







大家好 我是Yhen
今天给大家分享一下
如何爬取卡塔尔世界杯球员榜

数据来源:百度体育
https://tiyu.baidu.com/match/%E4%B8%96%E7%95%8C%E6%9D%AF/tab/%E7%90%83%E5%91%98%E6%A6%9C/current/0
一.需求分析
我们这次的目标是将所有榜单(射手榜、助攻榜…犯规)中的球员名 球队名/球员位置 以及榜单对应的数据爬取下来
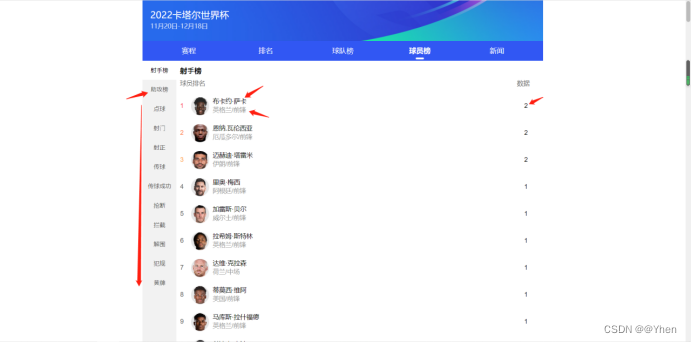
并保存到excel中去
二.思路分析
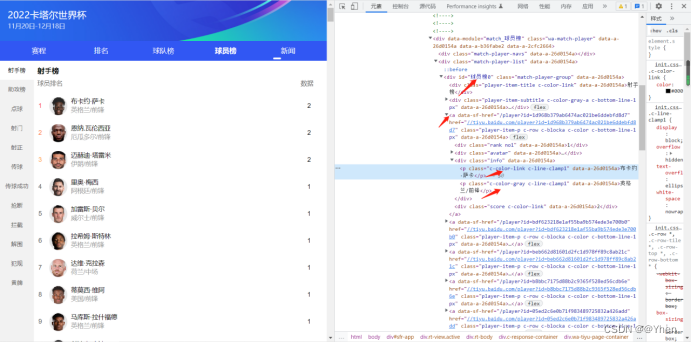
首先按下键盘的F12 打开浏览器检查工具
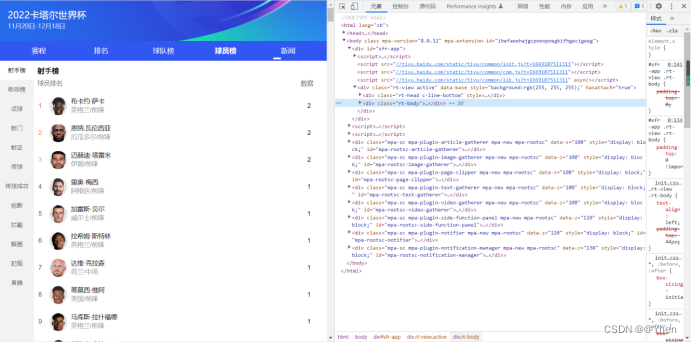
点击左上角的按钮 再点击到球员的名字处
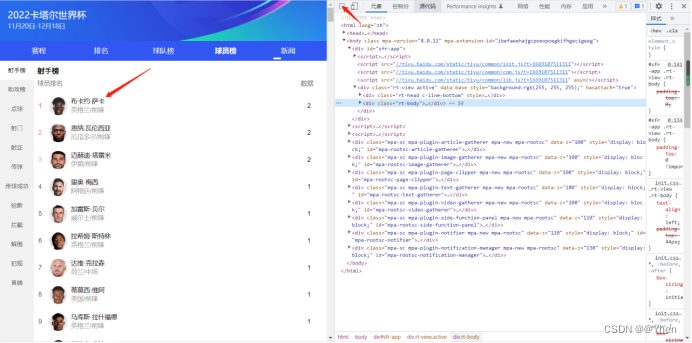
我们可以看到射手榜中的球员名字的数据在页面中 id为球员榜0下的a标签下 class属性为info标签下的class属性为c-color-link c-line-clamp1的文本
同理
球队/队员位置的数据在 class属性为info标签下的class属性为c-color-gray c-line-clamp1的文本
(叠的BUFF有点多,新手看起来可能有点复杂…别急慢慢看,其实就是看每个展开的接口,然后找到对应的唯一的属性标识。不熟悉可以看看我其他的爬虫文章多多了解,练多了就好了~加油)
在代码中用Pyquery解析出来就好了
但是这只是第一个榜单,如何获取其他的榜单的数据呢?
接下来我们观察一下
我们点击不同的榜单 url会有怎么样的变化呢?

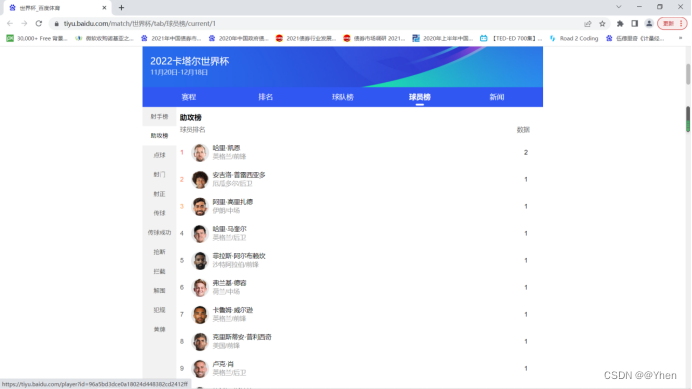
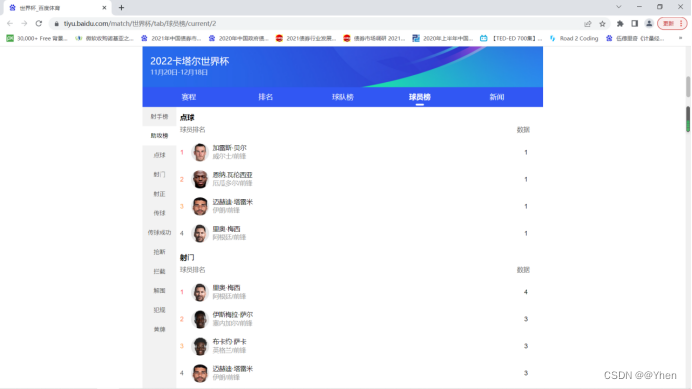
聪明的同学很快就发现了
每切换一次榜单,url最后的数字就会增加1
哇~ 你真厉害 这都被你发现了
点赞!
于是聪明的同学自信的敲起了代码
很快啊 一个获取球员信息的代码就写出来了
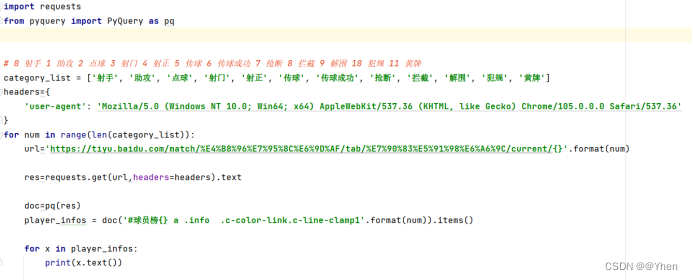
但当这位聪明的同学自信地运行时
却发生了意想不到的一幕
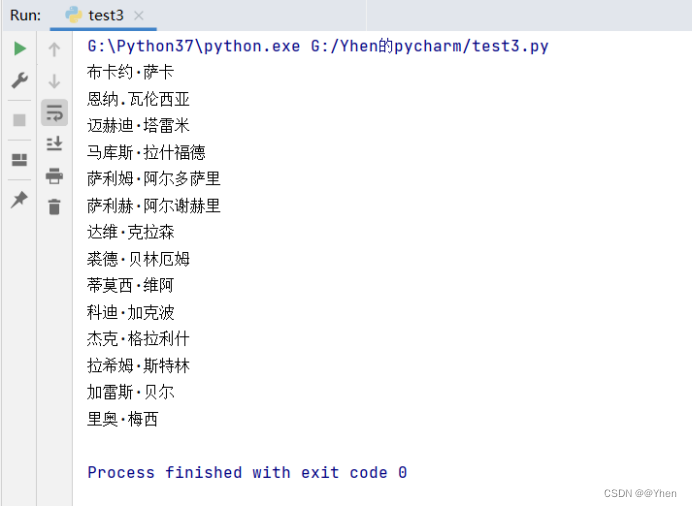
嗯嗯嗯?怎么就这么一点数据
他对比了一下原网页,现在似乎只爬取到了第一个榜单的数据
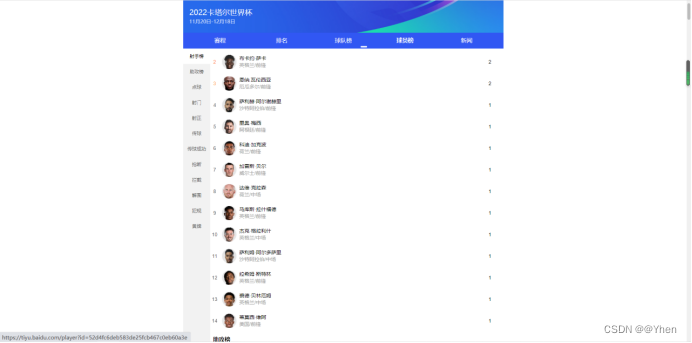
他百思不得其解
没理由啊,我已经根据榜单的数量做了一个循环处理了呀
为啥还是只得到第一个的数据呢?
困惑的他回到网页中
手动地将url中最后的数字从0改成1
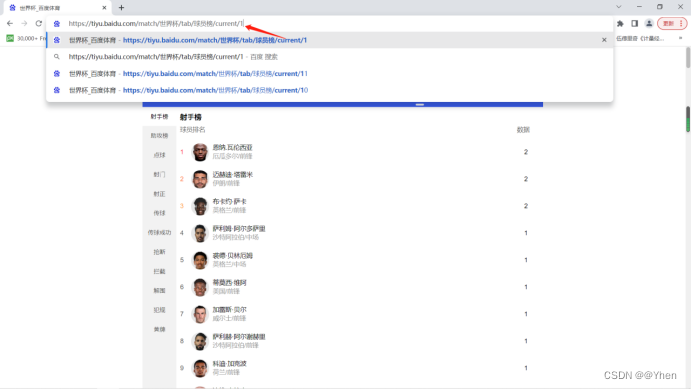
按下回车
无语的一幕发生了
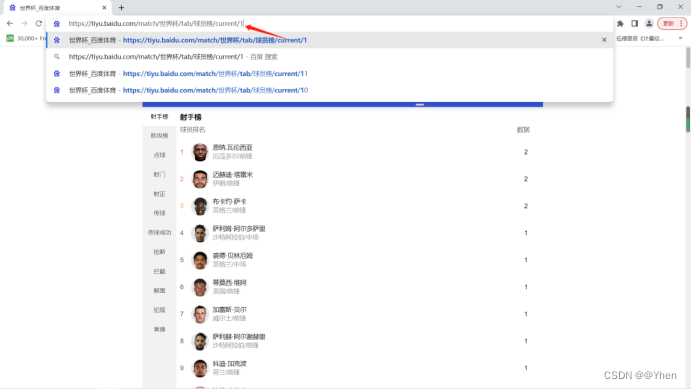
网页中显示的还是第一个榜单的内容…
怪不得
无效跳转了属于是
后来他又尝试改成其他的数字
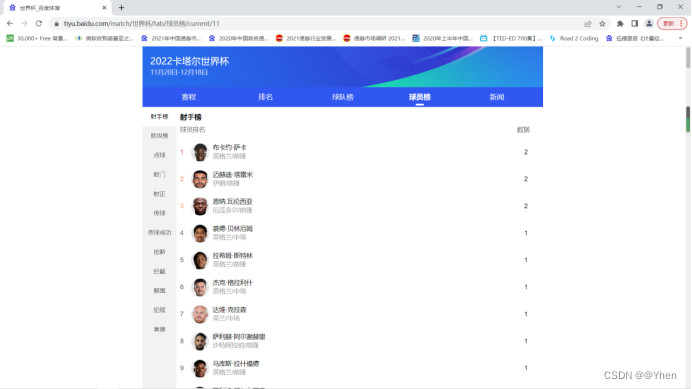
最后发现无论改成多少,显示的都是第一个榜单的内容
他终于悟了
在这里改变上面的url并不能实现页面的跳转
那么到底如何获取其他榜单的内容呢?
回到网页中来
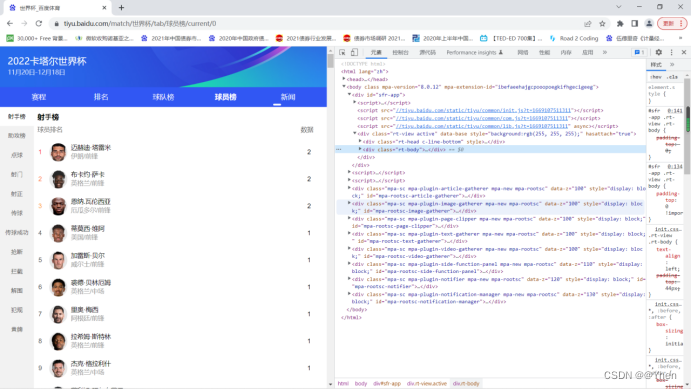
有没有一种可能
其他榜单的数据其实早就在页面中了呢?
仔细观察网页元素
发现榜单是由不同的div块组成的
每个榜单对应不同id的div块
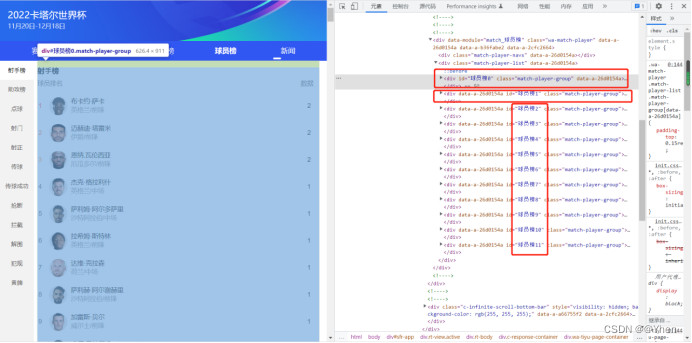
再仔细看看发现 每个榜单数据的获取
除了id不同,其他子元素都是相同的
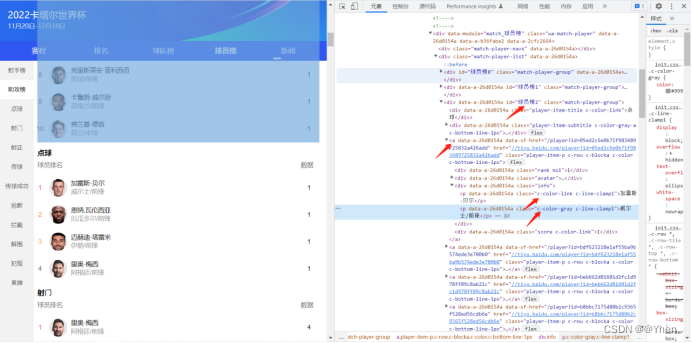
那么在没有指定id的情况下,获取的范围是更大的
在页面完整的情况下,常理来说应该能获取所有id下的数据才对
那么为什么只能获取到第一个榜单的数据?
Emmm…页面完整的话…
嗯?难道刚刚爬取下来的页面元素不完整?
于是我打印了刚刚获取到的源码
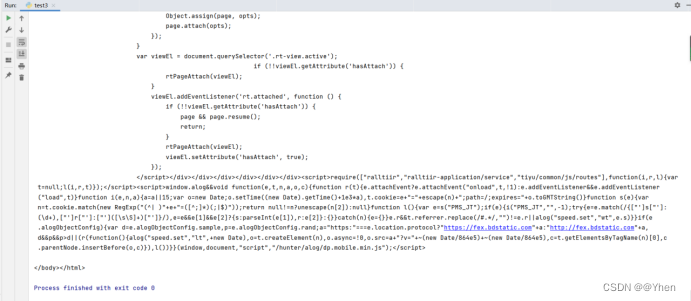
按下ctrl + F 搜索发现可以搜索到 球员榜0的数据
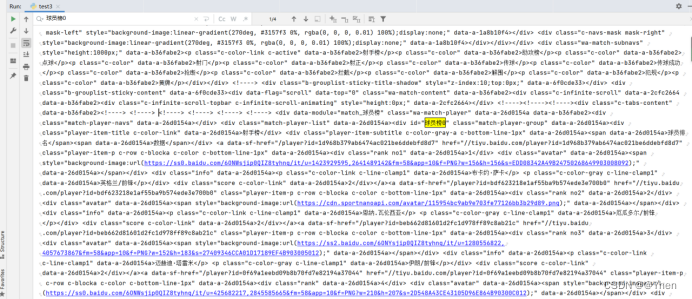
但当我搜索 球员榜1 时 就找不到对应的数据了
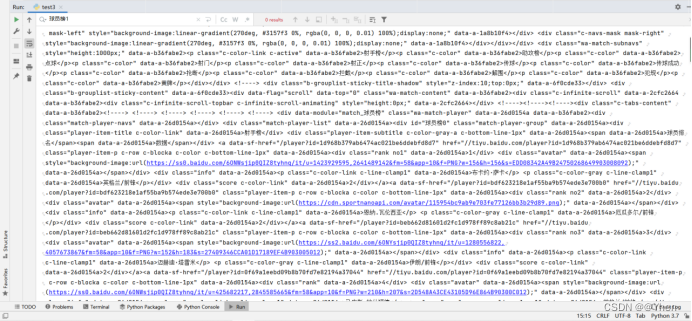
真相了
爬取下来的根本就没有我们想要的内容
那么还谈何解析?
为什么会这样呢?
因为我是用requessts发送请求并获取页面数据的
但是因为requests获取的是静态页面返回的数据
很多页面的内容并没有加载完全或者需要我们执行下滑操作才能加载
所有其他榜单的内容就无法获取到了
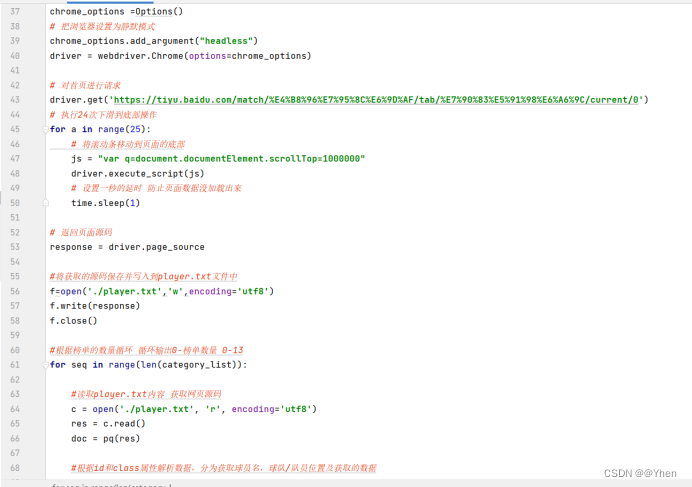
对于这种情况 我们可以使用selenium来爬取
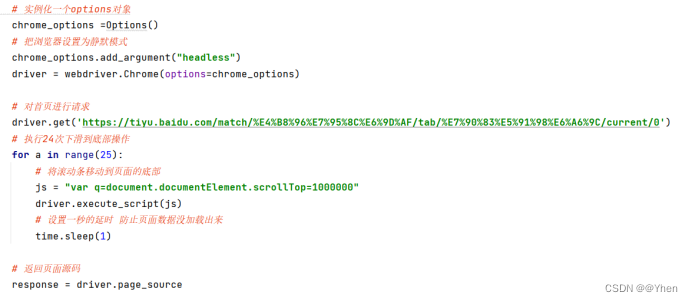
现在就可以成功获取到其他榜单的内容了
有了数据
其他就是小菜一碟了
三.代码实战
首先导包
import requests
from pyquery import PyQuery as pq
from openpyxl import Workbook, load_workbook
from openpyxl.styles import Font, Alignment
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
from pyquery import PyQuery as pq
Tip:需要下载浏览器对应的webdriver驱动才能使用selenium
各个浏览器下载地址参考:
https://www.jianshu.com/p/6185f07f46d4
使用selenium 爬取页面内容
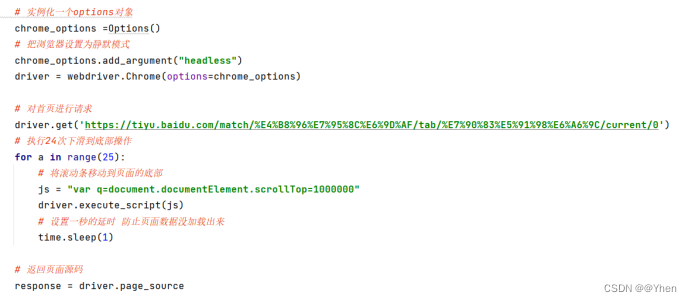
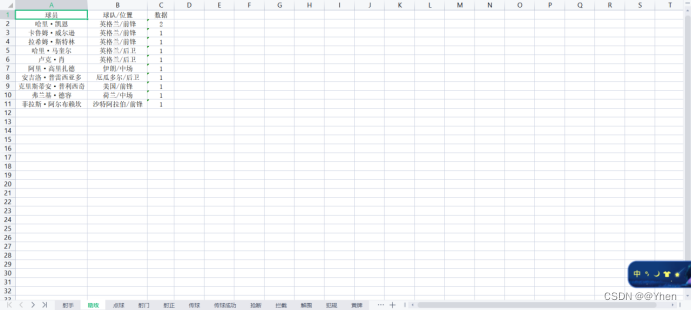
运行结果
解析出数据(详细方法看上面思路分析)
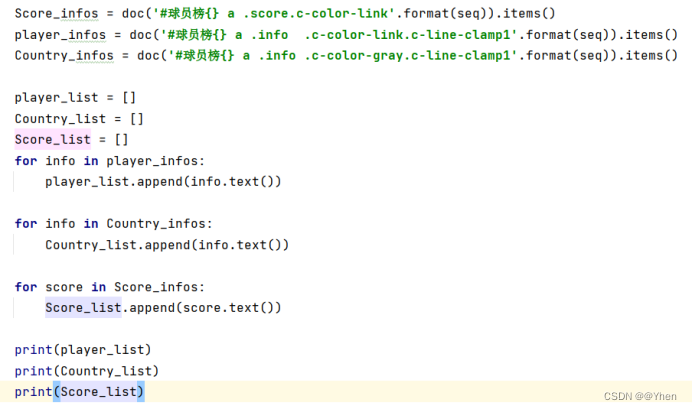
运行结果
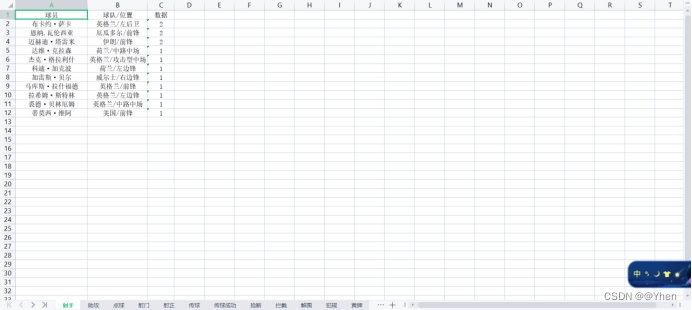
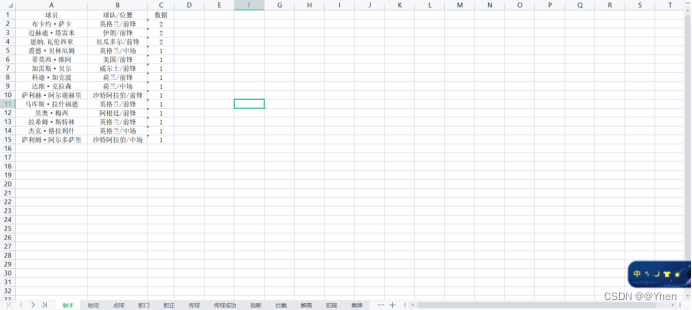
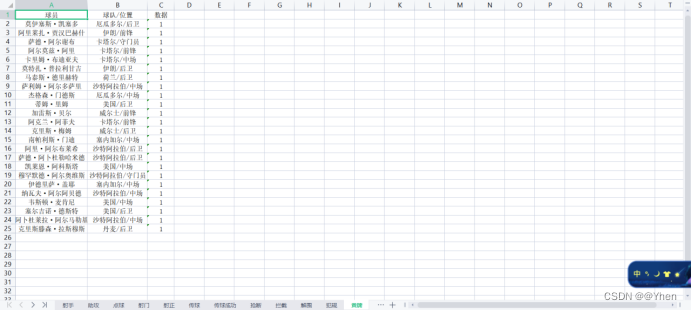
写入到excel中


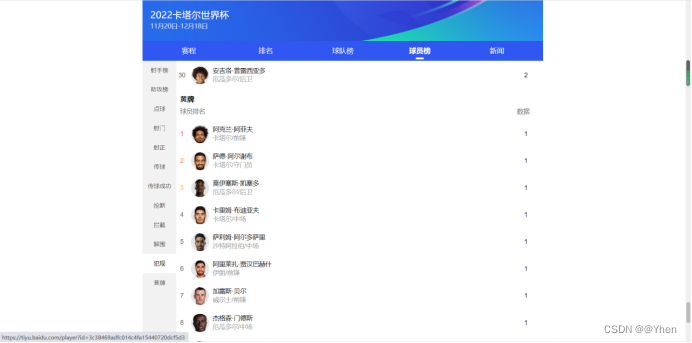
我们来看看最终的效果吧~
和网页上的对比一下
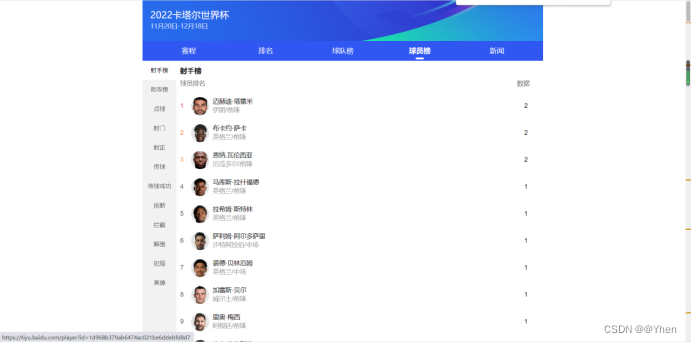
除了同成绩的展示顺序不一样(网站随机排序,刷新几次都不一样)
其他都是一样的
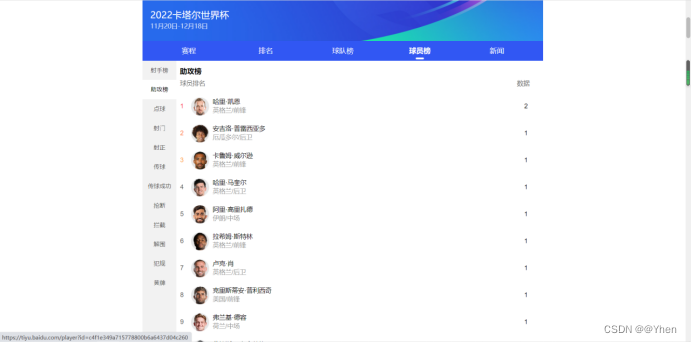
至此
我们已经成功爬取下了世界杯的榜单
四.源码获取















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









