






作者丨李迎松@知乎
来源丨https://zhuanlan.zhihu.com/p/522285892
编辑丨3D视觉工坊
本篇是比较简单的基础概念,刚入门的朋友可能是需要的。

视差图

点云
首先,我们要介绍下这三个概念。
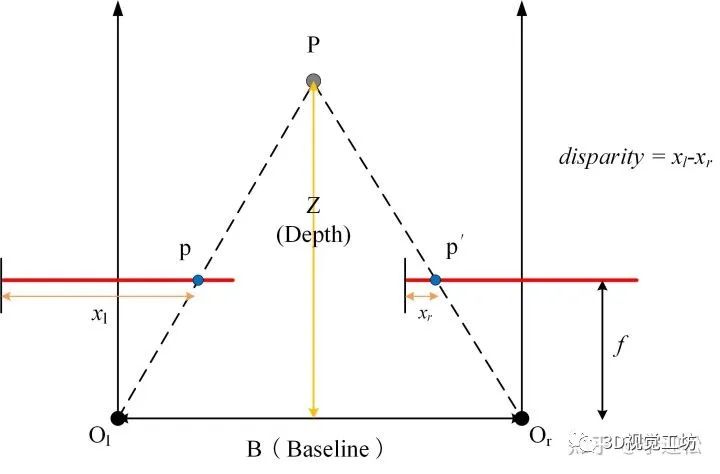
视差(disparity)

深度(depth)
深度D等于像素在该视图相机坐标系下Z坐标,是空间单位。深度并不特在校正后的图像对里使用,而是任意图像都可获取深度图。
视差图(disparity map)
视差图指存储立体校正后单视图所有像素视差值的二维图像。
1. 视差图是一张二维图像,和原图等大小
2. 视差图每个位置保存的以像素为单位的该位置像素的视差值
3. 以左视图视差图为例,在像素位置p的视差值等于该像素在右图上的匹配点的列坐标减去其在左图上的列坐标
深度图(depth map)
深度图指存储单视图所有像素的深度值的二维图像,是空间单位,比如毫米。
1. 深度图是一张二维图像,和原图等大小,也就和视差图等大小
2. 深度图每个位置保存的是该位置像素的深度值
3. 深度值就是相机坐标系下的Z坐标值
点云(point cloud)
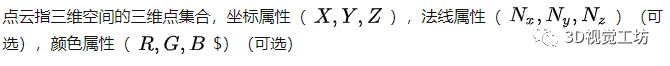
其次,为什么会有视差图和深度图呢?
我们知道,立体匹配一般是指逐像素的稠密匹配,这意味着每个像素都会得到一个视差值(包括无效值),如何存储这些视差值呢,显然以二维图的方式存储是很合适的,最大的两点优势是一方面可以通过像素坐标快速的在二维图中找到对应位置的视差值,而且和图像一样是有序的,邻域检索、视差滤波等将会变得非常方便;另一方面是可以直观的通过观察视差图和原图的对比,对视差图的质量有初步的判定。
而深度图的意义则是以更少的存储空间、有序的表达图像匹配的三维成果。更少的存储空间是因为只保存了一个深度值,而不是三维点云的三个坐标值,而深度值是可以结合像素坐标计算三维点坐标值的。有序是因为深度图和原图像素是一一对应的,所以原图的邻域信息完全继承到了深度图里。
这就是视差图和深度图的意义,视差图是立体匹配算法的产出,而深度图则是立体匹配到点云生成的中间桥梁。
视差图和深度图中间,有着一对一的转换公式:

常见问答:
问:为什么我从.png格式的视差图里读取到的视差值和真实值有很大差异?
答:我们要先搞清楚,视差图是如何存储的。通常而言,我们是把二维视差图以图像格式存储,常见的格式有png、tif、pfm等,但这些图像格式存储的数据类型是有区别的,其中png只能存储整数,而tif和pfm则可以存储小数。而显然准确的视差值必然是浮点型的小数,所以存储为tif和pfm可以原值无损存储,而存储为png必然会损失精度,所以有的代码比如opencv会把得到的浮点型视差值乘以16倍取整,存储到png里,这样存储视差值的精度变为1/16,对于这种情况我们在读取png后要先除以16才是真实视差值,且视差会有阶梯分层现象。
那有同学就问,既然这样为什么要存储png呢?是因为目前主流的图像软件,不支持直接看浮点格式的tif和pfm,存储为png可以更好的观看视差图,当然要是实际生产使用,是必然不建议存储为png的,用来查看视差结果是可以的。
还有人会直接把视差值拉伸或者压缩到0~255,存储到png或bmp等存储整数的格式中,这样的视差图只能用来观看视差效果,没有其他作用,比如我的代码里的存储方式。
问:极线像对下的深度图和原图的深度图是一样的吗?如何转换?
答:不一样,因为深度图是在视图所在的相机坐标系下的,所以和相机坐标系强挂钩,极限校正后的左视图和原始的左视图是不一样的相机坐标系,所以它们的深度图是不一样的。
1. 对于极线像对左视图某像素p,通过单应变换H转换到原左视图上,得到原图上的像素坐标q。
2. 将p的相机坐标系坐标通过一个旋转R变换到原左视图的相机坐标系坐标,得到q的深度。
3. H和R在极线校正步骤可以获取(极线校正的必然产出)。
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:3dcver.com
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









