






文章目录
性能测试
理论知识
1. 概述
**为什么性能测试:**电商双11,抢红包,12306订票,服务器同时支持20000使用
性能关注点:时间特性(响应时间),资源特性(运行时服务器资源的消耗情况:CPU、内存、磁盘)
**性能测试:**使用自动化工具,模拟不同场景,对软件各项性能指标进行测试和评估的过程
- 代码性能,后台处理程序的性能
- 中间件(系统软件和应用软件的之间连接,tomcat,apache)、数据库 ,架构设计
- 服务器的资源消耗:CPU,内存,磁盘,网络
**目的:**评估系统能力,寻找 性能瓶颈,优化性能,评估软件是否满足未来的需要
性能与功能区别:
- 焦点不一样
- 功能:验证是否满足 功能需求规格,焦点在正向与逆向
- 性能:验证软件是否满足业务需求场景,焦点在业务场景的需要:时间、资源
- 关系
- 相辅相成
- 先功能后性能
2.性能测试类型
**性能测试策略:**基准测试,负载测试,稳定性测试,并发测试,压力测试,容量测试
基准测试:
-
单用户测试,测试环境确定后,对重要业务做单独的测试,获取但用户运行时的各项性能(获取基础的数据采集)
-
是一种测量和评估软件性能指标的活动,可以在某个时刻通过基准测试建立一个已知的性能水平(基准线),当软件硬件发生变化后再进行测试以确定那些变化对性能的影响
eg.原版本1.0为基准线,新版本1.1再进行测试
-
为多并发测试和综合场景测试提供参考依据,识别系统或环境配置对性能的影响,为系统优化前后性能的提升与下降提供指标
负载测试:
- 通过逐步增加系统负载(服务器承受的压力),测试系统性能的变化,再满足指标的情况下,最大的能承受的负载量的测试
- 负载:向服务器发送的请求数量,请求越多,负载越高
负载测试曲线图: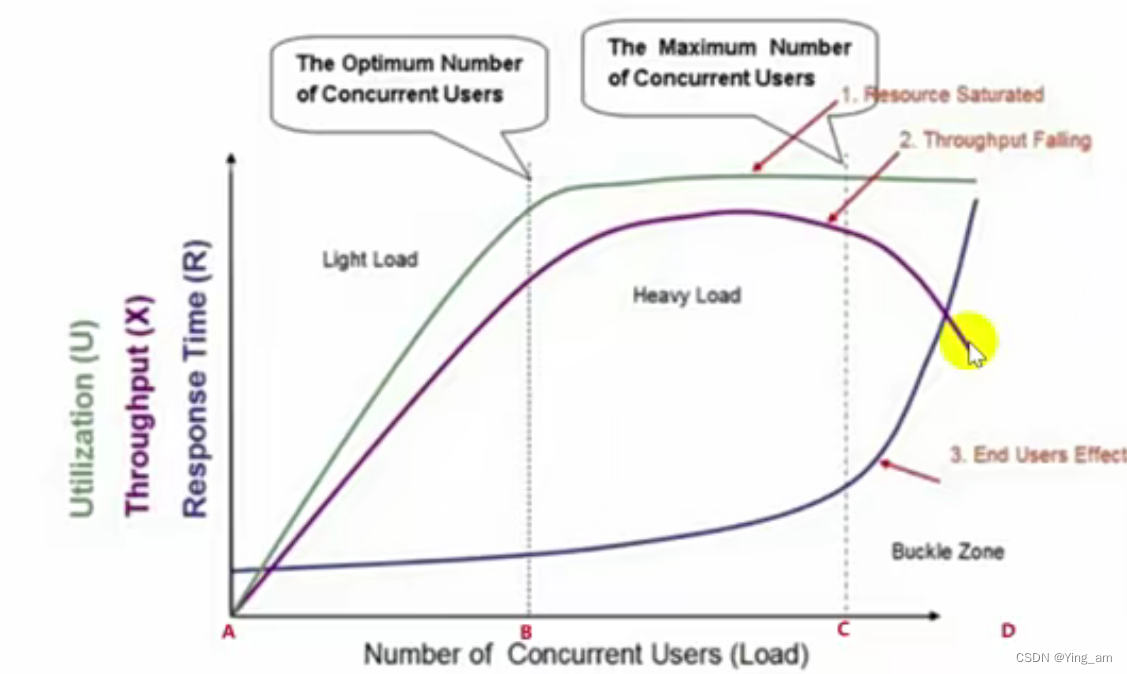
曲线1:服务器的资源,CPU、内存等
曲线2:系统的处理能力,1秒能处理多少请求
曲线3:做业务处理的响应时间
**稳定性测试:**在服务器稳定运行(业务正常负载量)的情况下进行长时间测试,保证服务器能满足线上业务需求,时长一般为1天、一周等(重点是时间)
**并发测试:**极短时间内,发送多个请求,验证服务器对并发的处理能力(资源竞争,相互等待):抢红包、抢购、秒杀
压力测试:在强负载(大数据量、大量并发用户等)下的测试,查看应用在峰值情况下使用,有效地发现系统地某项功能隐患、系统是否具有良好的容错能力和可恢复能力。压力测试分为高负载下的长时间的稳定性压力测试和极限负载情况下导致系统崩溃的破坏性压力测试
**容量测试:**软件在极限压力下各个极限参数值,最大TPS、最大连接数、最大并发数、最多数据条数
3.性能测试指标
**性能测试指标:**经过运算得出的结果,衡量性能的表追
响应时间、并发数、吞吐量、点击数、错误率、资源利用率、PV和UV
**响应时间:**客户端发送请求,到服务器收到响应,这个过程经历的全部时间,都是响应时间, =应用程序处理时间+网络传输时间
**并发数:**并发测试的用户数
系统用户数:系统注册的总用户数据
在线用户数据:某段时间内访问系统的用户数,这些用户并不一定同时向系统提交请求
并发用户数:某一物理时刻同时向系统提交请求的用户数
**吞吐量:**单位时间内处理的客户端请求数量,直接提现软件系统的性能承载能力
业务角度:用业务数/小时、业务数/天、访问人数/天、页面访问量/天来衡量
网络角度:字节数/小时、字节数/天来衡量
技术指标:每秒的事物数(TPS)、每秒查询数(QPS)来衡量
*TPS:*每秒事物数,单位时间内系统处理的客户端请求的事务次数
一个事务通常是界面上的一个操作,一个事务可以包含多个接口请求。如登录、支付
*QPS:*每秒查询数,服务器每秒处理的请求数(接口请求数)
**点击数:**衡量Web服务器处理能力的重要指标(针对Web)
是该页面包含的元素(图片、链接、代码)加载时,向服务器发送的请求数量
**错误率:**系统在负载情况下,失败业务的概率,错误率=失败业务数/业务总数
不同系统对错误率要求不同,<<0.5%(万分之几)
稳定性好的系统,错误率应该是由超时引起(来不及处理,资源耗光),即超时率
资源利用率:资源使用量/总的资源可用量
常用:CPU(80%)、内存(80%)、磁盘(90%)、网络(80%)
4.性能测试流程
- 性能测试需求分析
- 性能测试计划以及方案
- 性能测试用例
- 性能测试脚本编写/录制
- 建立测试环境
- 执行测试脚本
- 性能测试监控
- 性能分析和调优
- 性能测试报告总结
**对比功能测试流程:**需求分析评审、编写测试计划和方案、编写测试用例评审、执行测试用例和提交缺陷、编写测试报告
**性能测试需求分析
熟悉被测系统:熟悉业务功能、熟悉系统的技术架构
明确测试内容:
- 业务角度:确定关键业务,用户使用频率较高的业务功能
- 技术角度:逻辑复杂度较高,CPU密集运算较大的地方,数据量较大的业务占用系统内存
明确测试策略:负载、稳定、并发
明确测试指标:需求内有指标,若没有就对比类似系统,以及对未来流量的预估,确定指标
性能测试计划以及方案
项目背景、测试目的、测试范围、测试策略、风险控制、交付清单、进度和分工
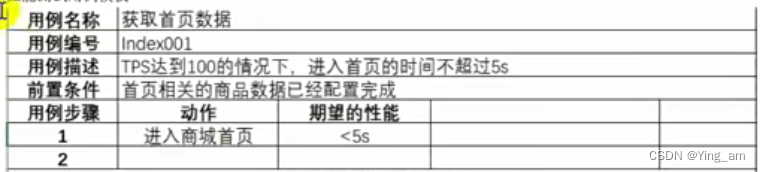
性能测试用例
要素:标题、编号、预置条件、步骤、预期结果、实际结果
**测试执行:**脚本编写、测试环境(与用户环境一致)、执行脚本、监控、分析与调优(只需确定是否存在性能bug,分析调优由开发人员完成)
**性能测试报告:**需求覆盖情况、测试过程回顾、测试中出现的问题、如何去分析调优解决的、风险如何控制、其他性能风险、经验教训、结论
jmeter
缺点:不支持ip欺骗,分析和报表能力相对与loadrunner欠缺精度
安装
- 安装JDK
- 环境变量
- 校验:java -version
- 安装JMter
- 环境变量
- 启动:1.jmter.bat 2.ApaceJMter.jar 3.命令行java -jar ApacheJMter.jar
文件目录
| bin目录 | 作用 |
|---|---|
| jmeter.bat | windows启动文件 |
| jmeter.log | jmeter日志文件,记录所有的错误信息 |
| jmeter.properties | jmeter配置文件,记录程序启动参数 |
| jmeter.sh | linux启动文件 |
| jmeter-server | linux下用于分布式执行的启动文件 |
| jmeter-server.bat | windows下用于分布式执行的启动文件 |
**docs目录:**api文档,api文件下的index.html,所有的api接口,主要用于二次开发
**printable_docs目录:**用户手册,usermanual下的index.html;核心元件的帮助文档,usermanual下的component_reference.html;demos子目录下是常用的jmeter脚本案例
**lib目录:**jmeter依赖的所有jar包,ext文件夹存放的是第三方插件
**汉化:**配置文件内改为language=zh_CN
元件
- 写脚本顺序:定义参数->对请求参数进行赋值->发送请求->收响应->提取响应->断言响应中的字段->观察运行结果
- 元件执行顺序:配置元件->前置处理器->取样器->后置处理器->断言->监听器
多个类似功能组件的容器(类似于类)
常见:取样器、逻辑控制器、前置处理器、后置处理器、断言、定时器、测试片段、配置元件、监听器
取样器:发送请求,request库
逻辑控制器:控制语言执行顺序,逻辑控制语句
前置处理器(后置处理器):请求发送之前(之后)执行,setup(teardown)
断言:assert;定时器:sleep
测试片段:封装的一段代码,供脚本调用,不直接执行,自己封装的基础类
配置元件:参数化,对参数进行赋值,自动化中的参数
监听器:查看脚本运行结果,结果打印
**作用域:**靠测试计划中的树形结构来判断
- 取样器:不和其他元件相互作用
- 逻辑控制器:对子节点的取样器起作用
- 其他元件:若父节点是取样器,则只对父节点起作用;否则,对父节点下的所有节点起作用
线程组:
- 普通线程组:发送业务请求的线程组,可并行可串行
- setup线程组:所有线程组之前执行
- teardown线程组:所有线程组之后执行
线程数:需要模拟的虚拟用户数
ramp-up-time:模拟的虚拟用户数全部启动所需要的时间;目的:模拟性能测试的场景,更加接近用户的使用习惯
参数化:
用户定义的变量:
- 测试计划->线程组->配置元件->用户定义的变量(或者在测试计划里也可以定义)
- 用${名称}引用变量
用户参数:
- 测试计划->线程组->前置处理器->用户参数,可定义用户,定义变量
- 用${名称}引用变量
CSV文件:
- 测试计划->线程组->配置元件->CSV文件
- 用${名称}引用变量
**函数助手对话框:**有很多函数可用,count函数生成动态变化的数值
eg. 1000个不同用户登录,用不同的测试金额数据访问支付接口
- 定义CSV文件,存放1000个账号密码
- 添加线程组,线程数设置为1000
- 添加CSV,读取,添加HTTP请求,引用CSV中数据登录接口
- 添加HTTP请求,支付接口,使用counter函数作为金额
- 添加查看结果树
断言
响应断言:
**JSON断言:**对JSON文档进行验证
- 解析JSON数据
- 使用Jayway JsonPath搜索指定的路径,找不到就会失败
- 找到JSON路径,并要求对期望值进行验证,执行验证操作
断言响应时间:超过设置的响应时间就报错
关联
一个请求与其他请求有联系
正则表达式、xpath关联、json关联

正则表达式提取器

xpath提取器

json提取器

线程组间关联
将提取到的数据通过函数助手变成jmeter属性
得到字符串放进beanshell取样器中
jmeter属性的引用:
自动录制脚本
在客户端和服务器中间,做一个代理的作用,收到的所有的请求和响应数据后,做一个逆向的解析动作,把数据报文转化为脚本
配代理:
系统配置
启动后录制的脚本
所有都会抓下来,所以设置过滤

cookie管理
例如在登录时需要保存cookie,后续请求都会带上cookie
其他功能
连接数据库
用来干嘛:验证数据是否正确,校验数据
预期结果并不固定,所以通过连接数据库实时查询数据库的响应
测试计划里进行导包

JDBC连接池配置
创建JDBC请求,查询数据库

url拼接的参数都是encodeURI进行编码了的,所以直接看不出来请求的参数
添加http请求,添加响应断言,注意先JDBC后http请求,注意数据库出来的数据名


逻辑控制器
常用:if、循环while、foreach
IF:添加用户定义的变量,在if控制器下添加http请求,没有else,所以全部用if,注意勾选框

报红:为了性能考虑,建议使用函数如下:

循环while:
与线程组循环的区别:作用域不同
foreach:与用户自定义变量或者正则表达式提取器搭配使用

定时器
又称:同步定时器(synchronizing timer),集合点(抢红包、双11秒杀)
相当于一个储蓄池,累积一定的请求,挡在规定时间内到达一定的线程数,这些线程就会在同一时间并发,用来做大数据量的并发请求(压力负载)
常数吞吐定时器(constant throughput timer):以指定吞吐量的速度发送请求

仅仅模拟固定吞吐量,帮助达到性能测试的负载压力要求,不能代表性能有无问题,对于bug分析需要通过响应时间来判断
分布式
针对测试机而言,模拟的负载太高(用户\请求),并发数较大,单台电脑无法模拟,用多个测试机一起模拟
由控制机控制多个代理机向测试机发送请求
通过帮助看教程
测试报告
聚合报告,报告响应时间


并发数计算
- PV页面访问量,刷新也算;UV唯一访问用户数,真实用户量
- 普通:TPS=总请求数/时间,问题:被平均了,不准确
- 二八:TPS=总请求数80%/时间20%
- 按照每天具体数据计算,模拟正常业务操作(稳定性测试)的并发量
- 大部分订单在8点到24点,时长为16h,该时间段订单量为总量的98%,以这两个数据做二八原则
- 按照每天具体数据计算,模拟峰值业务操作(压力性测试)的并发量
- 订单高峰在21点-22点,TPS=峰值请求/峰值时间*系数(系数是预测的)
常用图表
装插件
-
bzm - Concurrency Thread Group(并发线程组)

-
jp@gc - Transactions per Second(TPS每秒事物数)
-
jp@gc - Bytes Throughput Over Time(运行中的传输速率)
-
jp@gc - PerfMon Metrics Collector(监控后台资源)
- 需要监控文件 Server Agent,装在服务器上

服务器资源指标监控
商城项目
性能需求分析:重点杂物i与满足特定的业务需求场景(时间、资源)
性能测试点提取规则:
用户频繁使用、关键业务、特殊交易日峰值交易、核心业务重大调整、资源占用非常高的业务
eg. 登录、进入首页、搜索商品、商品详情、添加购物车、查看购物车、商品结算、提交订单、查看我的订单
测试目标:
- 核心业务功能TPS,响应时间
- 对业务流程多接口组合压测,(对功能连起来形成一套业务流程)
- 实际系统运行压力下稳定运行24h
测试计划
测试背景、测试目的、测试范围、测试策略(基准:单用户、负载:多用户、稳定性)、风险控制、交付清单、进度与分工
编写脚本
- HTTP信息头管理器:对请求头进行修改
- HTTP请求默认值:写协议、域名、端口、编码格式,在HTTP取样器中只写入路径、方法、参数。(换了测试环境,就直接修改默认值)
- 一个用例就是一个独立的线程组
整体用例:
发现问题1:没有携带token,但假如购物车成功
编写脚本的过程,常用的静态数据,可以写到用户定义的变量中,在脚本中进行引用,好处:可直接修改变量,不需要到每个脚本中修改
环境搭建
特点
- 不能混着用,对独立性要求更高,:某个环境下运行多个系统,很难判断对资源的占用情况
- 尽量保持性能测试环境与真实生成环境的一致性
如何保持一致性
- 硬件:服务器、网络
- 软件:版本一致、配置一致:操作系统、数据库、被测程序、三方软件
- 使用场景:基础业务数据一致(用户、商品数),业务操作模式一致(模拟用户使用真实场景)
测试数据准备:
相同sql语句在不同数据库的基础上,执行时间不同,因此需要构造与用户实际数量级的数据
import pymysql
#创建连接
conn=pymysql.connect(host='127.0.0.1',user='root',password='root',database='tpshop2.0',port=3306)
#创建游标
cursor=conn.cursor()
#建立sql语句
goods_sql = " "
#循环执行sql语句并提交事务
goods_start = 200000
for i in range(100000):
goods_id=goods_start+i;
sql=goods_sql.format(goods_id,goods_id,goods_id)
cursor.execute(sql)
conn.commit()
#关闭游标
cursor.close()
#关闭连接
conn.close()
执行测试脚本
- 执行测试脚本的测试机
- 分布式执行
eg 登录:将登陆时的用户名密码进行参数化,让不同用户进行登录,函数助手random
//未完
locust框架
nn=pymysql.connect(host=‘127.0.0.1’,user=‘root’,password=‘root’,database=‘tpshop2.0’,port=3306)
#创建游标
cursor=conn.cursor()
#建立sql语句
goods_sql = " "
#循环执行sql语句并提交事务
goods_start = 200000
for i in range(100000):
goods_id=goods_start+i;
sql=goods_sql.format(goods_id,goods_id,goods_id)
cursor.execute(sql)
conn.commit()
#关闭游标
cursor.close()
#关闭连接
conn.close()
**执行测试脚本**
1. 执行测试脚本的测试机
2. 分布式执行
eg 登录:将登陆时的用户名密码进行参数化,让不同用户进行登录,函数助手random
# //未完
## locust框架















 660
660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









