






一篇增粉文:
请大家关注我的公众号,文末可以扫码:
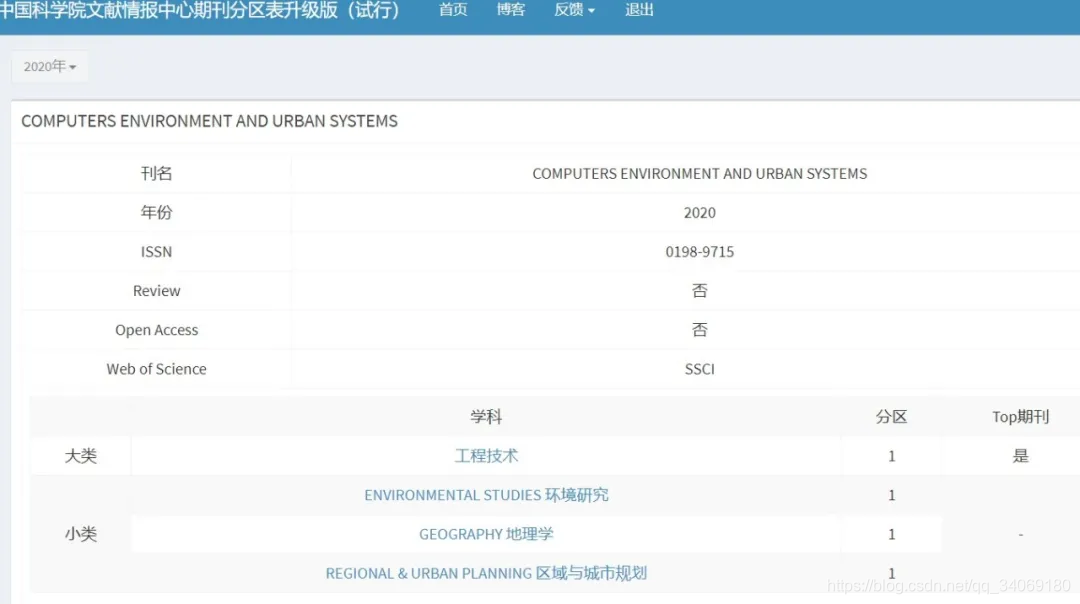
协同感知与知识服务
不定期推送GIS相关的研究,也可以与我交流。
给大家分享一篇最新录用在CEUS的一篇文章。

这篇文章的灵感来源于博士入学前的暑假,因为疫情原因延迟开学,在家里收集了疫情期间的新浪微博数据,想着能不能做一些工作可以让GIS在这场与疫情的战役中体现价值。我整理收集好的数据,有着林林种种的观点表达,映射世间百态,既有对国家抗疫政策以及医护人员的力挺,也有很多对疫情期间各种事件的评论,许多医疗资源的求助信息也包含其中。作为一个GISer,我很敏感的发现这些微博很多都是不含有地理属性的,也就是说从这些数据中你无法定位发博者的地理位置,现有很多方法可以利用NER的方式来探测文本中的地理位置信息,然而大部分微博是不含有对位置的描述的,我抓取的20多万条数据仅有5000条含有可用位置信息,分布在武汉市1000多个兴趣点上。我考虑能否利用文本中的语义信息对这些微博进行分类,基于一个假设:在同一个位置或同一类位置微博关注内容是类似的。我认为用户在武汉黄鹤楼的微博内容与在武汉江汉关的微博内容是具有一定相似性的,即他们都含有旅游观光的属性。应该会与在火车站or汽车站位置发送的微博有着显著的语义区别。社会感知的主体是人,诚然我们无法避免一些误差,但是在样本丰富的情况下,我认为还是具有一定的甄别可能。文末提供了文章的下载连接以及round1审稿人的意见与我的回复,整整写了快30页,希望对大家有参考。此外本文还感谢刘瑜教授给的大修机会。
社会感知是通过从海量的志愿信息数据中提取可靠的信息来研究人与空间的互动关系的一种分析方法。在COVID-19大流行期间,有大量的互联网社会感知数据。然而,其中大部分数据缺乏地理属性。为了解决这一问题,本文提出了一种基于关键词提取和相似实体对齐的卷积神经网络地理分类模型(KE-CNN),该模型可以通过提取文本数据中的语义特征来确定地理属性。此外,我们通过捕捉大量人群的时空行为,对大流行期间的虚拟世界与现实世界的社会动态进行感知,构建了共词复杂网络。我们的模型与传统的机器学习方法相比,准确率提高了5%~15%。可以有效建立医疗、餐饮、火车站、教育等各类文本的地理特征集,补充缺失的空间数据标签,实现地理空间上无缝社会感知。
▼
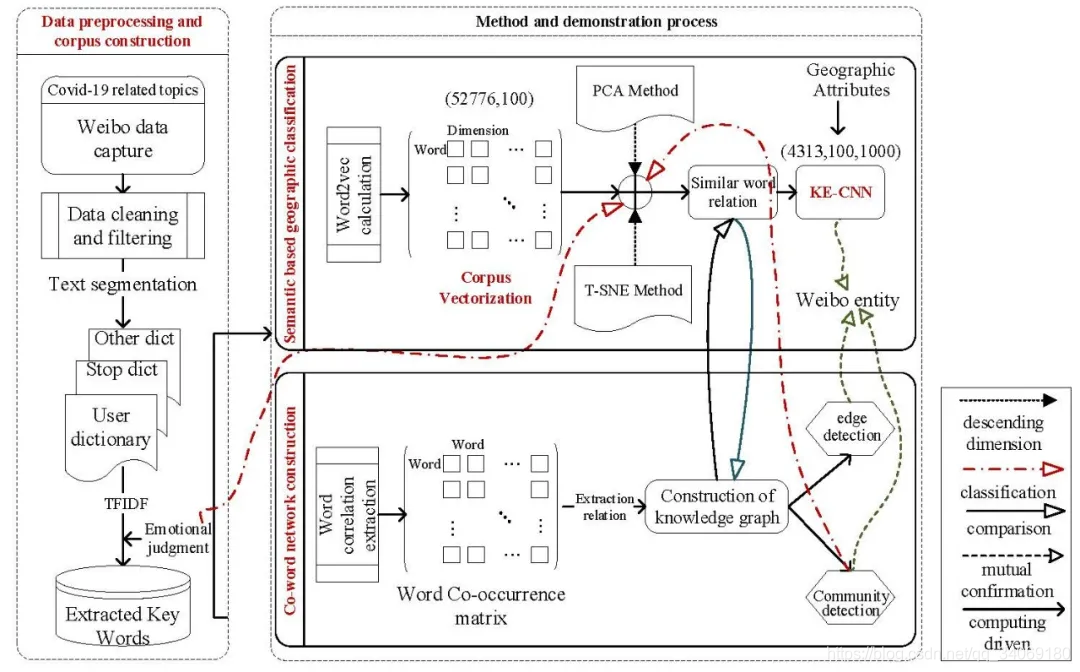
文章技术路线
社会感知可以从庞大的地理空间数据中提取社会经济、文化、生活等方面的特征和动态。社会中的每一个人都扮演着传感器的角色,对周围环境进行实时反馈。智能设备的普及和5G技术的发展,促进了 "社会感知 "数据的获取。与传统的数据采集方式相比,智能设备提供的在线 "众包 "数据具有量大、速度实时、覆盖面广等特点。社会感知可以通过捕捉空间行为模式,以人作为最小的颗粒度单位,显示社会特征的某些方面,主要包括对地理环境的感受、地理空间的活动和运动;以及个人之间的社会关系。与其他数据源相比,社会传感数据有两个明显的优势。1)可以准确捕捉社会经济特征;2)这些数据的传感器是人。
现有的研究已经证明,社会传感可以观察自然灾害或公共卫生事件,并利用基于位置的社交媒体(LBSM)数据检测真实世界的事件。社会传感还被应用于地震、洪水、台风、流感和城市贫困等灾害应对和恢复。然而,大量的社会传感数据(本文主要指地理社会媒体数据)不具备地理位置信息,使得数据无法使用。
地理属性指的是社交媒体文本背后嵌入的位置信息,这种位置信息不是详细的地址信息,而是功能位置。与传统的基于字典匹配或称为实体识别从文本中提取详细位置信息的方法不同,本文提出了一种基于神经网络的方法来发现文本中嵌入的地理语义信息。即使在社交媒体文本中不存在描述位置的相关词语,所提出的方法仍然可以通过词语在文本中出现的概率或不同词语的共现概率来推断其背后的地址类型(地理属性)。所提出的方法将每个词以及不同词之间的组合作为一个观察值,并根据这些观察值进行推断。
Q1
研究问题
(RQ1):在疫情期间,武汉市封城举措对居民的情绪变化产生了怎样的影响。
(RQ2):考虑到社交媒体平台上日益严格的隐私保护,在文本中没有地址描述的情况下(即无法利用NER进行地址提取),如何通过词的出现频率和共词关系来推断社交媒体文本的地理属性?
利用社会感知,可以识别城市中不同类型的潜在主题,从而确定城市的功能区。此外,社会感知传感还可以通过利用社交媒体平台上隐含的明确位置足迹和挖掘潜在的人口信息,来研究人类流动的时空特征。除了科研之外,商业公司也提供使用社会传感的产品。社交传感在提供土地利用类型的高频更新、周边交通拥堵状态的实时感知(如谷歌地图、腾讯宜出行人口热力图)、人口分布细粒度的评估等方面是最被广泛认可的活跃工具。
许多学者利用社会感知方法对疫情防控进行了深刻的尝试:如对不同用户群体关注的话题进行及时研究,从社交媒体数据中提取预警信息,利用社交媒体快速识别COVID-19确诊病例,根据疫情数据确定城市风险区域,并通过互联网快速颁布信息。某些学者建立了实时的社会传感和分析系统,收集和流通COVID-19传播数据,并提供风险预警。
为了分析社会传感系统获取的社会媒体数据,最常用的是(LDA)主题建模方法,它将社会媒体文本解析为三层结构的单词文档主题。某些研究者认为,可以将每个文档特征视为一个独立的传感器。在本文中,语料经过深度学习训练后,用一个高维矩阵表示。矩阵的每个维度都可以被认为是一个传感器,以测量一个(可能是抽象的、未知的或无意义的)地理语义的信号。
由LDA表示的主题模型可以从许多文档中自动发现隐含的主题结构,而无需事先了解。利用聚类算法和话题模型对地理标签推文进行分析,研究事件的时空模式,识别语义内容。同样,主题模型也被用来描述灾难性事件的时空特征,从而进行风险评估。在城市功能的研究中也采用了同样的方法,将每个POI视为一个词,将采样地点周围的POI视为一个文档,并为采样地点赋予不同的功能属性。此外,某些学者还利用无监督神经网络方法对Twitter数据的时空和语义聚类进行了探索。通过构建本体模型与地名索引来研究从网络文档(新闻报道)中提取语义信息。
在从社交媒体文本中提取地理属性方面,上述研究有两个不足之处。LDA方法是一种无监督的分类模型,城市功能的提取结果与真实的分类标准不同。此外,这些方法需要预先准备好地名库,在社交媒体文本中进行识别。
我们的研究希望能够生成具有可解释性的基于既定标准的位置结果,而不是使用无监督训练方法生成聚类。我们将原始符号词空间的数据映射到特征空间中(例如,词法、句法、共现关系、出现频率和语义)。特征工程通常是一项繁重的任务,可能需要外部知识,而这些知识并不总是可用或难以获得。传统的文本特征工程有n-gram方法和独热编码方法,只能学习局部信息,我们利用词向量编码结果结合卷积神经网络(CNN)方法来学习更多的全局信息。
该方法分为以下几个步骤。
(1)社会感知数据的图结构化表示。
(2)社会感知数据的知识嵌入(embedding)。
(3)数据的实体对齐(相似替换)。
(4)融合知识的地理属性。
(5)训练KE-CNN分类器。
(6)地理推理与补全。
该方法的优点是可以提取语料的语义特征,并基于语义匹配地理位置类型。还可以将长度不确定的语料转换成CNN可识别的统一的格式(numpy矩阵)。

社会感知数据的图结构化表示
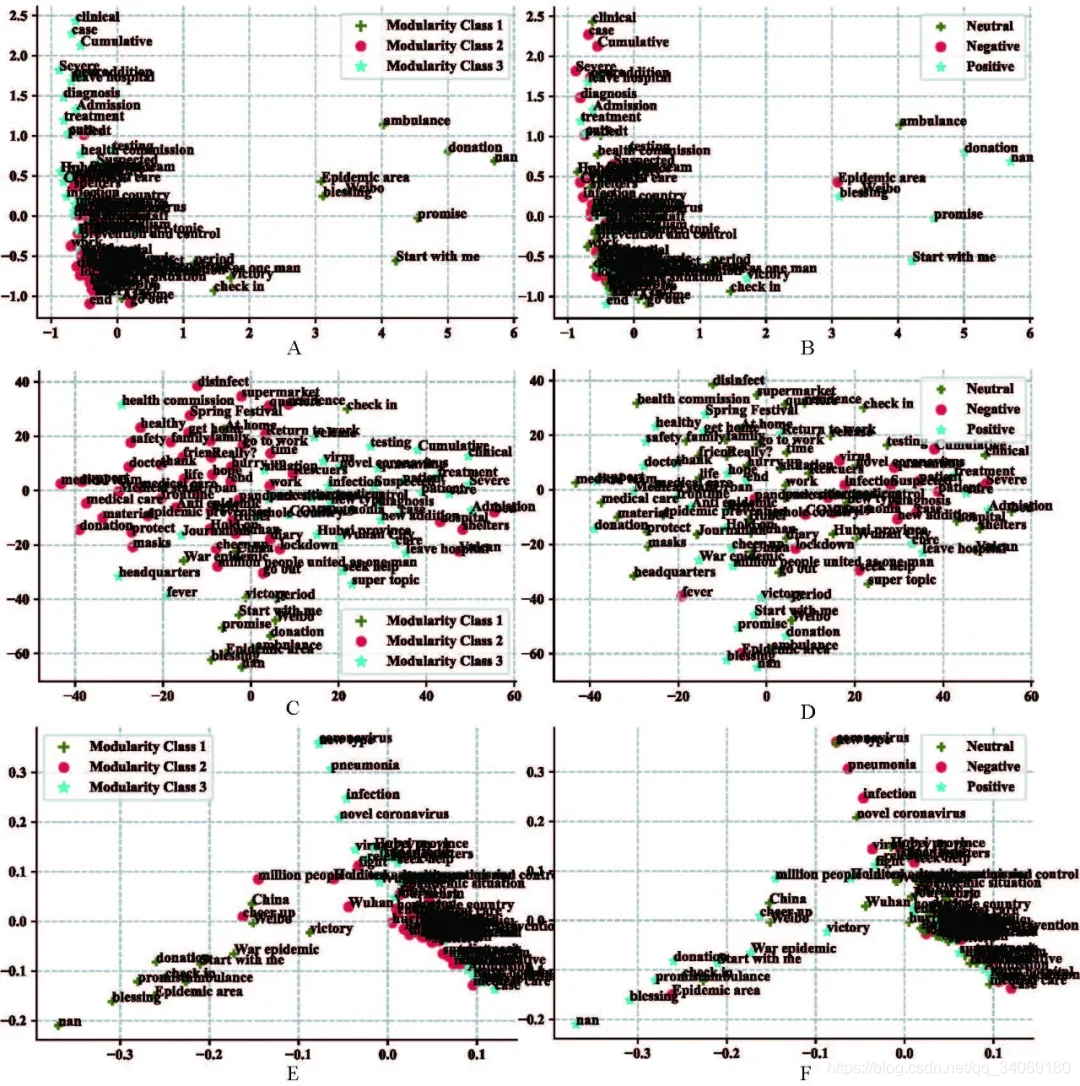
知识嵌入(embedding),依据复杂网络的社区划分算法与情感分类算法赋予标签
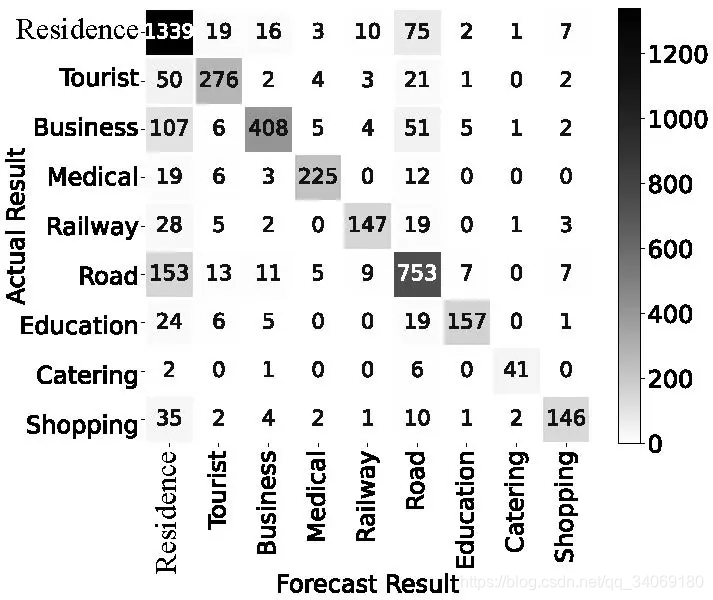
预测结果
我们利用本文提出的模型来绘制预测结果的混淆矩阵。例如,居住类的1339条微博被正确地归入了相应的土地利用类型;但有75条微博被错误地归入了道路和交通类型。矩阵的kappa系数为0.756。模型对居住类型的预测精度最低,其次是道路和交通类型的预测。因此,模型对道路和交通、居住、商业的预测能力较差,说明这些地区用户的Weibos并没有表现出相似的文本特征。例如,光谷步行街(武汉最著名的商圈之一)表现出多种特征属性。江汉路和范湖火车站具有道路与交通、商业、居住等属性,这无疑影响了模型的分类效果。本文提出的模型对医疗、餐饮、火车站、教育类型的预测准确率较高,说明具有这些地理特征的微博包含了丰富的文本特征属性。
经过统计,在本文抓取的20多万条微博中,只有约5%的微博含有地理属性;但利用本文提出的分类模型,我们可以对剩余95%的微博进行有效的地理属性标注,推理与补全。

文末福利:
1.Computers, Environment and Urban Systems 审稿意见与回复(Word)
2.文章下载链接
链接:https://pan.baidu.com/s/1_UVa1nSnXNTadN-2RLck-g
提取码:q49v

















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









