




摘要
本文详细介绍了基于ElasticSearch的RAG(检索增强生成)本地部署方案。RAG技术通过结合信息检索和文本生成,利用外部知识库增强大模型输出,减少幻觉现象。文章使用ElasticSearch作为向量数据库,配合本地部署的Ollama granite-embedding:278m嵌入模型(输出维度1536),实现了完整的RAG流程。部署过程包括:配置ElasticSearch向量存储(需确保维度匹配)、验证嵌入模型、处理文档读取(使用MarkdownDocumentReader)、设置相似度检索阈值和topK参数。实验通过自定义术语测试成功,证明系统能有效检索私有知识。
文章还分享了Redis作为向量数据库的尝试经验,包括Jedis连接工厂配置问题和RedisSearch模块依赖问题,最终选择ElasticSearch作为更稳定的解决方案。强调需使用ElasticSearch 8+版本以兼容KNN搜索算法,为本地RAG部署提供了实用参考。
RAG 简介
检索增强生成(Retrieval-Augmented Generation, RAG)是一种结合了信息检索和文本生成技术的新型自然语言处理方法。这种方法增强了模型的理解和生成能力(将相关数据整合到提示词中以获取精准的AI响应)。
RAG 涉及批次处理作业风格的编程模型,从文档中读取非结构化数据,对其进行转换,然后将其写入向量数据库。在高层次上,这是一个ETL(Extract、Transform and Load)管道。矢量数据库用于RAG技术的检索部分,作为将非结构化数据加载到向量数据库的一部分,最重要的转换之一是将原始文档拆分为更小的片段(pieces)。将原始文档拆分为更小的片段的过程有两个重要步骤:
-
将文档拆分为多个
部分(parts),同时保留内容的语义边界(semantic boundaries)。例如,对于包含段落和表格的文档,应避免在段落或表格的中间拆分文档(因为段落很有可能是用来解释表格的)。对于代码,应避免在方法实现的中间拆分代码。 -
将文档拆分后的每个部分进一步拆分为大小仅为AI模型
token限制的一小部分的部分。
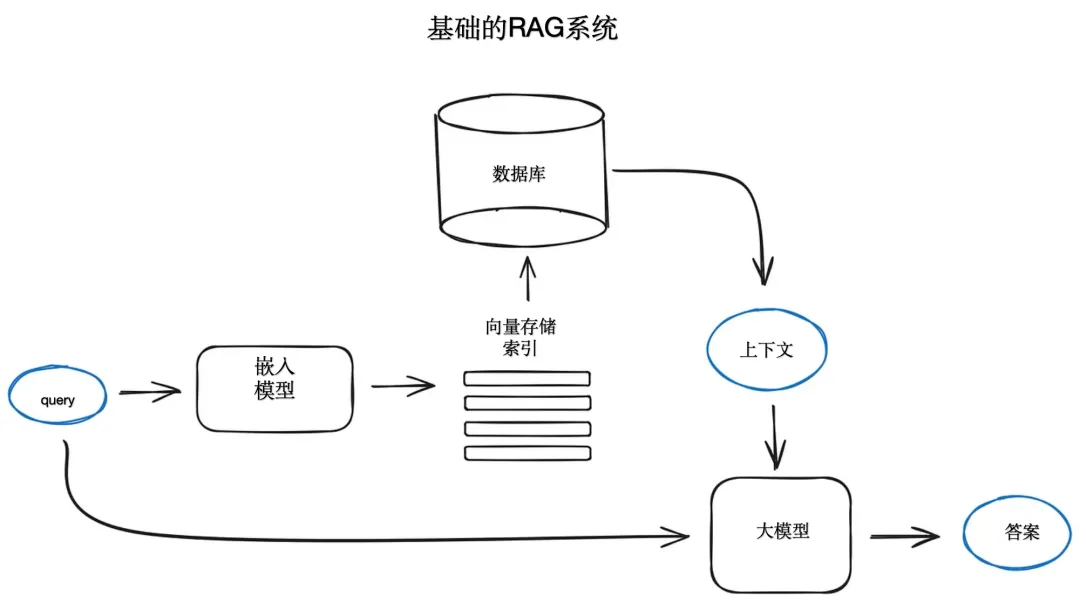
相比于传统的生成模型,检索增强生成可以通过添加来自其他数据源的上下文并通过培训补充大模型的原始知识库来提高搜索体验的相关性。 这增强了大型语言模型的输出,而无需重新训练模型。 其他信息来源的范围包括 LLM 未受过培训的互联网上的新信息、专有业务背景或属于企业的机密内部文件。
接下来我们用一个简单易懂的例子来解释 RAG。你是一个导游,在你的工作中遇到了问题。你把当导游时无法给游客提供专业、全面信息的困惑告诉了你的主管,于是主管给了你一本志愿者手册。游客询问最近的全聚德烤鸭店在哪里,你拿出了志愿者手册,翻到了全聚德烤鸭店的位置,然后告诉了游客具体的走法。

你又遇到了一个游客,游客眼睛不太好,他想知道如何前往银锭桥,此时你也犯难了,志愿者手册并没有该细节内容,但是此时游客手里有一张导览图,你接过地图,经过简单的分析,按照地图指出应该如何前往银锭桥。

假设我们是开发大模型导游助理的技术团队,我们把导游助理比作志愿者。
在第一种情况下,“志愿者手册”就是我们在开发系统的时候就配置好的知识库,因此导游助理可以从系统默认的知识库中获取烤鸭店的地址,然后生成导航路径给游客。
在第二种情况中,假设我们的系统支持用户上传个性化资料,来更好地满足个性化业务需要。换句话说,系统支持用户添加垂直领域知识,构建私域知识库。那么,当游客向志愿者提供一份个性化导航资料时,系统可以结合游客的垂直领域知识与系统预置的知识共同为游客提供服务。
第一种方案的知识库,可以理解是公司统一配置的知识库;第二种方案中,每个团队或者用户还可以根据自己的需要来增加私域定制化知识库。显然,第二种系统更灵活,不需要复杂的操作就能补充了业务知识。但总体来看,这两个系统都是通过知识库来增强导游助理的能力,减少幻觉(Halluciation)回答的情况(即导游助理不是编造一个像模像样的地址,而是按照已有知识来回答)。
在这个案例中,我们明白了检索增强生成包括三个步骤,建立索引、检索、生成。如果说大模型导游助理是一位志愿者,那么我们给志愿者们准备“志愿者手册”的过程就是建立知识库索引,志愿者查看资料就是系统在检索知识库,志愿者基于检索到的资料充分思考并回答用户的问题就是生成答案。
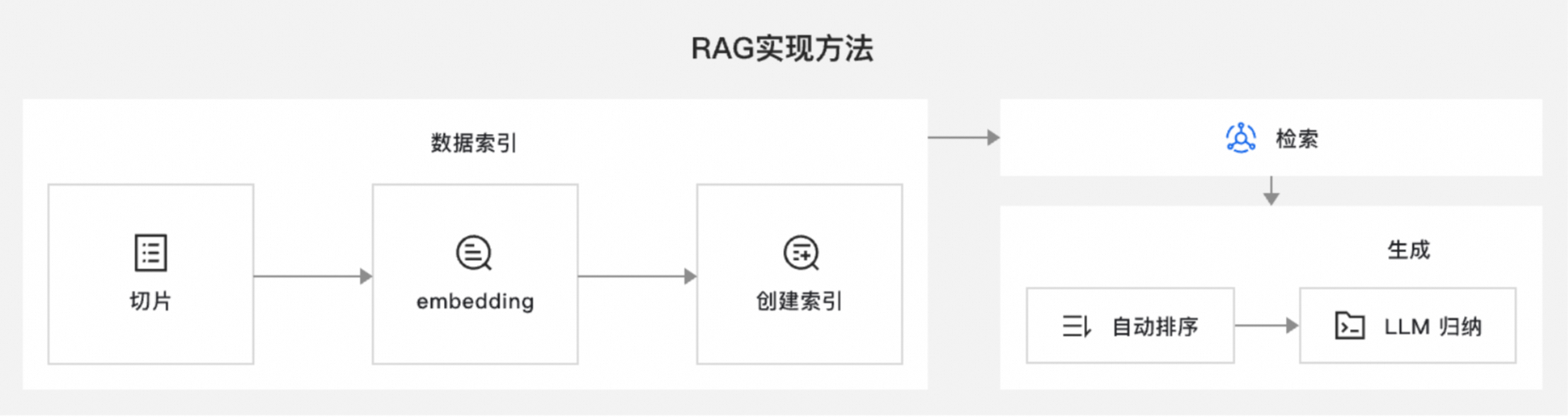
在 Spring AI 中的大体过程是:
-
将文档以
语义向量的方式存入向量数据库;使用 Embedding 模型将文本向量化。 -
大模型根据用户的提问,再进行向量化后,去向量数据库中根据相似度算法(比如
余弦相似)比对 -
根据相似度阈值(代码中的
SimilarityThreshold),选出相似度大于等于相似度阈值的所有文档 -
再选出最为相似的
K条,这个算法称为topK -
将选出的文档作为上下文提供给大模型
-
大模型根据提供的上下文回答

Flower and Mirror,由美国印象派画家阿博特·富勒·格雷夫斯(Abbott Fuller Graves)创作
代码配置
在这之前,确保你已经启动了 ElasticSearch,我使用的是 windows 平台:
# 先删除现有服务(如果存在)
elasticsearch-service.bat remove
# 重新安装服务
elasticsearch-service.bat install
# 启动服务
elasticsearch-service.bat start新版 Spring AI 默认使用的 KNN 算法不兼容 ElasticSearch 8 版本以下;建议使用 8 版本的 ElasticSearch
引入依赖,我使用的是 spring initializer,所以版本信息被配置好了:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-elasticsearch</artifactId>
</dependency>配置信息如下:
# RAG
spring.ai.vectorstore.elasticsearch.dimensions=1536
spring.ai.vectorstore.elasticsearch.index-name=tou-hou-agent-index
spring.ai.vectorstore.elasticsearch.initialize-schema=true
spring.ai.vectorstore.elasticsearch.similarity=cosine
spring.elasticsearch.password=${ES_PASSWORD}
spring.elasticsearch.username=${ES_USERNAME}在配置任意 VectorStore 时,确保维度数量与 EmbeddingModel 相同。否则将导致在调用
vectorStore.add(..)出现parse fail错误。详细的异常信息只能通过 IDE 调试发现,因为在源码中,输出的只是parse fail。
这里使用的 EmbeddingModel 为本地部署的 granite-embedding:278m ,其输出的向量维度为 1536。如果你不知道你的 EmbeddingModel 的输出向量的维度是多少,则可以配置一个 Validator Bean:
@Component
@ConditionalOnProperty(name = "spring.ai.vectorstore.elasticsearch.index-name")
public class VectorStoreValidator {
private final VectorStore vectorStore;
private final EmbeddingModel embeddingModel;
public VectorStoreValidator(VectorStore vectorStore, EmbeddingModel embeddingModel) {
this.vectorStore = vectorStore;
this.embeddingModel = embeddingModel;
}
@PostConstruct
public void validateSetup() {
try {
// 测试嵌入
List<String> texts = List.of("东方Project角色博丽灵梦");
List<float[]> embeddings = embeddingModel.embed(texts);
int dimension = embeddings.get(0).length;
System.out.println("✅ 嵌入维度: " + dimension);
// 测试存储
Document document = new Document(
"博丽灵梦是东方Project中的主角,是博丽神社的巫女",
Map.of("category", "角色", "source", "东方Project")
);
vectorStore.add(List.of(document));
// 测试搜索
List<Document> results = vectorStore.similaritySearch("博丽灵梦");
System.out.println("✅ Elasticsearch VectorStore 配置成功!");
System.out.println("✅ 搜索返回结果数: " + results.size());
} catch (Exception e) {
System.err.println("❌ 配置验证失败: " + e.getMessage());
e.printStackTrace();
}
}
}这里使用本地部署 Embedding Model 的原因是:不限制 Batch Size 限制。我之前使用的 DashscopeEmbeddingModel 限制 BatchSize 为 10 以内。
配置 BatchSize 的方式是在 IoC 中提供一个 BatchingStrategy ,spring ai 默认提供了 TokenCountBatchingStrategy ,你可以提供一个自定义参数的 TokenCountBatchingStrategy 类,以控制 Batch Size。我目前还为进行实践。另一个方案是通过配置的方式实现对 batch-size 的控制
然而在我同时引入 dashscope starter 以及 ollama starter 时,只出现了 ollama 的 batch 配置。以下是在调用 dashscope 时的异常信息:
Caused by: org.springframework.ai.retry.NonTransientAiException:
HTTP 400 - {"request_id":"de445ba7-5890-93c7-a360-0e8b6095c059","code":"InvalidParameter","message":"<400> InternalError.Algo.InvalidParameter: Value error, batch size is invalid, it should not be larger than 10.: input.contents"}我使用的是 ollama 本地部署,配置如下
spring.ai.ollama.embedding.model=granite-embedding:278mollama 的 embedding model 不需要 run 启动,只需要 pull 完成即可。
实验
实验方式:定义一个网络中从未出现过的名词,然后给出其定义,如果 AI 能够回答这个名词的定义,那么 RAG 实验成功。
Spring 提供了很多不同类型文件的读取接口,比如 html reader json reader。这里使用的是 markdown reader 。先引入依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
</dependency>然后定义一个用于从本地路径读取文件的组件:
@Component
public class MarkdownDocumentLoader {
private static final Logger log = LoggerFactory.getLogger(MarkdownDocumentLoader.class);
private final ResourcePatternResolver resolver;
// ...
}我打算直接在类路径中读取,所以使用了 ResourcePatternResolver ,spring web 已经提供了这个 Bean,所以可以直接注入。
定义 read 方法如下:
/**
* 从包路径读取指定位置的Markdown文档
*
* @param location 文档位置,比如 "classpath:document/*.md"
*/
public List<Document> read(String location) {
try {
log.debug("try to read markdown documents from {}", location);
return Arrays.stream(resolver.getResources(location))
.map(resource -> {
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(true)
.withAdditionalMetadata("filename", Optional.of(resource.getFilename()).orElse(""))
.build();
return new MarkdownDocumentReader(resource, config).get();
})
.flatMap(Collection::stream)
.toList();
} catch (Exception ex) {
log.error("Error reading markdown document", ex);
throw new RuntimeException(ex);
}
}对于 document reader 使用的方式,可以去 Spring AI ETL Pipeline 进行学习;或者直接复制我的代码。定义好这个组件后,定义配置后的 VectorStore
@Bean
public VectorStore customisedVectorStore(VectorStore vectorStore,
MarkdownDocumentLoader markdownDocumentLoader) {
final List<Document> documents = markdownDocumentLoader.read("classpath:document/*.md");
log.debug("documents: {}", documents);
vectorStore.add(documents);
return vectorStore;
}VectorStore 提供者是 spring-ai-starter-vector-store-elasticsearch ,我们拿过来,存入一些文档,你也可以使用 CommandRunner ,一种更优雅的方式来实现这个逻辑。
我在 resource/document 中定义了一个文件rag-test.md,内容如下:
# Glossary
定义 HUFENGS-LG9 是一个地球上的实体,它是一个机器人;被建造于 1999 年 8 月 14 日。
它喜欢吃苹果。接下来组装 RetrievalAugmentationAdvisor 并配置到 ChatClient 中:
@Bean
public VectorStoreDocumentRetriever vectorStoreDocumentRetriever(VectorStore vectorStore) {
return VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.5)
.vectorStore(vectorStore)
.topK(5)
.build();
}
@Bean
@Scope("singleton")
public ChatClient ollamaChatClient(ChatModel ollamaChatModel,
RedisChatMemory redisChatMemory,
VectorStoreDocumentRetriever vectorStoreDocumentRetriever
) {
return ChatClient.builder(ollamaChatModel)
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(redisChatMemory).order(1).build(),
RetrievalAugmentationAdvisor.builder()
.order(2)
.documentRetriever(vectorStoreDocumentRetriever)
.build(),
new SimpleLoggerAdvisor())
.build();
}
代码 4 行 SimilarityThreshold 是相似性阈值,这已经在 RAG 简介 中提到过了。组装完成后,进行测试
@Autowired
private ChatClient ollamaChatClient;
@Test
public void testChatModelRAG() {
ollamaChatClient.prompt("HUFENGS-LG9 是什么?")
.stream()
.content()
.filter(StringUtils::hasText)
.subscribe(System.out::println);
try {
TimeUnit.MINUTES.sleep(1L);
} catch (InterruptedException ignore) {}
结果如下:
<think>
嗯
,
用户
问
的是
“
H
UF
EN
GS
-L
G
9
是
什么
”,
还
提供了
四
条
几乎
相同的
重复
信息
作为
上下
文
。
这
有点
奇怪
啊
,
连续
四个
定义
都
一
模
一样
,
连
标
点
都没
变
过
。
首先
注意到
这个
实体
的
描述
非常
基础
:
地球
上的
机器人
,
1
9
9
9
年
8
月
1
4
日
建造
,
喜欢吃
苹果
。
用户
可能
是在
测试
我的
记忆
一致性
功能
?
或者
想
看看
重复
信息
会不会
影响
回答
准确性
?
考虑到
这是
中文
查询
,在
思考
如何
组织
答案
时
应该
保留
原文
特征
并
精确
遵循
规则
:
第一条
规则
是
如果
不知道
就
直接
说
不知道
。
但从
上下
文
看
确实
知道
相关信息
。
第二
条
要求
避免
“
基于
上下
文
”
这类
引导
语
,
所以
要用
陈述
句
而非
条件
句
作
答
。
这个
机器人
实体
的
名称
很
特别
,“
H
UF
EN
GS
-L
G
9
”的
命名
方式
有点
像
工业
代
号
或
内部
系统
标识
符
。
回答
时
需要
保持
原
样
不
擅自
修改
,并
且
严格
对应
所有
四
条
重复
信息
的内容
点
。
用户
似乎
只需要
一个
简单
直接
的答案
,
不需要
额外
解释
为什么
有
这么多
重复
信息
。
</think>
根据
提供的
上下
文
:
H
UF
EN
GS
-L
G
9
是
一个
地球
上的
实体
,
它
是一个
机器人
;
被
建造
于
1
9
9
9
年
8
月
1
4
日
。
它
喜欢吃
苹果
。
注意
:
所有
提供的
信息
都是
关于
同一个
主题
的
重复
内容
。根据结果,我发现 deepseek 思考的问题:
嗯,用户问的是“HUFENGS-LG9 是什么”,还提供了四条几乎相同的重复信息作为上下文。这有点奇怪啊,连续四个定义都一模一样,连标点都没变过。
这似乎为我们的主角(AI) 造成了一些困惑,通过使用瞪眼法发现,为了保证实验的正确性,我前后运行了4次代码,这导致文档被重复插入到了向量数据库中
@Test
public void test() {
final List<Document> documents = vectorStoreDocumentRetriever.retrieve(Query.builder()
.text("HUFENGS-LG9 是什么?")
.build());
System.out.println(documents.size());
documents.forEach(document -> {
System.out.println(document.getText());
});输出
4
定义 HUFENGS-LG9 是一个地球上的实体,它是一个机器人;被建造于 1999 年 8 月 14 日。 它喜欢吃苹果。
定义 HUFENGS-LG9 是一个地球上的实体,它是一个机器人;被建造于 1999 年 8 月 14 日。 它喜欢吃苹果。
定义 HUFENGS-LG9 是一个地球上的实体,它是一个机器人;被建造于 1999 年 8 月 14 日。 它喜欢吃苹果。
定义 HUFENGS-LG9 是一个地球上的实体,它是一个机器人;被建造于 1999 年 8 月 14 日。 它喜欢吃苹果。总体来看,实验目的达成了。
后续工作
防止文档被重复插入向量数据库。
定义 BathStrategy ,提供兼容性更强的组件。
研究 RetrievalAugmentationAdvisor 在 advisor 链中的位置问题,比如:如果 RAG 放在 ChatMemory 之前,那么将导致文档被存入记忆数据库中,Advisors 应该如何排列?
研究文档被拆分为 pieces 的策略
目前只能读取 markdown 文档,实际使用时需要读取支持更广的文档类型。
一些关于 Redis VectorStore 的经验
之前使用 Redis 部署向量数据库经历了曲折的过程,最终以失败而告终(不想折腾了);过程总结如下:
-
使用 Redis 作为向量数据库时发现Bean VectorStore 并未被加载;通过给 IoC 开启 DEBUG 模式:
logging.level.org.springframework.boot.autoconfigure=DEBUG logging.level.org.springframework.context=DEBUG发现
RedisVectorStoreAutoConfiguration: Did not match: - @ConditionalOnBean (types: org.springframework.data.redis.connection.jedis.JedisConnectionFactory; SearchStrategy: all) did not find any beans of type org.springframework.data.redis.connection.jedis.JedisConnectionFactory (OnBeanCondition)Spring 没有找到
JedisConnectionFactorybean,因为 SpringBoot 3.5.4 默认使用的是letture解决方法是通过配置更换 Redis 客户端的类型:spring.data.redis.client-type=jedis -
在解决完上述问题后;新的问题如下:
Caused by: redis.clients.jedis.exceptions.JedisDataException: ERR unknown command 'FT._LIST',原因是 Redis 没有安装 RedisSearch;解决方案如:拉源码,编译,配置 Redis;以及使用 docker 部署
redis-stack或使用 windows sub system for linux ;因为我使用的平台是 windows,编译太麻烦;而之前因为玩 战地6 把系统虚拟化关了,所以都不想尝试了。
最终解决:使用 ElasticSearch 作为向量数据库。



















 1386
1386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











