









以下内容为本人原创,欢迎大家观看学习,禁止用于商业用途,谢谢合作!
·作者:@Yhen
·原文网站:CSDN
·原文链接:https://blog.csdn.net/Yhen1/article/details/105460969
转载请说明此出处,侵权必究!谢谢合作!
大噶好!我是python练习时长一个月的Yhen,今天向大家分享的是爬取去哪儿网旅游信息,特别感谢六星教育python学院,我就是在这里学的,老师讲的挺好挺仔细的,以下内容都是基于我在课堂上学到的,大家有兴趣可以到腾讯课堂报名听课,都是免费的。
我的前两篇博客有讲到如何爬小说和爬知乎大佬的文章,有兴趣的同学可以去我的博客主页看看哦!由于今天的内容比较简单,所以正文内容篇幅较之前两篇会短一点。但是放心,绝对详细。来不及解释了,快上车!!!
一.明确需求
今天我们的目标是把去哪儿网的热门旅游项目的项目名称,用户评分,以及价格爬取下来

我们以广州一日游为例
二.代码演示
首先是基本操作:先对网址发送请求,获取网页数据
import requests
url = 'https://piao.qunar.com/daytrip/list.htm?keyword=%E5%B9%BF%E5%B7%9E%E4%B8%80%E6%97%A5%E6%B8%B8®ion=&from=mdl_search&sort=&page={}'.format(c)
# 请求头 浏览器类型
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.9 Safari/537.36"}
# 向网址发送请求
res = requests.get(url,headers=headers).text
注意这里要加个请求头:浏览器类型哦,防止被网站识别出我们是爬虫在操作。
我们来康康请求结果

很nice,成功请求了,也没有出现乱码
好了,接下来就是提取数据
我的前两篇博客中提取数据时分别用到了xpath和pyque
我们今天 还是用pyquery来提取数据,忘了的同学可以去我博客复习下呀
首先导包,然后数据初始化
from pyquery import PyQuery as pq
# 数据初始化
doc =pq(res)
接下来回到我们的网页看看
首先F12,打开检查工具,然后点击左上角的按键。
我们先来定位项目名称
如图

我们看看下面给我们反馈的数据

首先我们能够看到,我们定位的数据类选择器为“name”
接下来再看看评分

我们可以看到,定位到评分时,下面给我们反馈的是在类选择器为“relation_count”
我们再来看看价格的

显然,价格是在类选择器为“sight_item_price”
好,下面我们就把他们取出来
他们的提取方法都是相同的
分别通过类选择器 “name”,“sight_item_price”,“relation_count”来提取他们的数据
# 通过类选择器获取旅游项目,项目价格以及评分信息
name =doc(".name")
sight_item_price=doc(".sight_item_price")
relation_count=doc(".relation_count")
print(name.text())
下面我们来看看我们提取到的项目名称的文本数据信息
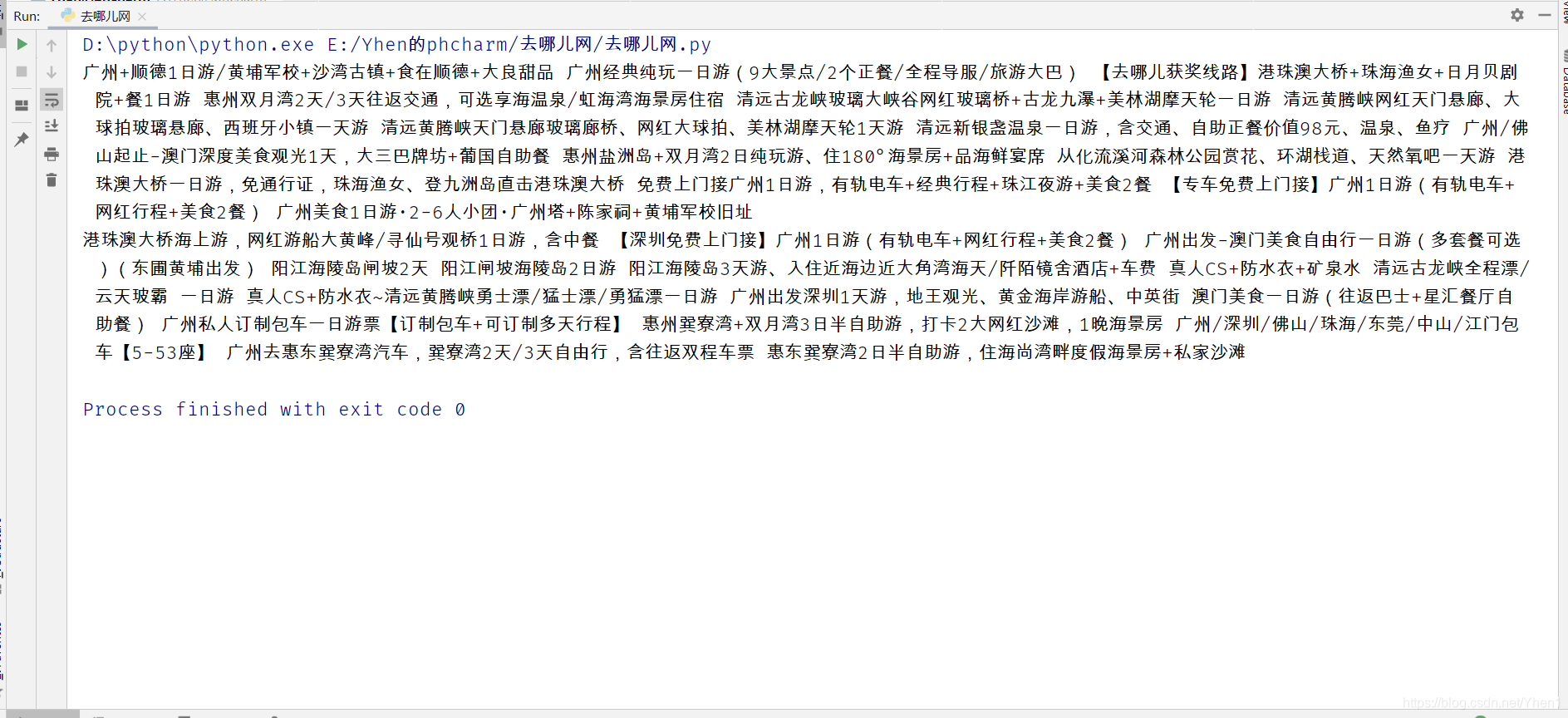
完美,都取出来了
然后我们用items()将数据转换成能够被遍历的数据
# 通过类选择器获取旅游项目,项目价格以及评分信息
name =doc(".name").items()
sight_item_price=doc(".sight_item_price").items()
relation_count=doc(".relation_count").items()
然后遍历数据,把他们一条条的取出,并分别转换成文本,并用travel这个变量来接收他
# 遍历旅游项目,项目价格以及项目名称
for x,s,f in zip(name,sight_item_price,relation_count):
# 将旅游项目信息转换为文本
name1=x.text()
#将项目价格转换为文本
sight_item_price1=s.text()
# 将评分信息转换为文本
relation_count1=f.text()
#将旅游项目,项目价格以及评分信息拼接起来
travel =(name1+sight_item_price1+relation_count1)
print(travel)
我们来看看打印结果
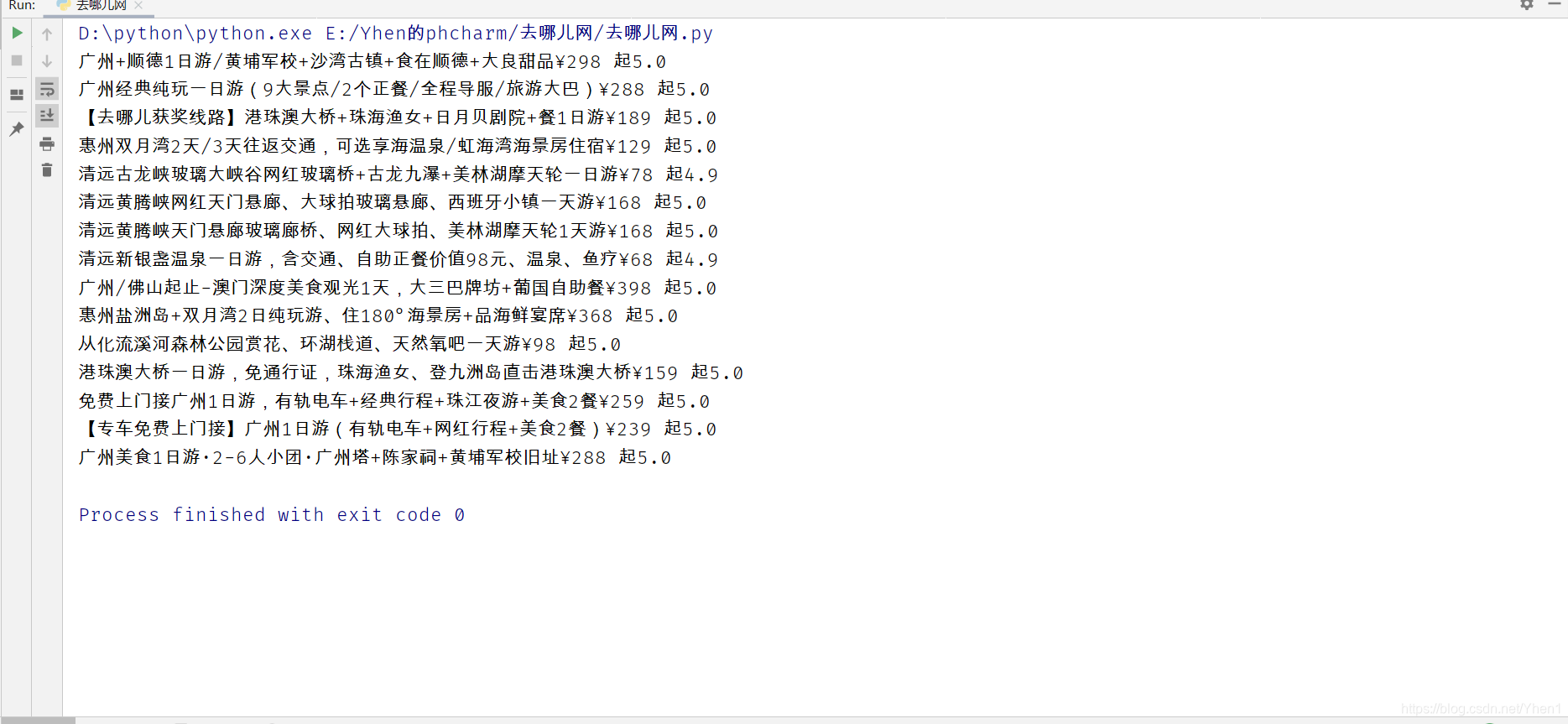
再看看我们的网页信息
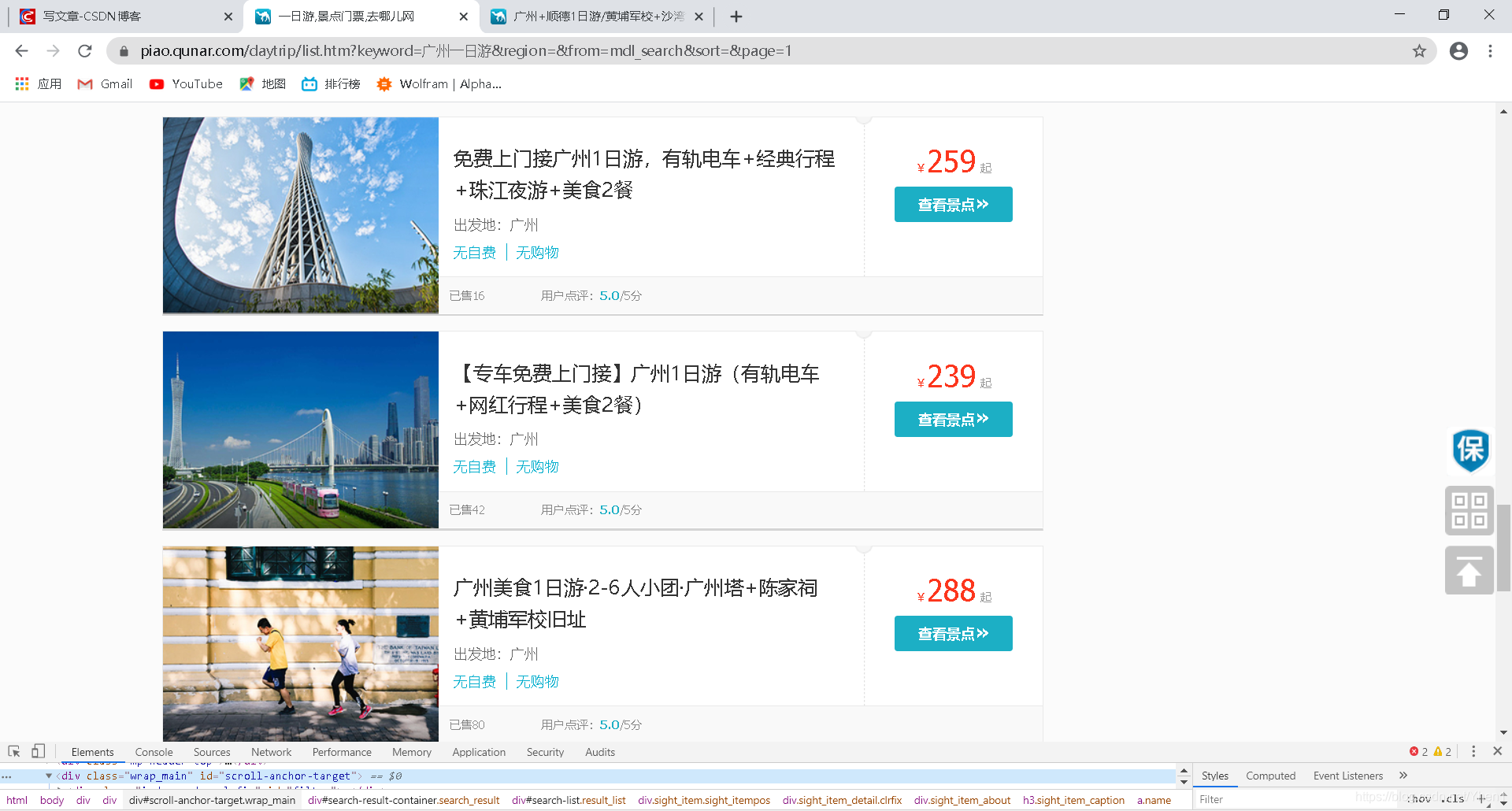
看!是不是就是正好我们第一页的内容呢!
可能有同学会问,那么如果我要两页数据怎么办?
下面就来教大家抓取两页的数据
首先,我们分析下第一页和第一页的网址有什么不同
第一页URL:
https://piao.qunar.com/daytrip/list.htm?keyword=%E5%B9%BF%E5%B7%9E%E4%B8%80%E6%97%A5%E6%B8%B8®ion=&from=mdl_search&sort=&page=1
第二页URL:
https://piao.qunar.com/daytrip/list.htm?keyword=%E5%B9%BF%E5%B7%9E%E4%B8%80%E6%97%A5%E6%B8%B8®ion=&from=mdl_search&sort=&page=2
大家发现什么不同了吗?
很明显,网址前面的都是一样的
只有最后page = 后面的数据变了
page我们都知道,是页的意思
这样我们就好理解了
page= 后面的数据是几页数就是几
那我们现在要第一页和第二页的数据
是不是只需要让page后面的数字分别等于1和二就ok了!
所以,我们设置一个for 循环,range为(1,3)根据取头不取尾的原则,将会输出1,2。然后我们将这个值填在page=后面,就可以达到我们的目的了
for c in range(1,3):
# 网页的地址
url = 'https://piao.qunar.com/daytrip/list.htm?keyword=%E5%B9%BF%E5%B7%9E%E4%B8%80%E6%97%A5%E6%B8%B8®ion=&from=mdl_search&sort=&page={}'.format(c)
页面显示不全,请同学们拖动看完整。
这里是用到 .format。用法是,我们先在我们要填充数据的地方用{}括住。然后在后面用.format()填充,括号里面的数据就是我们填充的数据
为了让同学们更直观地看到效果,我们把填充后的url打印下

看!是吧。输出的url就是我们第一页和第二页的url
大家都懂了吧?不懂欢迎评论区留言哦
那么我们再执行下程序,看看是否能够成功获取到两页的数据
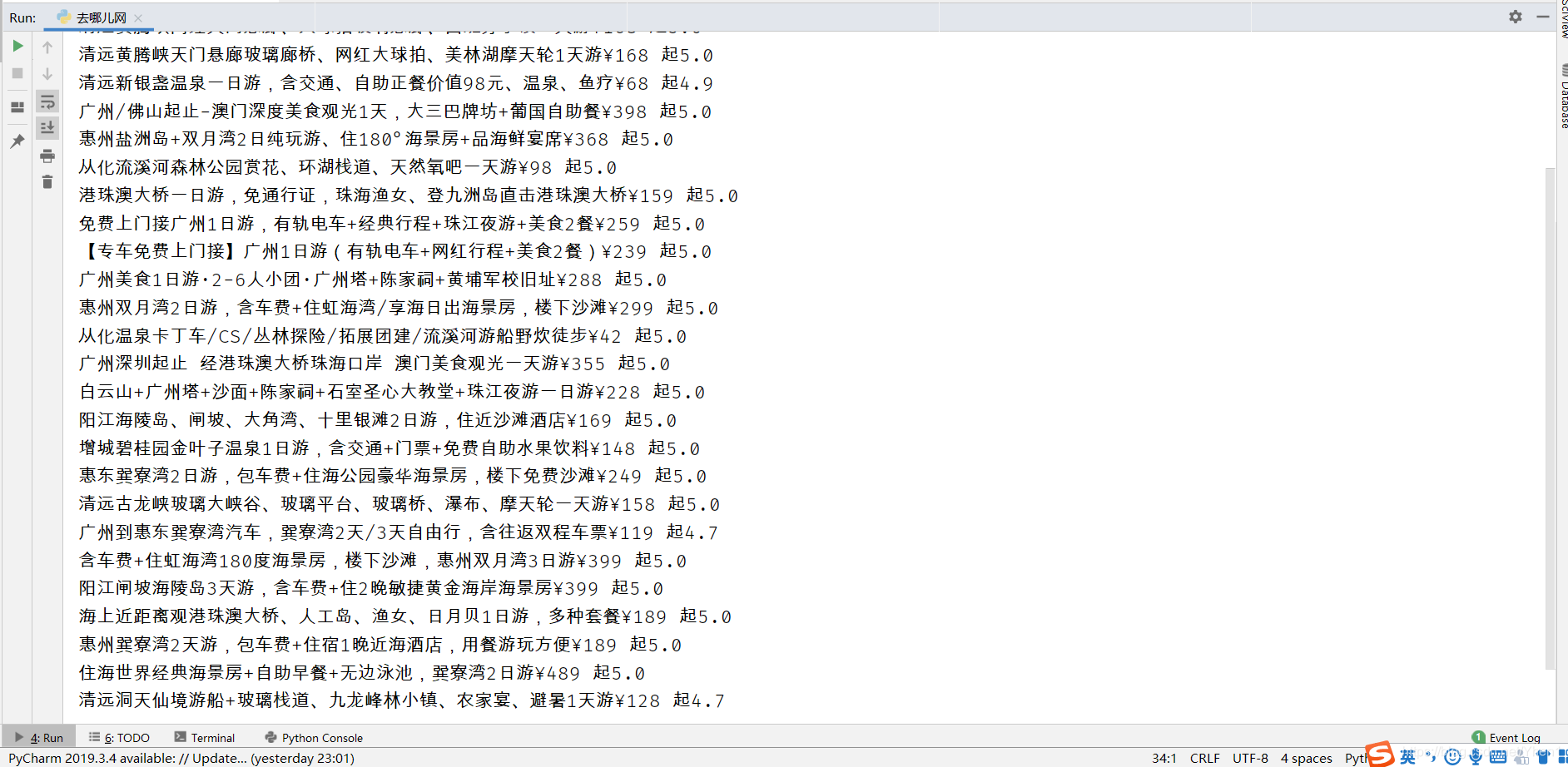
网页第二页
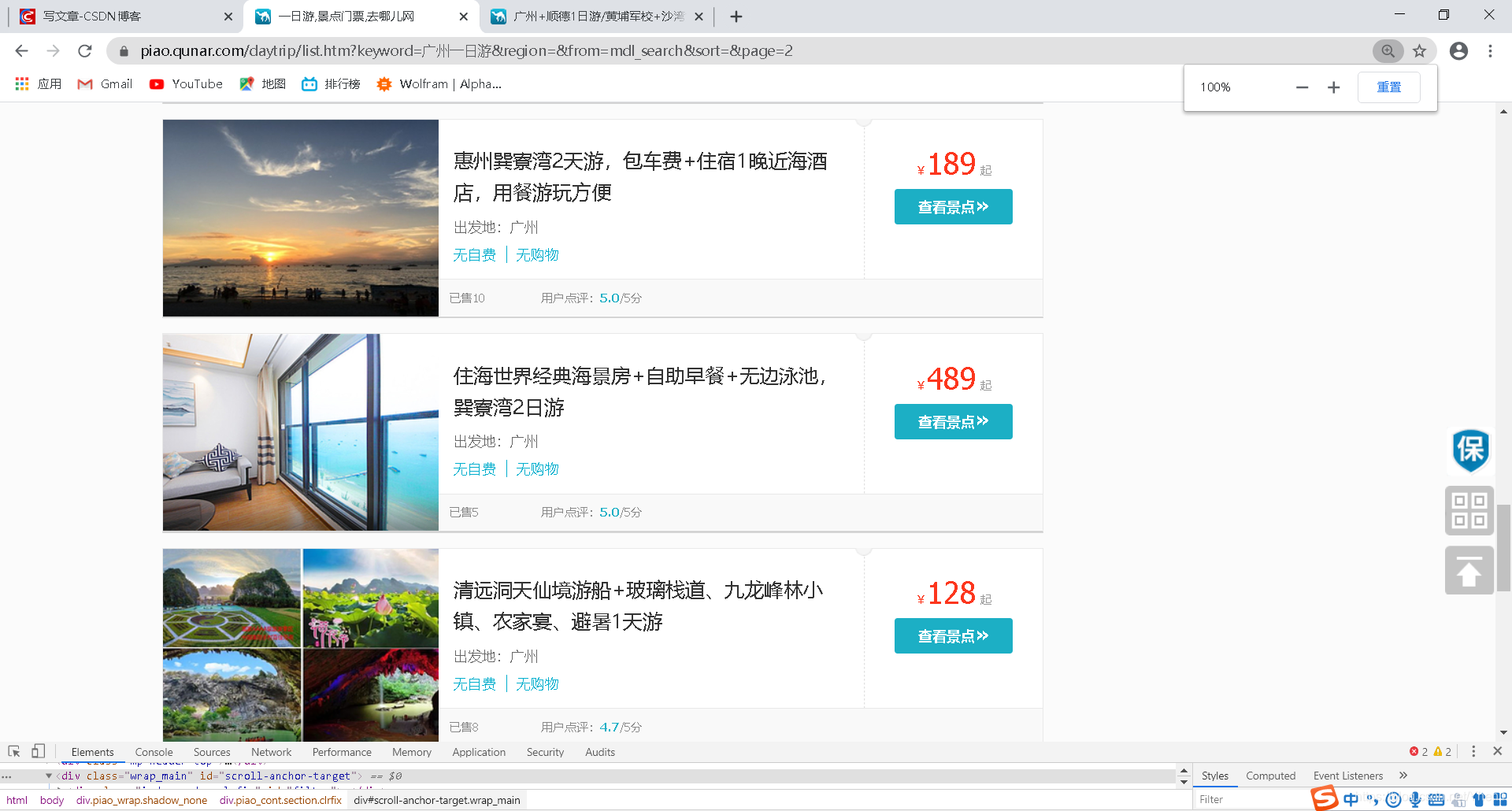
没毛病 成功把两页的数据都提取出来了!
最后我们把这些信息保存到本地
# 打开“去哪儿网”文件夹,保存为“广州一日游.txt”,"a"追加的方式,编码为utf-8
f =open('./'+'广州一日游1'+'.txt',"a",encoding="utf-8")
# 写入旅游信息
f.write(travel+"\n")
# 关闭文件写入
f.close()
看看结果
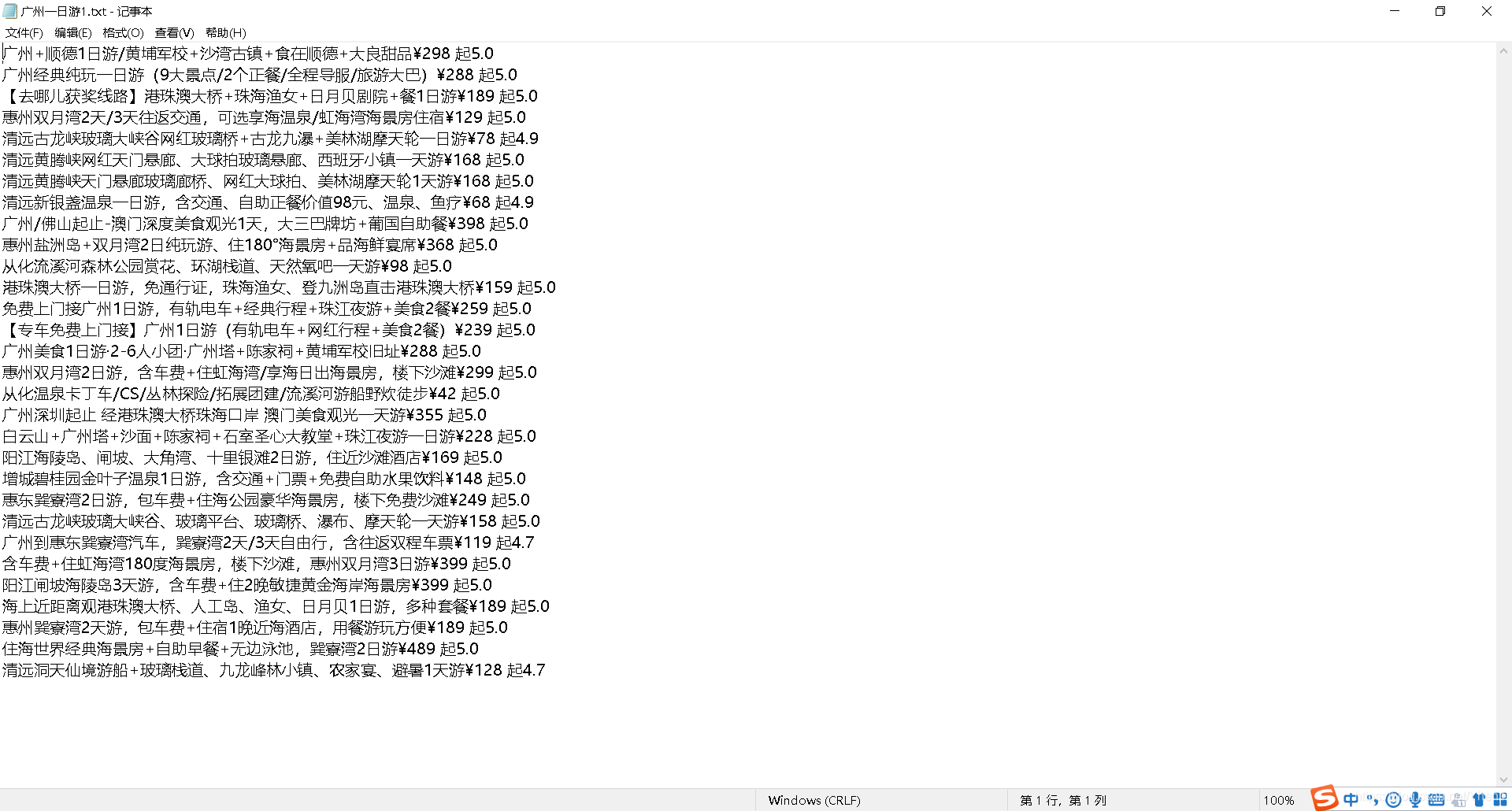
大功告成!
三.源码获取
扫码关注我的微信公众号“Yhen杂文铺在后台回复“旅游信息Spider”即可获取完整的源码啦!

四.项目拓展
大家仔细观察一下这个在浏览器里的url,有没有发现什么信息,或者对他有什么想法?
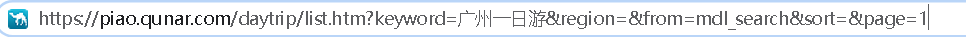
哈哈哈同学们可能会想,不就一条死板的数据嘛。又不帅又不美能有什么想法!?
但是我告诉大家,他不是一条死板的数据,他是很灵活的数据哦。
大家发现没有。在url中,有个叫keyword的,后面的数据是不是就是我们刚刚输入的搜索关键字?
那么我们就有理由猜测,我们可以通过修改这个数据来改变我们的搜索结果
那么我们先在浏览器里试试

我把广州一日游改成了上海一日游
看看我们的页面会出现什么变化
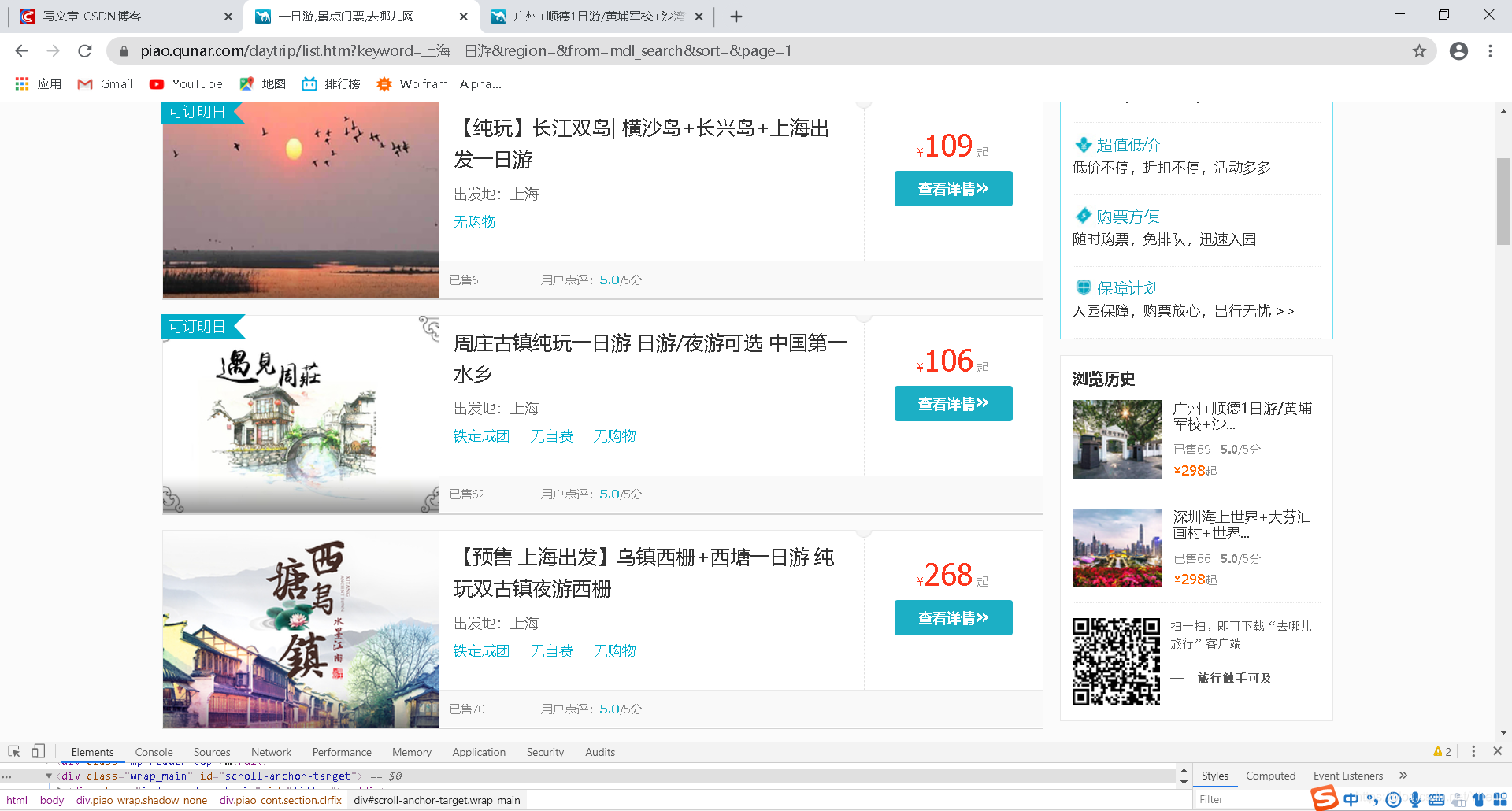
登登登登!页面跳转到了以上海为出发地的一日游信息!有点意思哈
然后我们看看在python中能不能达到同样的效果
但是
当我们回到pycharm
却发现网址变成了这样
https://piao.qunar.com/daytrip/list.htm?keyword=%E5%B9%BF%E5%B7%9E%E4%B8%80%E6%97%A5%E6%B8%B8®ion=&from=mdl_search&sort=&page=1
keyword后面变成了一堆乱七八糟我看不懂的东西,什么鬼?这是什么?
不要慌!虽然我们不知这是什么(我估计是被编码了吧)
但是我们可以试试直接输入中文,换成我们想要搜索的东西,看看得到我们想要的东西
for c in range(1,3):
# 网页的地址
url = 'https://piao.qunar.com/daytrip/list.htm?keyword=上海一日游®ion=&from=mdl_search&sort=&page={}'.format(c)
我同样改成上海一日游
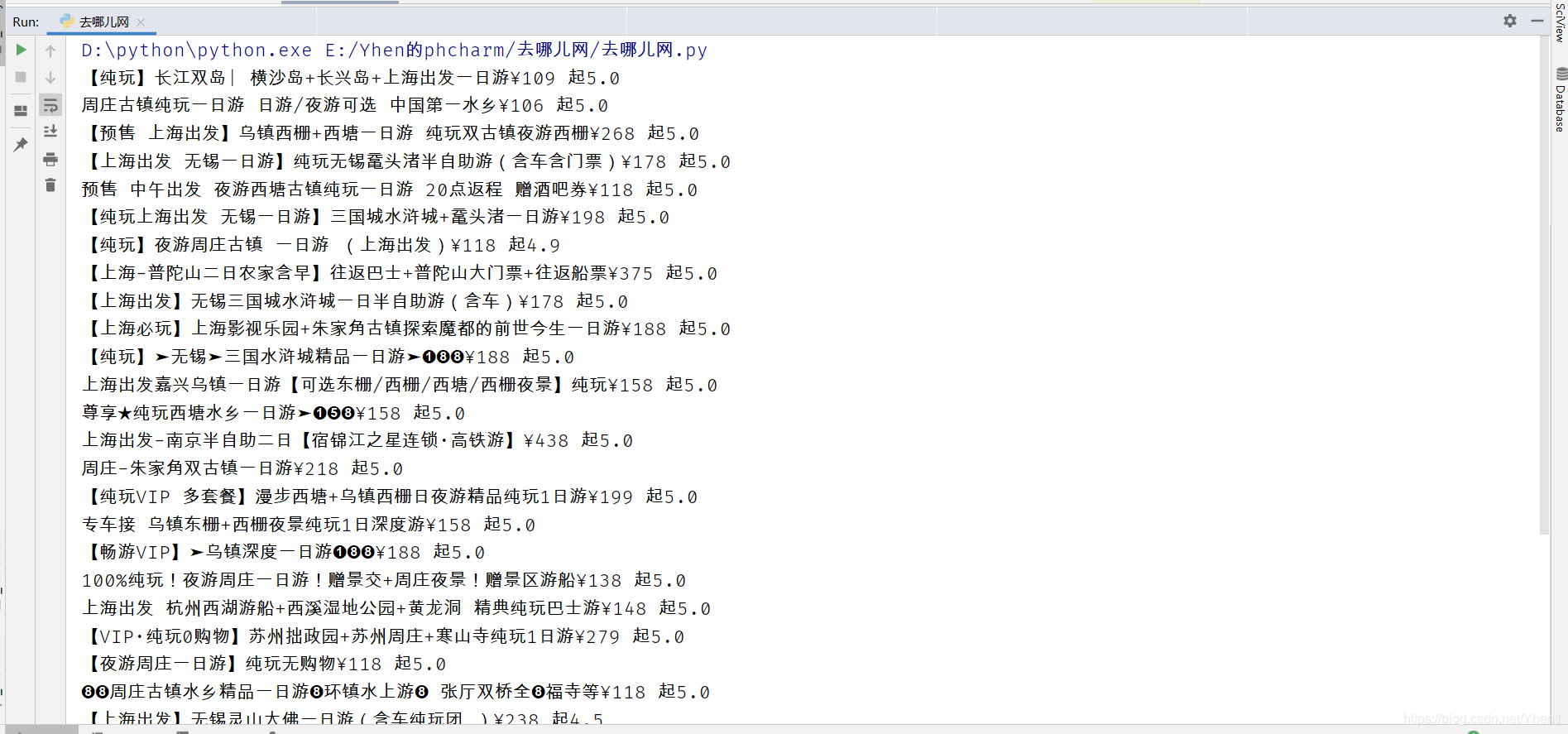
wow,居然真的成功得到了上海一日游的数据了!!!
然后我有个大胆的想法
能不能把他变成我们一个保存在本地的旅游搜索工具呢?
听起来是不是很刺激,很好玩哈哈哈
来带你去实现
#让使用者自行输入要查询的旅游地
travel_name =input("请输入你要查询的一日游旅游地信息.如(广州)")
#设置循环两页
for page in range(1,3):
# 网页的地址。把keyword和page后面的值设置为填充值
url = 'https://piao.qunar.com/daytrip/list.htm?keyword={}®ion=&from=mdl_search&sort=&page={}'.format(travel_name,page)
在这里对旅游地的查询,我用了一个input函数。这个函数的用法是,用户输入的数据就会变赋值到左边的变量中去,这样我们就可以自行选择我们的旅游地的效果了!
在下面文件保存也需要用到format
# 打开“去哪儿网”文件夹,保存为“xx一日游.txt”,"a"追加的方式,编码为utf-8
f =open('./'+'{}一日游'.format(travel_name)+'.txt',"a",encoding="utf-8")
# 写入旅游信息
f.write(travel+"\n")
# 关闭文件写入
f.close()
我们来运行下
这里我以上海为例
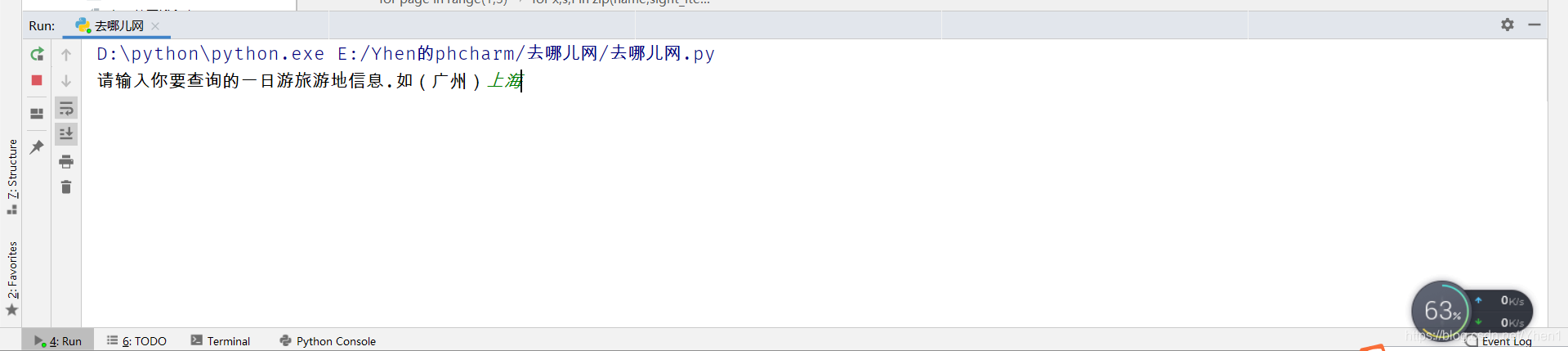
成功得到了一个上海一日游.txt文件
打开看看

哈哈哈哈成功了
五.打造本地旅游查询工具(exe打包)
嗯,对了。刚刚我说的是让他变成我们的一个本地的旅游信息查询工具
既然是本地工具
那么当然要打包
下面教下大家打包成exe
首先我们点击下方的Terminal
这里要用到一个pyinstaller来打包
这个也是要下载的
和下载我们的第三方库一样
pip install pyinstaller

黄色这个不用管它,因为我这里网络不太好,请求缓慢

出现successful就表示安装成功
然后在Terminal继续输入pyinstaller --console --onefile (这里是你py文件的路径)

说明我们成功打包了

这里是我们exe文件的保存路径

看!它在这
我们执行以下看看
这次我们以北京为例

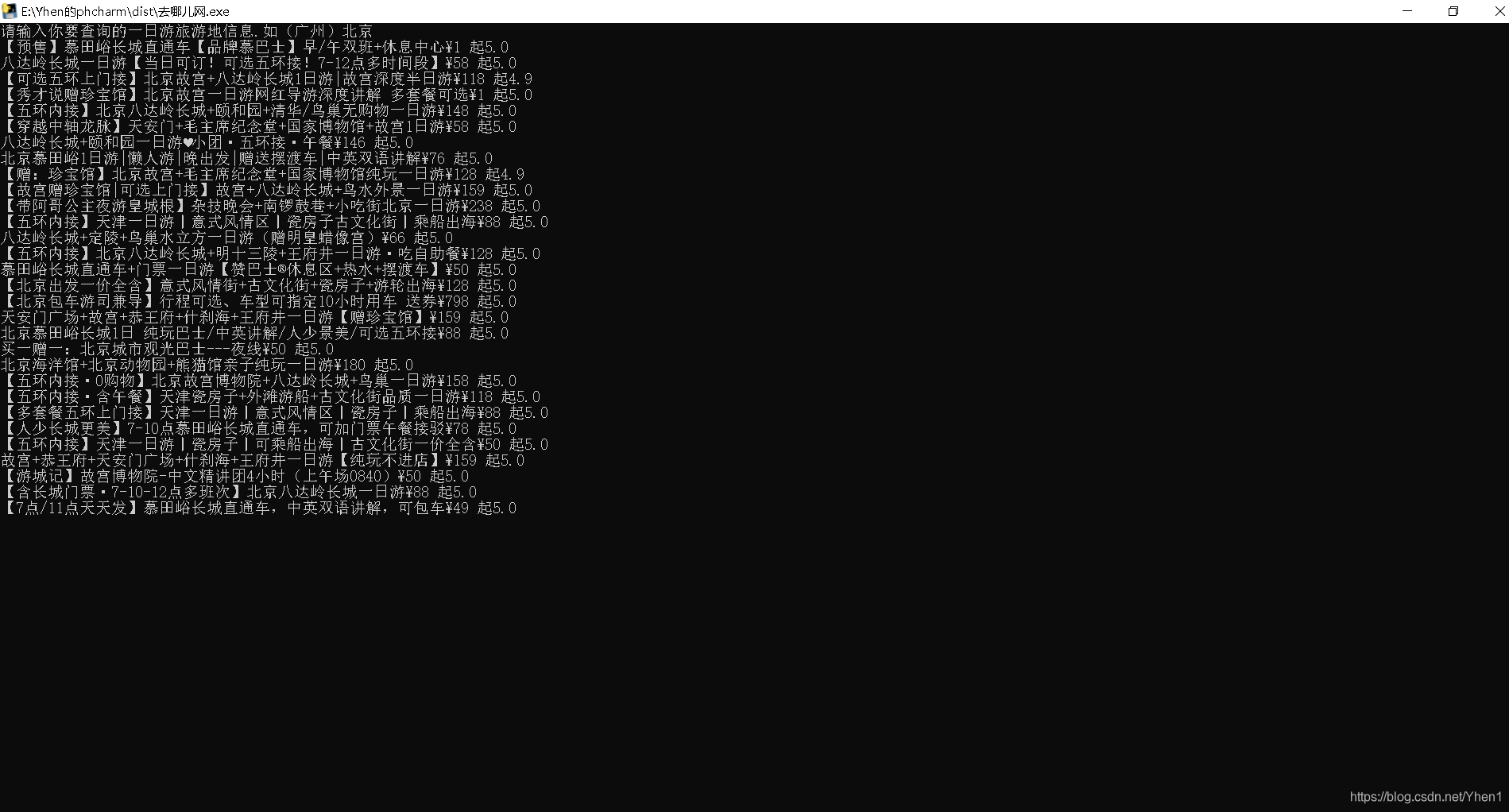
自动给我们生成了一个北京一日游的txt文件
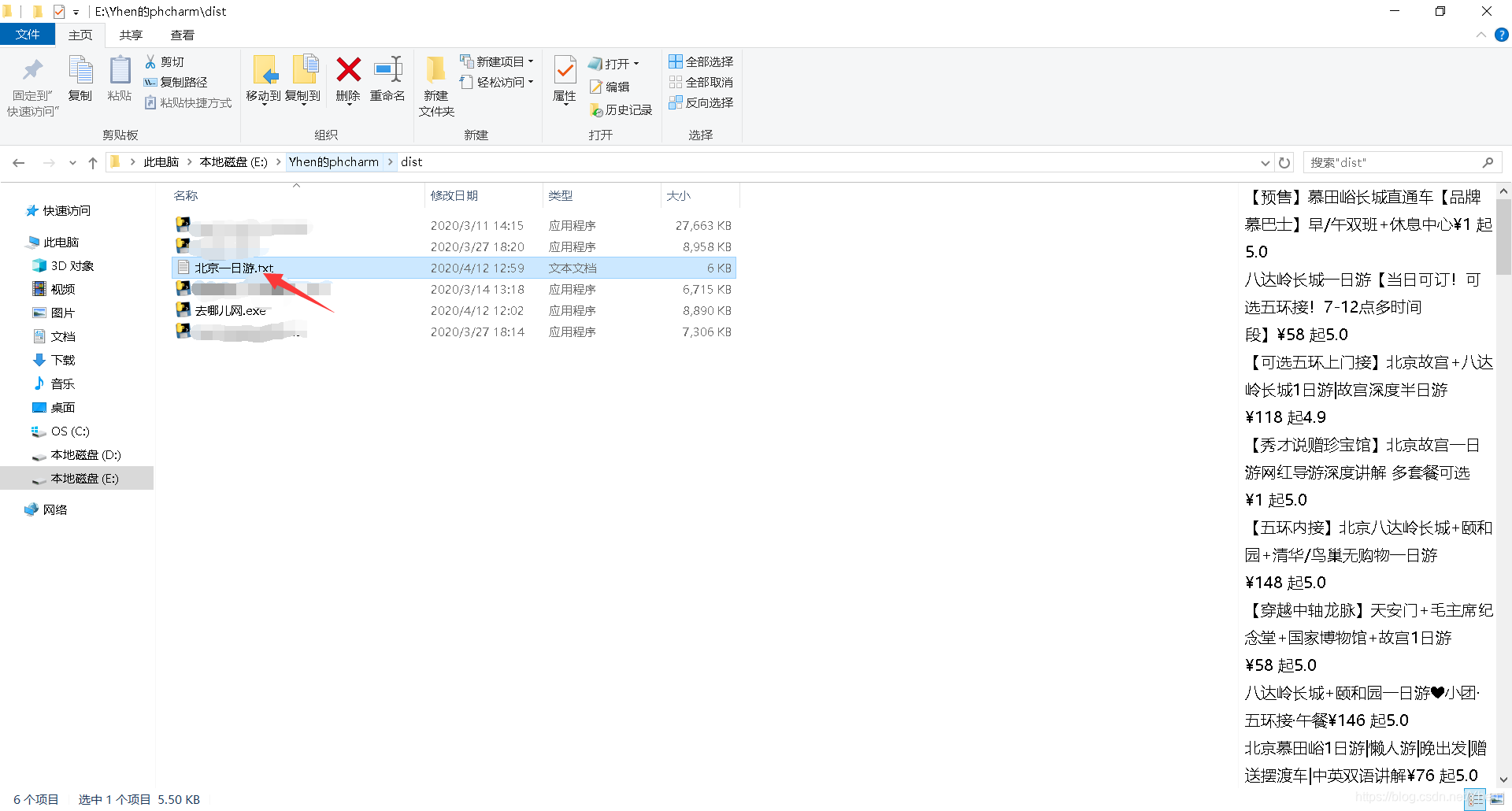
打开看看

成功得到我们的数据了
以后想要查询旅游信息再也不用打开浏览器,进入去哪儿网,再搜索了
直接打开这个小工具,你想要的,全都有哈哈哈
好啦,到这里这次的经验分享就要结束了
六.源码及exe文件获取
扫码关注我的微信公众号“Yhen杂文铺在后台回复
①“旅游信息Spider”获取完整源码
②“旅游信息查询工具”获取exe脚本文件
七.往期文章回顾
Yhen带你趣味入门Python①—Windows下Python下载及安装
【python热搜爬虫+定时发送邮件操作①】不会吧不会吧!不会2020了还有人需要用软件看微博热搜吧?
【python微博爬虫+定时发送邮件操作②】不会吧不会吧!不会2020了还有人需要用软件看微博热搜吧?
【爬虫+数据可视化】Yhen手把手带你爬取CSDN博客访问量数据并绘制成柱状图
【爬虫】Yhen手把手带你爬取去哪儿网热门旅游信息(并打包成旅游信息查询小工具
【爬虫】Yhen手把手带你用python爬小说网站,全网打尽,想看就看!(这可能会是你看过最详细的教程)
【实用小技巧】用python自动判断并删除目录下的空文件夹(超优雅)
【爬虫+数据库操作】Yhen手把手带你用pandas将爬取的股票信息存入数据库!
【selenium爬虫】
Yhen手把手带你用selenium自动化爬虫爬取海贼王动漫图片
【爬虫】秀才不出门,天下事尽知。你也能做到!Yhen手把手带你打造每日新闻资讯速达小工具。
【爬虫】Yhen手把手带你用python爬取知乎大佬热门文章
【爬虫】Yhen手把手教你爬取表情包,让你成为斗图界最靓的仔
【前端】学过一天的HTML+CSS后,能做出什么有趣的项目?
希望大家能够喜欢这篇文章
如果可以的话,可以点个赞鼓励下嘛?加个关注更好呦!
我是Yhen,下次见~

















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









