






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:机器之心
添加小助理:cv3d001,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。
扫描下方二维码,加入「3D视觉从入门到精通」知识星球(点开有惊喜),星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

过去一年,3D 生成技术迎来爆发式增长。在大场景生成领域,涌现出一批 “静态大场景生成” 工作,如 SemCity [1]、PDD [2]、XCube [3] 等。这些研究推动了 AI 利用扩散模型的强大学习能力来解构和创造物理世界的趋势。
尽管这些方法在生成复杂且稀疏的三维环境方面表现出色,现有技术仍面临一个核心挑战:在生成大型 3D 场景时,它们将环境视为静止的 “快照”—— 道路凝固、行人悬停、车辆静止不动。这种静态生成方式缺乏真实世界瞬息万变的交通流,难以反映复杂多变的交通场景,限制了实际应用。
那么,如何让生成的 3D 场景突破静态单帧的限制,真正捕捉动态世界的时空演化规律?
对此,上海人工智能实验室、卡耐基梅隆大学、新加坡国立大学和新加坡南洋理工大学团队提出DynamicCity,给出了突破性的解答。这项创新性工作以4D 到 2D 的特征降维为核心突破点,首次实现了高质量、高效的 4D 场景建模,并在生成质量、训练速度和内存消耗三大关键维度上取得跨越式进展。
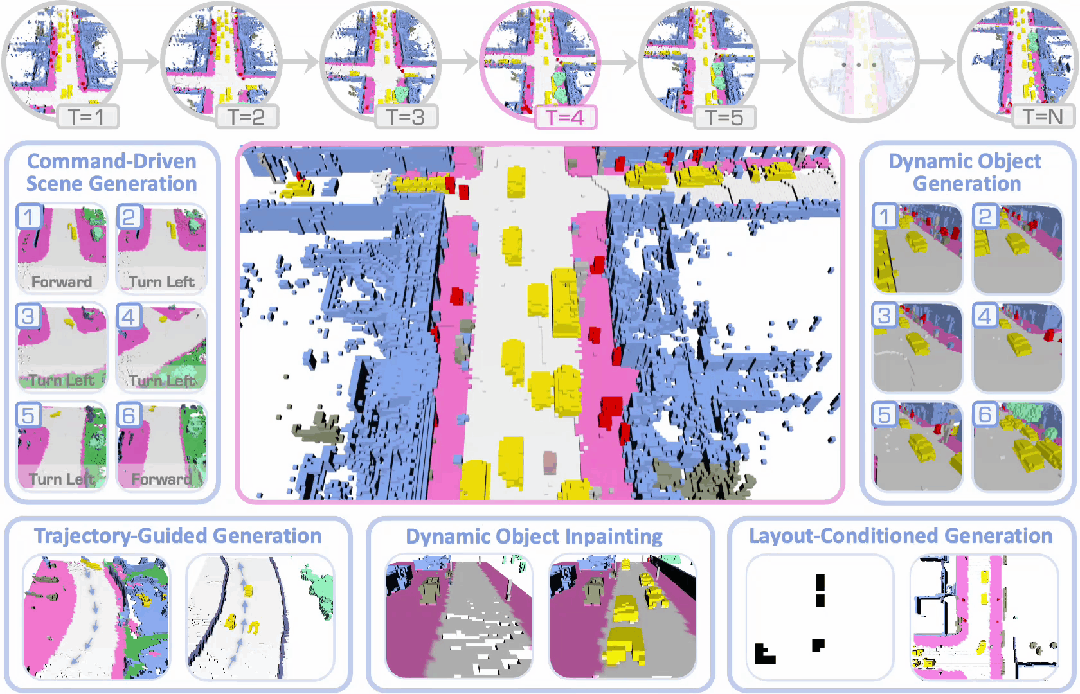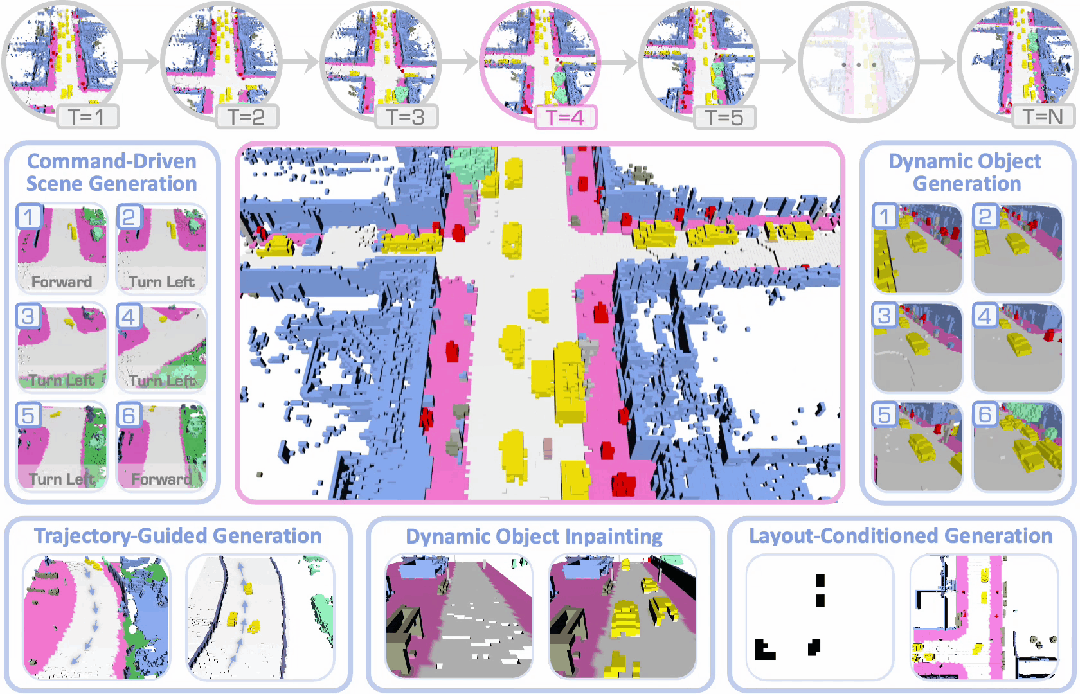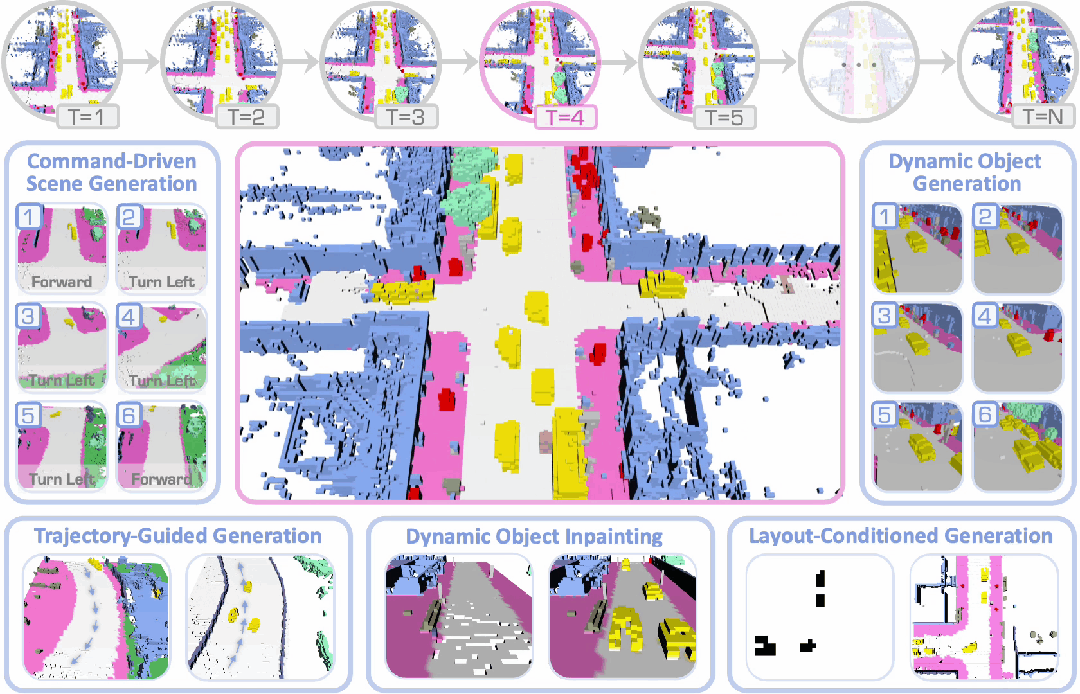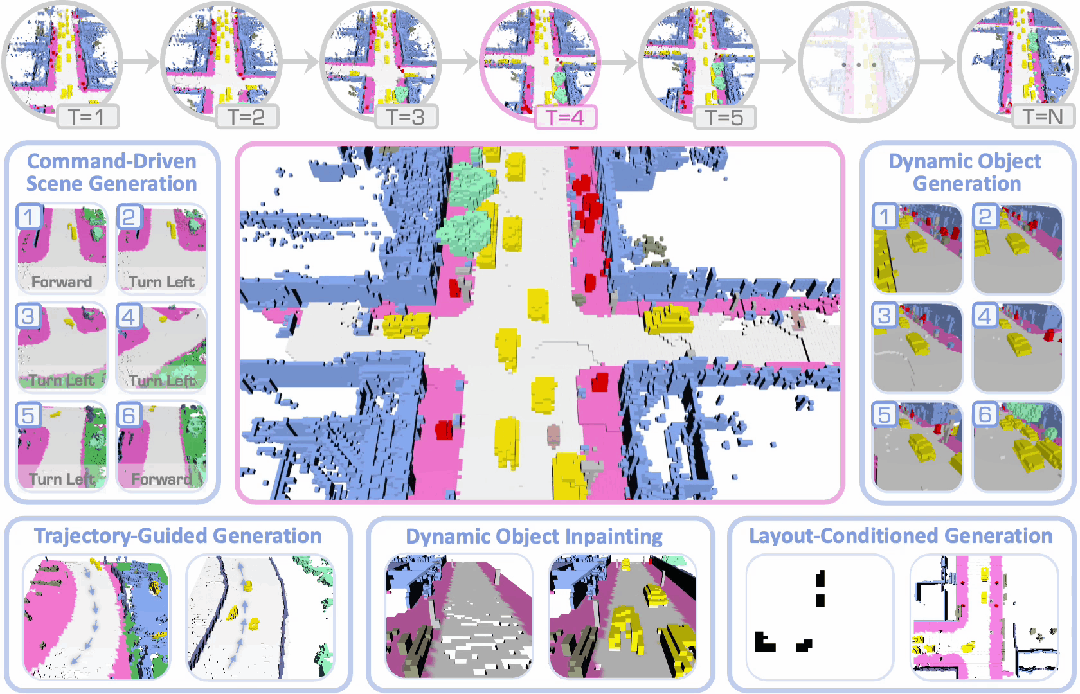
DynamicCity已被 ICLR 2025 接收为Spotlight论文,项目主页和代码均已公开。

论文:https://arxiv.org/abs/2410.18084
主页:https://dynamic-city.github.io
代码:https://github.com/3DTopia/DynamicCity
引言
3D 大型场景生成技术旨在利用深度学习模型,如扩散模型,构建高保真、可扩展的场景。该技术有望为智能系统的训练与验证提供近乎无限的虚拟试验场。然而,现有方法大多还在探索静态场景的单帧生成(如 XCube [1]、PDD [2]、SemCity [3] 等),难以捕捉真实驾驶环境中交通流、行人运动等动态要素的时空演化规律。这种静态与动态的割裂,严重制约了生成场景在复杂任务中的应用价值。
主流的静态场景生成方法 [1, 2, 3] 主要依赖体素超分或 TriPlane 压缩,以实现大规模静态场景的高效生成,其本质仍是对单帧 3D 场景的 “快照式” 建模。尽管近期研究尝试将生成范围扩展至动态(如 OccSora [4], DOME [5]),4D 场景的复杂性 —— 包含数十个移动物体、百米级空间跨度及时序关联 —— 仍导致生成质量与效率的严重失衡。例如 OccSora 无法在大压缩率的情况保证较好的重建效果,以及扩散模型生成的结果也较为粗糙。
针对这一难题,上海人工智能实验室等提出DynamicCity—— 面向 4D 场景的生成框架。核心思想是,通过在潜空间显式建模场景的空间布局与动态变化,并借助扩散模型,直接生成高质量的动态场景。具体而言,DynamicCity 采用以下两步方法:1) 通过变分自编码器(Variational Autoencoder, VAE)将复杂的 4D 场景压缩为紧凑的 2D HexPlane [5][6] 特征表示,避免高维潜空间过于复杂导致生成模型难以学习;2) 采用 Padded Rollout Operation (PRO) 使潜空间捕捉到更多时空结构,帮助扩散模型(Diffusion Transformer, DiT [7])更好生成场景的空间结构与动态演化。
DynamicCity 的主要贡献如下:
1. 时空特征压缩:提出基于 Transformer 的投影模块(Projection Module),将 4D 点云序列压缩为六个 2D 特征平面(HexPlane),相较于传统平均池化方法,mIoU 提升 12.56%。结合 Expansion and Squeeze Strategy (ESS),在提升 7.05% 重建精度的同时,将内存消耗降低 70.84%。
2. 特征重组:提出 Padded Rollout 操作,将 HexPlane 特征重组为适配 DiT 框架的特征图,最大程度保留 HexPlane 结构化信息,帮助生成 DiT 更好的学习潜空间。
3. 可控生成:支持轨迹引导生成、指令驱动生成、4D 场景修改、布局条件生成等功能,并可轻松扩展至更多应用,实现更可控的生成。
DynamicCity:基于 HexPlane 的动态场景扩散模型
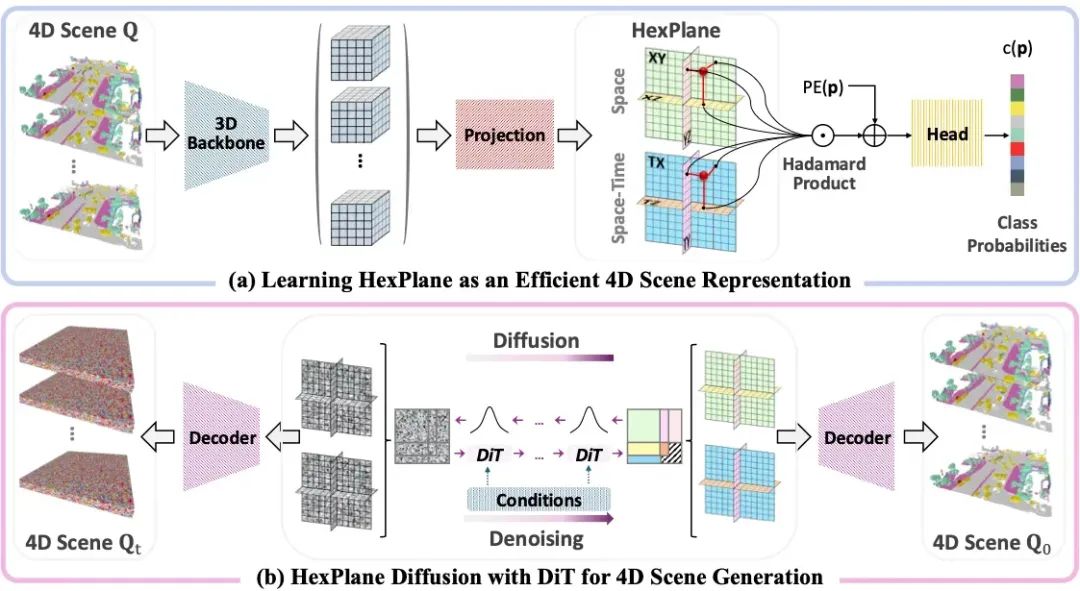
DynamicCity 采用HexPlane 表征和DiT构建了一个高效的4D 场景生成框架 。核心思想通过特征降维的方式,将 4D 场景映射到紧凑的 2D HexPlane,并在此基础上训练 DiT 进行场景生成。如图所示,DynamicCity 主要由以下两个核心模块构成:
1. 基于 HexPlane 表征的 VAE:利用投影模块 (HexPlane Projection Module),将 4D 场景压缩到六个互相正交的2D 特征平面,并通过 Expansion & Squeeze Strategy (ESS) 进行解码,以高效恢复原始时空信息。
2. 在重组 HexPlane 上训练的扩散模型:基于Padded Rollout Operation (PRO),对 HexPlane 进行结构化展开,并在此潜空间训练DiT进行采样,以生成新的 4D 动态场景。
DynamicCity 通过这两个核心模块,解决了现有 4D 生成模型重建效果和生成结果差的问题,提供了更紧凑的表征、更高效的训练、更高质量的动态场景合成。
基于 HexPlane 表征的 VAE
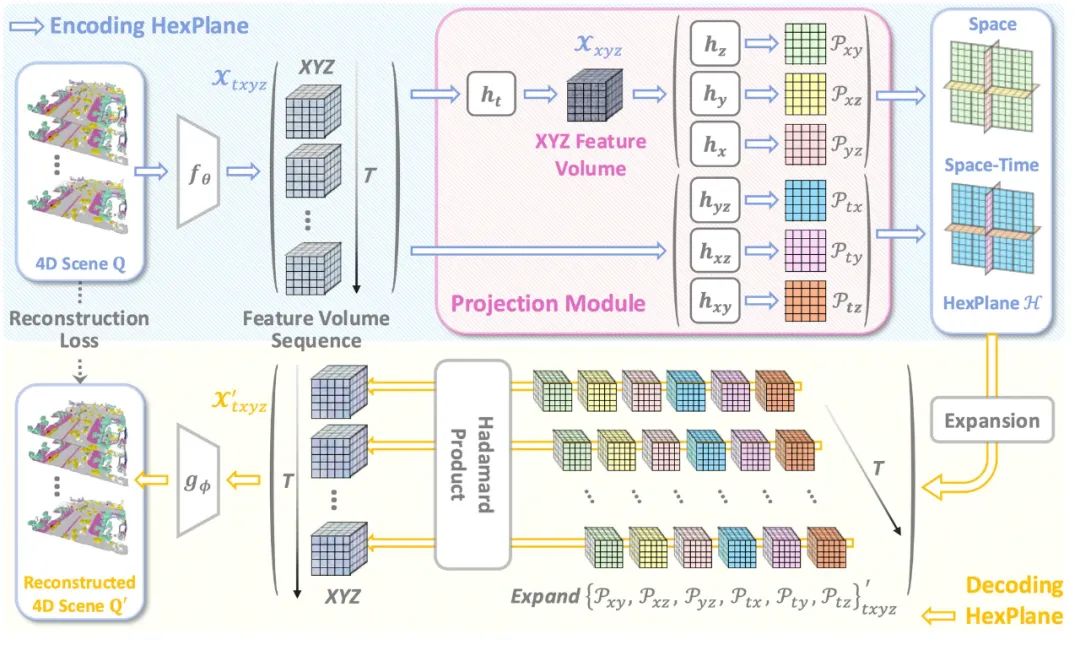
DynamicCity 使用 VAE 将 4D 点云转换为紧凑的 HexPlane 表征。一个 4D 场景被表示为时空体素数据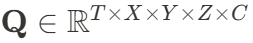 ,其中
,其中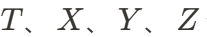 分别表示时间、空间维度,而
分别表示时间、空间维度,而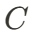 代表特征通道数。VAE 将 4D 数据进行降维成 HexPlane:
代表特征通道数。VAE 将 4D 数据进行降维成 HexPlane:
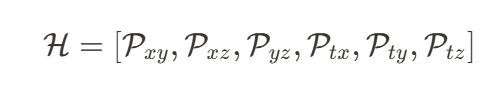
其中,下标表示每个平面保留的维度。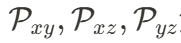 负责建模空间维度信息,
负责建模空间维度信息,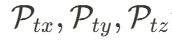 负责建模时空关联。这一映射成功将 4D 表达压缩至 2D 空间,使得后续的生成任务更高效。
负责建模时空关联。这一映射成功将 4D 表达压缩至 2D 空间,使得后续的生成任务更高效。
投影模块(Projection Module)
为了高效获取 HexPlane,作者设计了投影模块 (Projection Module),用于将高维特征映射至 HexPlane。在通过共享 3D 卷积特征提取器提取初步的时空 4D 特征后,作者使用多个投影网络 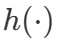 ,将 4D 特征投影到 2D 平面,每一个投影网络会压缩一个或两个维度。
,将 4D 特征投影到 2D 平面,每一个投影网络会压缩一个或两个维度。
投影模块由 7 个小型的投影网络组成,其中 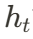 首先进行时间维度压缩,而后三个小型网络分别提取空间特征平面
首先进行时间维度压缩,而后三个小型网络分别提取空间特征平面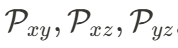 。而时空特征平面
。而时空特征平面 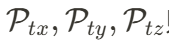 则是通过三个小型网络直接从 4D 特征中提取得到。
则是通过三个小型网络直接从 4D 特征中提取得到。
Expansion & Squeeze Strategy (ESS) 解码
在动态 NeRF 等领域中,HexPlane 常用一个多层感知机(MLP)进行逐点解码。然而在 4D 场景中,点的数量非常多,导致模型速度慢,显存占用大。DynamicCity 提出 ESS 解码策略,用卷积神经网络代 MLP,减少显存占用,加速训练,同时显著提升重建效果。
首先,对每个 2D 特征平面进行扩展和重复,使其匹配 4D 体素特征;然后,利用 Hadamard 乘积进行信息融合:
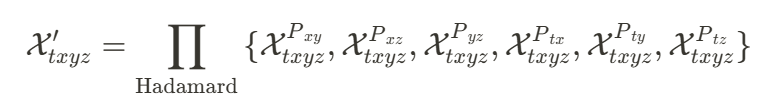
最终,通过卷积解码器 生成完整 4D 语义场景。
生成完整 4D 语义场景。
在重组 HexPlane 上训练的扩散模型
在 VAE 编码器学习到 4D 场景的 HexPlane 表征之后,DynamicCity 使用 DiT在学习 HexPlane 空间的分布,并生成时空一致的动态场景。
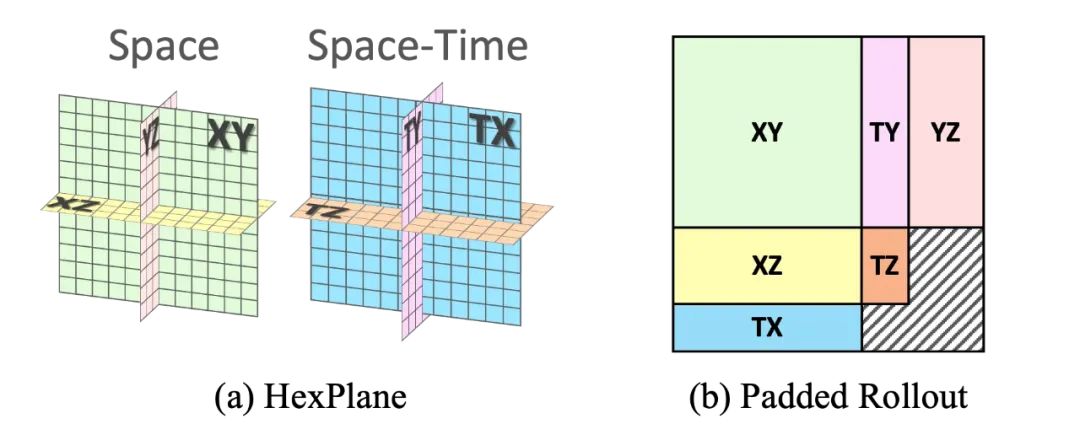
HexPlane 的六个特征平面共享部分空间维度或时间维度。作者希望能够用一种简单有效的方式,在训练扩散模型时,六个平面并非互相独立,而是共享部分时空信息。Padded Rollout Operation (PRO)将六个特征平面排列成单个统一的 2D 矩阵,并在未对齐的区域填充零值,以最大程度地保留 HexPlane 的结构化信息 。
具体而言,PRO 将六个 2D 特征平面转换为一个方形特征矩阵,通过将空间维度和时间维度尽可能的对齐,PRO 能够最小化填充区域的大小,并确保空间与时间维度之间的信息一致性。
随后,Patch Embedding将该 2D 特征矩阵划分为小块,并将其转换为 token 序列。在训练过程中,作者为所有 token 添加位置嵌入,并将填充区域对应的 token排除在扩散过程之外,从而保证生成过程中时空信息的完整性。
可控生成与应用
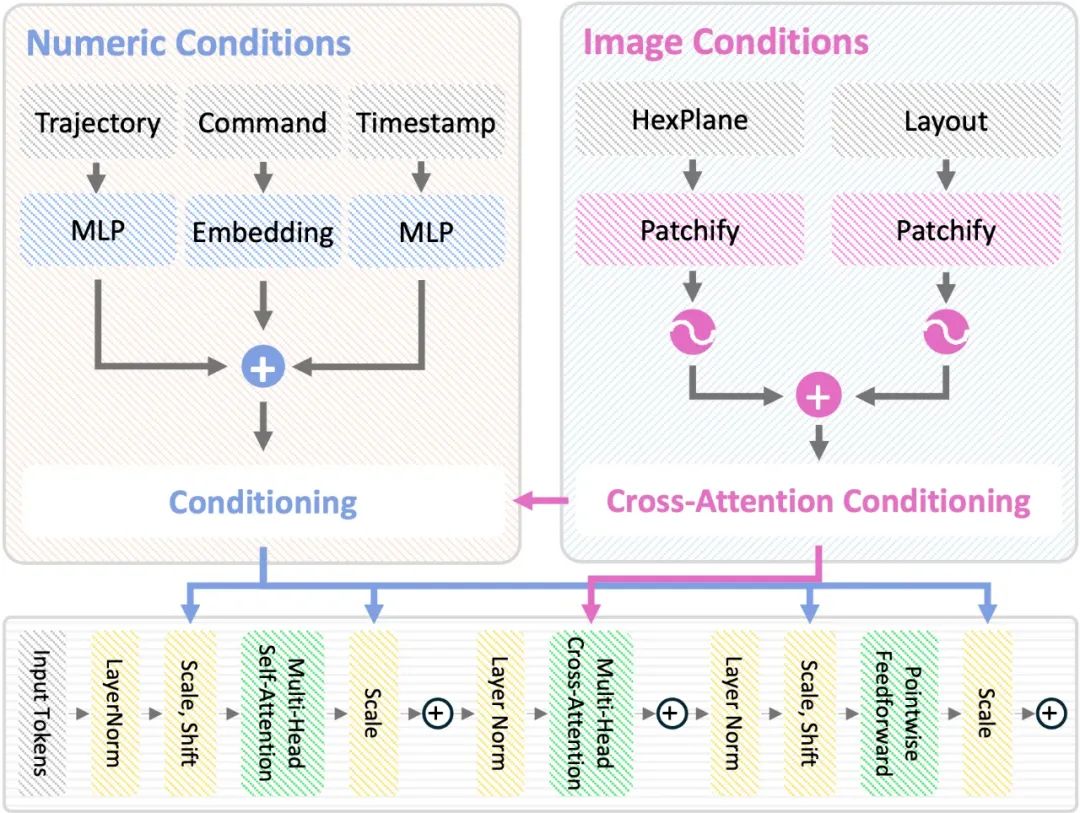
为了让 HexPlane 生成过程具备可控性,作者引入 Classifier-Free Guidance (CFG)[8]机制,以支持不同条件约束下的场景生成。
对于任意输入条件,作者采用AdaLN-Zero技术来调整 DiT 模型内部的归一化参数,从而引导模型生成符合特定约束的场景。此外,对于图像条件 (Image-based Condition),作者额外添加跨模态注意力模块 (Cross-Attention Block),以增强 HexPlane 与外部视觉信息的交互能力。
通过 CFG 和 HexPlane Manipulation,DynamicCity 支持以下的应用,且可以轻松拓展到其他的条件:
1. HexPlane 续生成 (Long-term Prediction):通过自回归方式扩展 HexPlane,实现 4D 场景未来预测,长序列 4D 场景生成等任务。
2. 布局控制 (Layout-conditioned Generation):根据鸟瞰 (BEV) 视角语义图,生成符合交通布局的动态场景。
3. 车辆轨迹控制 (Trajectory-conditioned Generation):通过输入目标轨迹,引导场景中车辆的运动。
4. 自车运动控制 (Ego-motion Conditioned Generation):允许用户输入特定指令,引导自车在合成场景中的运动路径。
5. 4D 场景修改 (4D Scene Inpainting):通过掩膜 HexPlane 中的局部区域,并利用 DiT 进行局部补全,实现 4D 动态场景的高质量修复。
结果
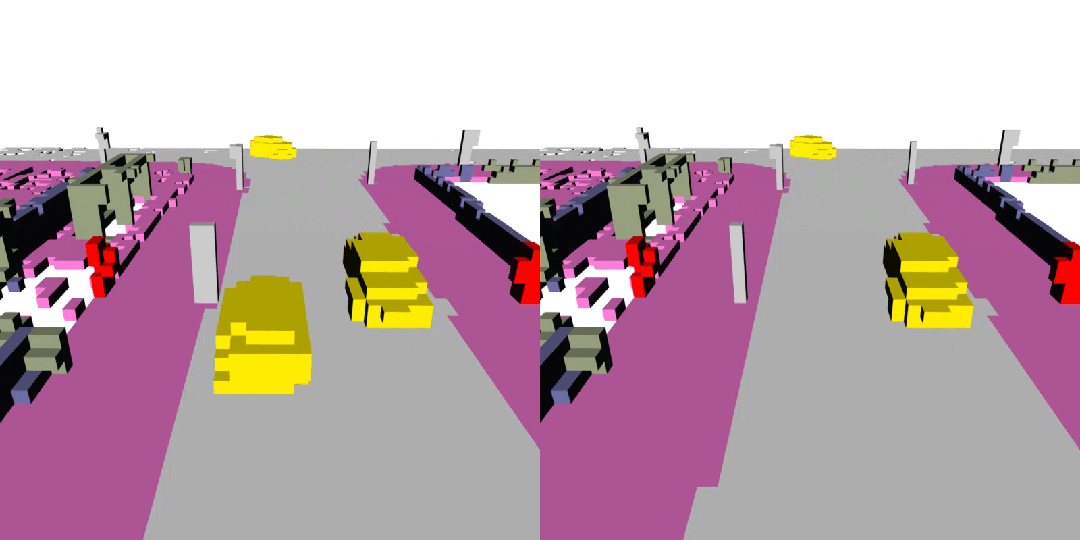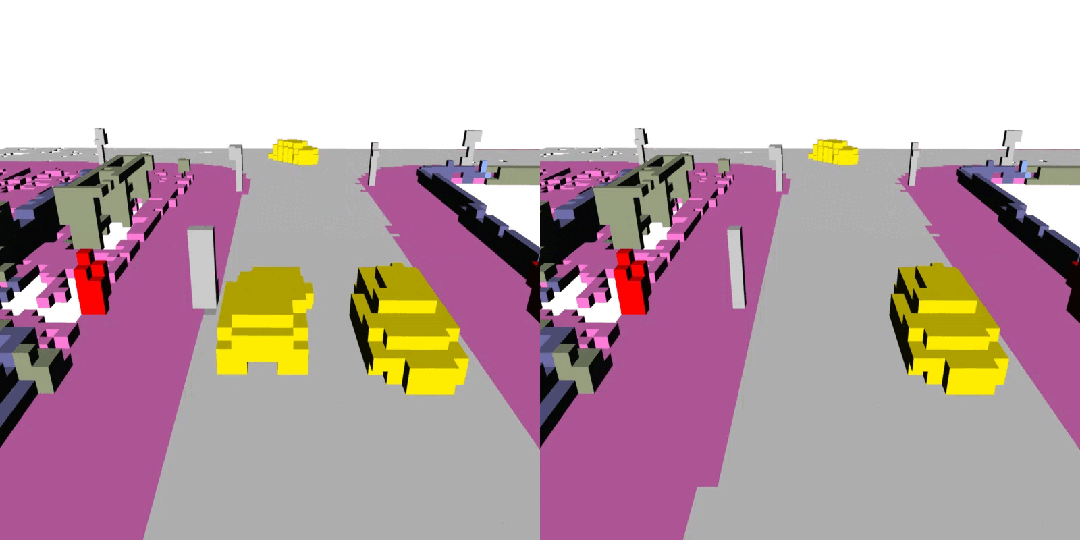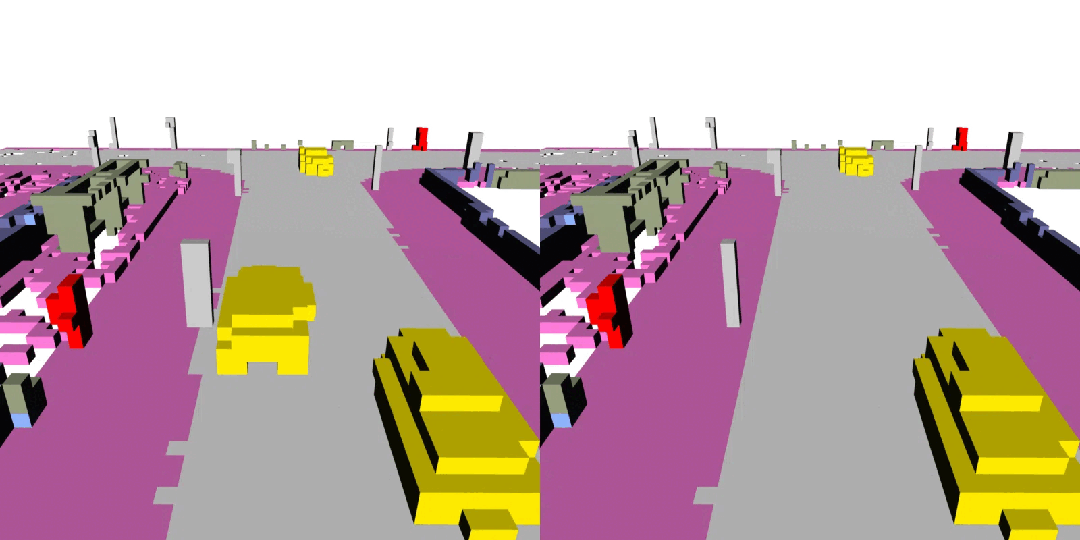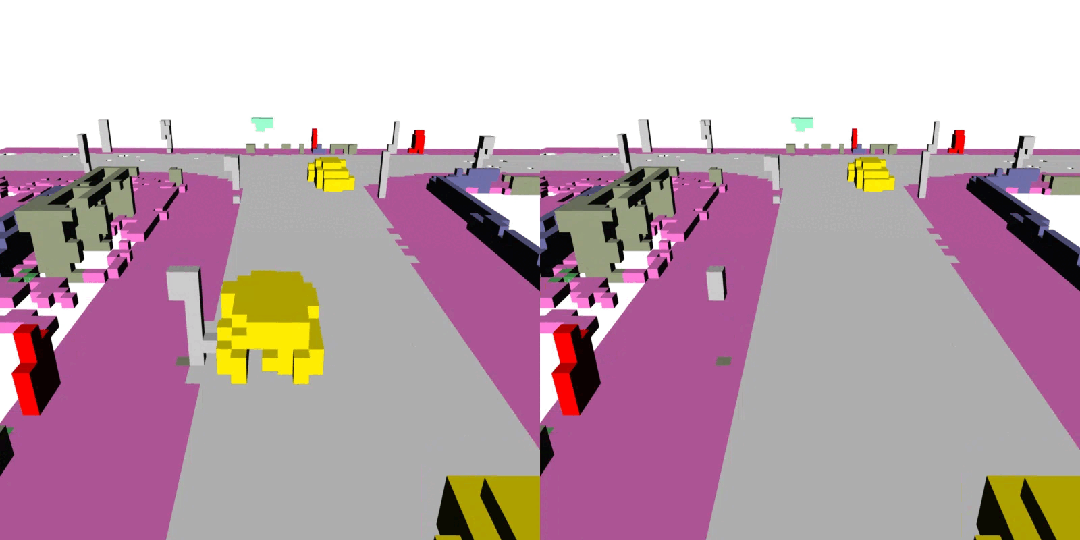
下面展示了一些 DynamicCity 的结果,包括无条件生成的结果,布局控制生成结果等。
无条件生成(左:OccSora [4]; 右:DynamicCity)
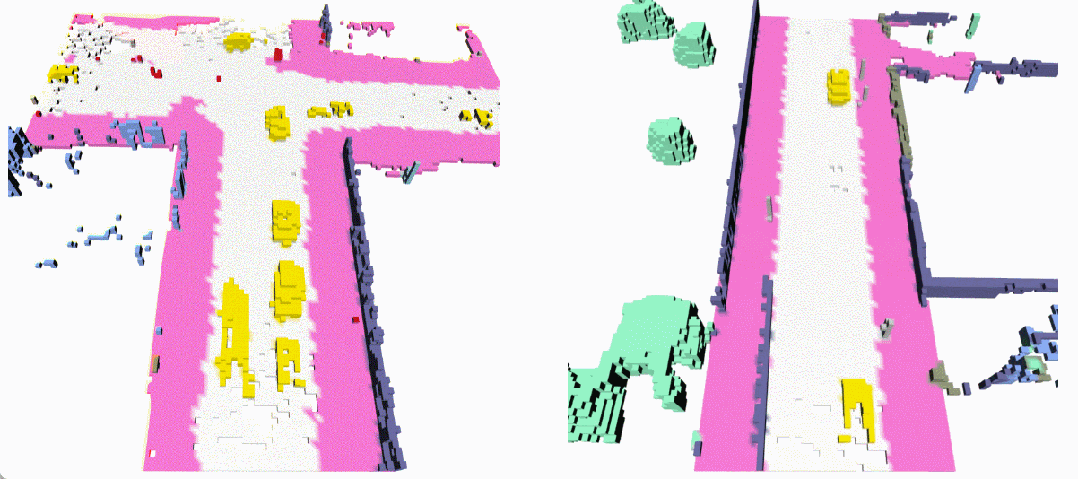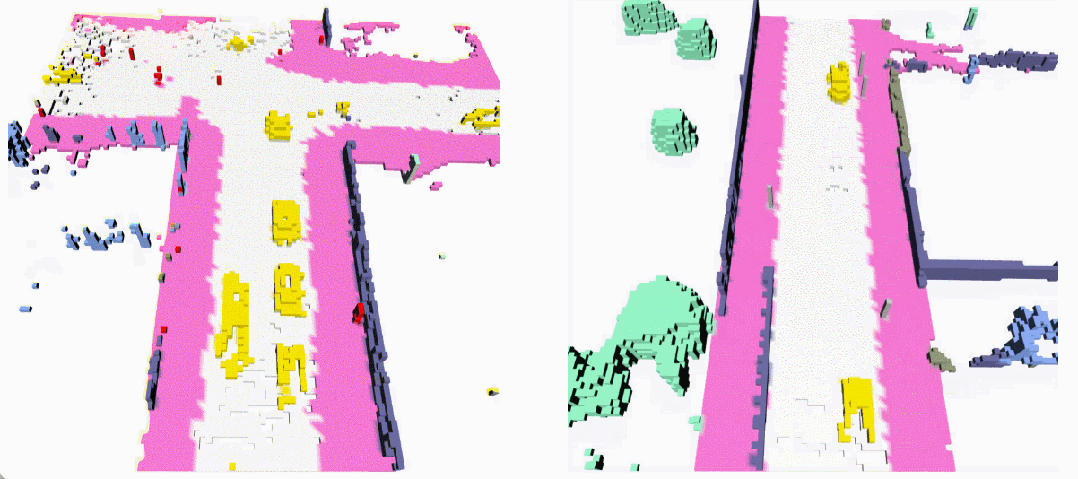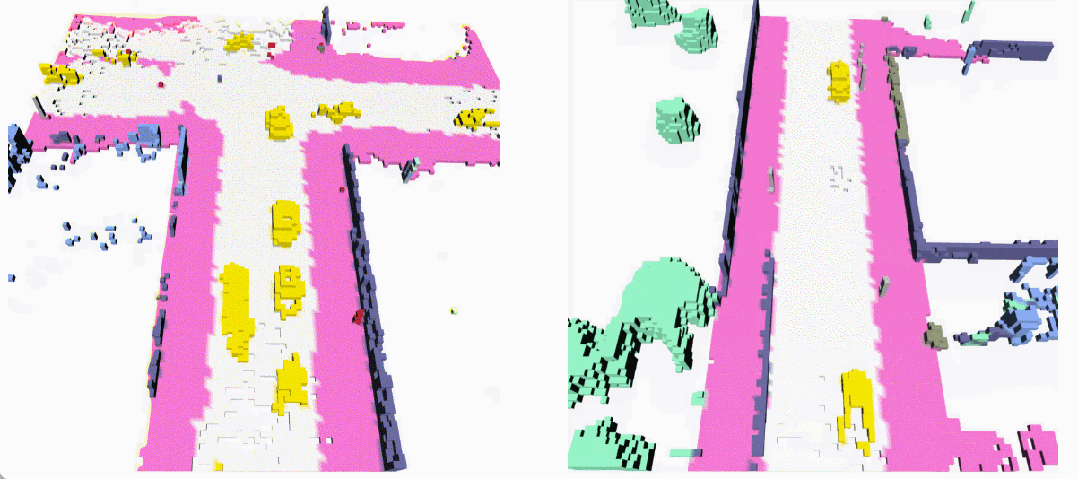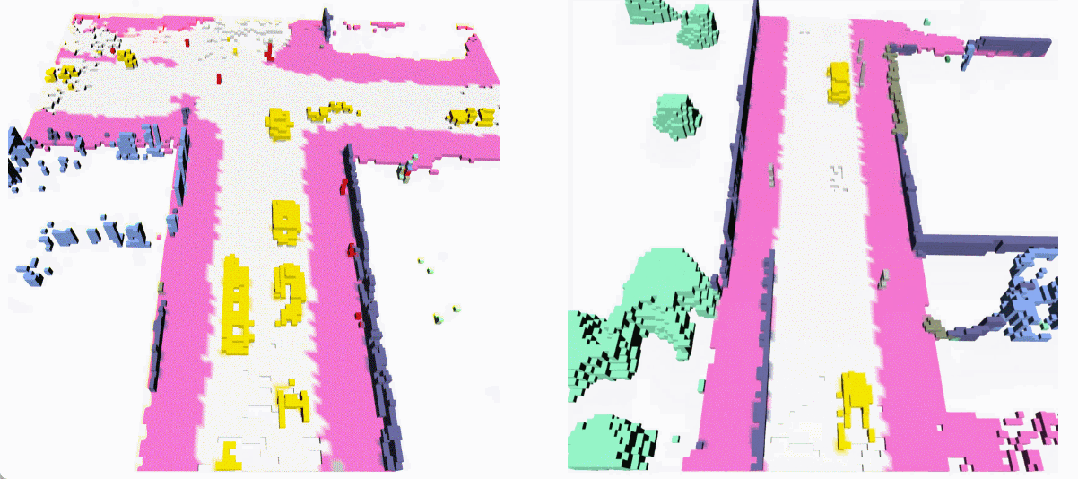

长序列生成

布局控制生成

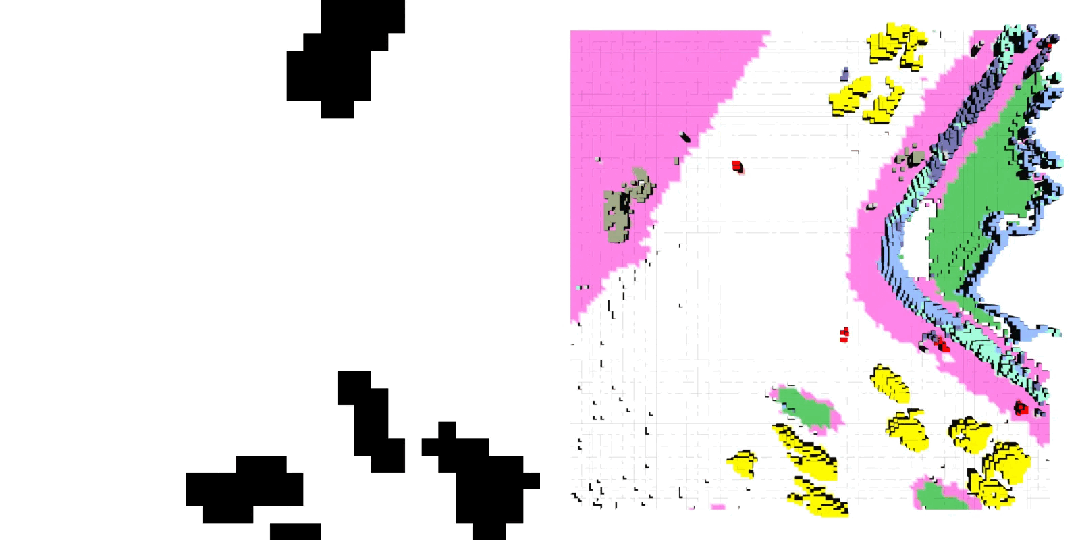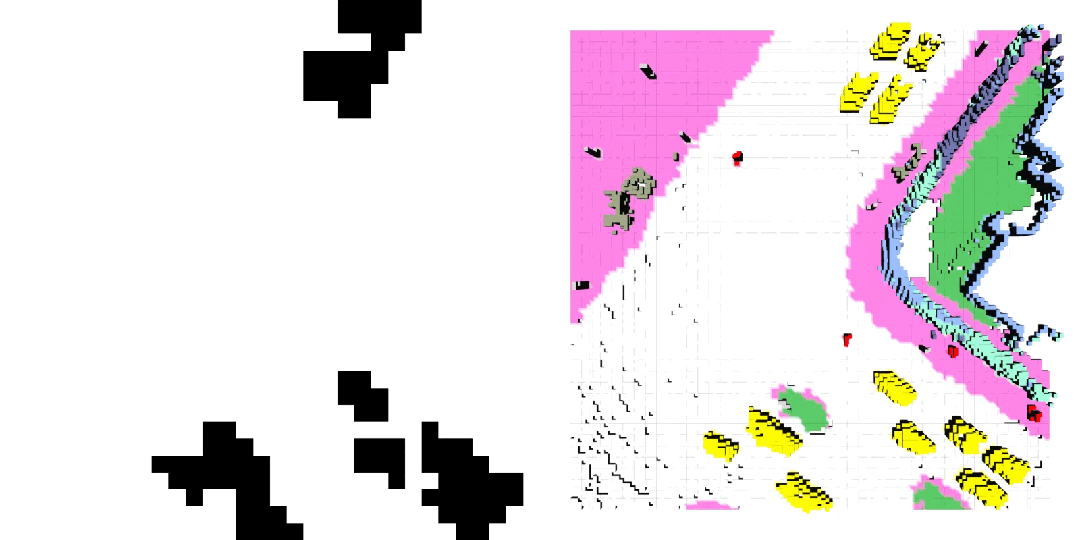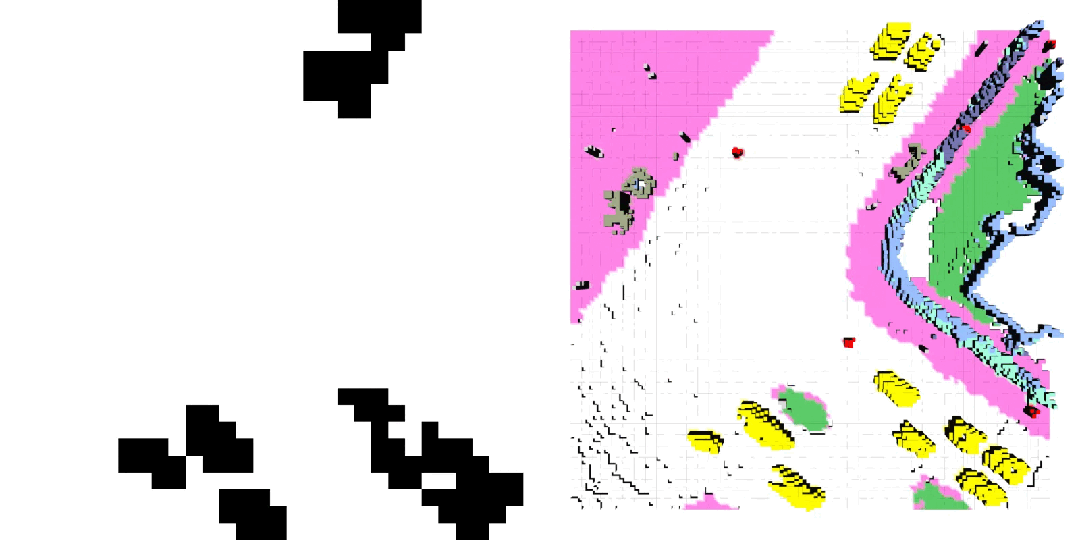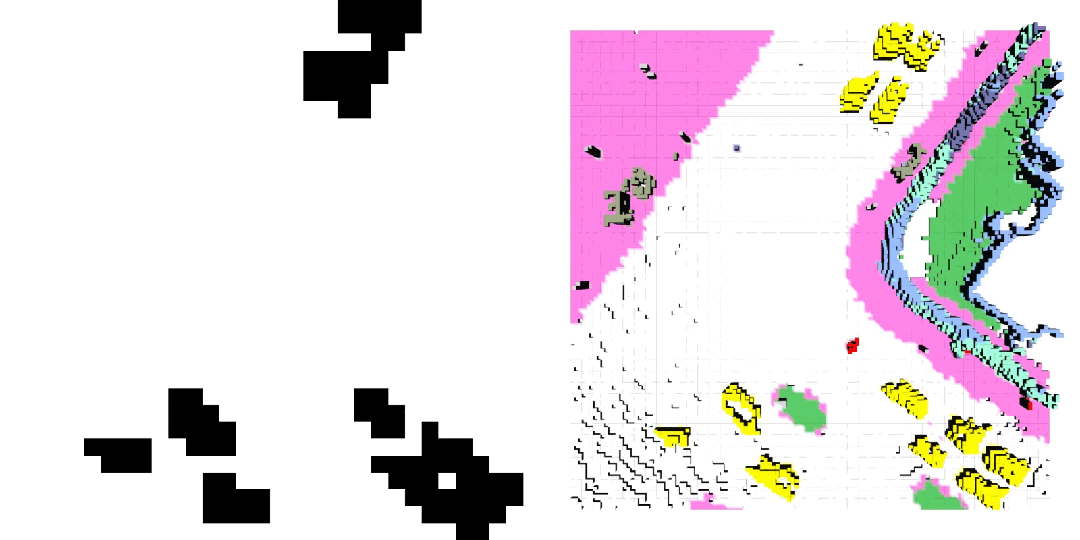
车辆轨迹 / 自车运动生成

4D 场景编辑

总结
DynamicCity 提出了基于 HexPlane 的 4D 场景扩散生成模型,通过 HexPlane 表征、Projection Module、Expansion & Squeeze Strategy、Padded Rollout Operation (PRO),以及Diffusion Transformer 扩散采样,实现了高效、可控且高质量的 4D 场景生成。此外,DynamicCity 还支持多种可控生成方式,并可应用于轨迹预测、布局控制、自车运动控制及场景修改等多个自动驾驶任务。
作者介绍
DynamicCity是上海人工智能实验室、卡耐基梅隆大学、新加坡国立大学和新加坡南洋理工大学团队的合作项目。
本文第一作者卞恒玮,系卡耐基梅隆大学硕士研究生,工作完成于其在上海人工智能实验室实习期间,通讯作者为上海人工智能实验室青年科学家潘亮博士。
其余作者分别为新加坡国立大学计算机系博士生孔令东,新加坡南洋理工大学谢浩哲博士、刘子纬教授,以及上海人工智能实验室乔宇教授。
References
[1] Lee, J., et al. (2024). SemCity: Semantic Scene Generation with Triplane Diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 28337-28347).
[2] Liu, Y, et al. "Pyramid Diffusion for Fine 3D Large Scene Generation". ECCV, 2024.
[3] Ren, X, et al. "XCube: Large-Scale 3D Generative Modeling using Sparse Voxel Hierarchies". CVPR, 2024.
[4] Wang, L., et al. (2024). OccSora: 4D Occupancy Generation Models as World Simulators for Autonomous Driving. arXiv preprint arXiv:2405.20337.
[5] Gu, S, et al. "DOME: Taming Diffusion Model into High-Fidelity Controllable Occupancy World Model". arXiv, 2024.
[6] Fridovich-Keil, S., et al. (2023). K-planes: Explicit radiance fields in space, time, and appearance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12479-12488).
[7] Cao, A., & Johnson, J. (2023). Hexplane: A fast representation for dynamic scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 130-141).
[8] Peebles, W., & Xie, S. (2023). Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 4195-4205).
[9] Ho, J., & Salimans, T. (2022). Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598.
本文仅做学术分享,如有侵权,请联系删文。


3D视觉交流群,成立啦!
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、最前沿、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
最前沿:具身智能、大模型、Mamba、扩散模型、图像/视频生成等
除了这些,还有求职、硬件选型、视觉产品落地、产品、行业新闻等交流群
添加小助理: cv3d001,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
「3D视觉从入门到精通」知识星球(点开有惊喜),已沉淀6年,星球内资料包括:秘制视频课程近20门(包括结构光三维重建、相机标定、SLAM、深度估计、3D目标检测、3DGS顶会带读课程、三维点云等)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

卡尔曼滤波、大模型、扩散模型、具身智能、3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪等。

3D视觉模组选型:www.3dcver.com

— 完 —
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~

















 1601
1601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









