






作者丨黄浴@知乎
来源丨https://zhuanlan.zhihu.com/p/467776433
编辑丨3D视觉工坊
arXiv在2022年1月15日上传论文“A Critical Analysis of Image-based Camera Pose Estimation Techniques“,作者来自伦敦Queen Mary大学、北航大学和滴滴公司。

摄像机,及其视场内的目标,其定位使许多计算机视觉领域受益,如自动驾驶、机器人导航和增强现实(AR)。经过几十年的发展,摄像头定位,也称作摄像头姿态估计,可以计算给定图像中摄像头相对于序列中不同图像的目标6-自由度(DOF)姿态。基于结构的定位方法,在与图像匹配或坐标回归集成时,取得了巨大成功。使用迁移学习的绝对和相对姿势回归方法,可以支持端到端定位直接回归相机姿势,但性能不太准确。尽管这一领域的多个分支发展迅速,但缺乏全面、深入和比较的分析来总结、分类和比较基于结构和基于回归的摄像机定位方法。
现有综述,要么关注较大的SLAM(同步定位和制图)系统,要么只关注摄像头定位方法的一部分,缺乏对所用方法或数据集、神经网络设计(如损失设计)和输入格式等方面的详细比较和描述。
该文章首先介绍了摄像机定位姿势的具体应用领域,以及根据不同子任务(基于学习的2D-2D任务、基于特征的2D-3D任务和3D-3D任务)的评估指标。然后,回顾基于结构的摄像机姿态估计方法、绝对姿态回归和相对姿态回归的常用方法,并对这些方法进行批判地建模,激发算法(如损失函数、神经网络结构)的进一步改进。此外,文章还总结了用于摄像机定位的普遍数据集,并将这些方法的定量和定性结果在详细性能指标上进行比较。最后,文章讨论了未来的研究可能性和应用。
首先看看下表是之前的综述比较:
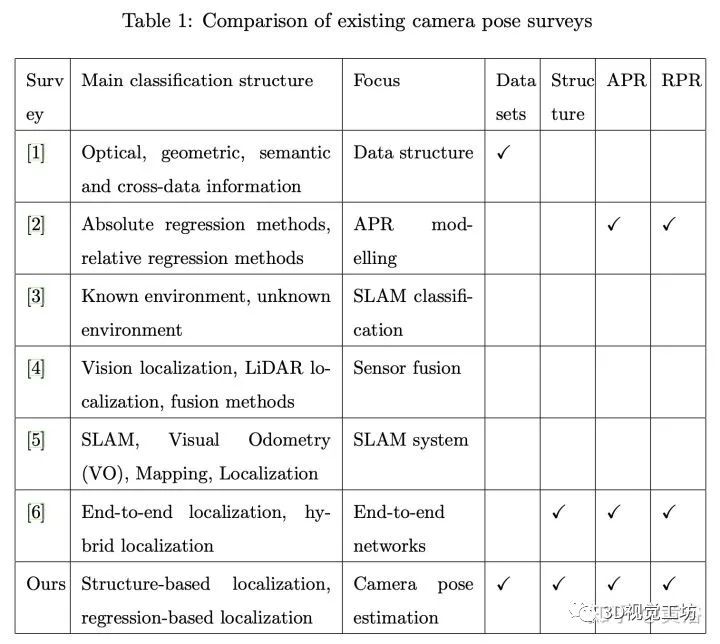
现有的摄像头姿势综述不倾向于就数据集和人工神经网络(ANN)的损失函数和输入格式(如单幅图像、图像序列和视频)进行详细比较。此外,由于一些姿态估计方法是建立在图像检索或图像匹配的基础上,该综述建立了一个两阶段方法模型。第一阶段是检索参考图像中最相似的图像或从输入图像对中获得匹配对应;第二阶段是基于检索或匹配结果回归到摄像头姿态。
本综述总结并分类在基于结构的姿势估计阶段摄像机姿势估计的图像匹配方法,并试图解决其他综述中对此类基于匹配或检索摄像机姿势估计问题描述的缺失。有关ANN分析(包括损失函数)方面,该综述还回顾基于结构方法和基于回归方法(包括APR方法和RPR方法)。此外,该综述还建立不同模型的定位中心公式,例如2D-2D定位、2D-3D定位和3D-3D定位,以及不同的多数据集格式(例如,单图像、图像序列和视频)和环境。
摄像机姿态估计研究的主要分支,包括基于结构特征和基于回归的姿态估计方法。
基于结构特征的定位流水线,是指通过在查询图像中的特征和场景模型中的三维结构特征之间建立对应关系,恢复摄像头姿势,其中3D点云模型是用记录整个场景结构的SFM或SLAM来构建的。与仅基于图像中的目标特征做相机姿态回归的方法相比,基于结构特征的流水线更依赖于三维场景模型的先验信息。
在场景模型的3D点云与查询图像之间建立对应关系后,可以通过几何约束恢复摄像头姿态,这是一个经典的流水线,应用PnP来计算摄像头姿态,并使用RANSAC方法来去除异常值。
根据目标的查询图像和三维感测模型之间建立对应关系的方法,可以将基于结构特征的定位方法分为两类:基于匹配的定位和基于场景坐标回归的定位。第一种方法基于描述子匹配,另一种方法基于可训练的定位流水线。
这些匹配方法试图在查询和场景之间高效地生成精确的对应关系。然后,通过RANSAC环应用PnP解算器来计算摄像头姿势。因此,匹配模块的精度在很大程度上决定了定位的精度。
基于场景坐标回归的定位方法直接从查询图像回归3D场景坐标。也就是说,训练一个随机森林或一个神经网络来直接预测像素的3D场景坐标。这样,图像中的2D点和场景中的3D点之间的对应关系可以在不进行特征检测和描述以及显式匹配的情况下得到致密的结果。目前这种方法只适合小尺度场景中,在大尺度场景没有证明其有效性。
基于回归的姿势估计方法,根据过程是端到端直接的,还是集成图像检索或CNN过程的两阶段(获得参考图像姿势,然后获得摄像头姿势),将这些方法分为绝对摄像头姿势回归和相对摄像头姿势回归。
绝对摄像头姿态回归的目的,是优化网络权值,通过CNN预测参考图像的6-自由度(DOF)姿态,直接将图像的位置和方向信息输出到回归器。网络输入可以是多种格式,即单个图像、图像序列还是视频。
继单目图像或辅助学习之后,现有的APR问题研究工作主要通过 1)更换编码器网络或添加一些模块进行改进;2) 修正网络损失函数;3) 用更多图像或增加时空限制来增强图像数据。
辅助学习是指结合绝对姿势回归和辅助任务约束(例如视觉里程计)。辅助学习方法中的损失函数通常包括APR损失和辅助任务损失。所有上述方法都可以用来获得相机的绝对姿态。甚至可能使用流水线中的相对损失。
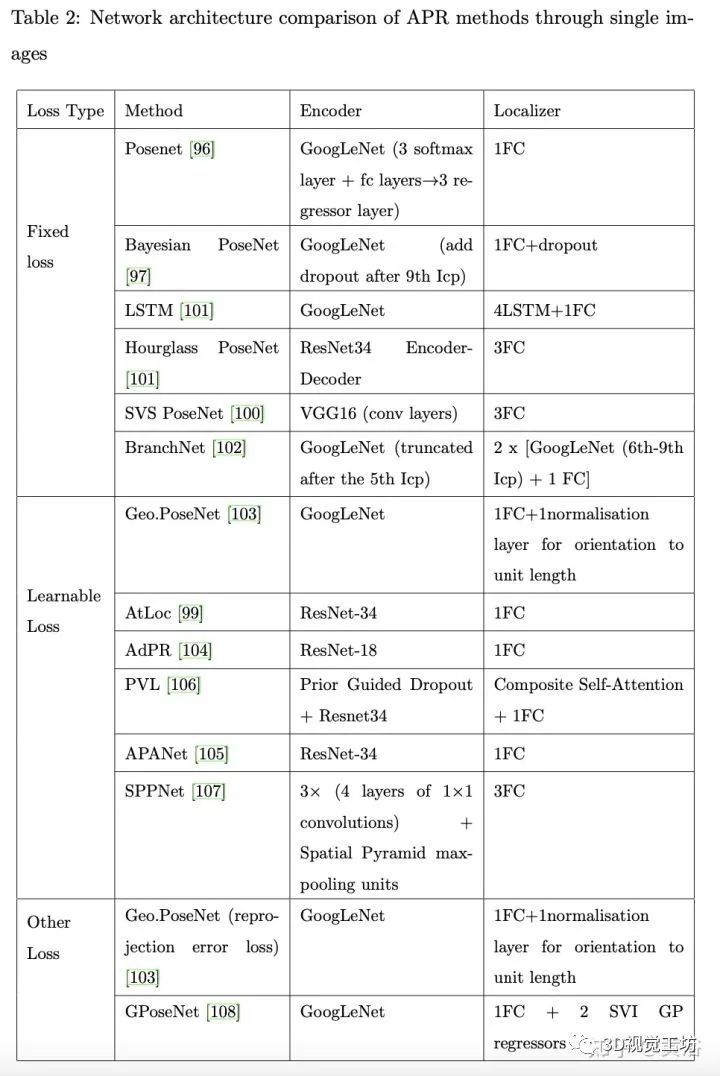
如下表是单目图像方法的网络比较:
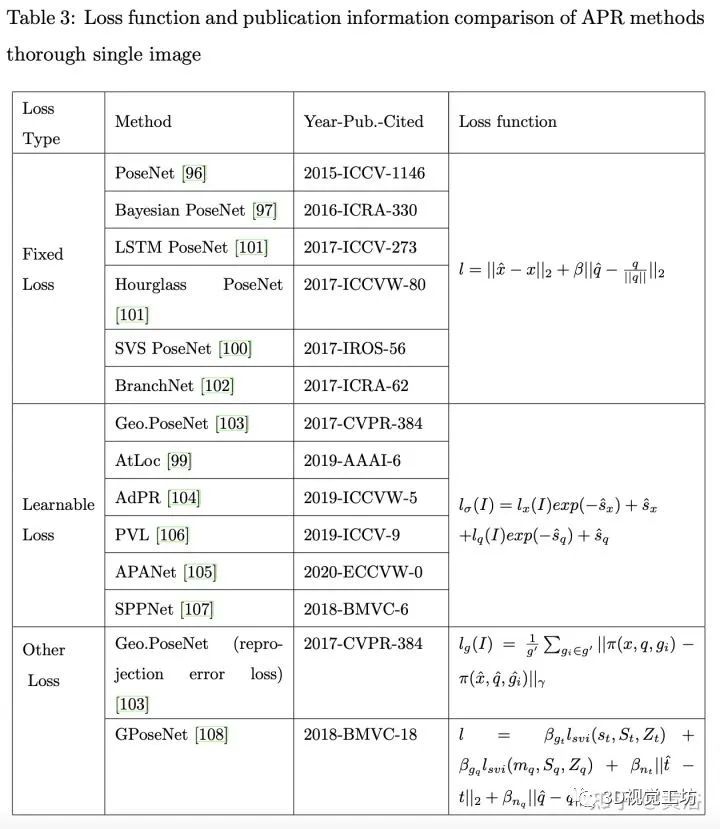
下表是损失函数的比较:
与单图像的方法不同,通过图像对的辅助学习,通常首先估计具有辅助约束的相对姿态来学习绝对姿态。这可能涉及全局一致的姿势预测,以提高定位性能,即减少定位误差,并提高定位鲁棒性。
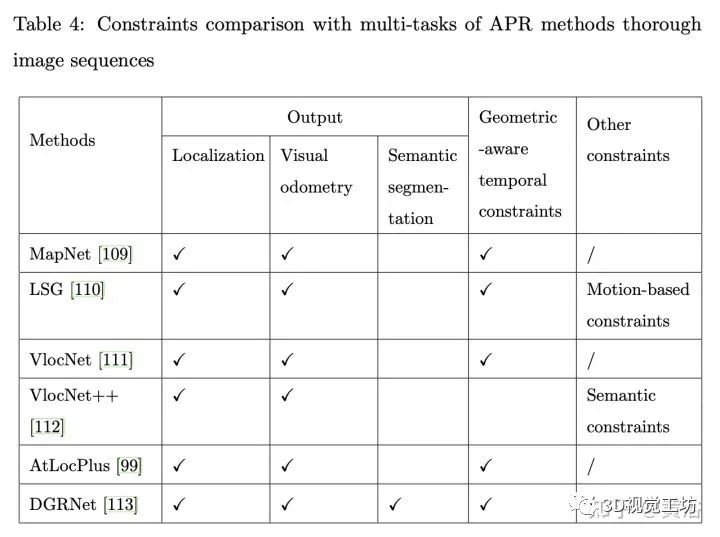
下表是图像序列的方法约束比较:
下表是其损失函数的比较:
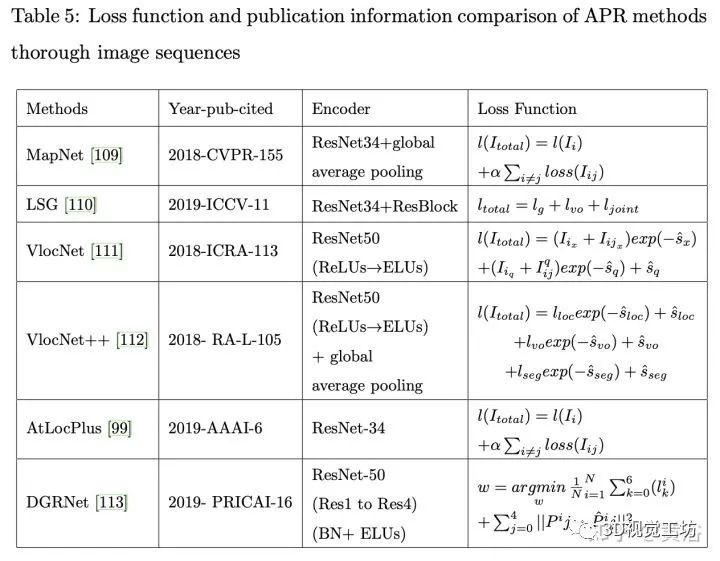
通过对齐时间戳,可以使用时间信息将视频同步到其他输入数据,如视觉里程计、惯性测量单元(IMU)传感器,如加速度计和陀螺仪,以及GNSS数据。与基于单图像和基于图像序列的APR方法类似,基于视频的APR方法通过CNN特征提取和定位器回归,回归平移和方向,同时得到视频同样的其他辅助信息。
下表给出视频的方法在损失函数的比较:
最近的研究表明,与基于结构的方法相比,APR方法的精度较低,而且过拟合。随着基于相对姿势回归的定位方法出现,这些方法可以用于场景特定的环境。训练过程通常可用于多个场景。
直接的绝对摄像头姿态回归模型,学习从目标像素图像到摄像头姿态的映射,该映射由特定场景所在的坐标系决定。因此,跨场景学习带来了有界的坐标转移,并提供了可学习的物理几何知识。
与场景特定的绝对姿势回归不同,相对摄像头姿势回归方法计算参考图像的相对姿势,并在一般多个未见过场景上进行训练,以端到端的方式增加扩展性。
相对摄像头姿态回归可以通过先前的图像检索过程来计算,该过程计算数据库中与查询图像最相似的图像,然后预测它们之间的相对姿态,最后得到查询图像的绝对姿态。
为了回归相对姿势,基于检索的方法利用多阶段策略最终获得绝对姿势,检索步骤是该过程的基础。基于CNN的方法提供了另一种在网络隐式回归相对姿势的方法。
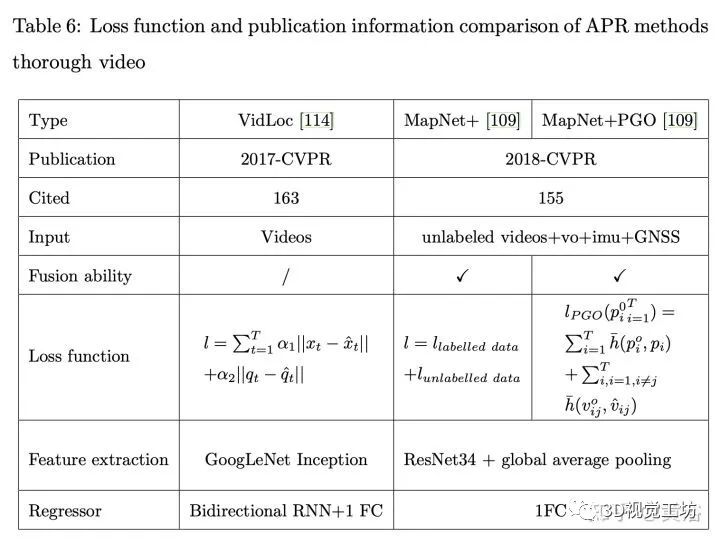
如表是RPR损失函数的比较:
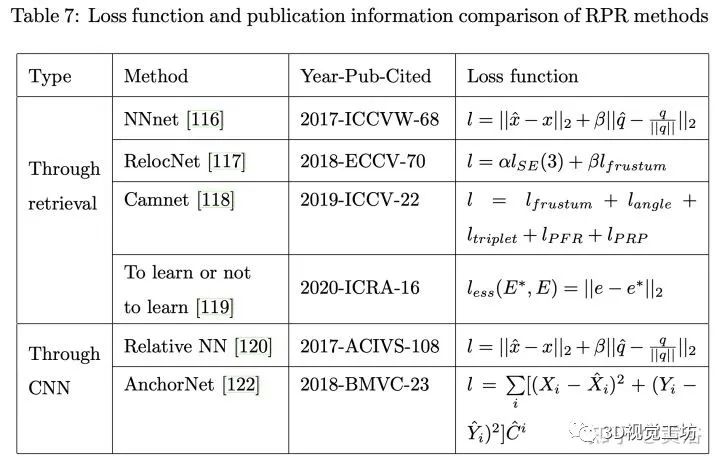
下表对一些普遍的摄像头定位数据集进行比较:
通常,与端到端方法(包括APR)相比,基于结构的方法实现了更高的精度。一些RPR方法继续追求基于结构的方法的精度,但流水线不那么复杂。基于检索的方法效果最差,因为它使用检索的图像姿势作为计算值。基于结构特征的定位方法依赖于二维查询特征与三维模型之间的对应关系。基于匹配的方法通过匹配特征描述子,建立场景模型中三维点云与二维查询图像特征之间的对应关系。
摄像头定位算法的应用已经相当成熟。但是,对于那些重复的局部特征,它们仍然很脆弱,并且仍然存在计算要求高的问题。大部分工作集中在2D图像中极端条件下的鲁棒特征点或精确特征描述子上。在更复杂的应用中,应该考虑3D空间几何对二维特征的约束,例如,大多数现有的场景坐标回归方法只能在小场景中采用,还没有在大型场景中证明。对于稳健性或准确性、准确性或效率,需要仔细考虑因素权衡。
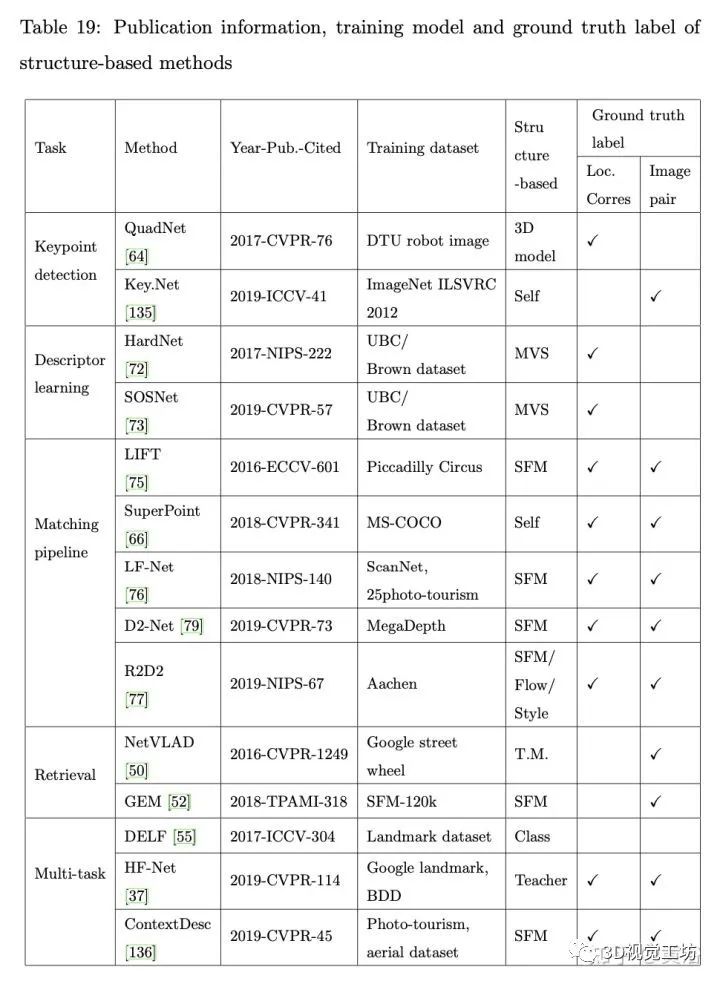
如表是基于结构方法在训练模型和真值标注的比较:
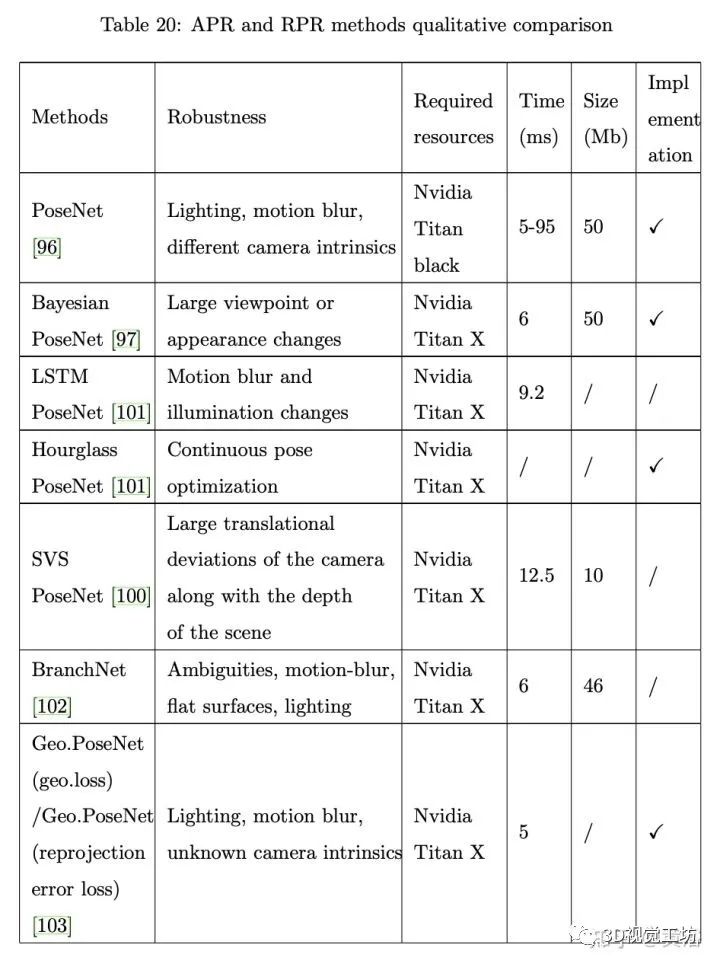
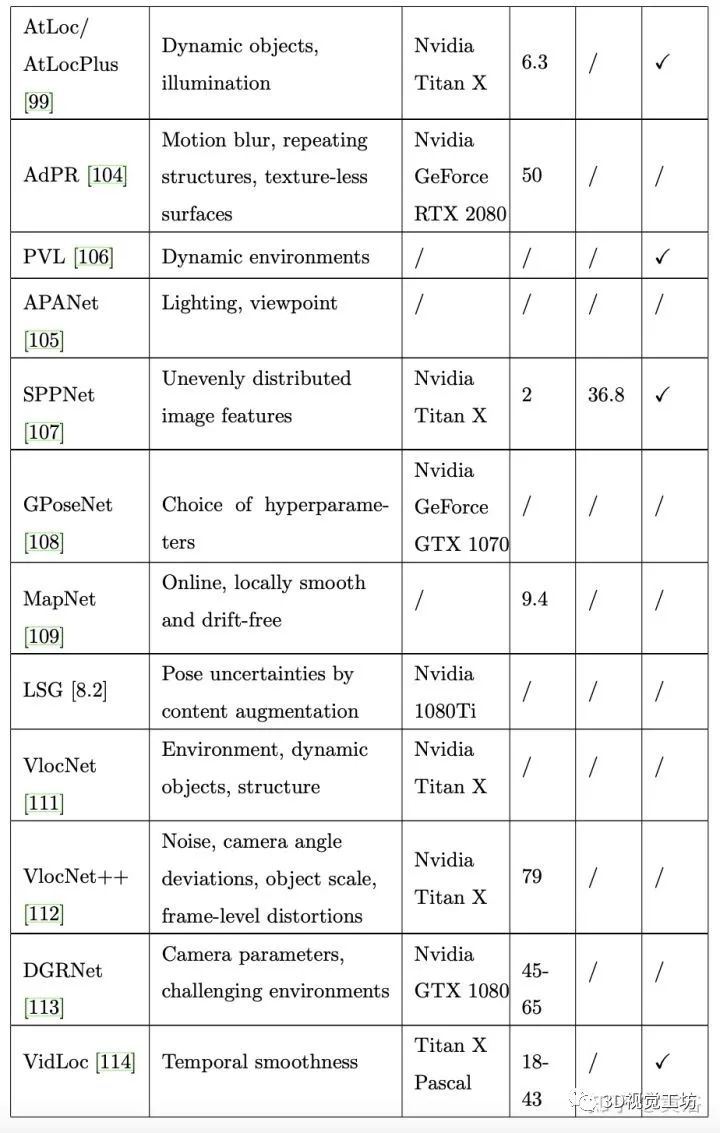
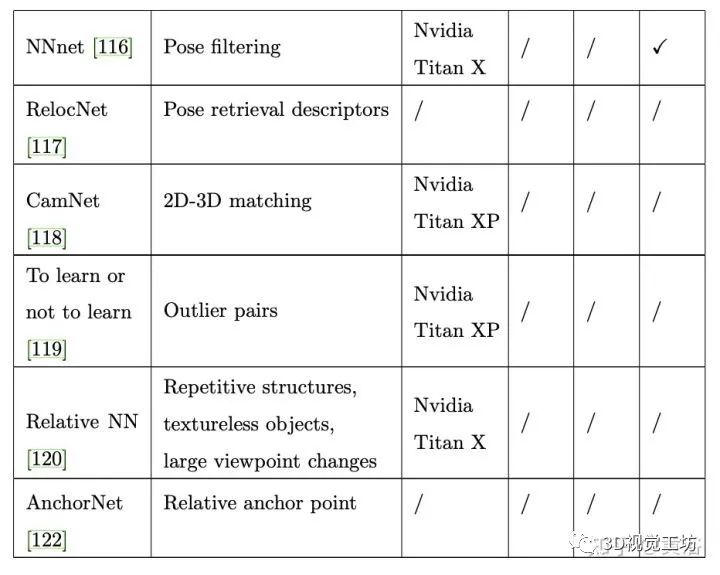
下表是APR(绝对)和RPR (相对)的方法定性分析比较:
未来一些研究方向:
·传感器融合
·多特征
·语义信息辅助
·多摄像头
·挑战性条件
·和轻量设备的集成
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









