






最近做的一个东西跟这个相关,本来希望是用深度学习对于没有标签的图像数据进行分类,但是通常情况下,深度学习是对有标签的数据进行学习,目的是用来自动提取特征,代替传统的手工提取特征。因此,比较容易想到,对于无标签又需要分类的图像数据,可以尝试先采用聚类来解决.
下面的内容是译自Jan Erik Solem的《Programming Computer Vision with Python》的第6章,该书已经由朱文涛和袁勇学长对该书进行了翻译,主要涉及相关代码和实例,可以转至http://yongyuan.name/pcvwithpython/。我仅对其中第6章的理论进行翻译,中途穿插自己的理解。
该博文仅供交流学习,如有侵权,请联系删除。
===================================================================================
(接上)
现在我们开始下一个基本的聚类算法。
6.2 层次聚类(Hierarchical Clustering)
层次聚类(或者叫做凝聚聚类)是另一个简单但是强大的聚类算法。其思想是基于成对距离建立一棵相似度树。该算法首先分组成为两个最近的对象(基于特征向量之间的距离),并且在一棵有着两个对象作为孩子的树中创建一个平均结点。然后在余下的结点中找到一个最近的pair,并且也包含任何平均节点,等等。在每一个结点,两个孩子之间的距离也会被存储。簇然后可以通过遍历这棵树并在距离比某个阈值小以至于决定聚类的大小的结点处停止来被提取出来。
层次聚类有几个优势。比如,树结构可以被用来可视化关系,并且显示簇是如何关联起来的。一个好的特征向量将得到树中好的分离。另一个优势是树可以在不同的簇阈值中被重用,而不需要重新计算树。缺点是需要选择一个阈值如果实际的簇需要的话。
让我们来看看这如何实现。创建一个文件hcluster.py,将下面的代码加进去。
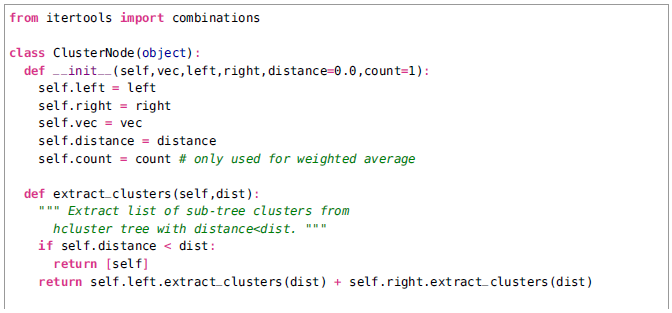
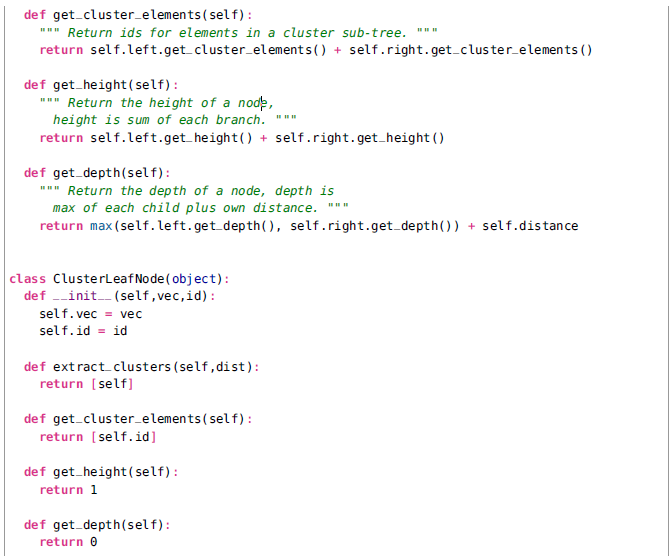
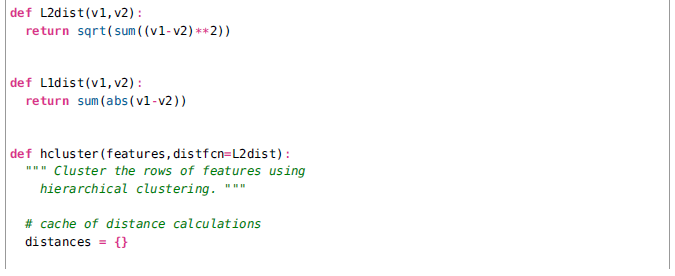
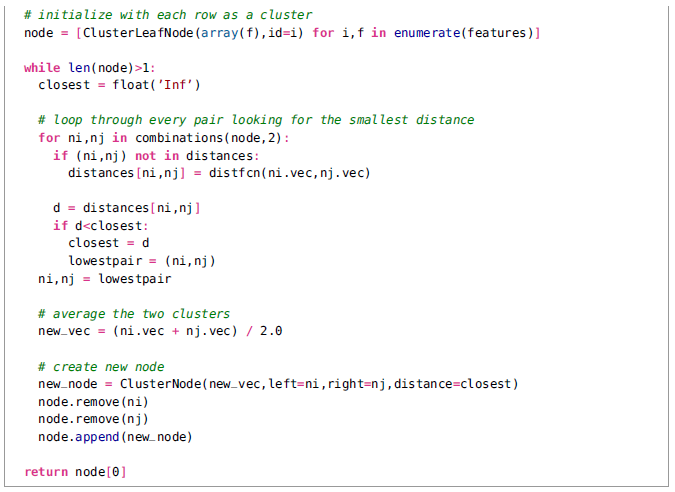
我们对树结点创建了两个类,ClusterNode和ClusterLeafNode分别用于创建簇树。函数hcluster()创建了树。首先一系列的叶子结点被创建,然后最近的对基于选择的距离度量被迭代地分组到一起。返回最后的结点将得到树的根节点。在一个将特征向量作为行的矩阵上面运行hcluster()可以创建和返回簇树。
距离度量的选择取决于实际的特征向量,这里我们使用欧几里得(L2)距离(对于L1距离的函数也是提供了的)但是你可以创建任意函数,并且可以将其作为参数传给hcluster(). 我们也使用了子树中的所有节点的平均特征向量作为一个新的特征向量来代表子树,并将每一棵子树看成对象。也有其他的方法来决定接下来合并哪两个节点,比如单连(Single Linking,在两棵子树的对象中使用最小距离)和全连(CompleteLinking, 在两棵子树的对象中使用最大距离)。连接的选择将影响生成的簇的类型。
为了从树中提取簇,你需要从顶层遍历树直到发现一个结点的距离值小于某个阈值。这个通过递归可以很容易实现。ClusterNode的方法extract_clusters()通过返回一个有结点本身小于距离阈值的队列,否则调用孩子结点(叶子结点总是返回自身)。调用这个函数会返回包含簇的子树队列。为了得到包含对象id的每一个簇子树的叶子结点,遍历每一个子树并使用get_cluster_elements()返回一序列的叶子。
接下来我们将它用在一个简单的例子中查看。首先创建一些2D的数据点(与上面的K均值一样)。

将点聚类,并使用某个阈值从列表中提取簇,并在控制台打印簇。

运行会得到类似下面的数据:

理想情况下,你应该得到两个簇,但是取决于实际的数据,也可能得到3个甚至更多的簇。在这个简单的聚类2D点的例子中,一个出应该包含小于100的值另一个包含100或者大于100的值。
图像聚类
下面我们看一个基于其颜色内容聚类图像的例子。文件sunsets.zip包含从Flickr使用标签“sunset”下载的100张图像。在这个例子中,我们将使用每张图像的一个颜色柱状图来作为特征向量。这样有一点粗糙和简单但是足够好地说明层次聚类做了什么。在包含sunset图像数据的目录下运行下面的代码。这里也可以将路径换成自己的图像数据集。

这里,我们将R,G和B颜色通道作为向量,并将他们传入NumPy的histogramdd()函数中计算多维柱状图(在这个案例中是三维)。我们在每一个颜色维度(8*8*8)中选择8箱,随后会在平展之后再特征向量中选择512箱。我们使用“normed=True”选项来归一化柱状图防止图像有不同的尺寸,并对每一个颜色通道设置范围为0…255. 一维的reshape()的使用设置为-1将自动决定正确的尺寸,因此可以创建对于计算包含RGB颜色值作为行的柱状图的输入数组。
为了可视化簇树,我们可以画一个树状图。树状图是显示树层次的图。这通常可以对一个给定的描述符有多好和在特殊情况下如何考虑相似性等问题给出有用的信息。将下面的代码加到hcluster.py中:

这里,树状图的描绘为每一个结点使用了draw()函数。将这个方法加到ClusterNode类中:

叶子结点有它们自己的特殊方法来画出实际图像的缩略图。将下面的代码加到ClusterLeafNode类中:


树状图(和它的字部分)的高度是由距离值决定的。这些需要被剪裁来适应被选择的图像分辨率。结点使用传递到下面层的坐标值迭代被画。叶子结点使用20x20像素的缩略图来画的。两个辅助函数被用来得到树的高度和宽度,get_height()和get_width()。
树状图通过下面的代码作图:

夕阳图像的聚类树状图在图5中。我们可以看到,,有相似颜色的图像在树中是很近的。图6给出了3个例子。

图5-在RGB坐标值作为特征向量使用一个512箱柱状图的100张夕阳图像的层次聚类
树中靠近彼此的图像具有相似的颜色分布。

图6-从有着层次聚类的100张夕阳图像中选出的样例聚类
使用树中最大结点距离的23%的阈值提取
这个样例中的聚类通过下面的代码被提取。

作为一个结束样例,我们可以为字体图像建立一个树状图:

其中projected和imlist分别表示的是在6.1节里K均值算法中使用的变量。结果树状图如下图7.

图7-使用40个主成分作为特征向量的66张选出来的字体图像的层次聚类

















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









