import os, re, sys
from nltk.corpus import wordnet # 过滤非英文单词,需要下载from collections import Counter
c = Counter()defextract_eng(text):global c
eng_ls = re.findall('[a-zA-Z]{5,}', text)
c += Counter([eng.lower()for eng in eng_ls if wordnet.synsets(eng)])deftraversal(path):for file_name in os.listdir(path):
extract_eng(file_name)# 收集文件名中的单词
abs_path = os.path.join(path, file_name)if os.path.isdir(abs_path):
traversal(abs_path)elif os.path.isfile(abs_path):print(abs_path)withopen(abs_path, encoding='utf-8')as f:try:
text = f.read()
extract_eng(text)# 收集文件中的单词except UnicodeDecodeError as e:print('\033[031m', e,'\033[0m')defshortest(ls=sys.path):
min_path ='_'*99for path in ls:iflen(path)<len(min_path):
min_path = path
return min_path
defmain():from time import time
import pandas as pd
t = time()
root = shortest()# Python安装目录
traversal(root)
most = c.most_common(30000)# 保存3万个词
pd.DataFrame(most).to_excel('words.xlsx', columns=['word','frequency'], index=False)print(time()- t)if __name__ =='__main__':
main()
1.2、算法拆解
1.2.1、递归遍历目录
import os
deftraversal(path):for file_name in os.listdir(path):
abs_path = os.path.join(path, file_name)if os.path.isdir(abs_path):
traversal(abs_path)elif os.path.isfile(abs_path):print(abs_path)
traversal(os.path.dirname(__file__))# 测试:遍历打印当前目录
1.2.2、词频统计
from collections import Counter
import jieba.posseg as jp
counter = Counter()
posseg = jp.cut(text)for p in posseg:"""自定义过滤条件"""
counter[(p.word, p.flag)]+=1
most = counter.most_common()print(most)# 写入Excelimport pandas as pd
pd.DataFrame([(m[0][0], m[0][1], m[1])for m in most], columns=['word','flag','frequency'])\
.to_excel('word_count.xlsx', index=None)
from nltk.corpus import wordnet # 可过滤非英文单词,需要下载
words =['python','ipython']for word in words:print(word,'is EN')if wordnet.synsets(word)elseprint(word,'is not EN')
1.2.5、英文停词过滤
# from nltk.corpus import stopwords# print(stopwords.words('english'))
stopwords =['i','me','my','myself','we','our','ours','ourselves','you',"you're","you've","you'll","you'd",'your','yours','yourself','yourselves','he','him','his','himself','she',"she's",'her','hers','herself','it',"it's",'its','itself','they','them','their','theirs','themselves','what','which','who','whom','this','that',"that'll",'these','those','am','is','are','was','were','be','been','being','have','has','had','having','do','does','did','doing','a','an','the','and','but','if','or','because','as','until','while','of','at','by','for','with','about','against','between','into','through','during','before','after','above','below','to','from','up','down','in','out','on','off','over','under','again','further','then','once','here','there','when','where','why','how','all','any','both','each','few','more','most','other','some','such','no','nor','not','only','own','same','so','than','too','very','s','t','can','will','just','don',"don't",'should',"should've",'now','d','ll','m','o','re','ve','y','ain','aren',"aren't",'couldn',"couldn't",'didn',"didn't",'doesn',"doesn't",'hadn',"hadn't",'hasn',"hasn't",'haven',"haven't",'isn',"isn't",'ma','mightn',"mightn't",'mustn',"mustn't",'needn',"needn't",'shan',"shan't",'shouldn',"shouldn't",'wasn',"wasn't",'weren',"weren't",'won',"won't",'wouldn',"wouldn't"]
1.3、结果可视化
2、单词翻译
2.1、代码
import requests, pandas as pd
from random import choice, randint
from time import sleep
UA =['Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0;',# IE9.0'Mozilla/4.0(compatible;MSIE8.0;WindowsNT6.0;Trident/4.0)',# IE8.0'Mozilla/4.0(compatible;MSIE7.0;WindowsNT6.0)',# IE7.0'Mozilla/4.0(compatible;MSIE6.0;WindowsNT5.1)',# IE6.0'Mozilla/5.0(Macintosh;IntelMacOSX10.6;rv:2.0.1)Gecko/20100101Firefox/4.0.1',# Firefox4.0.1–MAC'Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1',# Firefox4.0.1–Windows'Opera/9.80(Macintosh;IntelMacOSX10.6.8;U;en)Presto/2.8.131Version/11.11',# Opera11.11–MAC'Opera/9.80(WindowsNT6.1;U;en)Presto/2.8.131Version/11.11',# Opera11.11–Windows'Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;Maxthon2.0)',# 傲游(Maxthon)'Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;TencentTraveler4.0)',# 腾讯TT'Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;360SE)',# 360浏览器'Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;TheWorld)',# 世界之窗(TheWorld)3.x'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko']
url ='https://fanyi.baidu.com/sug'
headers ={'Host':'fanyi.baidu.com','User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0','Accept':'application/json, text/javascript, */*; q=0.01','Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Accept-Encoding':'gzip, deflate, br','Referer':'https://fanyi.baidu.com/?aldtype=16047','Content-Type':'application/x-www-form-urlencoded; charset=UTF-8','X-Requested-With':'XMLHttpRequest','Connection':'keep-alive','Content-Length':3}
words = pd.read_excel('words.xlsx')['word'].values
dictionary =[]for word in words:
word =str(word)
post_data ={'kw': word}
headers['User-Agent']= choice(UA)
headers['Content-Length']=str(3+len(word))try:
js = requests.post(url, headers=headers, data=post_data, timeout=99).json()
kv = js['data'][0]except Exception as e:
kv ={'k': word,'v':str(e)}print(kv)
dictionary.append((kv['k'], kv['v']))
sleep(randint(1,9))# 存
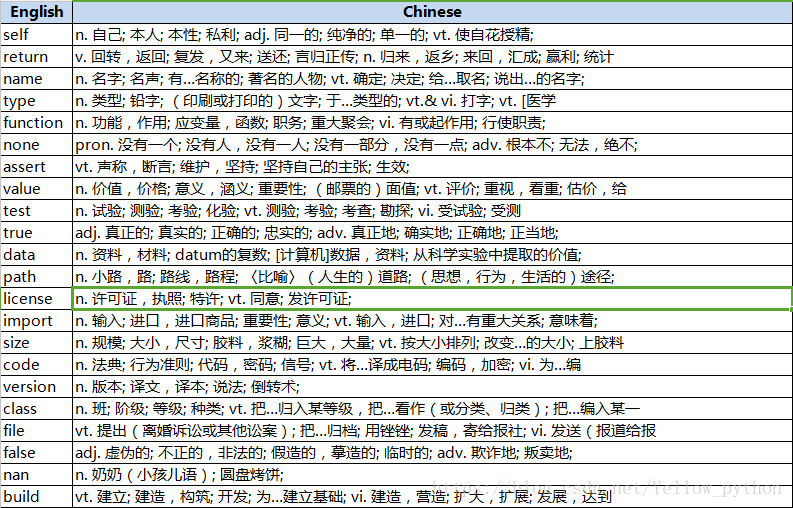
pd.DataFrame(dictionary, columns=['English','Chinese']).to_excel('dictionary.xlsx', index=None)



























 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











