








1.Introduction
做目标检测时,用LabelImg生成的 xml 文件需要和对应的图片文件名,生成VOC格式列表。同时需要按照一定比例划分为训练集、验证集和测试集。
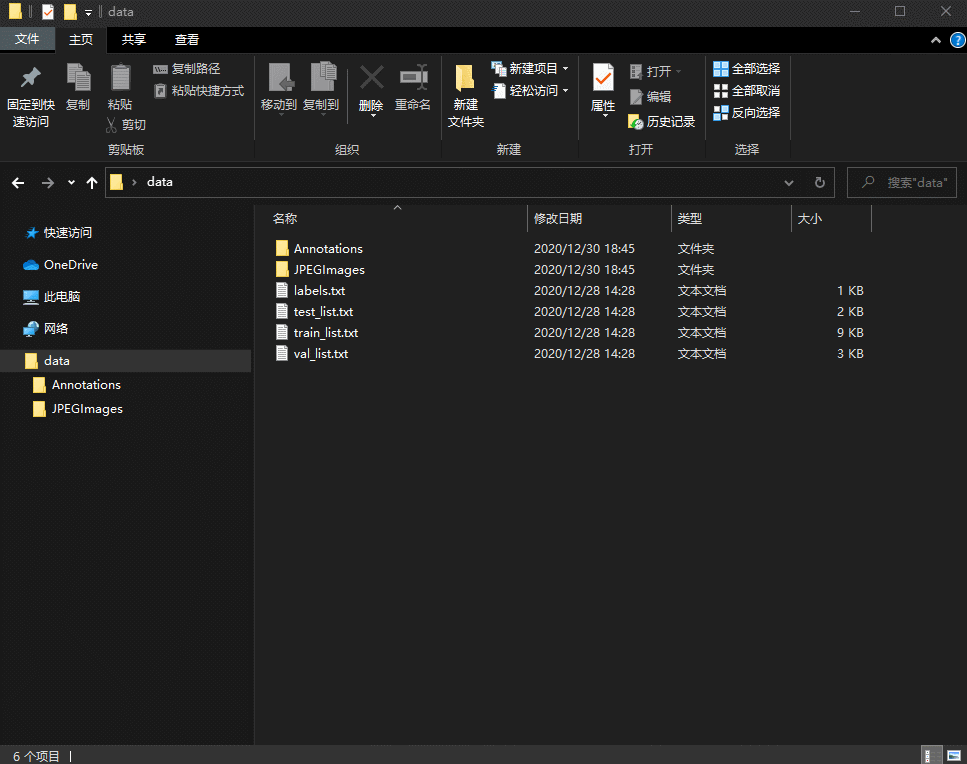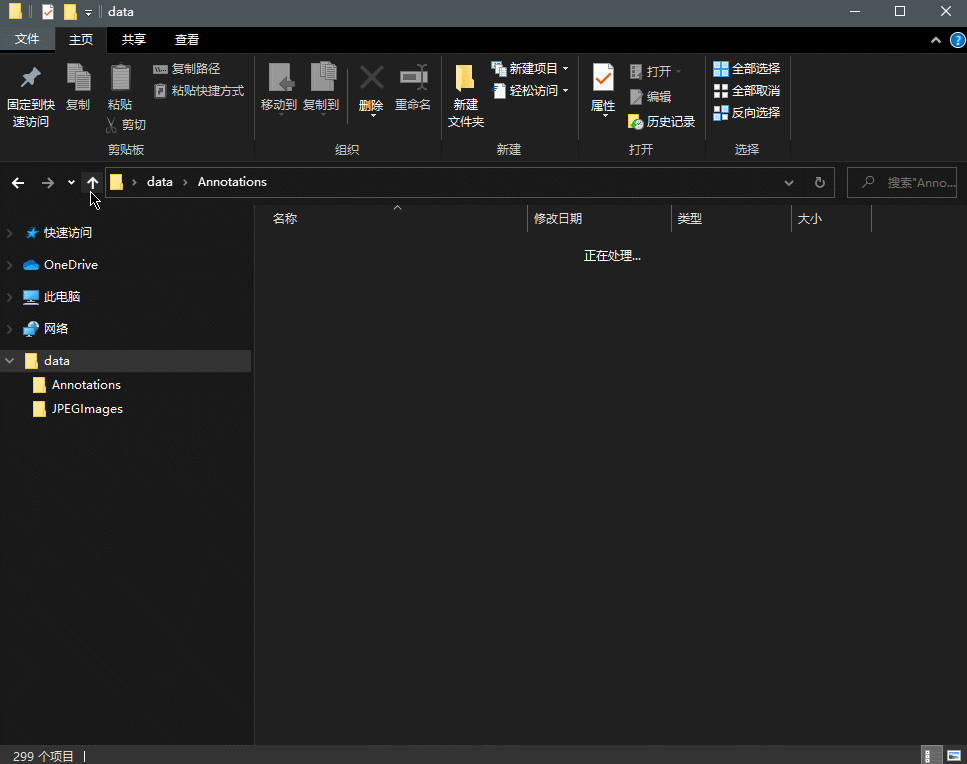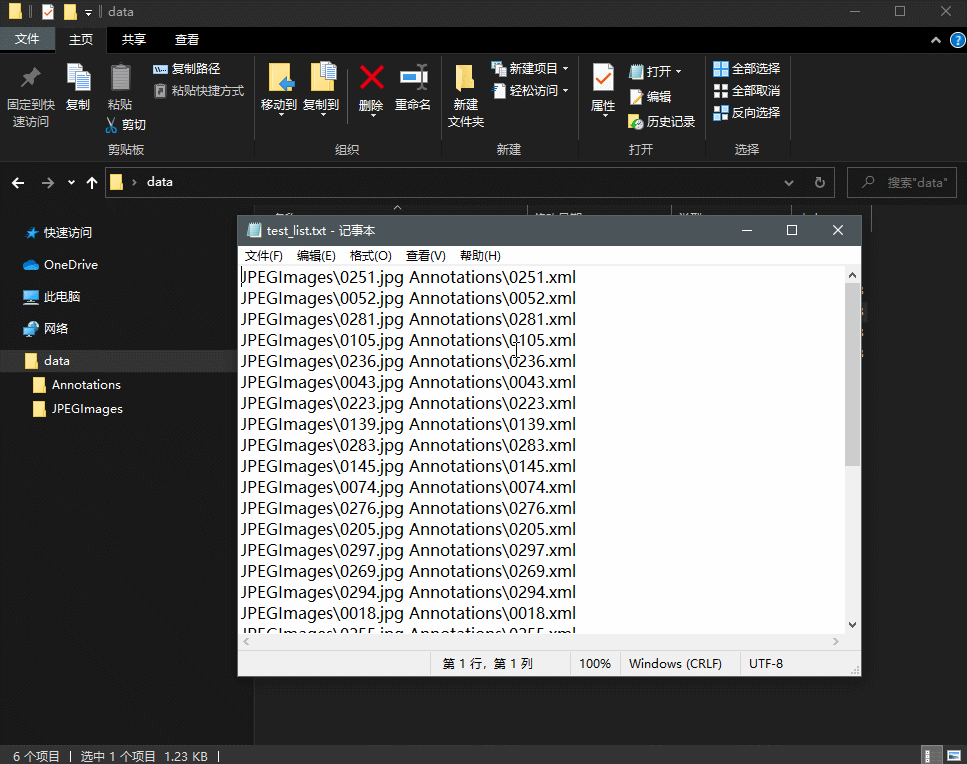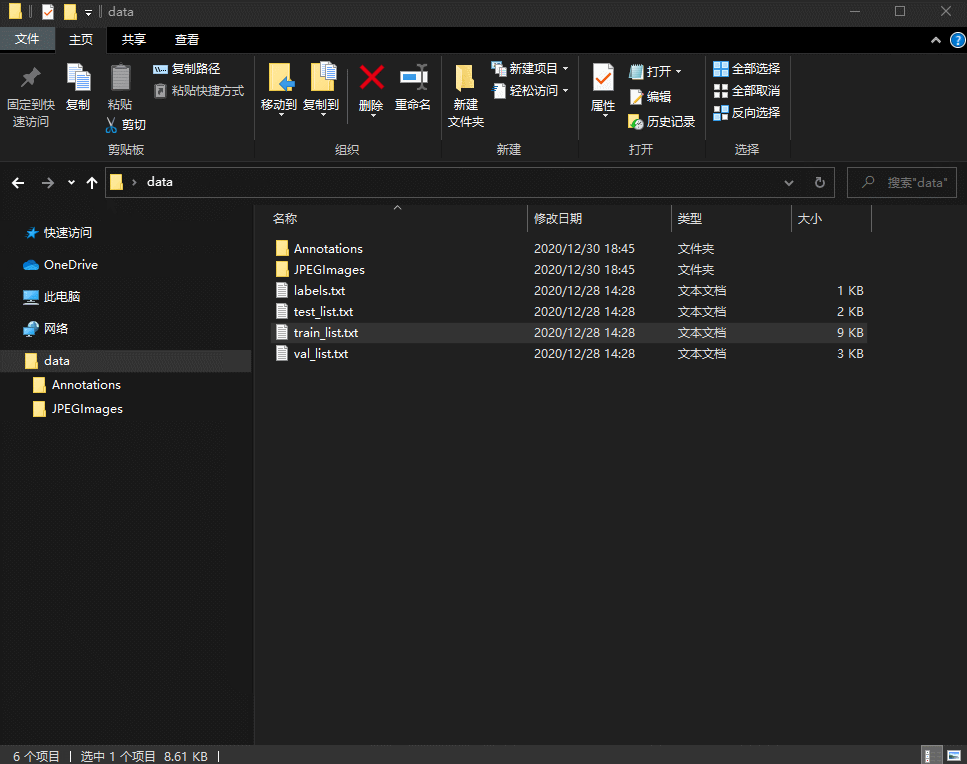
2.Materials and methods
上述功能可以分为四步:
(1)读取图片名或者xml文件名(这俩一样)
(2)对文件名列表打乱顺序
(3)按比例从乱序表中抽取文件名
(4)拼接字符串,写入txt文件
话不多说,上代码:
# -*- coding: utf-8 -*-
"""
Created on Wed Dec 30 14:49:41 2020
@author: YaoYee
"""
import os
import random
READ_DIR = 'C:/Users/YaoYee/Desktop/data/Annotations'
WRITE_DIR = 'C:/Users/YaoYee/Desktop/data'
TRAIN_RATIO = 0.7
VAL_RATIO = 0.2
TEST_RATIO = 0.1
imgs = os.listdir(READ_DIR)
# Shuffle list imgs in place.
random.shuffle(imgs)
with open(WRITE_DIR+'/train_list.txt', 'w') as f:
for im in imgs[0:int(len(imgs)*TRAIN_RATIO)]:
info = 'JPEGImages/'+im+' '
info += 'Annotations/'+im[0:4]+'.xml\n'
f.write(info)
with open(WRITE_DIR+'/val_list.txt', 'w') as f:
for im in imgs[int(len(imgs)*TRAIN_RATIO):int(len(imgs)*(TRAIN_RATIO+VAL_RATIO))]:
info = 'JPEGImages/'+im+' '
info += 'Annotations/'+im[0:4]+'.xml\n'
f.write(info)
with open(WRITE_DIR+'/test_list.txt', 'w') as f:
for im in imgs[int(len(imgs)*(TRAIN_RATIO+VAL_RATIO)):]:
info = 'JPEGImages/'+im+' '
info += 'Annotations/'+im[0:4]+'.xml\n'
f.write(info)
print('The data length is:', len(imgs))
print('The train_data length is:', int(len(imgs)*TRAIN_RATIO))
print('The val_data length is:', int(len(imgs)*(TRAIN_RATIO+VAL_RATIO))-int(len(imgs)*TRAIN_RATIO))
print('The test_data length is:', len(imgs)-int(len(imgs)*(TRAIN_RATIO+VAL_RATIO)))
如果想按原顺序划分数据集,在代码中把下面行注释掉就行了~
#random.shuffle(imgs)
3. Results and discussion
运行下看看效果~
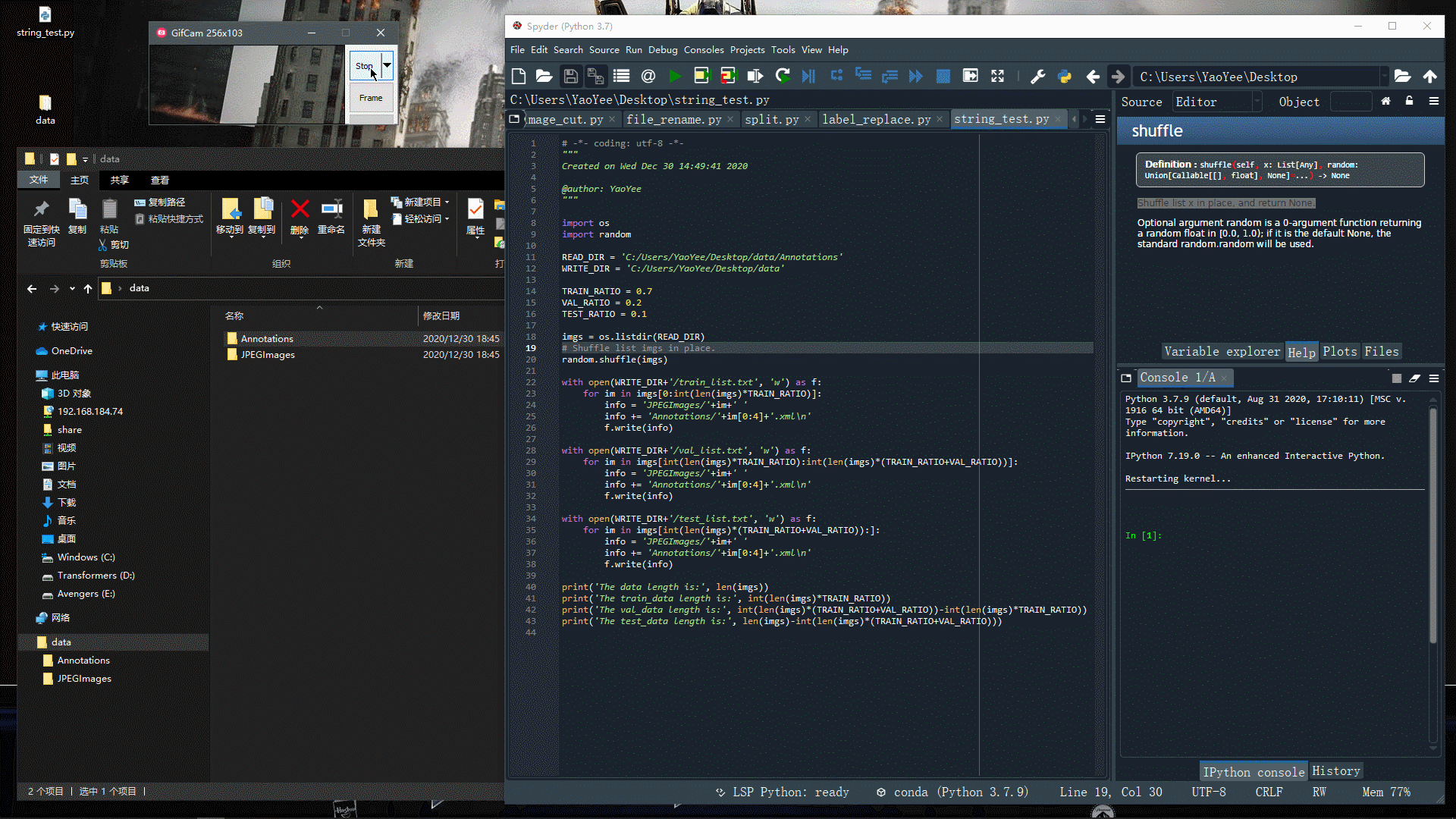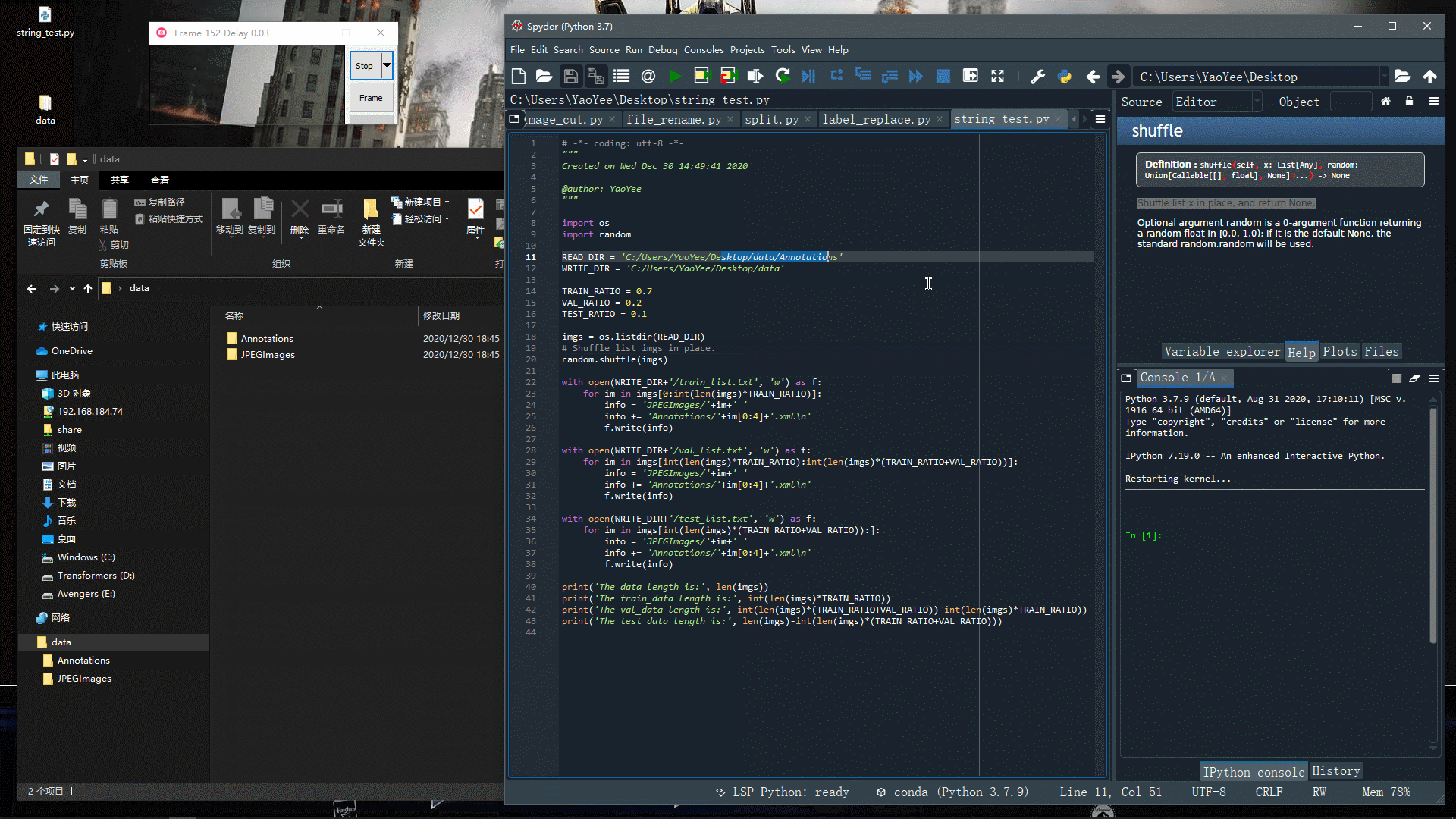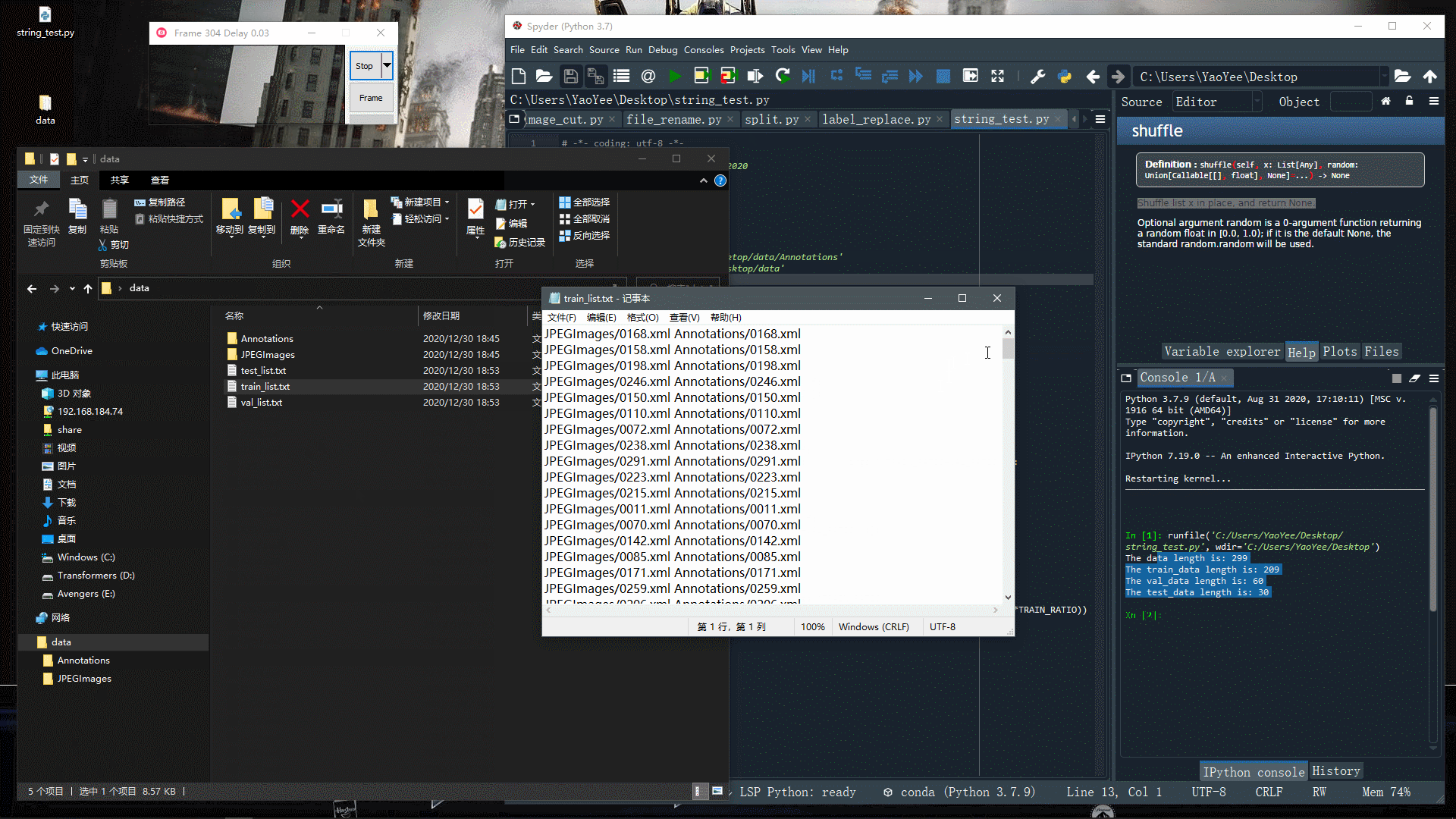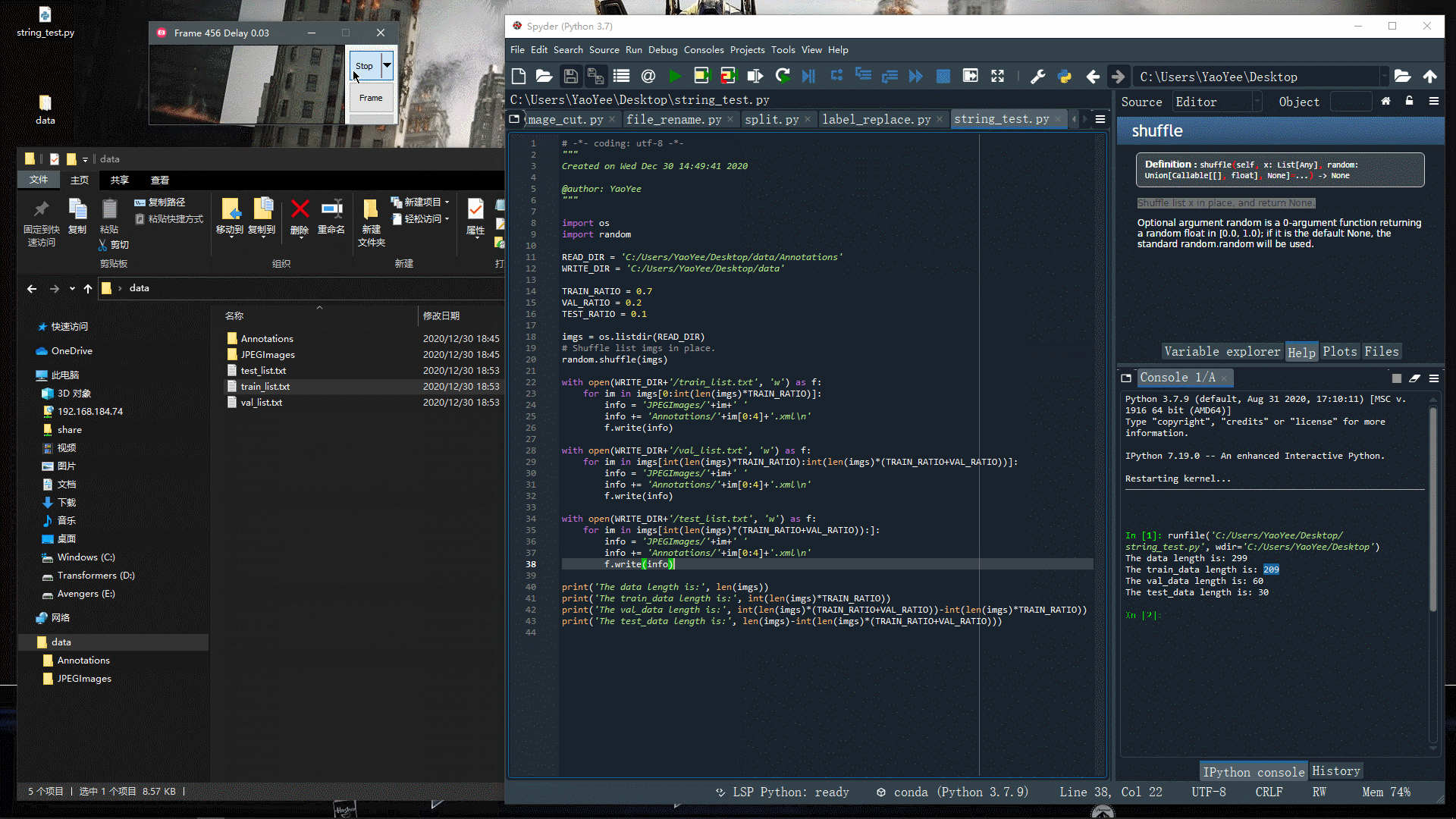
可以发现,效果还是很好的,不过细心的小伙伴可能发现了,这里并没有生成Label文件,也就是没有读取xml文件里的label信息,本文暂时不涉及这块(后面再说)。
如果用paddle的话,官方已经实现了划分+读取标签,可直接调用,如下:
import paddlex
!paddlex --split_dataset --format VOC --dataset_dir C:\Users\YaoYee\Desktop\data --val_value 0.2 --test_value 0.1
4. Conclusion
Python真好用~
猜你喜欢:👇🏻
⭐【Python】如何在文件夹里批量分割图片?
⭐【Python】如何在文件夹里批量替换文本中的内容?
⭐【Python】如何在文件夹里批量修改文件名?(0001-1000)
















 3696
3696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









