







文章目录
前言
-
行政区划信息抽取算法,简称区划抽取
-
本文区划仅针对中国(缺港澳台,2020年国家统计局更新,2019年数据):
http://www.stats.gov.cn/tjsj/tjbz/
http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/index.html

必备常识
- 行政区划:是行政区域划分的简称,是国家为了进行分级管理而实行的区域划分。
| 等级 | 详情(2019年,每年会有更新,以更新为准,不要参考此处) | 合计 |
|---|---|---|
| 省级行政区 | 23个省、5个自治区、4个直辖市、2个特别行政区 | 34 |
| 地级行政区 | 293个地级市、7个地区、30个自治州、3个盟 | 333 |
| 县级行政区 | 965个市辖区、387个县级市、1323个县、117个自治县、49个旗、3个自治旗、1个特区、1个林区 | 2846 |
| 乡级行政区 | 8516个街道、20975个镇、8122个乡、966个民族乡、153个苏木、1个民族苏木、1个县辖区 | 38734 |
- 省级行政区划
| 区划代码(前2位) | 省级行政区 | 简称 | 行政中心 | 区划代码(前2位) | 省级行政区 | 简称 | 行政中心 |
|---|---|---|---|---|---|---|---|
| 11 | 北京市 | 京 | 北京 | 43 | 湖南省 | 湘 | 长沙 |
| 12 | 天津市 | 津 | 天津 | 44 | 广东省 | 粤 | 广州 |
| 13 | 河北省 | 冀 | 石家庄 | 45 | 广西壮族自治区 | 桂 | 南宁 |
| 14 | 山西省 | 晋 | 太原 | 46 | 海南省 | 琼 | 海口 |
| 15 | 内蒙古自治区 | 内蒙古 | 呼和浩特 | 50 | 重庆市 | 渝 | 重庆 |
| 21 | 辽宁省 | 辽 | 沈阳 | 51 | 四川省 | 川、蜀 | 成都 |
| 22 | 吉林省 | 吉 | 长春 | 52 | 贵州省 | 贵、黔 | 贵阳 |
| 23 | 黑龙江省 | 黑 | 哈尔滨 | 53 | 云南省 | 云、滇 | 昆明 |
| 31 | 上海市 | 沪 | 上海 | 54 | 西藏自治区 | 藏 | 拉萨 |
| 32 | 江苏省 | 苏 | 南京 | 61 | 陕西省 | 陕、秦 | 西安 |
| 33 | 浙江省 | 浙 | 杭州 | 62 | 甘肃省 | 甘、陇 | 兰州 |
| 34 | 安徽省 | 皖 | 合肥 | 63 | 青海省 | 青 | 西宁 |
| 35 | 福建省 | 闽 | 福州 | 64 | 宁夏回族自治区 | 宁 | 银川 |
| 36 | 江西省 | 赣 | 南昌 | 65 | 新疆维吾尔自治区 | 新 | 乌鲁木齐 |
| 37 | 山东省 | 鲁 | 济南 | 71 | 台湾省 | 台 | 台北 |
| 41 | 河南省 | 豫 | 郑州 | 81 | 香港特别行政区 | 港 | 香港 |
| 42 | 湖北省 | 鄂 | 武汉 | 82 | 澳门特别行政区 | 澳 | 澳门 |
极简代码示例
from jieba.posseg import dt # 带词性分词
dt.tokenizer.add_word('禅城区', 9, 'ns') # 地名词库加载
text = '''
广东省佛山市南海区桂城街道地处南海区东南部,西部与禅城区祖庙街道、南部与禅城区石湾镇街道、顺德区陈村镇接壤
'''.strip()
print(set(i.word for i in dt.cut(text)if i.flag == 'ns')) # 带词性分词
-
print
- {‘顺德区’, ‘佛山市’, ‘南海区’, ‘广东省’, ‘桂城’, ‘禅城区’, ‘石湾镇’}
特殊数据处理
歧义名称
不知所云的名称,直接抛弃
exclusion = {'市辖区', '县', '省直辖县级行政区划'}
例如【郊区】一词有歧义,可用【阳泉市郊区、佳木斯市郊区、铜陵市郊区】来替代
exclusion = {'城区', '郊区', '矿区', '东区', '西区'}
重名
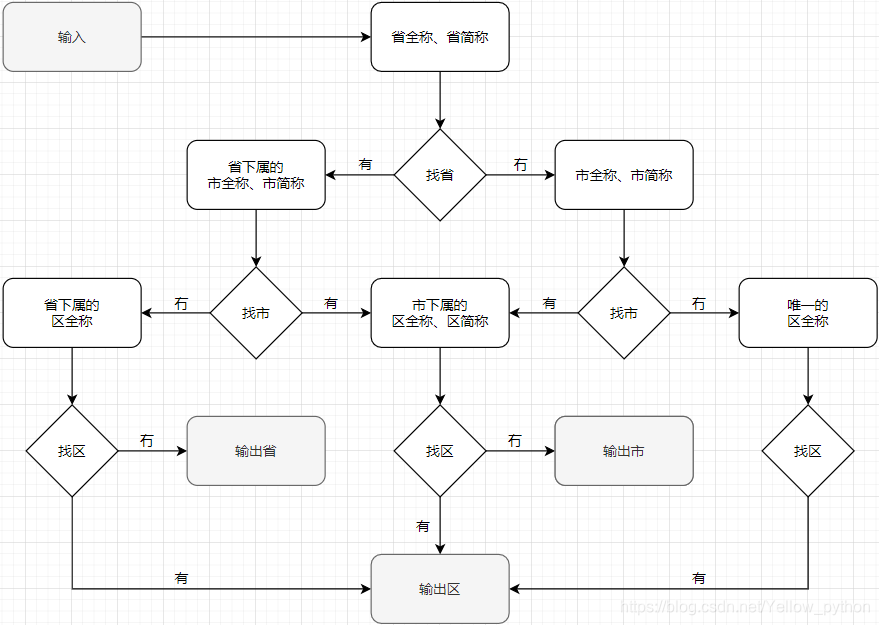
- 省级和市级的行政区划没有重名,区级和县级的行政区划有重名,遇到重名要进一步从文本中查找其上级区划来消除歧义
消歧方法1:层级查找(荐给Java用)
消歧方法2:根据区划代码前缀 设置权重(荐给Python用)
from jieba.posseg import dt # 带词性分词
name2code = {'白云区': {'440111': .6, '520113': .4}, '广州市': {'4401': 1}, '贵阳市': {'5201': 1}}
dt.tokenizer.add_word('白云区', tag='ns')
def similarity(a, b):
"""
佛山市 match 南海区 = 50%
禅城区 match 南海区 = 0%
"""
if a == b:
return 0
la, lb, score = len(a), len(b), 0
for i in range(min(la, lb)):
if a[i] == b[i]:
score += 1
else:
break
return score / (la + lb)
def extract(text):
# 识别区划名称,取集合(或计数器)
s = set(i.word for i in dt.cut(text)if i.flag == 'ns')
# 区划名称转区划代码
ls = [(code, score) for name in s for code, score in name2code[name].items()]
# 权值计算并排序
ls = sorted([(c1, sum(similarity(c1, c2) for c2, s2 in ls)+s1) for c1, s1 in ls], key=lambda x: x[1], reverse=True)
# 返回最长区划码
return max(ls, key=lambda x: len(x[0]))[0]
text1 = '广州市的白云区'
text2 = '贵阳市的白云区'
print(text1, extract(text1))
print(text2, extract(text2))
-
print
-
广州市的白云区 440111
贵阳市的白云区 520113
后缀
有时有些区划不使用全称而使用简称,例如:佛山(佛山市)、宁夏(宁夏回族自治区)等,此时就要识别简称来获取区划代码
后缀名称
suffix = [
'特别行政区', '民族苏木', '自治区', '自治州', '自治县', '自治旗', '民族乡', '地区',
'特区', '林区', '街道', '苏木', '省', '市', '盟', '区', '县', '旗', '镇', '乡']
去掉后缀
PROVINCE_ABBR={'北京':'北京市','山西':'山西省','云南':'云南省','河北':'河北省','西藏':'西藏自治区','宁夏':'宁夏回族自治区',
'安徽':'安徽省','重庆':'重庆市','青海':'青海省','山东':'山东省','湖南':'湖南省','江西':'江西省','广西':'广西壮族自治区',
'甘肃':'甘肃省','陕西':'陕西省','海南':'海南省','黑龙江':'黑龙江省','上海':'上海市','辽宁':'辽宁省','吉林':'吉林省',
'贵州':'贵州省','福建':'福建省','江苏':'江苏省','广东':'广东省','内蒙古':'内蒙古自治区','河南':'河南省','四川':'四川省',
'浙江':'浙江省','天津':'天津市','新疆':'新疆维吾尔自治区','湖北':'湖北省'}
_CITY_ABBR={'武威','荆门','宿州','亳州','洛阳','邵阳','郑州','眉山','赤峰','阜新','岳阳','衡水','贵阳','榆林','聊城','南平',
'枣庄','随州','泰州','长春','梅州','百色','淮南','白银','珠海','内江','铜川','丹东','三亚','商洛','滨州','株洲','绥化',
'宁波','钦州','扬州','沈阳','新余','宣城','铁岭','许昌','潮州','昌都','舟山','双鸭山','松原','阳泉','鸡西','徐州','白山',
'赣州','鹤岗','黄冈','阜阳','东营','遵义','焦作','桂林','承德','海口','西宁','荆州','昆明','林芝','宜宾','汕尾','韶关',
'咸宁','河池','延安','南昌','益阳','宿迁','巴彦淖尔','葫芦岛','吐鲁番','惠州','开封','银川','营口','芜湖','阳江','漯河',
'伊春','黄山','湘潭','朔州','濮阳','牡丹江','张家界','萍乡','宁德','烟台','黑河','大庆','临沂','太原','云浮','绵阳','庆阳',
'汕头','那曲','哈密','杭州','衢州','广州','锦州','南通','镇江','嘉兴','宜昌','鹰潭','广安','乌鲁木齐','毕节','酒泉','铜仁',
'青岛','玉林','周口','天水','唐山','七台河','吕梁','济南','石家庄','深圳','柳州','德阳','衡阳','拉萨','无锡','襄阳','自贡',
'大连','丽水','九江','来宾','日照','安顺','西安','威海','孝感','景德镇','临沧','河源','陇南','池州','秦皇岛','滁州','保定',
'盐城','定西','铜陵','厦门','常德','鞍山','白城','贵港','合肥','资阳','信阳','金昌','菏泽','南阳','邯郸','茂名','南充',
'呼伦贝尔','上饶','金华','吉安','台州','中卫','曲靖','雅安','张掖','广元','朝阳','黄石','鄂州','张家口','佳木斯','渭南',
'克拉玛依','汉中','龙岩','巴中','湖州','肇庆','永州','莆田','常州','泰安','沧州','平顶山','新乡','六盘水','十堰','长治',
'海东','南京','清远','辽源','安康','鹤壁','佛山','吴忠','石嘴山','潍坊','忻州','邢台','包头','济宁','遂宁','呼和浩特',
'温州','兰州','晋城','晋中','四平','淮安','泉州','江门','娄底','三门峡','贺州','崇左','乐山','通化','通辽','马鞍山','德州',
'平凉','吉林','宜春','揭阳','梧州','山南','辽阳','安阳','苏州','东莞','乌海','郴州','南宁','防城港','玉溪','昭通','盘锦',
'六安','安庆','淄博','抚顺','武汉','嘉峪关','攀枝花','廊坊','鄂尔多斯','漳州','本溪','连云港','泸州','固原','绍兴','中山',
'蚌埠','达州','福州','商丘','三沙','齐齐哈尔','怀化','丽江','抚州','湛江','日喀则','临汾','咸阳','长沙','运城','淮北',
'大同','宝鸡','哈尔滨','成都','乌兰察布','普洱','北海','三明','儋州','保山','驻马店'}
CITY_ABBR={i:i+'市'for i in _CITY_ABBR}
去后缀的坑
白云机场不在白云区,而在花都区
黄埔大道不在黄浦区,而在天河区
海珠广场不在海珠区,而在越秀区
数据下载
直接下载
2019年数据(2020年出)下载地址(CSDN资源,免积分,下载好了点个赞哈😓):
https://download.csdn.net/download/Yellow_python/12469089
使用爬虫
直接复制可用,存excel,需要半天时间
request
import requests
from random import choice
from time import strftime, sleep
UA = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
'Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0;',
'Mozilla/4.0(compatible;MSIE8.0;WindowsNT6.0;Trident/4.0)',
]
red = lambda x: print('\033[91m', x, '\033[0m', sep='')
yellow = lambda x: print('\033[93m', x, '\033[0m', sep='')
def write_log(*args):
with open(strftime('%Y%m%d')+'.txt', 'a', encoding='utf-8') as f:
for a in args:
red(a)
f.write('{}\n'.format(a))
f.write('\n')
sleep(1) # 减速
def get(url, encode='gb2312', times=50):
if times < 0:
write_log(url, times)
return ''
try:
r = requests.get(url, headers={'User-Agent': choice(UA)}, timeout=30)
except Exception as e:
write_log(url, e, times)
return get(url, encode, times - 1)
if r.status_code == 200:
r.encoding = encode
return r.text
else:
write_log(url, r.status_code, times)
return get(url, encode, times - 1)
if __name__ == '__main__':
print(get('http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/', 'utf-8'))
spider
"""
国家统计局:统计用区划和城乡划分代码
http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/index.html 1级
http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/11.html 2级
http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/11/1101.html 3级
http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/11/01/110101.html 4级
http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/11/01/01/110101001.html 5级
http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/index.html 1级
http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/44.html 2级
http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/44/4419.html 3级
http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/44/19/441900003.html 5级
"""
from re import findall
from request import *
# 主页,按年份调整
HOMEPAGE = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/index.html'
# 网址前缀
PREFIX = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/'
# 数据存储列表
ls_of_ls = []
def lv5(url):
"""乡级"""
html = get(url)
# yellow(html)
for code, other, name in findall("<td>([0-9]{12})</td><td>([0-9]{3})</td><td>([\u4e00-\u9fa5]+)</td>", html):
print(code, name, other)
ls_of_ls.append([code, name, other])
def lv4(prefix):
"""县级 -> 乡级"""
html = get(prefix)
# yellow(html)
prefix = prefix[:-11]
for suffix, code, name in findall("<a href='([0-9]{2}/([0-9]{6,9})[.]html)'>([\u4e00-\u9fa5]+)</a>", html):
url = prefix + suffix
print(code, name, url)
ls_of_ls.append([code, name, url])
lv5(url)
def lv3(prefix):
"""地级 -> 县级or乡级"""
html = get(prefix)
# yellow(html)
prefix = prefix[:-9]
for suffix, code, name in findall("<a href='([0-9]{2}/([0-9]{6,9})[.]html)'>([\u4e00-\u9fa5]+)</a>", html):
url = prefix + suffix
print(code, name, url)
ls_of_ls.append([code, name, url])
if len(code) == 6:
lv4(url)
elif len(code) == 9:
lv5(url)
else:
write_log(code, name, url)
def lv2(url):
"""省级 -> 地级"""
html = get(url)
# yellow(html)
for suffix, code, name in findall("<a href='([0-9]{2}/([0-9]{4})[.]html)'>([\u4e00-\u9fa5]+)</a>", html):
url = PREFIX + suffix
print(code, name, url)
ls_of_ls.append([code, name, url])
lv3(url)
def lv1():
"""省级"""
html = get(HOMEPAGE)
# yellow(html)
for suffix, code, name in findall("<a href='(([0-9]{2})[.]html)'>([\u4e00-\u9fa5]+)[^\u4e00-\u9fa5]*?</a>", html):
url = PREFIX + suffix
print(code, name, url)
ls_of_ls.append([code, name, url])
lv2(url)
def run():
try:
lv1()
except Exception as e:
write_log(e)
with open('region.txt', 'w', encoding='utf-8') as f:
for ls in ls_of_ls:
f.write(','.join(ls) + '\n')
from pandas import DataFrame
DataFrame(ls_of_ls, columns=['code', 'name', 'others']).to_excel('region.xlsx', index=False)
if __name__ == '__main__':
# lv3('http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/44/4406.html') # 佛山
# lv3('http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2019/44/4419.html') # 东莞
run()


















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











