






3.1 configuration
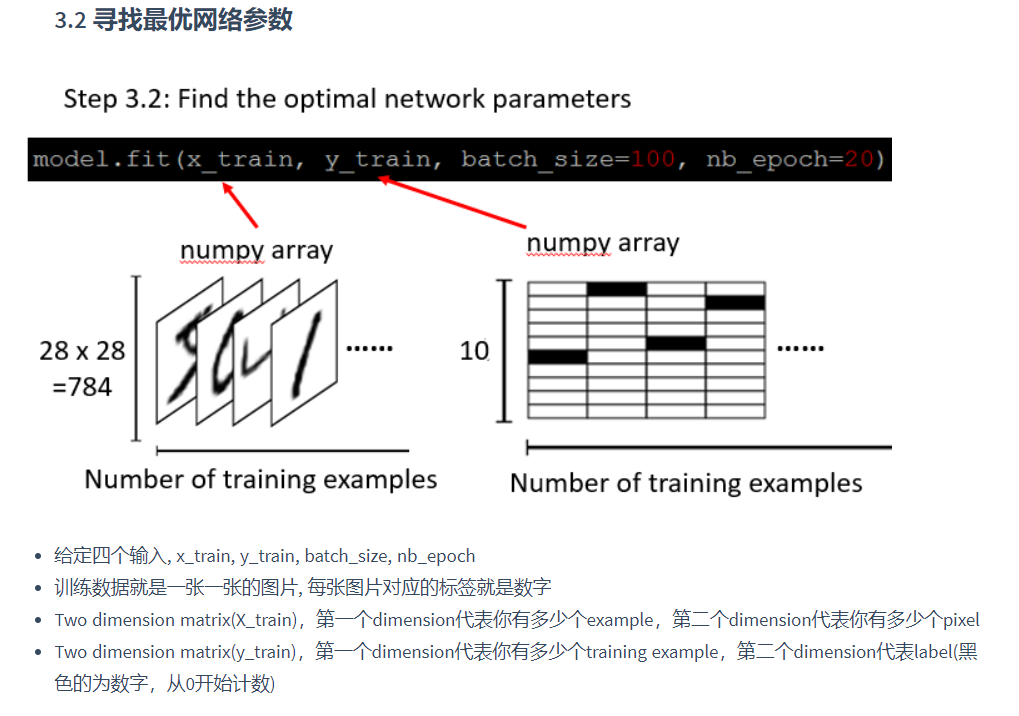
3.2 寻找最优网络参数
代码示例:
# 1.Step 1
model = Sequential()
model.add(Dense(input_dim=28*28, output_dim=500)) # Dense是全连接
model.add(Activation('sigmoid'))
model.add(Dense(output_dim=500))
model.add(Activation('sigmoid'))
model.add(Dense(output_dim=10))
model.add(Activation('softmax'))# Step 2
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# Step 3
model.fit(x_train, y_train, batch_size=100, nb_epoch=20)# 模型保存
#case1:测试集正确率
score = model.evaluate(x_test,y_test)
print("Total loss on Testing Set:", score[0])
print("Accuracy of Testing Set:", score[1])
#case2:模型预测
result = model.predict(x_test)Keras 2.0 代码类似
# 创建网络
model=Sequential()
model.add(Dense(input_dim=28*28,units=500,activation='relu'))
model.add(Dense(units=500,activation='relu'))
model.add(Dense(units=10,activation='softmax'))
# 配置
model.compile(loss='categorical crossentropy',optimizer='adam',metrics=['accuracy'])
# 选择最好的方程
model.fit(x_train,y_train,batch_size=100,epochs=20)
# 使用模型
score = model.evaluate(x_test,y_test)
print('Total loss on Testiong Set : ',score[0])
print('Accuracy of Testiong Set : ',score[1])
# 上线后预测
result = model.predict(x_test)x_train, y_train解释
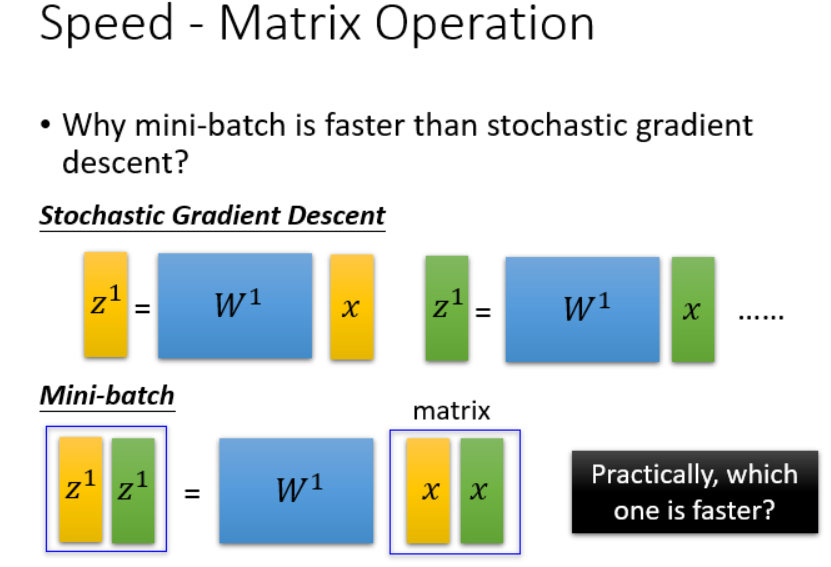
小批量梯度下降,速度更快的原因是因为可以并行计算。

完整的Keras演示:
import numpy as np
from keras.models import Sequential
from keras.layers.core import Dense,Dropout,Activation
from keras.optimizers import SGD,Adam
from keras.utils import np_utils
from keras.datasets import mnistdef load_data():
(x_train,y_train),(x_test,y_test)=mnist.load_data()
number=10000
x_train=x_train[0:number]
y_train=y_train[0:number]
x_train=x_train.reshape(number,28*28)
x_test=x_test.reshape(x_test.shape[0],28*28)
x_train=x_train.astype('float32')
x_test=x_test.astype('float32')
y_train=np_utils.to_categorical(y_train,10)
y_test=np_utils.to_categorical(y_test,10)
x_train=x_train
x_test=x_test
x_train=x_train/255
x_test=x_test/255
return (x_train,y_train),(x_test,y_test)(x_train,y_train),(x_test,y_test)=load_data()
model=Sequential()
model.add(Dense(input_dim=28*28,units=633,activation='sigmoid'))
model.add(Dense(units=633,activation='sigmoid'))
model.add(Dense(units=633,activation='sigmoid'))
model.add(Dense(units=10,activation='softmax'))
model.compile(loss='mse',optimizer=SGD(lr=0.1),metrics=['accuracy'])
model.fit(x_train,y_train,batch_size=100,epochs=20)
result= model.evaluate(x_test,y_test)
print('TEST ACC:',result[1])运行结果:
Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz
11493376/11490434 [==============================] - 21s 2us/step
Epoch 1/20
10000/10000 [==============================] - 3s 342us/step - loss: 0.0905 - acc: 0.1042
Epoch 2/20
10000/10000 [==============================] - 3s 292us/step - loss: 0.0900 - acc: 0.1043
Epoch 3/20
10000/10000 [==============================] - 3s 278us/step - loss: 0.0900 - acc: 0.1096
Epoch 4/20
10000/10000 [==============================] - 3s 284us/step - loss: 0.0900 - acc: 0.1133
Epoch 5/20
10000/10000 [==============================] - 3s 290us/step - loss: 0.0900 - acc: 0.1105
Epoch 6/20
10000/10000 [==============================] - 3s 286us/step - loss: 0.0900 - acc: 0.1120
Epoch 7/20
10000/10000 [==============================] - 3s 316us/step - loss: 0.0900 - acc: 0.1098
Epoch 8/20
10000/10000 [==============================] - 3s 306us/step - loss: 0.0900 - acc: 0.1117
Epoch 9/20
10000/10000 [==============================] - 3s 294us/step - loss: 0.0900 - acc: 0.1102
Epoch 10/20
10000/10000 [==============================] - 3s 296us/step - loss: 0.0899 - acc: 0.1129
Epoch 11/20
10000/10000 [==============================] - 3s 334us/step - loss: 0.0899 - acc: 0.1153
Epoch 12/20
10000/10000 [==============================] - 3s 307us/step - loss: 0.0899 - acc: 0.1141
Epoch 13/20
10000/10000 [==============================] - 4s 351us/step - loss: 0.0899 - acc: 0.1137 0s - loss: 0.089
Epoch 14/20
10000/10000 [==============================] - 3s 321us/step - loss: 0.0899 - acc: 0.1157
Epoch 15/20
10000/10000 [==============================] - 3s 302us/step - loss: 0.0899 - acc: 0.1156
Epoch 16/20
10000/10000 [==============================] - 3s 323us/step - loss: 0.0899 - acc: 0.1159 1s -
Epoch 17/20
10000/10000 [==============================] - 3s 331us/step - loss: 0.0899 - acc: 0.1141
Epoch 18/20
10000/10000 [==============================] - 3s 299us/step - loss: 0.0899 - acc: 0.1234
Epoch 19/20
10000/10000 [==============================] - 3s 316us/step - loss: 0.0899 - acc: 0.1143
Epoch 20/20
10000/10000 [==============================] - 3s 337us/step - loss: 0.0899 - acc: 0.1236
10000/10000 [==============================] - 2s 246us/step
TEST ACC: 0.1028可以调一下units的参数值,可以再多加几层,尝试一下效果并不是很好,之后章节会对这个代码进行优化。














 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









