







2022吴恩达机器学习课程学习笔记(第一课第三周)
动机与目的
只有两个可能输出的分类问题成为二元分类。
常常用 class 或 category 表示类别;negative class 表示负类,positive class 表示正类。
注意:negative 和 positive 仅仅用于区分正负类别,不意味着好与坏。
我们之前学习的线性回归模型不适用于分类问题。

此时使用线性回归模型拟合数据,模型输出值小于0.5的预测为0,反之预测为1,似乎有效的解决了分类问题,但当我们再增加一点时,就会改变拟合的直线,从而改变决策边界,使分类出现问题。
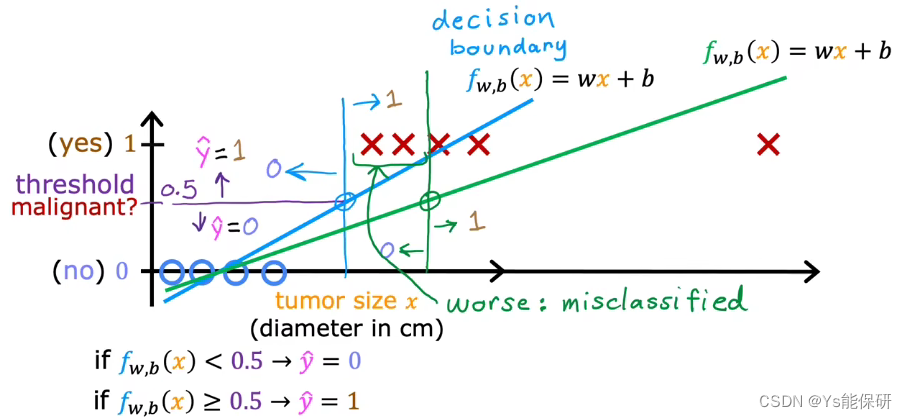 数据的添加不应该改变我们分类的方式,所以线性回归模型不适用于分类问题。
数据的添加不应该改变我们分类的方式,所以线性回归模型不适用于分类问题。
接下来要学习的逻辑回归模型用于解决二元分类问题。
逻辑回归
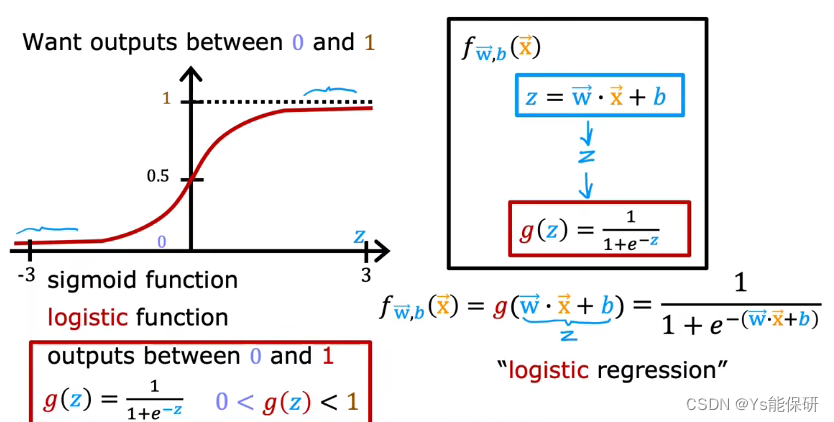
逻辑回归模型的作用是输入特征并输出一个介于 0 和 1 之间的数字。
为此引入 sigmoid 函数,先将输入特征 x 经过线性运算变成中间变量 z,然后将sigmoid 函数应用于 z ,最后输出一个介于 0 和 1 之间的数字。
逻辑回归模型的输出是指预测类别为 1 的概率。
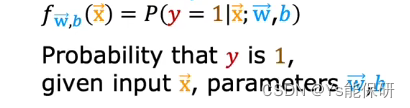
给定特征 x,参数是 w 和 b 时,输出结果 y 等于 1 的概率。
决策边界
我们知道逻辑回归模型的输出是预测类别为 1 的概率,那么如何来学习预测算法呢?也就是如何预测输出的值是 1 还是 0?
我们要做的事是设置一个阈值,高于该值时预测 y-hat = 1,低于该值时预测 y-hat = 0。
一个常见的选择是设置阈值为 0.5。

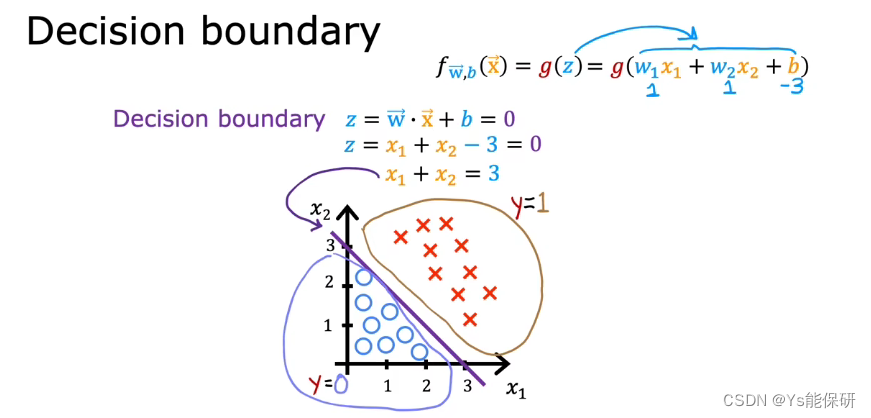
我们将 z = w · x + b = 0 称为决策边界,因为这条线对于 y 是 0 还是 1 几乎持中立状态。
在线性回归中可以使用多项式,同样,在逻辑回归中也可以使用多项式,适用于决策边界不是直线的情况。

逻辑回归中的代价函数
平方误差代价函数不适用于逻辑回归模型,因为它的代价函数不是凸函数。
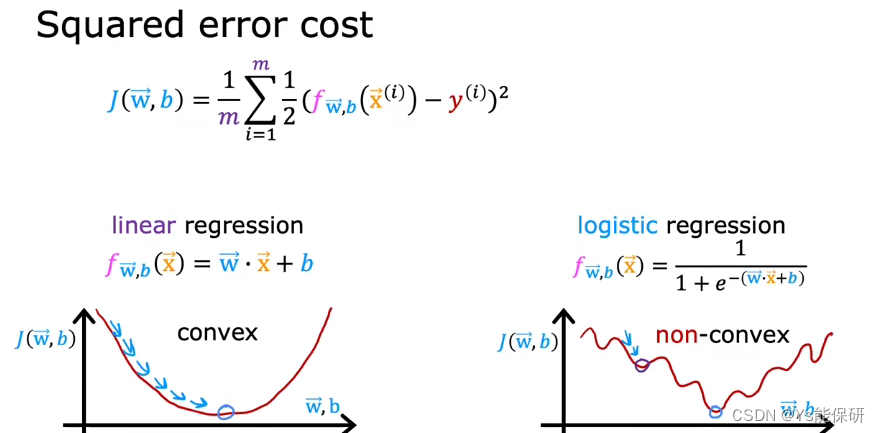
逻辑回归损失函数的定义

损失函数衡量的是在一个训练样例上做的如何,通过把所有训练样例上的损失相加得到的是代价函数——衡量在整个数据集上做的如何。
逻辑回归损失函数的理解
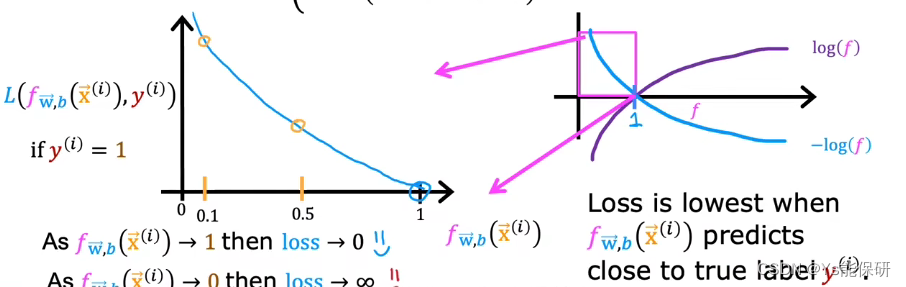
右侧图给出当 y(i) = 1 时,-log(f(x)) 的函数图像,而我们模型的输出在 0 和 1 之间,所以左侧给出我们需要关注的部分。
当 y-hat 接近 1 时,损失函数接近 0,当 y-hat 接近 0 时,损失函数接近正无穷,因此,当y(i) = 1 时损失函数是合理的。
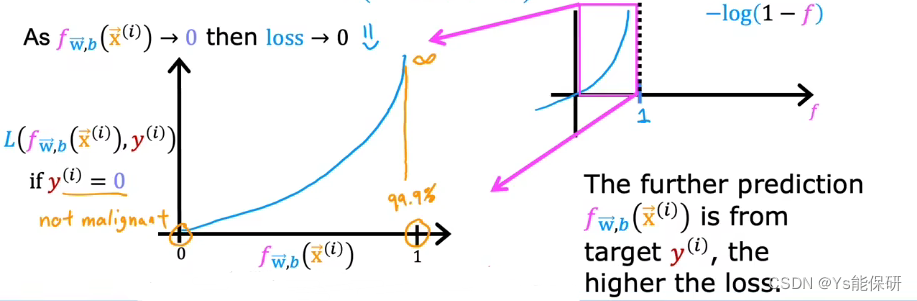
右侧图给出当 y(i) = 0 时,-log(1-f(x)) 的函数图像,而我们模型的输出在 0 和 1 之间,所以左侧给出我们需要关注的部分。
当 y-hat 接近 0 时,损失函数接近 0,当 y-hat 接近 1 时,损失函数接近正无穷,因此,当y(i) = 0 时损失函数是合理的。
上述的损失函数可以简化,如下:

逻辑回归代价函数的定义
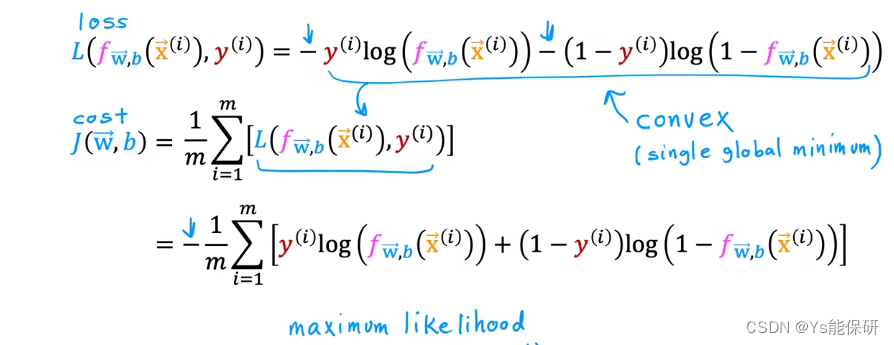
我们使用最大似然估计的统计学原理选择了这个特定的代价函数。
可以证明(但超出本课程的范围),此时的代价函数时凸函数。
实现梯度下降

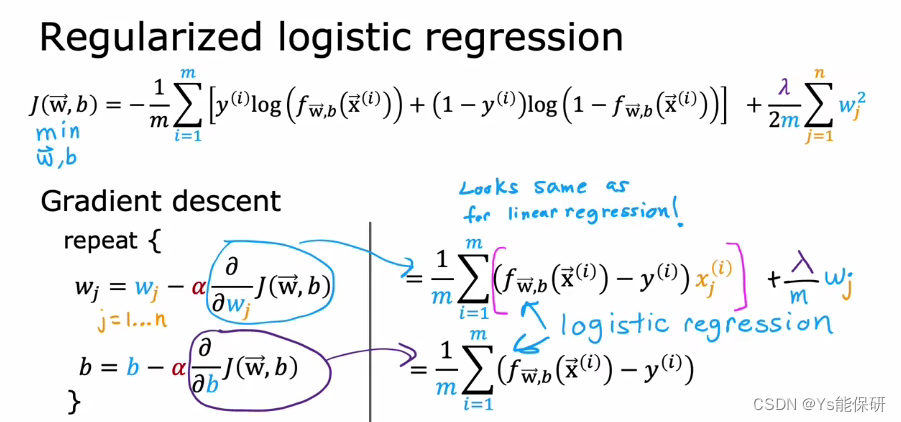
即使梯度下降的方程看起来和线性回归模型是一样的,但是他们的 f(x) 是不同的,因此是不同的算法。
过拟合问题
过拟合定义
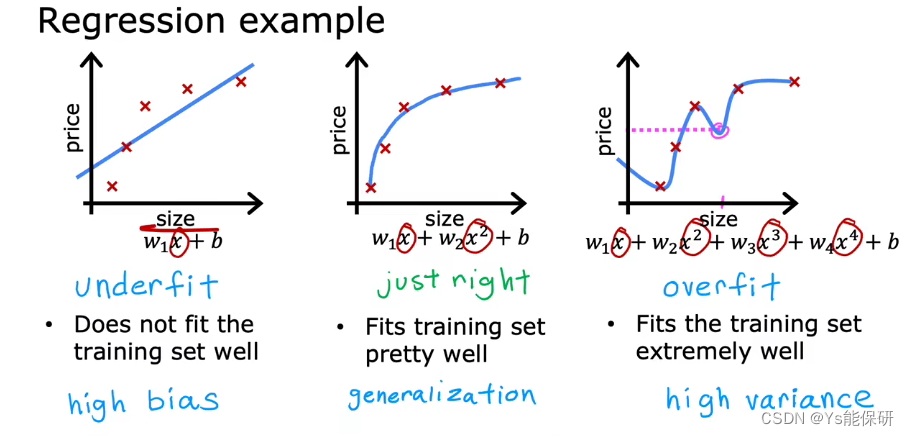
左侧图代表模型是欠拟合的,又称具有高偏差,我们认为数据是线性的,但是数据不是线性的,导致数据拟合的很差,所以被称为高偏差。
中间图代表模型是刚刚好的(实际上没有一个专门的名字来描述这种情况),泛化意味着模型对于以前从没见过的数据也能做出良好的预测。
右侧图代表模型是过拟合的,又称具有高方差,我们非常努力地拟合每一个训练样例,但是数据集稍有不同,就会导致拟合的曲线不同,所以被称为高方差。
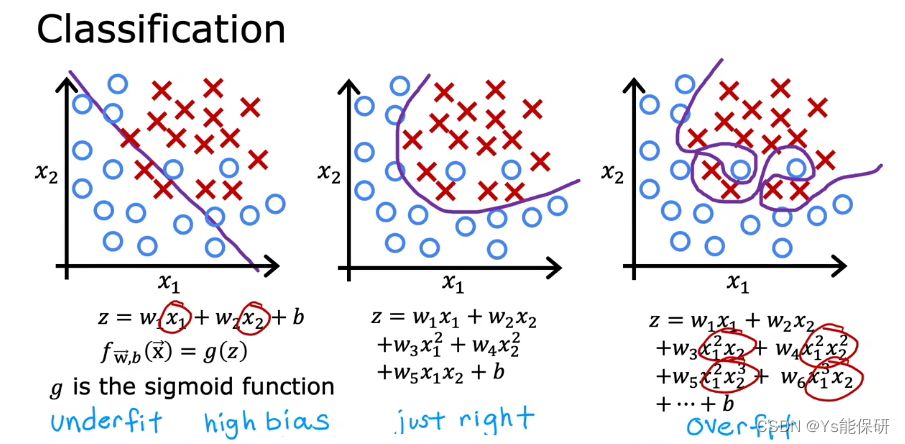
分类问题上同样存在欠拟合与过拟合问题。
解决过拟合
- 收集更多数据
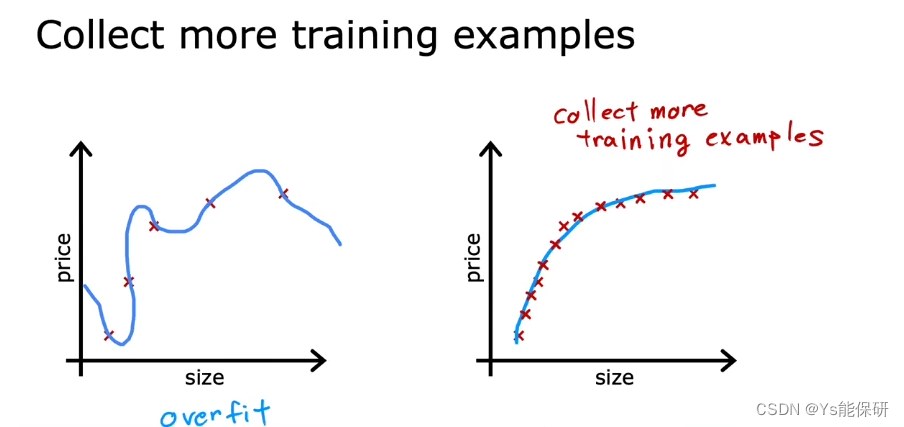
但这通常不是一个有效的办法,因为不一定还有更多的数据。 - 尝试只选择和使用所有特征的一个子集
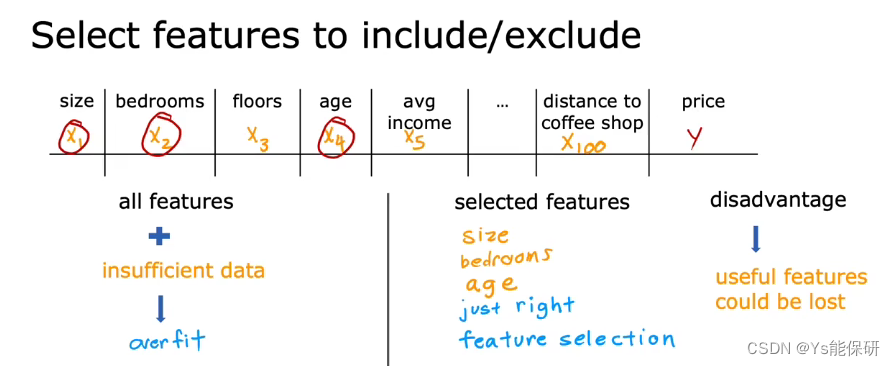
这可能会导致丢失某些有用的信息。 - 使用正则化来减少参数的大小
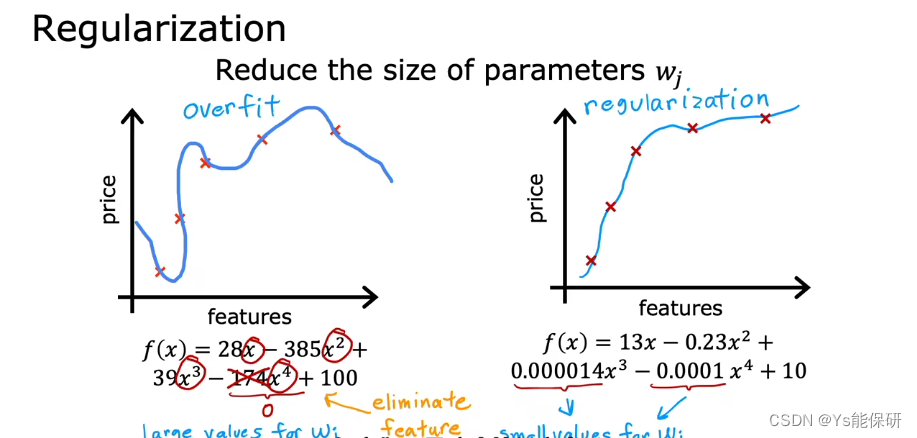
正则化的作用是保留所有特征,并鼓励学习算法缩小参数,从而防止特征产生过大的影响。
我们通常只是对 w 使用正则化,而不用去正则化 b,实践中,是否正则化 b 几乎没什么影响。
正则化
正则化工作原理

由于我们不知道哪个参数是重要的,所以通常的正则化方式是惩罚所有的特征,更准确的,惩罚所有的 wj。
第一项是均方误差,第二项是正则化项。
将后面的正则项也除以 2m,可以使选择一个好的 λ 值变得更容易一些,尤其是当我们扩充我们的训练集时,之前选择的 λ 现在也可能有效。
对于这个新的代价函数,我们有两个目标,即尝试最小化第一项,鼓励算法通过最小化平方误差来很好地拟合训练数据,尝试最小化第二项,保持所有的 wj 较小来抑制过拟合,而我们选择的 λ 指定了这两个目标的相对重要性。
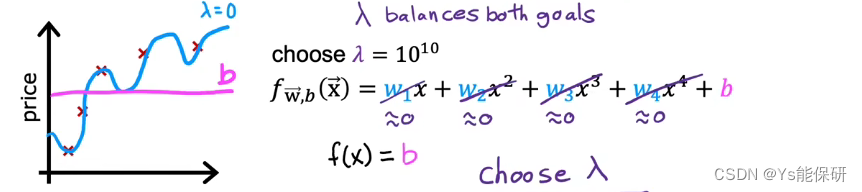
λ 很小时,导致模型过拟合;λ 很大时,导致模型欠拟合。
用于线性回归的正则化方法

与没有使用正则化的梯度下降不同的是,更新 wj 的公式中多了一项。
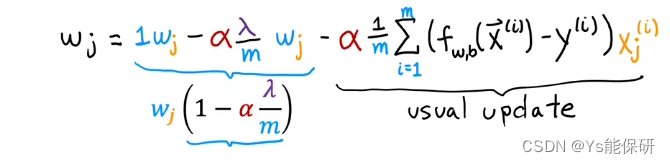
正则化工作原理:在每次迭代中,将 wj 乘以一个略小于 1 的数,使其具有缩小 wj 的效果。
用于逻辑回归的正则化方法














 7236
7236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









