






作者:dianyunPCL | 来源:点云PCL
文章:Ground-VIO: Monocular Visual-Inertial Odometry with Online Calibration of Camera-Ground Geometric Parameters
作者:Yuxuan Zhou, Xingxing Li, Shengyu Li, Xuanbin Wang, Zhiheng Shen
编辑:点云PCL
摘要
单目视觉惯性里程计(VIO)是一种低成本解决方案,可提供高精度、低漂移的姿态估计。然而,在车辆场景中,由于动态范围有限和缺乏稳定特征,单目VIO面临着一些挑战。本文提出了Ground-VIO,利用地面特征和特定的相机-地面几何关系,增强了单目VIO在实际道路环境中的性能,在该方法中,通过以车辆为中心的参数对相机-地面几何关系进行建模,并将其集成到基于优化的VIO框架中。这些参数可以在线校准,并通过提供稳定的尺度感知性来同时改善里程计的准确性。此外还开发了一个专门设计的视觉前端,通过逆透视变换(IPM)技术稳定地提取和跟踪地面特征,通过模拟测试和实际实验验证了所提出方法的有效性。结果表明,在车辆场景中,我们的方案能够显著提高单目VIO的准确性,实现与最先进的双目VIO解决方案相当甚至更好的性能。
主要贡献
地平面本身提供了一个自然且强大的约束条件,可以用于增强VSLAM/VIO的性能,考虑到车辆在地面上行驶,车载传感器和局部地平面之间有一个相对固定的几何关系,主要取决于传感器的安装和车辆的尺寸。对于VSLAM/VIO,局部地平面可以在相机坐标系中表示为一个特定的平面,如图1所示。
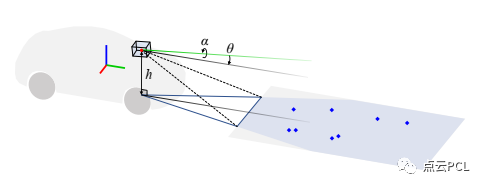
图1,摄像机地面几何示意图。对于地面车辆,局部地平面可以表示为相机坐标中的特定平面,在本工作中,该平面被参数化为具有两步旋转的高度信息。
将这种固定的关系称为相机-地面几何关系,可以用来约束地标的深度,从而推导出对于高精度姿态估计至关重要的度量尺度的几何信息,然而,很少有研究对于相机-地面几何关系在VIO中的应用进行了深入探讨。
实际上,这种相机-地面几何关系已经在车辆感知中广泛应用,有时是隐含地应用。通常,著名的逆透视变换(IPM)技术利用预先校准的相机-地面几何关系生成鸟瞰图像(BEV)或称为全景监控(AVM),从而有效地感知周围的道路环境。从这个角度来看,相机-地面几何关系的在线自动校准也是一个有意义但尚未解决的问题。
在提出的Ground-VIO中,将相机-地面几何参数的在线估计引入到单目VIO中,这不仅可以改善里程计性能,还可以提供一种IPM的自动校准方法。本文的贡献如下:
提出了一个以车辆为中心的模型来参数化相机-地面几何关系,将其集成到单目VIO中进行在线校准,以改善导航性能。
开发了一种新颖的视觉前端,利用相机-地面几何关系和IPM精确地跟踪地面上的特征。
进行了模拟测试和实际实验,验证了系统的不同方面,包括C-G参数的估计、里程计的准确性和IPM的校准性能。
开源了地面特征处理模块和测试数据序列。
主要内容
相机-地面几何模型
首先介绍了在所提出的系统中使用的相机-地面几何模型。对于安装在地面车辆上的相机,它与地面有着特定的几何关系,假设局部地面是平坦的并且车辆是刚体(暂时忽略悬挂系统),相机坐标系中的地面平面是一个特定的平面,可以通过其法向量和距离来明确定义。为了方便起见,在这里我们使用从相机中心到地面的高度h以及一个两步旋转来参数化局部地面平面,使相机坐标系的X-Z平面与地面平面平行,如图2所示。
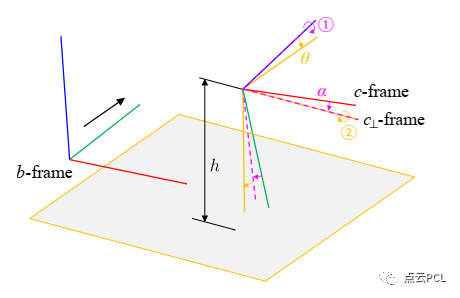
图2. C-G参数的示意图,b-frame是车体/IMU坐标系,c-frame是相机坐标系,c⊥-frame是虚拟相机坐标系,其X-Z平面与局部地平面是平行。
具体而言,首先围绕Z轴旋转实际相机坐标系c,使其X轴与地面平面平行。然后将得到的坐标系围绕X轴旋转,得到期望的虚拟相机坐标系c⊥,这也可以看作是IPM的参考坐标系。因此,相机坐标系中的地面平面可以通过以下单行方程表示:
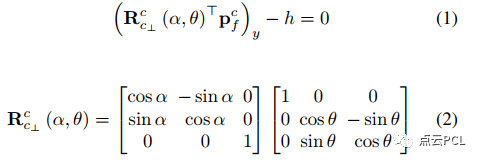
其中,(·)x/y/z表示三行向量/矩阵的第一/二/三行,α和θ分别表示两步旋转的大小,对应相机的横滚角和俯仰角。本文中将三元组(h, θ, α)定义为C-G参数,类似于[37]中的参数化方式。这样的参数化方式使得相机-地面几何的估计变得更加直观(即一个高度和两个角度),并且可以通过使用IMU姿态来补偿几何关系。可以合理地期望在常见的道路环境中,C-G参数(表示局部地面平面)在传感器对准或车辆负载没有显著变化的情况下是统计稳定的,提出的Ground-VIO充分利用了这一点,并且后面将给出一些技术来处理复杂的情况。
给定相机观测到环境中的一个地标点f,我们可以得到:
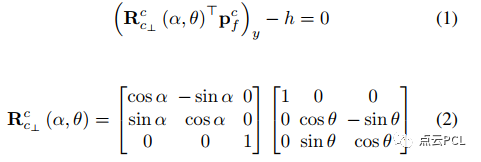
其中,(u, v)是图像上f点的像素坐标, uf = (x, y, 1)是归一化的图像坐标,πc是相机投影矩阵,λf是f点的逆深度。
方程(1)和(3)揭示了在已知相机-地面几何关系的情况下,可以即时恢复图像上地面特征的度量尺度(逆深度)。
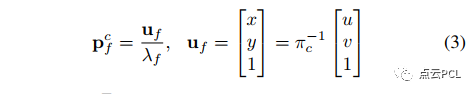
通过结合(1)和(3),相机-地面几何关系可以应用于VSLAM/VIO中以约束地标的深度。这里使用了一个简化的一维模型来定性地分析其在VSLAM/VIO中的意义。
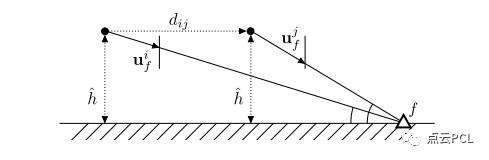
图3,一个简单的一维模型,用于演示摄像机地面几何结构如何在VSLAM/VIO中工作。
如图3所示,里程计系统需要通过跟踪地标f来估计行驶距离dij,假设已知C-G参数并导致了一个全面的相机高度h-^,可以得到行驶距离dij的估计值。
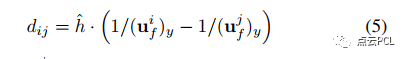
假设视觉观测没有噪声,对dij的估计仅取决于h的准确性。

假设在典型的车辆场景中,综合相机高度h^为2米,误差为2厘米,对dij的估计将具有1%的相对误差。换句话说,仅通过跟踪一个地面特征,就可以获得关于平移的几何信息,相对误差为1%,这对于单目视觉惯性系统来说非常有意义。这引出了以下问题:1)如何将相机-地面几何集成到常见的VIO中,以及2)如何在线获取或估计C-G参数。
系统概述
Ground-VIO的整体结构如图4所示。
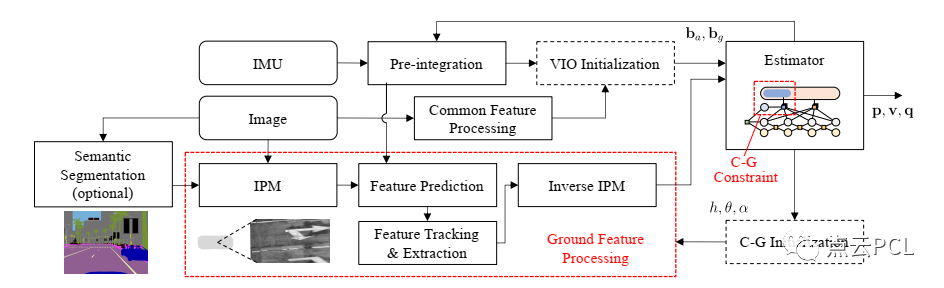
图4. 所提出系统的结构遵循基于优化的单目VIO(Visual-Inertial Odometry)[8]的经典流程,在此基础上,添加了一个专门设计的前端用于地面特征处理,与常规特征处理器并行工作,IMU和相机(包括地面特征)的测量值在因子图估计器中进行融合,在估计器之后定期调用C-G参数的初始化模块,直到参数被初始化为止。
系统的基本结构遵循基于优化的VIO(Visual-Inertial Odometry)的经典流程,但增加了与相机-地面相关的机制,基本上收集到的图像和IMU数据被用于常规的VIO初始化和优化流程。在此基础上,还设计了一个额外的前端,用于地面特征处理,并与常规特征处理器并行工作。地面特征处理器提取并跟踪通过IPM生成的鸟瞰图像上的特征,从而实现了高效准确的跟踪。可以使用语义分割模块进行地面分割,但这不是必需的。在因子图优化中,地面特征被视为具有相机-地面几何约束的视觉特征的子集,这些约束可以显著提高VIO性能,并实现C-G参数的在线估计。在C-G参数完全未知的情况下,在常规因子图优化之后,会调用C-G初始化模块。一旦初始化完成,特征处理和因子图优化中与相机-地面相关的机制将被启用,在VIO运行期间,C-G参数将持续进行精细化。
地面特征处理
在典型的VIO实现中,图像中的特征点被连续追踪以构建视觉测量,所提出的系统遵循典型的VIO例程,以检测和跟踪相机视野中的环境特征。具体而言,采用了[41]中的特征检测方法和KLT光流算法[42],并使用基础矩阵的RANSAC算法来检测异常值, 对于地面特征而言,它们在透视图像上的独特分布和快速运动使得它们难以跟踪。透视图像上的近到远地面高度高度“扭曲”,而近处的点尽管具有更好的观测几何关系,但移动幅度很大。与常规方法不同,我们开发了一个特殊模块,用于更精确地关联地面特征的数据,借助相机-地面几何关系,可以即时获取与地面对应的透视图像上每个像素的三维位置,参考公式(4)。从另一个角度来看,我们可以使用逆透视变换(IPM)高效地生成鸟瞰图像,并且图像上的每个像素直接与一个三维位置相关联,以下是度量尺度的三维点、透视图像上的点和鸟瞰图像上的点之间的映射关系:
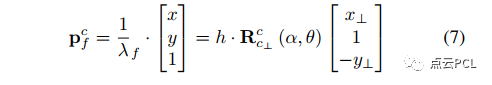
其中,u⊥ 是地面特征在鸟瞰图像上的归一化图像坐标,逆深度λf参考公式(4),通过逆透视变换(IPM)生成鸟瞰图像的过程可参考[20]。相机-地面几何关系的知识使得对地面特征跟踪的准确预测成为可能,每当有新的图像到来时,可以借助IMU预测的相对姿态来预测现有地面特征的位置。
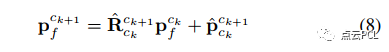
其中,Rˆ , pˆ是通过IMU积分估计的相对姿态,结合公式(7)和(8),可以在透视图像或鸟瞰图像上对地面特征进行预测,从而将光流跟踪的搜索区域限制在几个像素范围内,从而大大提高了跟踪性能。
在Ground-VIO中选择在鸟瞰图像上提取和跟踪特征,原因是鸟瞰图像的“变形”较小,并且具有更好的跟踪一致性。实际上,KLT光流跟踪无法保证尺度和旋转不变性,如图5所示的失败案例。
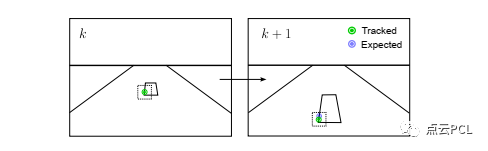
图5。透视图上的光流跟踪错误案例说明,绿色点表示被跟踪的特征,而蓝色点表示预测的精确对应点。
幸运的是,IPM可以恢复地面特征的度量尺度几何,并在快速运动过程中消除大部分尺度效应,从而提供更好的跟踪精度。图6展示了在鸟瞰图像上通过IMU辅助特征预测进行地面特征跟踪的示例,此外使用基于单应矩阵的RANSAC方法来高效检测异常的特征跟踪。在我们的实现中,主要关注车载相机前方的矩形区域(距离车辆15米范围内,宽度为±3米,空间分辨率为0.015米),这有利于在车辆运行期间对地面特征进行多帧跟踪,并保证良好的跟踪精度。
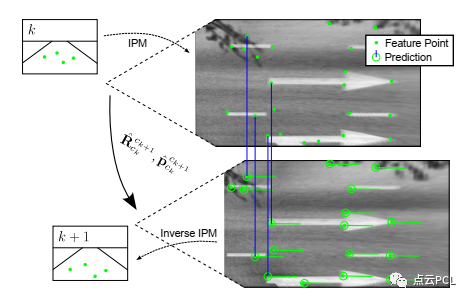
图6,BEV图像上的地面特征跟踪示意图。
在鸟瞰图像上的特征处理完成后,通过IPM的逆过程将得到的地面特征重新映射到透视图像上,这样这些特征就可以与普通特征一起进行一致处理。通过这样做,鸟瞰图像上的跟踪有助于提高跟踪精度,同时又不引入与C-G参数相关的系统误差,在VIO的运行过程中,用于地面特征处理的C-G参数可以不断更新。直观地说,要提取和跟踪地面特征,需要特别识别图像中的地面区域。通过应用基于深度学习的语义分割方法[44] [45],可以实现这一任务,该方法在车辆场景中表现良好。然而,在本方法中,语义分割是可选的,IPM处理本身可以排除大部分不在地面上的物体,而基于C-G参数的准确特征预测以及RANSAC方法可以排除鸟瞰图像上的异常值(例如车辆、护栏等)。在后续的因子图优化中,通过异常值检测方法可以进一步减轻粗大误差的影响,因此,尽管语义分割可以为系统提供最佳性能,但它并非必需。在因子图优化中,提取的地面特征被视为视觉特征的子集,用于构建视觉重新投影因子,同时将他们应用到相机-地面约束中。
基于优化的视觉惯性里程计
遵循[8]的方法,我们维护一个滑动窗口因子图,通过优化不同类型的测量值,同时估计导航状态、地标以及C-G参数。Ground-VIO的状态向量定义如下:
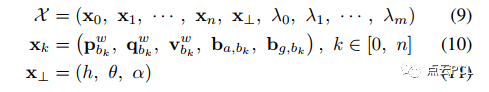
其中,pw_bk、qw_bk和vbwk分别表示第k个帧在世界坐标系中的位置、姿态和速度,ba_bk和bg_bk分别表示加速度计偏置向量和陀螺仪漂移向量,λ0、λ1、...、λm表示地标的逆深度,每个地标都是相对在滑动窗口中的第一次观测帧中。优化过程中考虑以下因素:
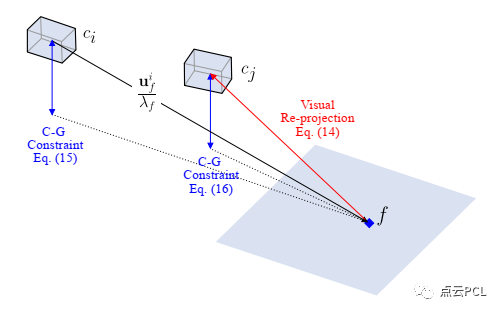
图8. 在地面特征f上构建的视觉重投影因子和相机-地面约束因子的示意图,这里,ci是参考帧,而cj是目标帧。
1)IMU预积分因子:帧之间的IMU数据被预积分并用于构建IMU预积分因子,其残差可以表示为:
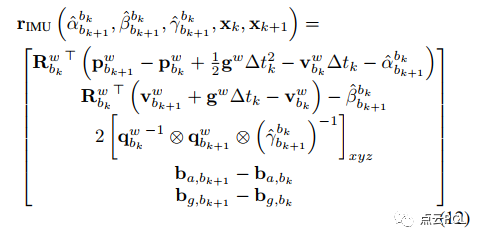
2)视觉重投影因子:滑动窗口中维护的视觉特征,包括地面特征,用于构建视觉重投影因子,其残差可以表示为:
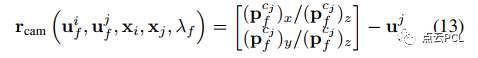
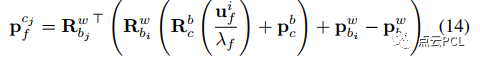
其中,ui(f)和uj(f)是时刻i和j的f的视觉观测,Rb_c和pb_c是IMU相机外参值,视觉测量通过类似于捆集调整(bundle adjustment)的模型来强力约束车辆的姿态和地标位置。
3)相机-地面约束因子:相机-地面约束应用于滑动窗口中维护的地面特征。在我们的实现中,有两种相机-地面约束因子,取决于地面特征的锚定帧和应用相机-地面约束的目标帧。如果锚定帧和目标帧相同,则残差可以表示为
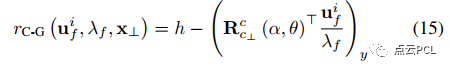
如果参考帧和目标帧不同,则残差可以表示为
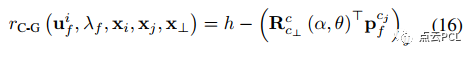
其中,第i帧是锚定帧,第j帧是目标帧,pc_fj是指(14)式中的结果。
通过将相机-地面几何约束引入估计器,可以基于VIO获得的信息估计和改进C-G参数,一旦C-G参数收敛,这些约束就可以互相提供无漂移的、度量尺度的几何信息给VIO。"使一些参数收敛并使用它们来维持估计性能"的机制与IMU偏差类似。然而,收敛的C-G参数预计会具有更持久的影响,原因如下:1)IMU偏差是时变的,而C-G参数相对稳定;2)C-G参数与姿态估计处于相同的数量级,不需要像IMU那样进行积分。
优化问题可以表示为最小化上述残差项和先验项,遵循以下形式:
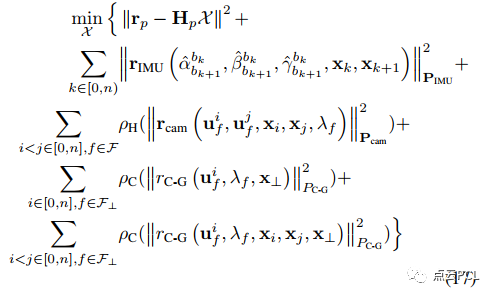
其中,(rp, Hp)是通过边缘化获得的先验信息,F是在滑动窗口中维护的地标点集合,F⊥是地面地标点的子集,ρH(·)和ρC(·)是Huber和Cauchy核函数,PIMU、Pcam、PC-G是残差的协方差/方差。使用ceres-solver 来解决优化问题。
相机-地面参数的初始化
如果在开始时完全不知道相机-地面(C-G)参数,地面特征处理模块将无法正常工作,也很难构建准确的相机-地面约束因子,在这种情况下,系统需要在线初始化C-G参数,单目VIO在足够的IMU激励下具有感知度量尺度环境结构的能力 [10]。在此基础上,完全可以在线初始化C-G参数,而无需来自其他传感器的辅助信息,初始化的具体步骤如下所示。在进行VIO初始化后,通常的VIO例程开始运行。目前由于缺乏C-G参数的知识,地面特征只能在透视图像上进行跟踪(没有IPM处理)。为了实现这一点,我们使用了一个保守的感兴趣区域(ROI),该区域由IMU-相机外参和粗略的车辆高度确定。对于C-G参数的初始化,周期性检查滑动窗口中地面地标的不确定性(即方差)。一旦获得足够数量的低于不确定性阈值的地面地标,将这些地标的观测结果堆叠在一起,以估计C-G参数,遵循以下步骤:
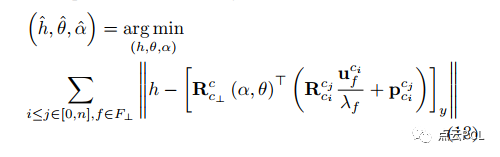
在完成C-G参数的初始化后,地面特征处理模块将被启用,以实现更好的跟踪准确性,同时,相机-地面约束因子将应用于因子图中,以增强VIO,并进一步优化C-G参数。
应用在道路复杂的场景中
在实际场景中,道路条件可能相对复杂,并不符合我们描述的理想相机-地面几何模型。这种情况主要包括以下两种情况:1)由于道路不平整或车辆动力学引起的车辆姿态振动,2)道路坡度的变化。
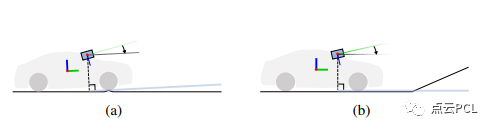
图 9. 复杂路况的两种典型情况,(a) 由路面不平和车辆动力引起的姿态振动, (b) 路面坡度的变化。
如果不仔细考虑这些问题,它们会导致系统出现系统性误差并影响系统性能。在所提出的系统中,采用了几种技巧来减轻这些问题的影响。为了应对车辆的高频姿态振动(图9(a)),我们使用局部IMU姿态估计临时补偿C-G参数,如图10所示。
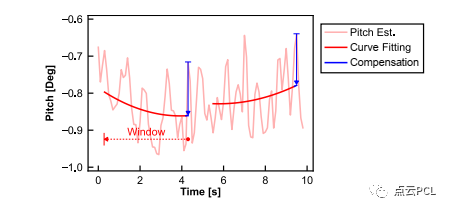
图 10. 在实际场景中应用摄像机-地面几何约束时的基于IMU的俯仰补偿示例。
在我们的实现中,只补偿俯仰分量θ,考虑到地面感兴趣区域(± 3 m宽,15 m远)更为敏感。具体来说,我们使用历史俯仰估计的4秒窗口拟合二次曲线,并计算当前时刻的俯仰补偿,遵循以下步骤:
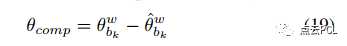
其中,θw_bk 是当前的IMU俯仰估计值,θˆb_wk 是通过曲线拟合预测的俯仰角,在应用该帧的相机-地面约束因子时,临时补偿C-G参数θ。
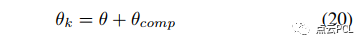
在这里,θk 被视为时刻 k 的临时 C-G 参数。通过这样做可以显著减轻由于姿态振动引起的相机-地面约束的噪声。为了处理道路坡度的变化(图 9(b)),首先,地面特征处理可以放弃一些不符合平面地面假设的特征观测。其次,在构建相机-地面因子时,采用相对严格的异常值剔除策略,使用截断阈值加上 Cauchy 核函数,以对抗由于陡峭坡度变化引起的粗大误差。
仿真测试
进行仿真测试以评估系统在相对理想条件下的性能,仿真的优势在于车辆-传感器校准和环境几何信息是准确已知的,这有助于进行更深入的分析。使用提供精美的三维场景和逼真车辆动力学的CARLA模拟器生成车辆姿态和图像,IMU数据是根据10 Hz的真实车辆姿态进行B样条拟合分别进行模拟,其中添加了自定义偏差和噪声,仿真的设置如表I所示。
图12显示了仿真测试中的车辆轨迹和捕获的图像,仿真包括两个序列,即S-A和S-B,分别对应城市和高速公路环境。

图12. 仿真轨迹和示例图像,色条表示车辆速度(m/s)。顶部:Seq. S-A,使用CARLA模拟器中的“Town10”场景。该场景具有清晰的道路纹理和丰富的环境特征,底部:Seq. S-B,使用CARLA模拟器中的“Town06”场景,该场景中可观察到较少的清晰地面特征,主要是道路标线。
考虑了由悬挂系统引起的车辆动力学,导致车辆姿态的振动最高可达±0.5◦。在模拟数据序列上测试了不同的VIO方案,包括:1) VINS-Fusion(单目),2) VINS-Fusion(立体),3) 带有地面特征的VINS-Fusion(单目),4) OpenVINS(单目),5) ORB-SLAM3(单目,带有IMU)和6) 提出的Ground-VIO。对于带有地面特征的VINS-Fusion(单目),采用地面真值C-G参数进行比较。对于Ground-VIO,C-G参数是未知的,并且将进行在线估计。对于基于VINS-Fusion的解决方案和Ground-VIO,设置了50 ms的最大优化时间限制以保证实时处理并提供更公平的比较。前端公共特征处理的最大特征数为250,而地面特征的最大数目设置为40。为了进行理想的分析,在仿真测试中使用了语义图像来确定地面区域。
首先,重点关注C-G参数的估计,图13显示了Seq. S-A和Seq. S-B上C-G参数的收敛情况。
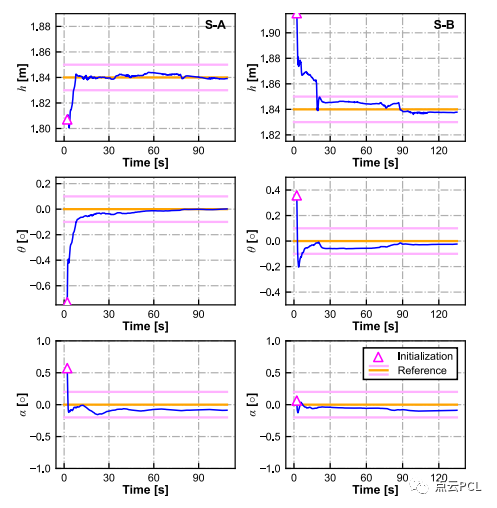
图13. 在线估计过程中C-G参数的收敛情况(左图:Seq. S-A,右图:Seq. S-B)。
其次,我们检查由VIO估计的地标深度与地面真值C-G参数之间的一致性,以分析模型的准确性。具体而言,使用地面真值C-G参数和估计的地标深度计算单帧摄像机-地面几何约束(15)的残差。如图14所示,如果不应用约束(VINS-Fusion),估计的地标深度与摄像机-地面几何不符合得很好。残差的分布反映了尺度估计的误差,可能超过0.1/h≈5%的水平,一旦考虑了相机-地面几何约束(Ground-VIO),残差将保持在0左右,这表明尺度的估计是无偏的,此外,通过对车辆俯仰进行局部补偿,残差的噪声水平显著降低,这表明补偿模型具有更好的精度,因为它补偿了由车辆动力学引起的大部分模型误差。
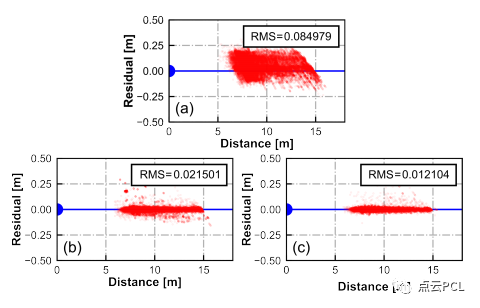
图14. 在Seq. S-A中应用真实的C-G参数时,相机-地面约束的残差,残差是在不同的VIO方案下计算的:(a) VINS-Fusion(单目)没有应用相机-地面约束。(b) Ground-VIO没有任何补偿。(c) Ground-VIO通过IMU的俯仰补偿,X轴表示参考帧中地标的感知距离,均方根(RMS)值附在旁边。
最后,我们对不同解决方案的姿态估计精度进行了研究,图15显示了估计的车辆轨迹,图16显示了相对平移误差的分布。
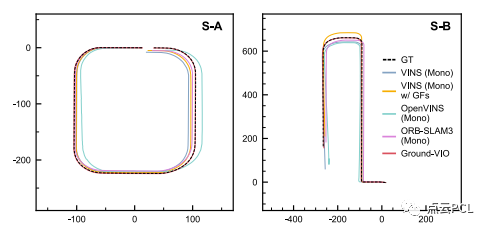
图15. 不同VIO解决方案在模拟测试中的车辆轨迹估计
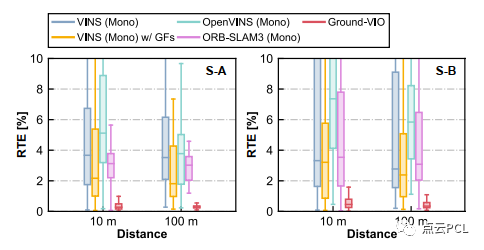
图16. 不同VIO解决方案在模拟测试中的短期相对平移误差
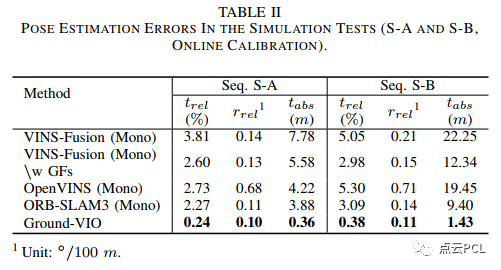
考虑到不同的VIO解决方案需要不同的时间(几秒钟)来初始化系统,对于Ground-VIO,在C-G参数在初始动态期间(加速度和旋转)收敛之后,相机-地面几何关系可以提供无偏的度量尺度信息,并帮助VIO保持准确的平移估计。不同VIO解决方案的导航性能统计数据列在表II中。
真实环境的实验
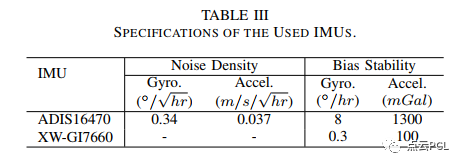
在真实的环境中以评估所提出的系统在典型车辆场景下的性能,包括城市道路和高速公路,实验车辆的外观如图17所示, 实验平台配备了两个Flir BFSPGE-31S4C摄像头,一个低成本的ADIS16470 MEMS IMU,一个XW-GI7660 IMU和一个Septentrio AsteRx4 GNSS接收器。来自IMU和GNSS接收器的数据进行后处理,生成参考轨迹。所使用的IMU的规格列在表III中。

图 17. 实验车辆的外观
在这部分中,我们评估了在完全不知道C-G参数的情况下提出的系统性能,在这种情况下,C-G参数将在数据时段中在线初始化并持续估计。使用四个持续时间为180秒的数据序列(Seq. R-A,R-B,R-C和R-D)进行评估,如图18所示。
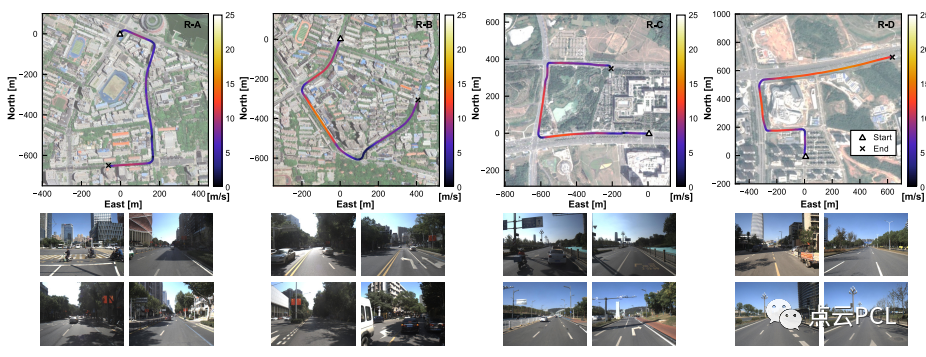
图18. 车辆轨迹和示例图像,包括Seq. R-A、Seq. R-B、Seq. R-C和Seq. R-D,颜色条表示车辆速度(m/s),Seq. R-A和Seq. R-B位于城市场景下,道路较窄,环境纹理丰富,速度相对较低。Seq. R-C和Seq. R-B主要在高速公路上,道路较宽,建筑物较少,速度适中。
在数据序列上测试了不同的VIO解决方案,与模拟测试不同,在这部分中考虑了具有双目相机配置的最先进的VIO实现,以研究在这些实际道路环境中能够实现的最佳VIO性能。C-G参数的收敛情况如图19所示,对于这四个序列,C-G参数的最终估计结果显示出良好的一致性。
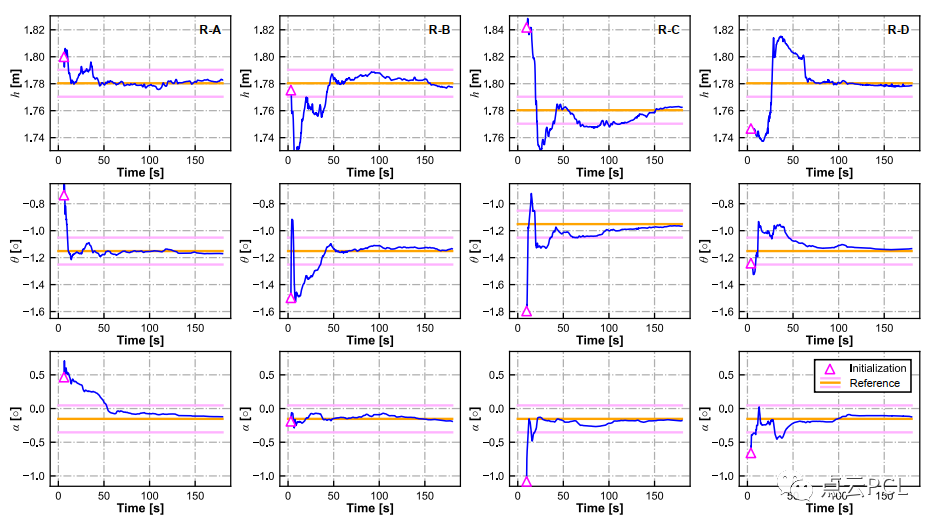
图19. 在Seq. R-A、R-B、R-C和R-D中的在线估计过程中C-G参数的收敛情况。
从图19中可以看出,参数的初始化可以在几秒钟内完成,并且初始精度与模拟测试相似(h为0.1米,θ为1°,α为1°),然而,与模拟测试不同,C-G参数的收敛速度较慢,具体而言,需要大约30∼60秒才能获得理想精度的C-G参数(h为0.01米,θ为0.1°,α为0.2°)。这可能归因于实际实验中道路条件更加复杂,IMU激励较小,这两者都会影响相机地面几何约束和单目VIO本身。粗略地说,VIO系统的可观测性更好,足够的地面特征和平整的道路表面可以加快C-G参数的收敛速度。然后,我们关注姿态估计性能。图20和图21显示了不同VIO方案的车辆轨迹和相对平移误差,VIO性能的详细统计数据列在表IV中。
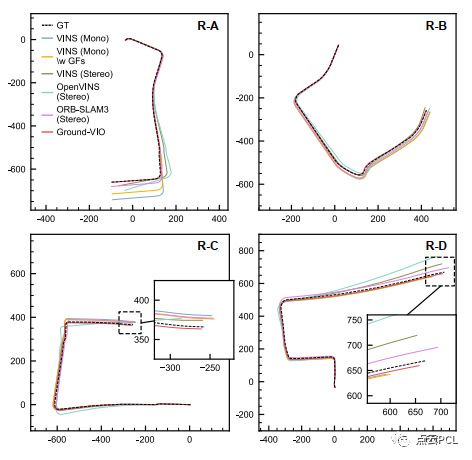
图20. 模拟测试中不同VIO方案的估计车辆轨迹
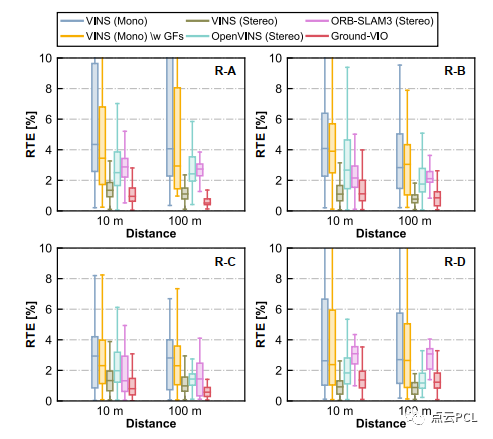
图21. 模拟测试中不同VIO方案的短期相对平移误差
与模拟测试类似,单目VIO(除了Ground-VIO)在姿态估计方面表现良好,但由于尺度漂移的存在,在平移误差方面表现较差,尤其是在长时间直行时,相比之下,双目VIO在相对平移误差方面表现更好,但在图20中仍然存在明显的姿态误差。总体而言,Ground-VIO在相对平移误差方面能够达到与最先进的立体VIO方案相当的性能(0.5%∼1.0%),而姿态估计性能甚至更好。因此,Ground-VIO在几乎所有四个序列上都实现了最小的位置漂移, 总之,通过适度的车辆动力学,提出的Ground-VIO能够在线校准C-G参数并同时获得良好的姿态估计精度。
在具有挑战性的场景下进行预校准的VIO
CG参数的在线校准依赖于车辆动力学,因为它需要VIO的可观测性来提取度量尺度的环境结构。幸运的是,通过预先校准C-G参数,即使在动态不足的场景下,VIO的性能也可以大大提高。实际上,预校准并不困难,因为当适度的车辆动力学可用时,它可以自动完成。
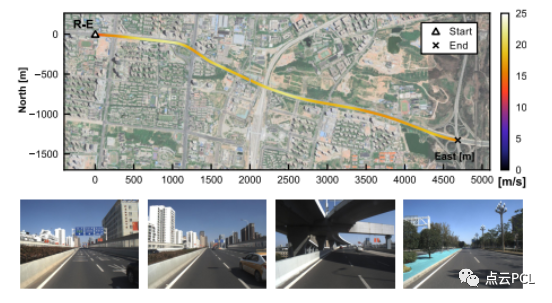
图22. Seq. R-E中的车辆轨迹和示例图像。该数据序列位于高速公路上,车速相对较高,附近的建筑物、树木和交通标志提供了有限数量的视觉特征。
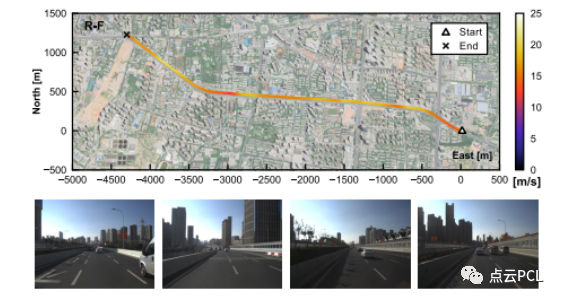
图23. Seq. R-F中的车辆轨迹和示例图像。该数据序列位于高速公路上,车速适中/较高。视野中的建筑物较远,周围对象(建筑物、护栏和灌木)的纹理大多重复。
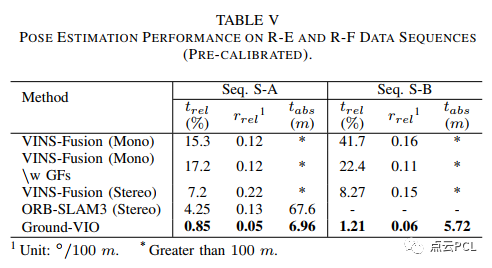
我们使用两个高速公路数据序列Seq. R-E和Seq. R-F如图22,,23,测试具有预校准C-G参数的系统性能,车辆轨迹和代表性图像如图18所示。这两个数据序列对VIO来说极具挑战性,动力学有限,环境特征不足且车速较高。这些条件可能会导致特征跟踪困难和VIO系统的可观测性不足,对于Ground-VIO,预校准的C-G参数是在线估计结果获得的。图24和图25显示了估计的车辆轨迹和相对平移误差分布。姿态估计误差的统计数据列在表V中。
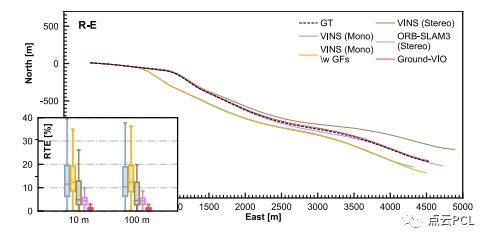
图24. 在序列R-E上,不同VIO方案的估计车辆轨迹和相对平移误差
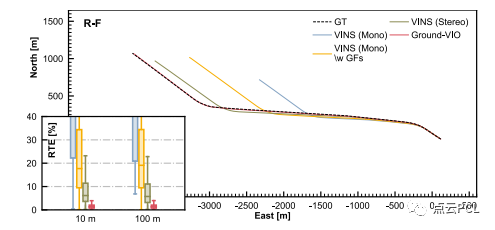
图25. 在序列R-F上,不同VIO方案的估计车辆轨迹和相对平移误差
IPM校准性能
在某种程度上,C-G参数的在线估计等价于在线校准透视变换校正(IPM),而IPM在车辆感知中被广泛应用。除了评估里程计性能之外,我们还定性地研究了在线IPM校准的有效性。具体而言,我们将估计得到的C-G参数应用于图像序列的IPM处理,通过IPM,图像将被转换为具有颜色信息的度量尺度点云,根据Ground-VIO获取的相机位姿,可以在参考坐标系中将这些点云进行合并。合并点云的一致性可以直接反映IPM的准确性。
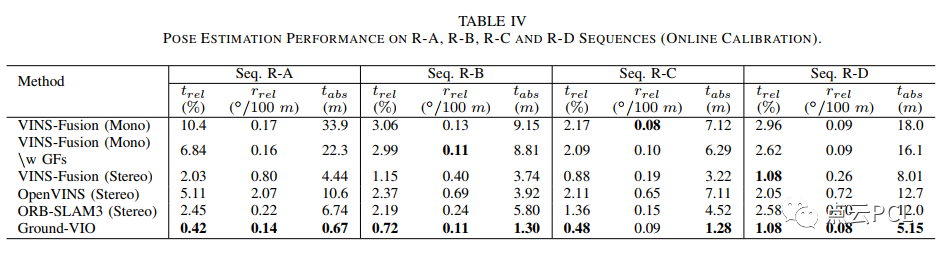
图26展示了基于不同C-G参数合并的点云,可以看到,当C-G参数的姿态或高度分量存在残差误差时,合并的点云会模糊并产生拼接错误,这反映了多个点云之间的不一致性,进一步表明生成的IPM点云在几何上不准确,粗略地说,纵向误差可达到米级水平,相比之下,经过校准的C-G参数合并的点云更加一致且更清晰,此外一旦应用了IMU的俯仰补偿,点云的细节变得更加清晰,验证了相机-地面几何模型的准确性,在IPM校准之后,可以期望获得10-15米的有效感知范围,并具有分米至厘米级的准确性。总的来说,提出的算法提供了一种在线校准车载摄像机的IPM参数的方法,该方法仅基于单目视觉惯性数据,无需额外的基础设施。

图26. 基于不同的C-G参数融合的11幅连续图像的IPM点云:(a) θ误差为1◦。(b) h误差为0.1 m。(c) 校准后的C-G参数。(d) 带有IMU俯仰补偿的校准后的C-G参数,红色三角形表示相机位姿。
总结
本文提出了Ground-VIO,它将相机-地面几何引入到单目VIO中,以改善里程计性能,该方法在C-G参数未知或预先校准的情况下都能良好运作,在车辆场景中实现了与现有先进双目VIO甚至更好的里程计准确性,该方法有望显著提高VIO在智能车辆应用中的实用性,并可以作为现有车辆导航方案的有效补充。此外,所提出的方法提供了一种基于单目视觉惯性数据进行在线IPM校准的高效方式,自动校准不需要额外的基础设施,并且能够处理传感器对准长期变化,这对于更好的车辆感知具有重要意义,未来有兴趣将这种技术应用于基于视觉的众包建图应用中。
—END—高效学习3D视觉三部曲
第一步 加入行业交流群,保持技术的先进性
目前工坊已经建立了3D视觉方向多个社群,包括SLAM、工业3D视觉、自动驾驶方向,细分群包括:[工业方向]三维点云、结构光、机械臂、缺陷检测、三维测量、TOF、相机标定、综合群;[SLAM方向]多传感器融合、ORB-SLAM、激光SLAM、机器人导航、RTK|GPS|UWB等传感器交流群、SLAM综合讨论群;[自动驾驶方向]深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器讨论群、多传感器标定、自动驾驶综合群等。[三维重建方向]NeRF、colmap、OpenMVS等。除了这些,还有求职、硬件选型、视觉产品落地等交流群。大家可以添加小助理微信: cv3d007,备注:加群+方向+学校|公司, 小助理会拉你入群。

第二步 加入知识星球,问题及时得到解答
针对3D视觉领域的视频课程(三维重建、三维点云、结构光、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、源码分享、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答等进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业、项目对接为一体的铁杆粉丝聚集区,6000+星球成员为创造更好的AI世界共同进步,知识星球入口:「3D视觉从入门到精通」
学习3D视觉核心技术,扫描查看,3天内无条件退款
第三步 系统学习3D视觉,对模块知识体系,深刻理解并运行
如果大家对3D视觉某一个细分方向想系统学习[从理论、代码到实战],推荐3D视觉精品课程学习网址:www.3dcver.com
基础课程:
[1]面向三维视觉算法的C++重要模块精讲:从零基础入门到进阶
工业3D视觉方向课程:
SLAM方向课程:
[1]如何高效学习基于LeGo-LOAM框架的激光SLAM?
[1]彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战
[2](第二期)彻底搞懂基于LOAM框架的3D激光SLAM:源码剖析到算法优化
[3]彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析
[4]彻底剖析室内、室外激光SLAM关键算法和实战(cartographer+LOAM+LIO-SAM)
视觉三维重建
[1]彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进)
自动驾驶方向课程:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









