







Lucene是一个基于Java的高效的全文检索库。
那么什么是全文检索,为什么需要全文检索?
目前人们生活中出现的数据总的来说分为两类:结构化数据和非结构化数据。很容易理解,结构化数据是有固定格式和结构的或者有限长度的数据,比如数据库,元数据等。非结构化数据则是不定长或者没有固定格式的数据,如图片,邮件,文档等。还有一种较少的分类为半结构化数据,如XML,HTML等,在一定程度上我们可以将其按照结构化数据来处理,也可以抽取纯文本按照非结构化数据来处理。
非结构化数据又称为全文数据。,对其搜索主要有两种方式:
1) 顺序扫描法(SerialScanning):顾名思义,要找内容包含某一个字符串的文档,就挨着文档一个个找,对照每一个文档从头到尾,一直扫描,指导扫描完所有的文档。类似于Windows中搜索文件的功能。
2) 第二种则为索引。就是从非结构化数据中提取出信息重新组织,使其变得有一定的组织,从而提高检索效率。比如我们的电话簿,从电话簿中查找联系人,我们根据首字母拼音可以索引定位到某一个联系人。
先建立索引在对索引进行搜索的过程就叫做全文检索(Full-text Search)。下图为全文检索的一般过程,也是Lucene检索的过程。
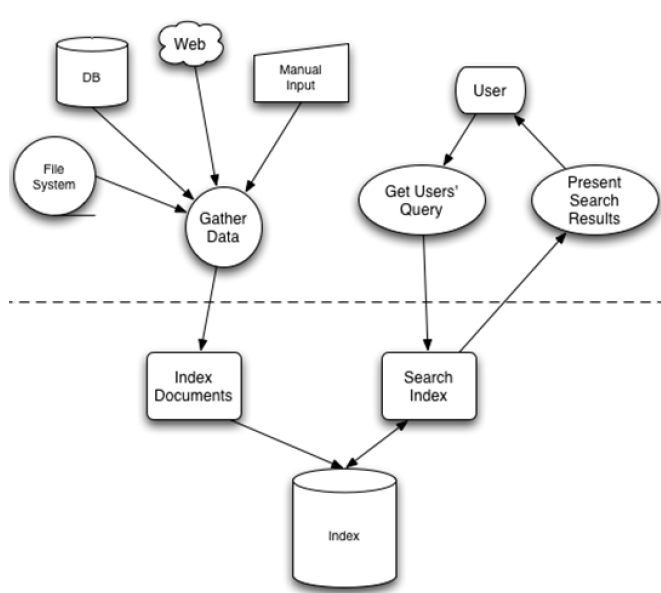
全文检索主要分为两个过程,索引创建和搜索索引。
索引创建:将显示中所有结构化和非结构化的数据提取信息,创建索引的过程。
搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
这里引出全文检索的三个问题:
1.索引中存储了怎样的数据
顺序扫描速度慢的原因是由于用户想要搜索的信息和非结构化数据中所存储的信息不一致。索引保存从字符串到文件的映射,则会大大提高搜索速度。从字符串到文件的映射是从文件到字符串映射的反向过程,因此保存这种信息的索引称为反向索引。

左边保存称为词典的一系列字符串,右边每个字符串指向包含自己的文档链表(倒排表,Posting List)。索引使得保存的信息与要搜索的信息一致,因而提高搜索的速度。
对于大量数据来说,创建索引确实是一个耗时的过程,但是相比于顺序扫描,创建索引只需要一次之后每次搜索不需要再创建索引,而顺序扫描是每一次都需要重新扫描。
2.如何创建索引
全文检索创建索引有以下几步:
1) 一些要索引的原文档(Document)
2) 将原文档传给分词组件(Tokenizer)
分词组件主要做的事情是将文档分成一个一个单独的单词,去掉标点符号和停词(句子中最普通的出现频率最高的一些词,没有实际和特别的意义,比如冠词the, a, an等)
3) 将得到的词元(Token)传给语言处理组件(LinguisticProcessor)
语言处理组件主要是对得到的词元做一些处理:大写变为小写,将单词缩写成词根形式(Stemming)和将单词换边为词根形式(Lemmatization)
Stemming 和lemmatization的异同:
相同之处:Stemming 和lemmatization 都要使词汇成为词根形式。
两者的方式不同:
Stemming 采用的是“缩减”的方式:“cars”到“car”,“driving”到“drive”。
Lemmatization 采用的是“转变”的方式:“drove”到“drove”,“driving”到“drive”。
两者的算法不同:
Stemming 主要是采取某种固定的算法来做这种缩减,如去除“s”,去除“ing”加“e”,
将“ational”变为“ate”,将“tional”变为“tion”。
Lemmatization 主要是采用保存某种字典的方式做这种转变。比如字典中有“driving”
到“drive”,“drove”到“drive”,“am, is,are”到“be”的映射,做转变时,只要查字典就可以了。
Stemming 和lemmatization不是互斥关系,是有交集的,有的词利用这两种方式都能达到相同的转换。
词元转换之后的词,我们称之为词(Term)。
4) 将得到的词(Term)传给索引组件(Indexer)
索引组件主要做:
A. 将得到的词(Term)创建一个字典;
B. 对字典按照字母顺序进行排序;
C. 合并相同的词(Term)成为文档倒排(PostingList)链表,在该表中需要注意两个定义:一个是Document Frequency,文档频次,表示总共有多少文件包含该词,另一个是Frequency词频,表示此文件中包含了几个该词
3.如何搜索索引
我们搜索到的结果往往不是只有几个,也往往不一定就是我们想要找的那几个,也可能返回成百上千上万个文件我们无法一眼就找到我们需要的文档。因此,我们需要在搜索结果中找到和查询语句最相关的文档才行。
因此搜索分为以下几步:
1) 用户输入查询语句
查询语句也是由语法的,基本的包含AND,OR,NOT等。例如:用户输入lucene AND learned NOT hadoop,则表示用户想要寻找一个包含lucene和learned但是不包含hadoop的文档。
2) 对查询语句进行词法分析,语法分析和语言处理
词法分析就是发现不合法的关键字会出现错误。比如关键字NOT拼写错误的话就会被当作普通单词参与查询
语法分析主要是根据查询语句的语法规则来形成一棵语法树

语言处理的过程与索引过程中的语言处理几乎相同,learned变为learn

3) 搜索索引,得到符合语法树的文档
该步骤有几步:
A. 在反向索引表中,分别找出包含lucene,learn,hadoop的文档链表
B. 对包含lucene和learn的链表进行AND操作,得到一个包含两个词的文档链表
C. 将此链表与hadoop的文档链表进行差操作,去除包含hadoop的文档,得到的文档链表就是我们需要的文档
4) 根据得到的文档和查询语句的相关性,对结果进行排序
需要对文档与文档之间的相关性进行打分,分数高的相关性好,应该排在前面。那么如何判断文档之间的关系呢?一个文档由许多词组成,对于不同的文档,不同的term重要性不同。因此,判断文档之间的关系,首先找出哪些词对于文档之间的关系最重要,然后判断这些词之间的关系,也就是计算词的权重。计算词的权重有两个参数,第一个是词(Term),第二个是文档(Document)。词的权重(Term weight)表示此词(Term)在此文档中的重要程度,越重要的词(Term)有越大的权重(Term weight),因而在计算文档之间的相关性中将发挥更大的作用。判断词(Term)之间的关系从而得到文档相关性的过程应用一种叫做向量空间模型的算法(Vector Space Model)。计算权重的过程中,影响一个词的重要性主要由Term Frequency (tf)(即此Term 在此文档中出现了多少次。tf 越大说明越重要。)和Document Frequency (df)(即有多少文档包含次Term。df 越大说明越不重要。)影响。然使用向量空间模型的算法来判断Term之间的关系从而得到文档相关性。
总结一下,创建索引和搜索索引的过程如下图:
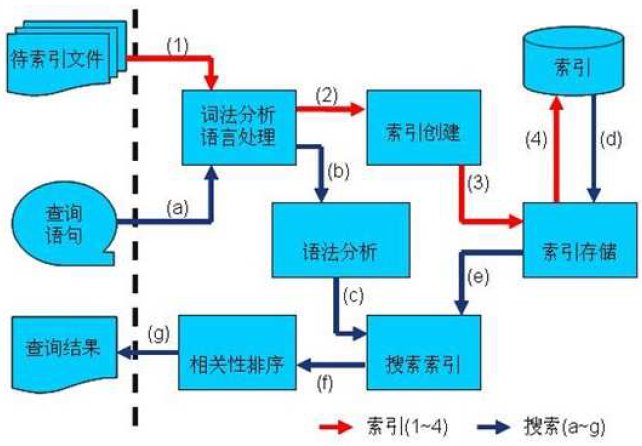
1. 索引过程:
1) 有一系列被索引文件
2) 被索引文件经过语法分析和语言处理形成一系列词(Term)。
3) 经过索引创建形成词典和反向索引表。
4) 通过索引存储将索引写入硬盘。
2. 搜索过程:
a) 用户输入查询语句。
b) 对查询语句经过语法分析和语言分析得到一系列词(Term)。
c) 通过语法分析得到一个查询树。
d) 通过索引存储将索引读入到内存。
e) 利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得到结果文档。
f) 将搜索到的结果文档对查询的相关性进行排序。
g) 返回查询结果给用户。
关于信息检索的相关理论差不多就是这些。
Lucene是对以上这种理论的一种基本实践,是一个高效的可扩展的全文检索库,全部用java实现,无需配置,但是仅仅支持纯文本文件的索引的搜索,不负责由其他格式的文件抽取纯文本文件,或者从网络中抓取文件的过程。
Lucene的构架如下图所示:

从图中而已看出,Lucene有索引和搜索两个过程,包含索引创建,索引,搜索三个要点。
索引的组件:

被索引的文档用Document对象表示。
l IndexWriter通过函数addDocument将文档添加到索引中,实现创建索引的过程。
l Lucene的索引是应用反向索引。
l 当用户有请求时,Query代表用户的查询语句。
l IndexSearcher通过函数search搜索Lucene Index。
l IndexSearcher计算term weight和score并且将结果返回给用户。
l 返回给用户的文档集合用TopDocsCollector表示。
索引过程:
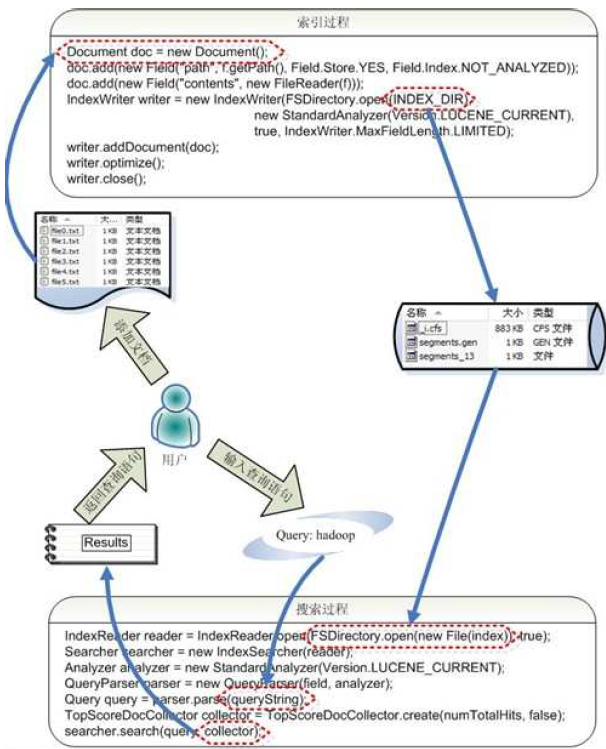
l 创建一个IndexWriter用来写索引文件,它有几个参数,INDEX_DIR 就是索引文件所存放的位置,Analyzer 便是用来对文档进行词法分析和语言处理的。
l 创建一个Document 代表我们要索引的文档。
l 将不同的Field 加入到文档中。我们知道,一篇文档有多种信息,如题目,作者,修改时间,内容等。不同类型的信息用不同的Field 来表示,在本例子中,一共有两类信息进行了索引,一个是文件路径,一个是文件内容。其中FileReader 的SRC_FILE 就表示要索引的源文件。
l IndexWriter 调用函数addDocument 将索引写到索引文件夹中。
搜索过程如下:
l IndexReader 将磁盘上的索引信息读入到内存,INDEX_DIR 就是索引文件存放的位置。
l 创建IndexSearcher准备进行搜索。
l 创建Analyer 用来对查询语句进行词法分析和语言处理。
l 创建QueryParser用来对查询语句进行语法分析。
l QueryParser 调用parser 进行语法分析,形成查询语法树,放到Query 中。
l IndexSearcher 调用search 对查询语法树Query 进行搜索,得到结果TopScoreDocCollector。
Lucene的各个模块:
l Lucene 的analysis 模块主要负责词法分析及语言处理而形成Term。
l Lucene的index模块主要负责索引的创建,里面有IndexWriter。
l Lucene的store模块主要负责索引的读写。
l Lucene 的QueryParser主要负责语法分析。
l Lucene的search模块主要负责对索引的搜索。
l Lucene的similarity模块主要负责对相关性打分的实现。
Lucene 的索引过程,就是按照全文检索的基本过程,将倒排表写成此文件格式的过程。
Lucene 的搜索过程,就是按照此文件格式将索引进去的信息读出来,然后计算每篇文档打分(score)的过程。
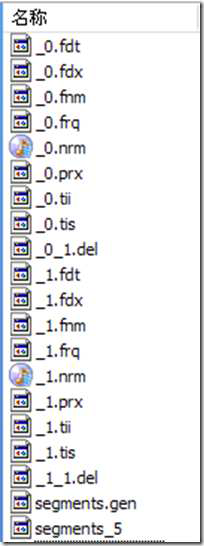
Lucene 的索引结构是有层次结构的,主要分以下几个层次:
l 索引(Index):
Ø 在 Lucene 中一个索引是放在一个文件夹中的。
Ø 如上图,同一文件夹中的所有的文件构成一个Lucene 索引。
l 段(Segment):
Ø 一个索引可以包含多个段,段与段之间是独立的,添加新文档可以生成新的段,不同的段可以合并。
Ø 如上图,具有相同前缀文件的属同一个段,图中共两个段 "_0" 和 "_1"。
Ø segments.gen 和segments_5 是段的元数据文件,也即它们保存了段的属性信息。
l 文档(Document):
Ø 文档是我们建索引的基本单位,不同的文档是保存在不同的段中的,一个段可以包含多篇文档。
Ø 新添加的文档是单独保存在一个新生成的段中,随着段的合并,不同的文档合并到同一个段中。
l 域(Field):
Ø 一篇文档包含不同类型的信息,可以分开索引,比如标题,时间,正文,作者等,都可以保存在不同的域里。
Ø 不同域的索引方式可以不同,在真正解析域的存储的时候,我们会详细解读。
l 词(Term):
Ø 词是索引的最小单位,是经过词法分析和语言处理后的字符串。
Lucene 保存了从Index 到Segment 到Document 到Field 一直到Term 的正向信息,也包括了从Term到Document 映射的反向信息,还有其他一些Lucene 特有的信息。
Index –> Segments (segments.gen,segments_N) –> Field(fnm, fdx, fdt) –> Term (tvx, tvd, tvf)
上面的层次结构不是十分的准确,因为segments.gen 和segments_N 保存的是段(segment)
的元数据信息(metadata),其实是每个Index 一个的,而段的真正的数据信息,是保存在域
(Field)和词(Term)中的。
段的元数据信息(segments_N)
域(Field)的元数据信息(.fnm),域(Field)的数据信息(.fdt,.fdx)
词向量(Term Vector)的数据信息(.tvx,.tvd,.tvf)
反向信息是索引文件的核心,也即反向索引。
反向索引包括两部分,左面是词典(Term Dictionary),右面是倒排表(Posting List)。
在Lucene 中,这两部分是分文件存储的,词典是存储在tii,tis 中的,倒排表又包括两部分,一部分是文档号及词频,保存在frq 中,一部分是词的位置信息,保存在prx 中。
Term Dictionary (tii, tis)
Frequencies (.frq)
Positions (.prx)
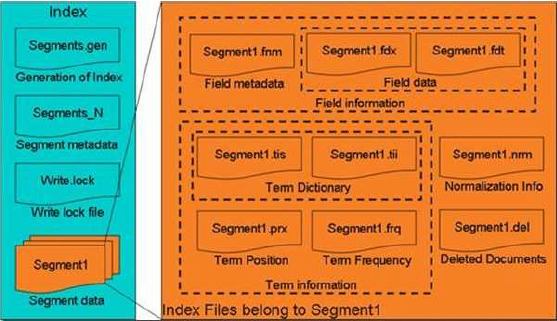
图为其Lucene索引文件的总体结构,
l 属于整个索引(Index)的segment.gen,segment_N,其保存的是段(segment)的元数据信息,然后分多个segment保存数据信息,同一个segment 有相同的前缀文件名。
l 对于每一个段,包含域信息,词信息,以及其他信息(标准化因子,删除文档)
l 域信息也包括域的元数据信息,在fnm 中,域的数据信息,在fdx,fdt 中。
l 词信息是反向信息,包括词典(tis,tii),文档号及词频倒排表(frq),词位置倒排表(prx)。
参考链接:http://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623594.html















 738
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









