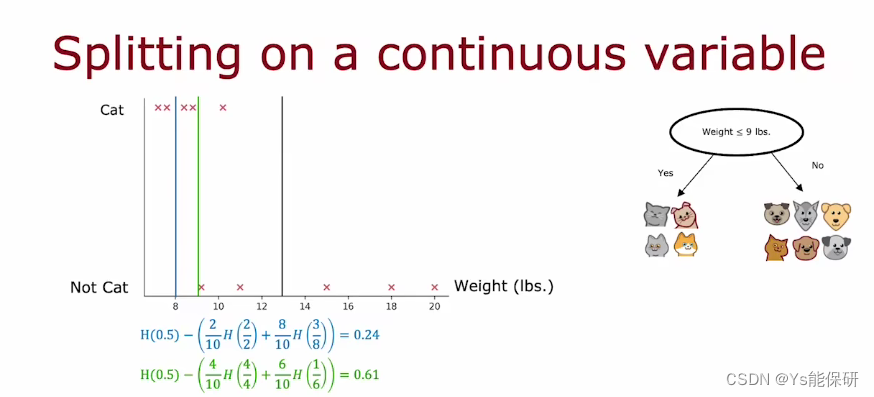
可能会有很多个不同的阈值选择,此时需要计算信息增益,选择带来的信息增益最大的那个阈值。
选择阈值时,一种常见的方法是,根据特征值大小对所有样例排序,取排序表中每两个连续点的中点值作为一种阈值选择,也就是说,当有 10 个样例时,会测试 9 个不同的阈值。
回归树
举例介绍回归树——预测动物体重。
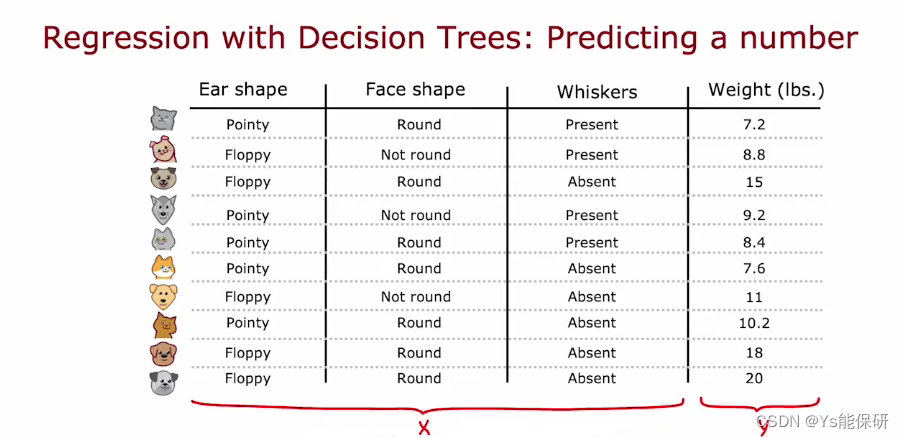
根据耳朵形状、面部形状、胡须来预测体重,因此是个回归问题。
为回归问题建立好的决策树如下图:
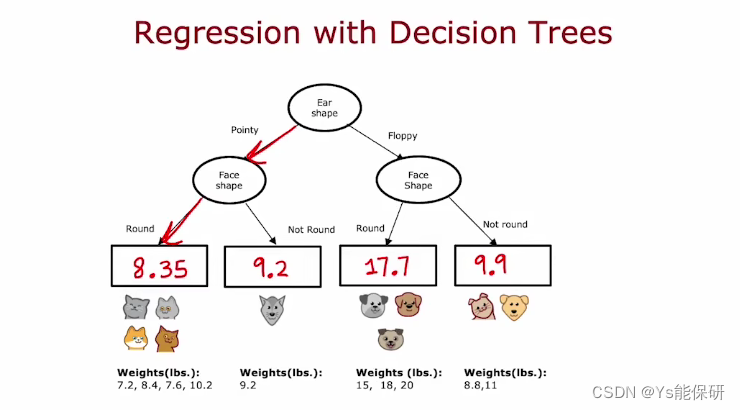
当预测一个新的样例时,从根节点开始根据样例特征进行决策,直至根节点,然后输出该叶节点动物的权重的平均值。

选择特征划分样例时,类比到尽量减少熵的方法,回归问题中是尽量减少方差。
使用多个决策树
使用单个决策树的缺点之一是该决策对数据中的微小变化高度敏感。
而使算法不那么敏感的解决方案是构建很多决策树,我们称之为树集合。

图中只更换了一个小猫的例子,就导致了两种完全不同的分类。
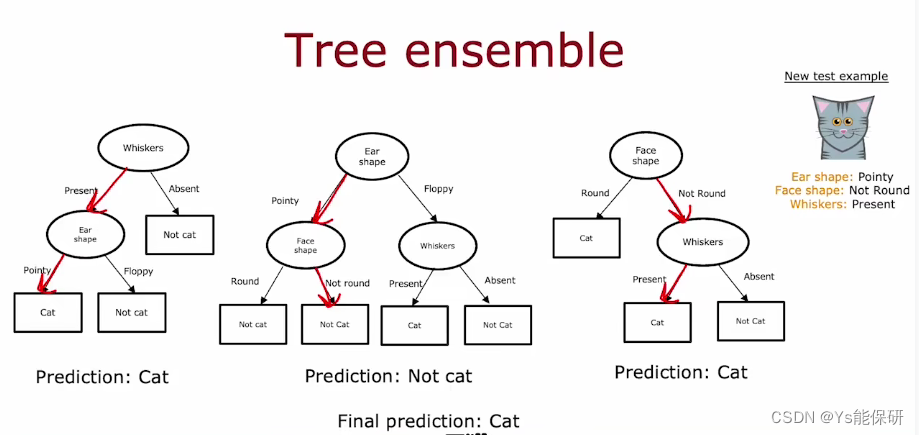
当构建多个决策树时,也就是树集合,对一个新的样例分别作出判断,然后投票决定最终结果。
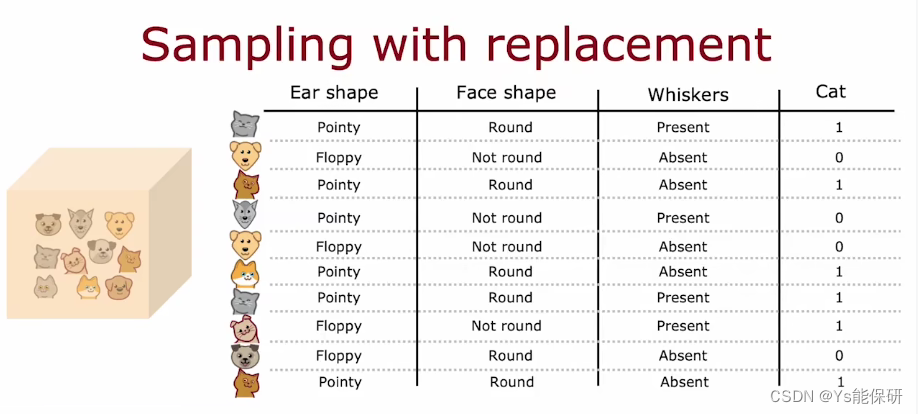
有放回抽样
原始训练集中有 10 个动物,我们做 10 次有放回抽样,得到一个新的训练集。
随机森林
如下图所示是生成一个树集合的算法:

对该算法进行一点更改,就变成了随机森林算法,如下图。

最后一个观点,机器学习工程师去哪里露营? 随机森林。
XGBoost

对生成树集合的算法进行了改进,除了第一次取样以外,每次优先选择在之前的随机树中预测错误的例子,也被称为刻意练习。
XGBoost 优点如下图:

XGBoost 的实现细节非常复杂,所以一般直接使用开源库。

何时使用决策树

总结一下,决策树适合处理结构化数据,并且训练速度快,小型决策树还具有可解释性;神经网络适合处理任何类型数据,通常和迁移学习一起应用,当需要多个模型联合使用时,使用神经网络也更容易一些。














 1705
1705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









