







与PCA一样的学习过程,在学习SVD时同样补习了很多的基础知识,现在已经大致知道了PCA的应用原理,SVD个人感觉相对要难一点,但主要步骤还是能勉强理解,所以这里将书本上的知识和个人的理解做一个记录。主要关于(SVD原理、降维公式、重构原矩阵、SVD的两个实际应用),当然矩阵的分解和相对的公式我会给出写的更好的文章对于说明(个人基础有限)。
首先从线代的角度说一下(因为涉及推荐系统需要用到SVD分解现学的,本科时感觉线性代数也认真学了点,但是完全没用,现在也基本只记得基本概念,所以我想说的是除了应付考试,其他学习技术的时候要用到某个知识,然后你在开始认真学习相关的数学知识,这样比较有目的性而且也可以更好的理解,在结合实际代码看效果就更完美了,来自本学渣的小建议)言归正传,首先我们回忆一下矩阵对角化:
如果存在一个可逆矩阵 B(方阵)使得 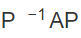 是对角矩阵,则它就被称为可对角化的。
是对角矩阵,则它就被称为可对角化的。
其中A为对角矩阵,P为单位正交矩阵,所以p的转置和p的逆矩阵一样。
关于B,一般的矩阵不一定可以对角化,但对称矩阵一定可以对角化。(这里打公式真的烦,我截图吧)

实质就是把矩阵分解为一些简单的线性叠加。
然后转到SVD分解:SVD是直接在原始矩阵上进行的矩阵分解。并且能对非方阵矩阵分解,得到左奇异矩阵U、sigma矩阵Σ、右奇异矩阵VT。和上面的矩阵分解一样,唯一的区别是它可以处理非对称矩阵和非方阵。
(最后给出两条SVD最重要的公式)
SVD(奇异值分解):
- 优点:简化数据,去除噪声点,提高算法的结果;
- 缺点:数据的转换可能难以理解;
- 适用于数据类型:数值型。
通过SVD对数据的处理,我们可以使用小得多的数据集来表示原始数据集,这样做实际上是去除了噪声和冗余信息,以此达到了优化数据、提高结果的目的。
隐形语义索引:最早的SVD应用之一就是信息检索,我们称利用SVD的方法为隐性语义检索(LSI)或隐形语义分析(LSA)
推荐系统:SVD的另一个应用就是推荐系统,较为先进的推荐系统先利用SVD从数据中构建一个主题空间,然后再在该空间下计算相似度,以此提高推荐的效果。
SVD与PCA不同,PCA是对数据的协方差矩阵进行矩阵的分解,而SVD是直接在原始矩阵上进行的矩阵分解。并且能对非方阵矩阵分解,得到左奇异矩阵U、sigma矩阵Σ、右奇异矩阵VT。
奇异性分解可以将一个矩阵分解成3个矩阵
、
、
,其中U、VT都是单式矩阵(unitary matrix),Σ是一个对角矩阵,也就是说只有对角线有值。对角元素称为奇异值,它们对应了原始矩阵Data的奇异值,如下:
[[2 0 0]
[0 3 0]
[0 0 4]
[0 0 0]]
一般奇异值我们只选择某一部分,选择的规则很多种,主要的一种为:
选择奇异值中占总奇异值总值90%的那些奇异值。(下面有演示如何选择)
SVD分解公式如下(类似于因式分解):
=
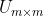
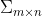
图形化表示奇异值分解:

在PCA中我们根据协方差矩阵得到特征值,它们告诉我们数据集中的重要特征,Σ中的奇异值亦是如此。奇异值和特征值是有关系的,这里的奇异值就是矩阵特征值的平方根。
SCV实现的相关线性代数,但我们无需担心SVD的实现,在Numpy中有一个称为线性代数linalg的线性代数工具箱能帮助我们。下面演示其用法对于一个简单的矩阵:
[[1 1]
[1 7]]
-
from numpy
import *
-
from numpy
import linalg
as la
-
-
df = mat(array([[
1,
1],[
1,
7]]))
-
U,Sigma,VT = la.svd(df)
-
print(U)
-
# [[ 0.16018224 0.98708746]
-
# [ 0.98708746 -0.16018224]]
-
print(Sigma)
-
# [7.16227766 0.83772234]
-
print(VT)
-
# [[ 0.16018224 0.98708746]
-
# [ 0.98708746 -0.16018224]]
通过简单的使用该工具就能得到运算的结果,所以我们着重应该理解的应该是这些结果的含义以及后续对它们的使用,下面通过推荐系统这个示例来进行实际的操作(数据集降维、重构数据集)。
基于协同过滤的搜索引擎:
我之前在集体编程智慧中学习了该算法,大致有两种方法来实现:
- 基于用户的协作型过滤
- 基于物品的协作型过滤
两种方法大致相同,但是在不同的环境下,使用最佳的方法能最大化的提升算法的效果。如下图(后面的示例数据)所示,对两样商品直接的距离进行计算,这称为基于物品的相似度。而对行与行(用户之间)进行距离的计算,这称为基于用户的相似度。到底该选用那种方法呢?这取决与用户或物品的数量,基于物品相似度的计算时间会随着物品数量的增加而增加。基于用户相似度则取决于用户数量,例如:一个最大的商店拥有大概100000种商品,而它的用户可能有500000人,这时选择基于物品相似度可能效果好很多。
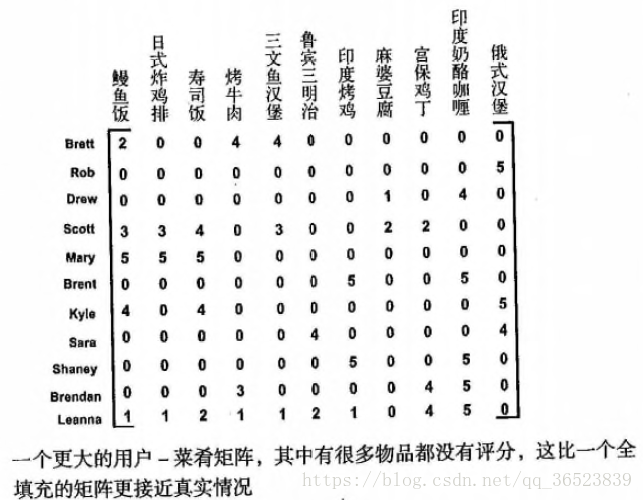
用上面的数据解释了如何选择基于协同过滤,下面使用基于物品相似度的方法来构建推荐系统(先直接使用原始矩阵来构建,然后再将处理函数换为SVD的处理函数,以便作比较)。
(说明:数据间的距离计算采用余玄相似、欧式距离、皮尔逊相关度其中任一种,这里不再解释,提供链接自行学习)
代码:
-
from numpy
import *
-
from numpy
import linalg
as la
-
-
# (用户x商品) # 为0表示该用户未评价此商品,即可以作为推荐商品
-
def loadExData():
-
return [[
0,
0,
0,
2,
2],
-
[
0,
0,
0,
3,
3],
-
[
0,
0,
0,
1,
1],
-
[
1,
1,
1,
0,
0],
-
[
2,
2,
2,
0,
0],
-
[
5,
0,
5,
0,
0],
-
[
1,
1,
1,
0,
0]]
-
-
# !!!假定导入数据都为列向量,若行向量则需要对代码简单修改
-
-
# 欧几里德距离 这里返回结果已处理 0,1 0最大相似,1最小相似 欧氏距离转换为2范数计算
-
def ecludSim(inA,inB):
-
return
1.0 / (
1.0 + la.norm(inA-inB))
-
-
# 皮尔逊相关系数 numpy的corrcoef函数计算
-
def pearsSim(inA,inB):
-
if(len(inA) <
3):
-
return
1.0
-
return
0.5 +
0.5*corrcoef(inA,inB,rowvar=
0)[
0][
1]
# 使用0.5+0.5*x 将-1,1 转为 0,1
-
-
# 余玄相似度 根据公式带入即可,其中分母为2范数计算,linalg的norm可计算范数
-
def cosSim(inA,inB):
-
num = float(inA.T * inB)
-
denom = la.norm(inA) * la.norm(inB)
-
return
0.5 +
0.5*(num/denom)
# 同样操作转换 0,1
-
-
-
# 对物品评分 (数据集 用户行号 计算误差函数 推荐商品列号)
-
def standEst(dataMat, user, simMeas, item):
-
n = shape(dataMat)[
1]
# 获得特征列数
-
simTotal =
0.0; ratSimTotal =
0.0
# 两个计算估计评分值变量初始化
-
for j
in range(n):
-
userRating = dataMat[user,j]
#获得此人对该物品的评分
-
if userRating ==
0:
# 若此人未评价过该商品则不做下面处理
-
continue
-
overLap = nonzero(logical_and(dataMat[:,item].A>
0,dataMat[:,j].A>
0))[
0]
# 获得相比较的两列同时都不为0的数据行号
-
if len(overLap) ==
0:
-
similarity =
0
-
else:
-
# 求两列的相似度
-
similarity = simMeas(dataMat[overLap,item],dataMat[overLap,j])
# 利用上面求得的两列同时不为0的行的列向量 计算距离
-
# print('%d 和 %d 的相似度是: %f' % (item, j, similarity))
-
simTotal += similarity
# 计算总的相似度
-
ratSimTotal += similarity * userRating
# 不仅仅使用相似度,而是将评分当权值*相似度 = 贡献度
-
if simTotal ==
0:
# 若该推荐物品与所有列都未比较则评分为0
-
return
0
-
else:
-
return ratSimTotal/simTotal
# 归一化评分 使其处于0-5(评级)之间
-
-
# 给出推荐商品评分
-
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
-
unratedItems = nonzero(dataMat[user,:].A==
0)[
1]
# 找到该行所有为0的位置(即此用户未评价的商品,才做推荐)
-
if len(unratedItems) ==
0:
-
return
'所有物品都已评价...'
-
itemScores = []
-
for item
in unratedItems:
# 循环所有没有评价的商品列下标
-
estimatedScore = estMethod(dataMat, user, simMeas, item)
# 计算当前产品的评分
-
itemScores.append((item, estimatedScore))
-
return sorted(itemScores, key=
lambda jj: jj[
1], reverse=
True)[:N]
# 将推荐商品排序
-
-
# 结果测试如下:
-
myMat = mat(loadExData())
-
myMat[
0,
1] = myMat[
0,
0] = myMat[
1,
0] = myMat[
2,
0] =
4
# 将数据某些值替换,增加效果
-
myMat[
3,
3] =
2
-
result1 = recommend(myMat,
2)
# 余玄相似度
-
print(result1)
-
result2 = recommend(myMat,
2,simMeas=ecludSim)
# 欧氏距离
-
print(result2)
-
result3 = recommend(myMat,
2,simMeas=pearsSim)
# 皮尔逊相关度
-
print(result3)
上面代码种用了三种计算距离的函数,经过测试后使用其中一种便可以了。然后对于物品评分函数中的nonzero(logical_and)不是很明白的请看这篇专门讲解的文章。以上为普通的处理方式,下面使用SVD来做基于物品协同过滤。
SVD方法,用下面函数(svdEst)来替换上面的物品评价函数(standEst)即可,并且这里使用更复杂的数据集:
-
# (用户x商品) # 为0表示该用户未评价此商品,即可以作为推荐商品
-
def loadExData2():
-
return [[
0,
0,
0,
0,
0,
4,
0,
0,
0,
0,
5],
-
[
0,
0,
0,
3,
0,
4,
0,
0,
0,
0,
3],
-
[
0,
0,
0,
0,
4,
0,
0,
1,
0,
4,
0],
-
[
3,
3,
4,
0,
0,
0,
0,
2,
2,
0,
0],
-
[
5,
4,
5,
0,
0,
0,
0,
5,
5,
0,
0],
-
[
0,
0,
0,
0,
5,
0,
1,
0,
0,
5,
0],
-
[
4,
3,
4,
0,
0,
0,
0,
5,
5,
0,
1],
-
[
0,
0,
0,
4,
0,
4,
0,
0,
0,
0,
4],
-
[
0,
0,
0,
2,
0,
2,
5,
0,
0,
1,
2],
-
[
0,
0,
0,
0,
5,
0,
0,
0,
0,
4,
0],
-
[
1,
0,
0,
0,
0,
0,
0,
1,
2,
0,
0]]
-
-
# 替代上面的standEst(功能) 该函数用SVD降维后的矩阵来计算评分
-
def svdEst(dataMat, user, simMeas, item):
-
n = shape(dataMat)[
1]
-
simTotal =
0.0; ratSimTotal =
0.0
-
U,Sigma,VT = la.svd(dataMat)
-
Sig4 = mat(eye(
4)*Sigma[:
4])
#将奇异值向量转换为奇异值矩阵
-
xformedItems = dataMat.T * U[:,:
4] * Sig4.I
# 降维方法 通过U矩阵将物品转换到低维空间中 (商品数行x选用奇异值列)
-
for j
in range(n):
-
userRating = dataMat[user,j]
-
if userRating ==
0
or j == item:
-
continue
-
# 这里需要说明:由于降维后的矩阵与原矩阵代表数据不同(行由用户变为了商品),所以在比较两件商品时应当取【该行所有列】 再转置为列向量传参
-
similarity = simMeas(xformedItems[item,:].T,xformedItems[j,:].T)
-
# print('%d 和 %d 的相似度是: %f' % (item, j, similarity))
-
simTotal += similarity
-
ratSimTotal += similarity * userRating
-
if simTotal ==
0:
-
return
0
-
else:
-
return ratSimTotal/simTotal
-
-
# 结果测试如下:
-
myMat = mat(loadExData2())
-
result1 = recommend(myMat,
1,estMethod=svdEst)
# 需要传参改变默认函数
-
print(result1)
-
result2 = recommend(myMat,
1,estMethod=svdEst,simMeas=pearsSim)
-
print(result2)

上面的之所以使用4这个数字,是因为通过预先计算得到能满足90%的奇异值能量的前N个奇异值。判断计算如下:
-
# 选出奇异值能量大于90%的所有奇异值
-
myMat = mat(loadExData2())
-
U,sigma,VT = linalg.svd(myMat)
-
sigma = sigma**
2
# 对奇异值求平方
-
cnt = sum(sigma)
# 所有奇异值的和
-
print(cnt)
-
value = cnt*
0.9
# 90%奇异值能量
-
print(value)
-
cnt2 = sum(sigma[:
3])
# 2小于90%,前3个则大于90%,所以这里选择前三个奇异值
-
print(cnt2)
-
-
# 541.9999999999995
-
# 487.7999999999996
-
# 500.5002891275793
在函数svdEst中使用SVD方法,将数据集映射到低纬度的空间中,再做运算。其中的xformedItems = dataMat.T*U[:,:4]*Sig4.I可能不是很好理解,它就是SVD的降维步骤,通过U矩阵和Sig4逆矩阵将商品转换到低维空间(得到 商品行,选用奇异值列)。
以上是SVD的一个示例,但是对此有几个问题:
- 我们不必在每次评分是都做SVD分解,大规模数据上可能降低效率,可以在程序调用时运行一次,在大型系统中每天运行一次或频率不高,还要离线运行;
- 矩阵中有很多0,实际系统中0更多,可以通过只存储非0元素来节省空间和计算开销;
- 计算资源浪费来自于相似度的计算,每次一个推荐时都需要计算多个物品评分(即相似度),在需要时此记录可以被用户重复使用。实际中,一个普遍的做法是离线计算并保存相似度得分,这一点在之前学习集体编程智慧中有说明。
基于SVD的图像压缩:
这里不采用书中的例子来讲解,因为无趣所以这里换作我们的男神来做一个简单的SVD图片压缩作为一个示例:
首先放上男神图片:

基于SVD图片压缩原理其实很简单,图片其实就是数字矩阵,通过SVD将该矩阵降维,只使用其中的重要特征来表示该图片从而达到了压缩的目的。
直接上代码:
-
# 男神老吴SVD处理
-
-
from skimage
import io
-
import matplotlib.pyplot
as plt
-
-
path =
'male_god.jpg'
-
data = io.imread(path,as_gray=True)
-
data = mat(data)
# 需要mat处理后才能在降维中使用矩阵的相乘
-
U,sigma,VT = linalg.svd(data)
-
# 在重构之前,依据前面的方法需要选择达到某个能量度的奇异值
-
cnt = sum(sigma)
-
print(cnt)
-
cnt90 =
0.9*cnt
# 达到90%时的奇异总值
-
print(cnt90)
-
count =
50
# 选择前50个奇异值
-
cntN = sum(sigma[:count])
-
print(cntN)
-
-
# 重构矩阵
-
dig = mat(eye(count)*sigma[:count])
# 获得对角矩阵
-
# dim = data.T * U[:,:count] * dig.I # 降维 格外变量这里没有用
-
redata = U[:,:count] * dig * VT[:count,:]
# 重构
-
-
plt.imshow(redata,cmap=
'gray')
# 取灰
-
plt.show()
# 可以使用save函数来保存图片

原图片为870x870,保存像素点值为870x870 = 756900,使用SVD,取前50个奇异值则变为:
存储量大大减小,仅50个奇异值就已经能很好的反应原数据了。
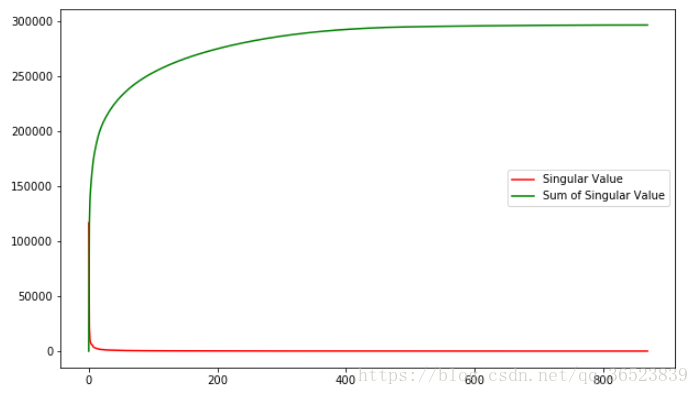
值得一提的是,奇异值从大到小衰减得特别快,在很多情况下,前 10% 甚至 1% 的奇异值的和就占了全部的奇异值之和的 99% 以上了。这对于数据压缩来说是个好事。下面这张图展示了本例中奇异值和奇异值累加的分布(参考博客下面附上链接):
SVD两个个人觉得最重要的计算步骤这里说一下:
- 数据集降维:
这里的sigma为对角矩阵(需要利用原来svd返回的sigma向量构建矩阵,构建需要使用count这个值)。U为svd返回的左奇异矩阵,count为我们指定的多少个奇异值,这也是sigma矩阵的维数。
- 重构数据集:
这里的sigma同样为对角矩阵(需要利用原来svd返回的sigma向量构建矩阵,构建需要使用count这个值),VT为svd返回的右奇异矩阵,count为我们指定的多少个奇异值(可以按能量90%规则选取)。
以上为两个个人觉得最重要的公式,如果有不明白的可以参考上面的代码,有使用到这两个公式。(虽然不负责任,但还是说一下:如果你不能立刻理解SVD的原理,可以先记下这两个公式来使用,后面有时间了在来深入了解哈哈)
————————————————————
参考书籍:《机器学习实战》















 1206
1206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









