







寻找Google终结者(上)
作者:坚如磐石
声明:作者的一切言论仅基于个人业余爱好,单纯从技术的视角来观察世界,并以此和热爱思考的朋友们交流,不欢迎任何带有个人感情色彩和主观意识范畴的评论。同时,因为作者只是个普普通通淹没在众多打工仔中的程序员,如同沧海一粟,由于自身的限制难免会出现错误甚至荒谬的言辞,但我相信更高水平的人会抱以宽容的态度给予指正,让作者得以从交流中提高自己。

Google是一家优秀的企业,笔者同很多人一样也非常认可她在信息处理史上所做出的卓越贡献。但同任何企业一样,她也时刻面临着来自各种竞争的威胁。有时候,相对商业竞争的威胁,技术竞争的结果给一个企业所带来的打击可能更加致命,也更加难以逆转。因为这种技术竞争是一种自然达尔文过程,残酷的进化进程从来都是不可逆转的,如同我们再也不可能回到没有互联网的时代了。
“IT WILL TAKE YOU A MILLION LIGHT YEARS FROM HOME. BUT WILL IT BRING YOU BACK?”- “星际之门”电影海报
从技术竞争的角度来看,谁将是Google终结者?本文将试图和大家一起寻找潜在的Google终结者。
有可能存在Google终结者吗?
从商业模式来看,虽然Google也在致力开发很多领域的产品,但这些产品要么不成体系要么依附于Google搜索,所以作者认为搜索系统仍然是Google的重要支撑基础,如果失去这个支撑基础,其他的东西如同“皮之不存毛将焉附”一样,竞争优势将不复存在。与竞争对手相比,我认为这就是Google脆弱的地方。以微软为例,它从操作系统、开发工具、数据库、办公系统、企业服务、网络服务…等构成一个完整的体系,各部分互为支持和制约,所以很难在单个领域对它产生致命威胁。
另外一个问题就是用户的忠诚度。根据我们自身的经验,网络服务用户的忠诚度是很低的,因为使用哪个网站来搜索不需要付出任何投资,不管是时间上的还是经济上的,再加上也没什么负担,所以只要有更好的技术出现,这些零成本用户就会毫不犹豫的离开。这跟办公软件、操作系统、数据库的用户是不一样的,要这些用户改换门庭他们首先会考虑迁移的代价和获得之比。即便对于使用盗版软件的用户来说,他也付出了时间的代价,获得了使用经验,积累了大量数据,这些都是作为迁移时用户会考虑的成本,所以他们不是零成本用户。
基于以上两个弱点的分析,作者认为Google的确有可能被单一领域的技术进步而终结,至少潜在危险是存在的。当然,相信Google自己比任何人都清楚这一点,所以也会努力改变这个金鸡独立的状态。不过建立自己的系统需要较长的时间,问题是当终结者真的出现的时候,Google是否已经准备好了呢?目前还不得而知,但Google是在和时间赛跑,但作者后面会提出的终结者将会以级数的速度前进,Google很难在时间上赢得它。最后很可能是Google自己会选择终结自己,她会抢先把终结者带到这个世界。
Google搜索系统内部原理简介
既然Google的支撑点和易受攻击点都是其搜索系统,那么我们寻找Google终结者的目标也就只能从这里入手。如果我们对Google的搜索系统内部原理一点不了解,那肯定找不到终结者会出现在哪里。所以,让我们先看看Google的搜索系统大概是什么样子,下面这个草图是作者基于自己的理解所画,并且为了说清楚其主要部分,省略和简化了很多细节。
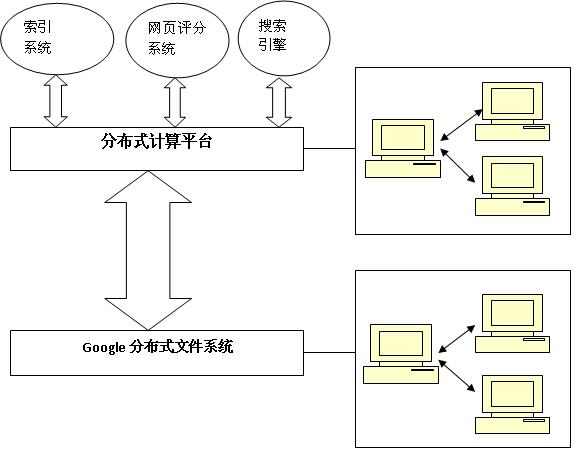
上图中各部分都是干什么的呢?按照从下往上的顺序介绍:
Google分布式文件系统:简称GFS。它由数千台PC所组成的网络,提供数据文件的分散存储和提取。它有两个主要目,一是使用廉价便宜的PC机提供网页缓存、索引数据库等必需得的高可靠性大容量存储服务;二是配合分布式计算平台实现高效的并行处理。GFS系统的特点有三:1.专门为搜索系统设计因而高效好用. 2.与上层的分布计算平台结合. 3.很高的鲁棒性,数据有多份拷贝,自动监测个别机器故障。
分布式计算平台:简称MapReduce。它基于分而治之的思想,抽象了索引系统、评分系统、搜索引擎等计算密集型任务,统一简化成“分散运算—合并结果”这两个过程。例如,要给数一个100K的网页统计单词个数,那就可以把这个网页分成10K一个单元,先由10台机器分别去数,同时启动其它机器对运行结果进行合并和去重任务。它在分配任务的时候会尽可能把计算任务分配在能最快访问相关数据的机器上(比如就是GFS中恰好本地存有所需数据的机器)。而且它会监测每个子任务的执行状态,必要时重新分配机器执行该子任务。
索引系统:由网络爬虫、URL服务器、索引器、词表等组成。网络爬虫抓取网页缓存在GFS中,并记录网页链接关系。索引器对网页做单词索引。简单点说,这个系统的目的就是生成一系列数据库,根据这些数据库可以知道某个词出现在哪里文档里,包括在文档里的位置以及其它属性。同时它也记录URL之间的链接关系表,给一个URL,可以通过查表知道有哪些URL指向它,它又指向谁。
网页评分系统:PageRank,这是Google的核心技术之一。Google搜索结果呈现给用户的时候是根据网页分数排序的。这个分数的计算,从公开资料来看分两部分,一是根据URL链接表的统计数据迭代计算,基于概率模型。即根据全网的链接关系计算出用户选择某个网页的概率,如果很多网站指向你的网页你的网页被选中的概率就高,如果这些指向你的网站本身就是分数很高的重要网站你的网页被选中的概率就更高,同时那些指向你的网站链接出去的越少则代表你的网页被选中的概率越大。这其实也是符合常识的。第二部分是一些小技巧部分,用来调整第一部分计算出的分数,很多规则Google没有公布。例如如果关键字在你的网页中是标题或者黑体或者比周围字体大,那分数就高一些,如果这个关键字是链接的文字说明分数也会高一些等等。当然,如果有钱的话,相信Google也很方便调整你的网页分数。
搜索引擎:分解并规范化用户的搜索请求,合并生成搜索结果。这没什么好说的,数据库操作而已,并不是Google的关键部分。
介绍完这几个组成部分,再结合上面的示意图,我想大部分技术人员和理工科学生都可以大概明白这个系统是怎么工作的了。如果有什么细节问题要讨论,请到作者主页留言,我会尽我所知回复。
从Google专有部分的特点寻找终结者潜在的方向
上节介绍的Google搜索系统的主要构成中,有几个部分是Google所专有的:Google分布式文件系统、Google分布式计算平台、以及Google网页评分系统。除此之外的部分,如索引系统和搜索引擎部分,和各主要竞争者相比并没有什么特别的,相信任何一个合格的程序员或者热爱编程的在校生都可以完成,不需要天才。
既然如此,Google之所以成为Google,秘密必然存在于这三个专有部分。同样地,如果有什么对Google构成致命威胁,也必然是针对这三个部分的。如果是模仿Google或者基于同样原理的衍生品,那肯定对Google不构成真正的威胁,因为你跑的快,Google拥有的资源可以保证他跑得比你更快。如同你跟刘翔比赛跨栏,那你赢的可能性极小,也构不成对世界冠军的威胁。
真正的威胁只能来自于和Google不同构的技术发展,它们将是什么呢?笔者只是个小程序员,不敢妄自尊严去预言什么。但我愿意提出自己的一些分析和思考,供大家分享。
下面,我们不妨从分析Google这三大专有系统的特点入手。
在Google的设计中,Google分布式文件系统 及Google分布式计算平台之所以优秀,并不是因为其它企业做不到,实际上市场有很多分布式存储系统如EMC和微软都提供。分布式计算平台也同样有很多,技术上未必就不如Google先进。在作者看来,Google的这两个系统最大特点在于它们就是针对搜索系统的需求而设计的,而不是设计成一个什么都能干又什么都干不好的完美通用系统。(注:有关这两个系统实现细节请参看Google发表的相关论文)。另一方面,它们的设计又的确实现了简单、高效、灵活的最高境界。简单不是简陋,高效不是死板,灵活不是无限…这正是软件工程实践里的真正艺术之处。说实话,对笔者这种水平来说,我只能说我能看到,我能欣赏,我会努力向这种艺术的境界前进,即所谓“大道至简、重剑无锋”。从设计思想和设计者水平方面来看,以我的理解,Google终结者只能是超越而不是对立的东西,即新的技术要更简单可靠、更加高效也更加灵活。否则难道一个设计上“复杂、低效、死板”的系统能对Google构成威胁?所以,我们确立第一个寻找方向:比Google分布式文件系统 及Google分布式计算平台更加简洁可靠、更加高效、更加灵活的设计。
好,我们确立了第一个方向,但这个方向未免太大,一点头绪没有。换个角度,我们从结构上来观察Google的分布式文件系统和分布式计算平台。如果大家回到我开始画的那个示意图,有没有认识到这是一个组织严密的结构化系统?即系统逻辑上分成一块一块的,数据流向是从A到B,从B到C,从C到D,都是可以预期的,每个组成部分各干各的事情,有条不紊,可以用一个稳定的流程图来表达。这和我们都政府组织体系类似:科教、文化、财政、税务、交通、司法…各管一块,你要去政府办一件事得按照一个流程一块一块去完成,尽管有些事情可以分解成几部分并行去处理。我们知道,与“结构化”对应的组织形式是松散的“非结构化”,在“非结构化”系统里,你根本就画不出完整的流程图来,很难分出各个清晰的各部分来,各个体的功能是不稳定的,随时发生变化,数据流向也一样。这两种系统,有点类似股市里的机构投资者和散户投资者。机构投资者的行为一般可以流程图化,事实上他们内部也是结构化的组织形式。而散户投资者就完全不同,他们的行为很难用流程图来表达,他们的群体也是松散和非结构化的,没有从A到B从B到C的可预测的稳定的信息传递关系。既然“非结构化”的组织形式与Google系统的组织形式是不同构的,而我们又暂时不能断定结构化组织一定优于非结构化组织(自然界是非结构化的,而人类社会整体上是结构化的,人定胜天?),所以我们的第二个寻找方向就是“非结构化”的组织形式。
再前进一步,如果注意到示意图中右侧的三台计算机之间的箭头关系,可以发现:这揭示了Google的系统是Centralized(中央集权)系统,即它的系统中存在集权中心,扮演着管理者和控制者的角色。比如在Google分布式计算平台中,它有一台机器是任务管理器,索引、评分等系统提交的任务由它接收,它再把任务分解发送给其它机器去做,其它机器要向它汇报状态。任务全部完成后,也是由它告诉调用者最后结果。这种结构有点能类似于厂长、科长、组长、员工的结构模式。这种集权系统的优点是通常效率高,缺点是这些关键集权中心一旦出问题了,整个系统即停止运转或者崩溃。与Centralized(中央集权)系统相对应的是Decentralized(无中心)系统(听上去像是无组织无纪律?呵呵,我们谈的是技术问题)。这就是我们确立的第三个寻找方向“Decentralized(无中心)”系统。
最后,我们来谈谈Google的网页评分系统(PageRank)。我觉得它的这个东西最大特点就是数学上自成体系,而且也符合人们的直觉,所以效果不错。但是,它既然自成体系,数学上构成完整的概率空间,也就决定它很难改变。一旦有不在这个概率空间里的因素加进来,它很难保证不破坏自己的数学模型,这就是说Google在这个系统的进步中将遇到的最大的障碍来自自己,他会倾向于只做修修补补和微调,不到万不得已不会去破坏自己完美的数学模型。PageRank虽然考虑其他信息,但本质上是基于互链接的统计模型。但是,网页和文档之间的关系包括其重要性并不是仅仅由链接所能揭示的,与链接模型相并列的还有一个“ 基于内容相关”的模型。当然,Google也在做“ 基于内容相关”模型的研究,但目前看来似乎也只能据此在输出结果的表达形式上作些调整。这似乎也是Google终结者可能存在的方向之一,但作者认为在人工智能研究没有突破之前,“ 基于内容相关”的模型也很难有根本性进步,所以在这个方向上暂时还找不到可以立即对Google的PageRank构成致命威胁的东西,所以暂时我们不把这个列为寻找方向之一。
确立了三个寻找方向以后,其实Google终结者是谁的答案已经非常明显了。它是谁?大家不妨先给出自己的答案,作者的推测请听下集分解。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









