






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0.这篇文章干了啥?
这篇文章介绍了使用视觉Transformer(ViT)实现四旋翼飞行器的端到端障碍物规避,并与其他学习架构进行了比较。作者通过行为克隆方法训练模型,并评估了模型在不同测试环境中的性能。结果表明,ViT+LSTM模型在保持低能量成本的同时,具有最佳的碰撞率和成功率,特别是在模拟环境中的泛化测试中表现出色。此外,硬件实验验证了ViT+LSTM模型在躲避障碍时的优越性。未来工作将探索传感器噪声和不良状态估计等因素对模型泛化能力的影响。
下面一起来阅读一下这项工作~
1. 论文信息
论文题目:Vision Transformers for End-to-End Vision-Based Quadrotor Obstacle Avoidance
作者:Anish Bhattacharya,Nishanth Rao等
作者机构:University of Pennsylvania
论文链接:https://arxiv.org/pdf/2405.10391
代码链接:https://github.com/anish-bhattacharya/vit-for-quadrotor-obstacle-avoidance
2. 摘要
我们展示了一种基于注意力的端到端方法,在密集、杂乱的环境中高速四旋翼避障的能力,并与各种最新的架构进行了比较。四旋翼无人机在高速飞行时具有极大的机动性;然而,随着飞行速度的增加,传统的基于视觉的导航通过独立的映射、规划和控制模块进行的方法由于传感器噪声增加、误差累积和处理延迟增加而失效。因此,基于学习的端到端规划和控制网络已经被证明对于在线控制这些快速机器人穿越杂乱的环境是有效的。我们在一个逼真的、高物理保真度的模拟器中训练和比较了卷积、U-Net和循环架构与视觉Transformer模型用于基于深度的端到端控制,在硬件上也进行了验证,并观察到随着四旋翼速度的增加,基于注意力的模型更有效,而具有许多层的循环模型在较低速度时提供更平滑的命令。据我们所知,这是第一个利用视觉Transformer进行端到端视觉四旋翼控制的工作。
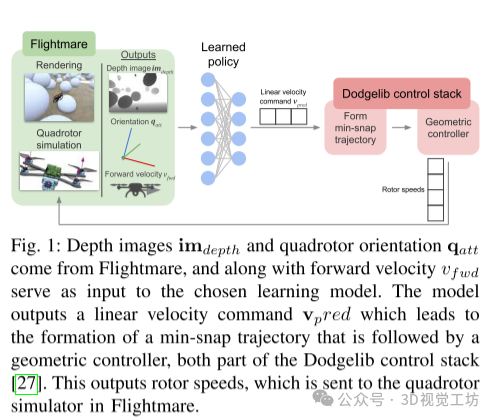
3. 效果展示
真实的世界实验在躲避刚性障碍物的任务中评估ConvNet和ViT+LSTM模型。

4. 主要贡献
首次使用视觉Transformer模型实现四旋翼的高速端到端控制。
将视觉Transformer模型与各种最先进的基于学习的模型进行比较,用于四旋翼的端到端深度控制。
在硬件上进行真实实验,展示和比较模型。
提供开源代码和数据集,以重现和扩展本文的结果。
5. 基本原理是啥?
这篇文章的基本原理是研究如何利用视觉变换器(Vision Transformers, ViTs)来实现四旋翼飞行器在障碍物环境中的自主导航。具体来说,文章探讨了使用ViT模型及其变体,与传统的卷积神经网络(CNN)和其他先进的架构相比,进行端到端的障碍物躲避任务。
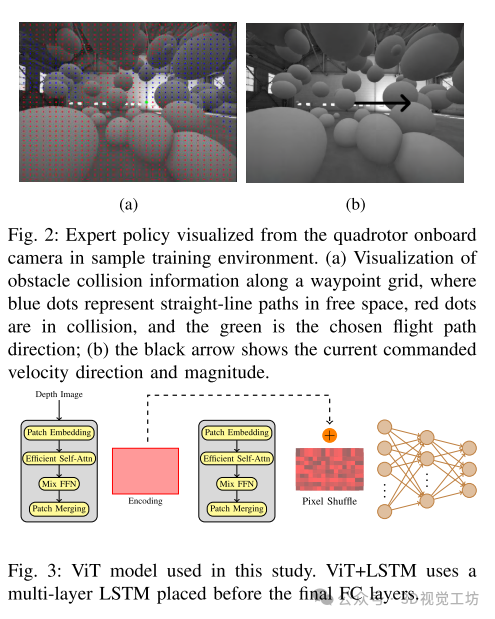
任务是让四旋翼飞行器在模拟的杂乱环境中,以不同的前进速度飞行固定距离,同时躲避静态的球形障碍物。研究中使用的专家是一个反应式规划器,模仿低技能飞行员的数据,避免了现实中的高风险训练。
使用一个特权专家来执行躲避障碍的算法,通过随机障碍场来收集监督数据。这些数据用于训练端到端学习的学生模型。专家策略依赖于四旋翼飞行器的状态和障碍物的位置来生成每个时间步的动作。
学生模型输入单一深度图像、四旋翼的姿态和前进速度,预测一个速度向量。通过模仿学习,从特权专家中学习这些预测。损失函数采用标准的L2损失。
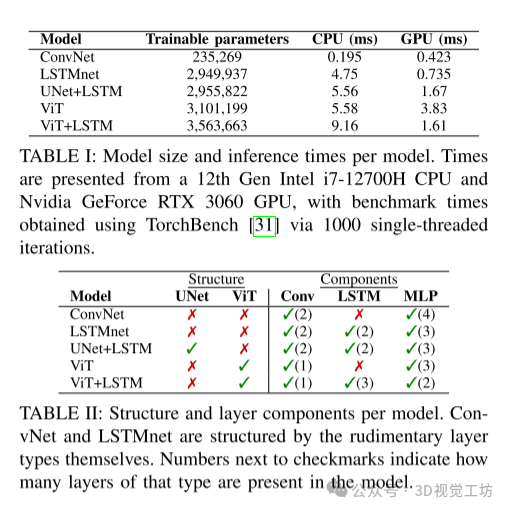
使用开源的Flightmare仿真器进行仿真和渲染,仿真环境包含各种大小的漂浮球形障碍物。训练过程中收集的数据用于训练不同的学生模型,包括ViT、ViT+LSTM、ConvNet、ConvNet+LSTM和UNet+LSTM。
实验在Vicon运动捕捉系统的环境中进行,使用Intel Realsense D435i深度相机采集深度图像,并将其输入到网络模型中。输出的速度指令发送到控制堆栈,最终控制四旋翼飞行器的方向和推力。
研究目标:
端到端控制:研究不同的模型在端到端障碍物躲避任务中的性能,特别是ViTs在此类任务中的表现。
模型比较:比较ViT与其他流行模型(如CNN、UNet、LSTM)的性能,探索ViT在反应式控制任务中的优势和劣势。
实用性验证:验证所提出的方法在真实硬件上的实用性,评估其在不同速度和障碍物环境中的表现。
主要结论:
端到端控制性能:使用ViT进行端到端控制在某些情况下优于传统的CNN模型,特别是在处理高维视觉数据时表现良好。
模型效率:研究中展示的模型能够在实时环境中运行,适合在四旋翼飞行器上进行实时控制。
方法实用性:在仿真和真实硬件环境中验证了方法的有效性,展示了模型在不同速度和障碍物环境中的适应能力。
6. 实验结果
A. 碰撞指标和成功率
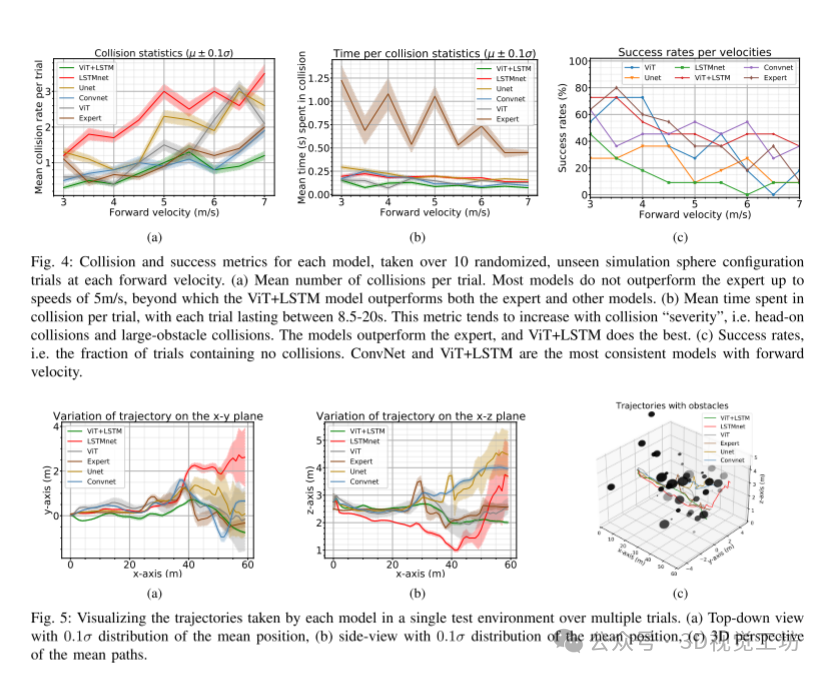
我们使用两个指标评估模型在不同、未见过的球形环境中多次试验中的碰撞情况,结果如图4所示。一般化性能的详细信息见IV-D部分。平均碰撞率描述了每次试验中的碰撞次数,而碰撞时间均值计算了无人机与障碍物碰撞的时间。与大型障碍物的碰撞和正面碰撞往往会增加第二个指标的值。图4a显示,随着速度增加,每个模型每次试验的平均碰撞次数普遍增加,这是由于响应时间减少所致,并且在之前的工作中也有所体现。然而,ViT+LSTM在速度超过5m/s后开始表现优于专家模型。ConvNet在6m/s时表现类似。由于训练数据集包含了专家轨迹中的碰撞,值得注意的是,ViT+LSTM模型在这种情况下表现优于专家。此外,ViT+LSTM模型的主要组成部分(即ViT和LSTMnet)的单独模型表现不佳,而组合模型在速度达到7m/s时保持显著较低的碰撞率。专家的碰撞时间均值(图4b)特别差,因为每次碰撞都会导致路径搜索失败;然而,值得注意的是,模型没有学习到专家的差劲统计数据。ViT+LSTM模型在该指标上也优于所有其他模型,特别是速度增加时。观察表明,ViT+LSTM模型倾向于碰撞障碍物的边缘,并且比其他模型正面碰撞更少;这导致碰撞时间减少。
B. 路径和命令特性
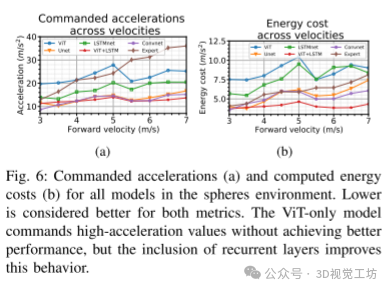
图5中的轨迹路径展示了无人机从x=0起点飞行到x=60时每个模型的路径。ConvNet的路径变化显著较小,而ViT模型在通过障碍物区域时选择的路径扩展有所变化。相比之下,ViT+LSTM模型的路径扩展随着x位置增加而稳步增加,这可能表明在多个试验中模型容量和平稳命令之间的平衡,尽管这需要进一步调查。图6展示了在球体环境测试集中各模型的命令特性。我们观察到,更平滑的速度命令更容易被四旋翼跟踪,并导致较低的加速度命令,能量成本指标如文献所述进行计算。ViT模型在所有前进速度下都有高命令加速度,但在加入LSTM层后,ViT+LSTM模型显著改善;值得注意的是,这并没有导致性能下降(图4)。一般来说,包括递归(LSTM)组件的模型命令较低的加速度并具有较低的能量成本;在树环境中尤其如此(图8c,IV-D节描述)。
C. 网络特征分析
图7突出显示了ConvNet模型和UNet模型中的卷积层以及ViT模型中的注意力层在深度图像中返回的最强信号区域。ConvNet突出了完整的障碍物,对其形状不太具体。UNet层特别突出了边缘,忽略了图像的其他区域。ViT模型似乎既捕捉到了障碍物边缘又捕捉到了周围的上下文,这可能是由于已知的ViTs在先前的目标检测工作中学习图像部分之间关系的行为。
D. 泛化能力
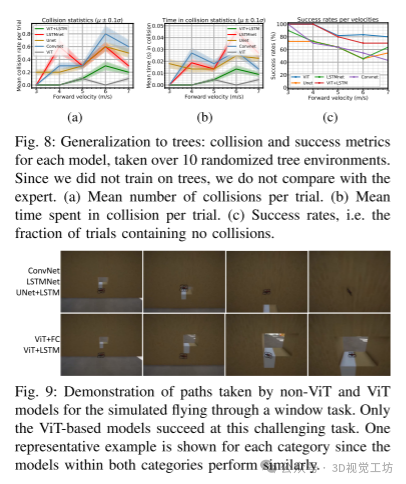
为了测试模型的泛化能力,我们在模拟环境中零样本部署模型,该环境包含随机放置的现实树模型(“树环境”)。图8中的碰撞率和成功率结果类似于球体环境测试结果,显示ViT和ViT+LSTM模型表现良好并优于其他模型。随着速度增加到5m/s,在该特定环境中碰撞时间增加,表明这些模型在发生碰撞时更多是正面碰撞。我们还展示了在所有模型上进行的3m/s的零样本通过窗口实验(图9)。虽然球体和树环境中存在多个可行的无碰撞路径,但该环境中除了一条可行的无碰撞路径外完全是碰撞。只有ViT模型(ViT和ViT+LSTM)成功完成了这一任务,其他模型都失败了。这进一步证明了ViT模型在端到端四旋翼控制中相比其他最先进计算机视觉模型(包括递归模型)的泛化能力更强。
E. 对状态信息的消融实验
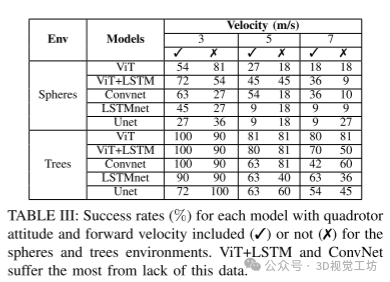
我们通过在训练和测试中去除四旋翼的姿态和前进速度状态信息(因此唯一的输入是深度图像本身)进行消融实验,成功率如表III所示。这种消融特别重要,因为在实际飞行中可能会导致状态估计噪声和前进速度的变化。结果表明,ViT+LSTM在速度超过5m/s后缺少这些信息时表现下降,而ConvNet在球体环境中所有速度下都表现不佳。在树环境中,在低速时大多数模型在缺少这些数据时保持或提高了成功率。随着速度增加,ConvNet在这个未见过的泛化环境中表现更好。
F. 硬件演示
我们在Falcon 250硬件平台上零样本部署了两个最成功且最不同的模型(ConvNet和ViT+LSTM),观察无人机在躲避单个物体时的路径。图10显示了不同路径的显著差异,我们观察到这种差异在多次试验中是一致的。ConvNet直到非常晚(距离障碍物<1m)才开始躲避动作,并且非常接近障碍物。ViT+LSTM则提前(距离障碍物2m)开始躲避,并且绕障碍物采取了较宽的路径。尽管需要进一步分析,这些结果表明ViT+LSTM模型在实际部署中比简单的ConvNet模型具有优势。

7. 总结 & 未来工作
我们展示了使用视觉Transformer进行基于深度感知的四旋翼飞行器端到端障碍物规避,并将其与其他流行的基于学习的架构进行了比较。所有模型都通过行为克隆从一位特权专家处以相同的方式进行训练。具有显著递归层的模型以较低的加速度和较低的能量成本发出命令,但成功率较低,而不包含LSTM层的基于注意力的ViT模型发出高值命令但成功率更高。然而,注意力-递归(ViT+LSTM)模型在呈现最佳碰撞和成功率的同时,具有理想的低加速度和低能量成本。在树环境和挑战性的飞过窗户任务的模拟泛化测试中,基于注意力的模型显著优于所有其他模型。实验证明,注意力-递归(ViT+LSTM)组合模型比仅使用卷积的(ConvNet)模型更早开始躲避动作,且分析模型层掩码表明,注意力层除了突出可见障碍物的边缘外,还捕捉了障碍物周围的上下文。进一步的研究可以探讨传感器噪声、不良状态估计和不同机器人平台如何影响这些端到端模型的泛化能力。此外,发出诸如集体推力和身体速度(CTBR)等较低级别的控制命令可能在实现快速敏捷飞行时优于线速度命令。
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
大模型:NLP、CV、ASR、生成对抗大模型、强化学习大模型、对话大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
3D视觉从入门到精通知识星球、国内成立最早、6000+成员交流学习。包括:星球视频课程近20门(价值超6000)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、三维视觉C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪,无人机等。

3D视觉相关硬件
| 图片 | 说明 | 名称 |
|---|---|---|
 | 硬件+源码+视频教程 | 精迅V1(科研级))单目/双目3D结构光扫描仪 |
 | 硬件+源码+视频教程 | 深迅V13D线结构光三维扫描仪 |
 | 硬件+源码+视频教程 | 御风250无人机(基于PX4) |
 | 硬件+源码 | 工坊智能ROS小车 |
 | 配套标定源码 | 高精度标定板(玻璃or大理石) |
| 添加微信:cv3d007或者QYong2014 咨询更多 | ||
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~
















 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









