







Some Raw Thoughts about apply “Stigmergy” Model to Search System
Word “Stigmergy” describes the basic mechanism to build natural Self-Organized system. Originally this word is used to describe the behavior of nest-building and ant trails. But more often, it is associated with the meaning of “Local actions can achieve global tasks” or “the whole is greater than the sum of its parts”.
Research demonstrated that this mechanism is a robust and viable alternative for clustering data and following trail. Furthermore, because this mechanism has crude potentials by adopting distributed parallel computing, I believe it’s an abstractive model for data mining applications in internet/Intranet environments.
Concretely, how can “Stigmergy” model apply to Search applications? In Part-I, we try to comprehend the key essentials of the model. And in Part-II, I present a raw solution for Search system to leverage the model by combining some research result of others. And lastly, I list some small experiment plans for following study.
Part I: How to build a “Stigmergy” Model?
The basic principle of Stigmergy is very straightforward: Individuals take actions according to local environments including its own states (context), and as a result, the actions will modify the local environments and its own states (See the figure below).
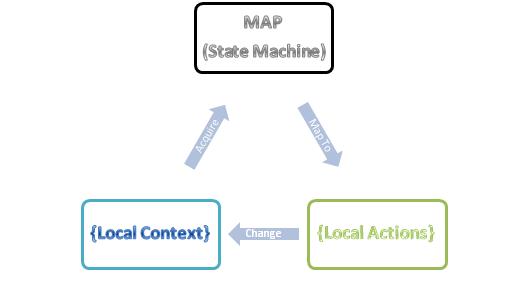
So, the tasks for building a Stigmergy model can be simplified into three questions.
1) What’s the set of {Local Context}?
Generally say, {Local Context} = {Environment Data} + {Private States}.
For Ants to find food and then back to its nest scenario (apply to network routing and distributed system), the environments data is the strength of pheromone around it, and the private data maybe include its own state such as “Position”, “carry with food?”, “energy level”, “latest visited cells”, etc.
For documents clustering scenario, the environments data maybe the eigenvector of current neighboring clusters, the private data maybe include position, adaptive parameters and the document we are processing. (It is possible to use TFIDF as eigenvector for document clustering).
2) What’s set of {Local Actions}?
Ants do not know how their local actions will contribute to global tasks; they just take actions to modify the local environments including its owned states. So, the set of {Actions} depends on the set of {Local Context}, we should define the actions which can efficiently change the local context.
For Ant to find the shortest path, we can define the actions set as {Deposit Pheromone, Move into n-th Neighboring Cell, Carry Food ….}. Those actions have abilities to change corresponding local context such as “local pheromone strength”, “position”, “Carried Food?”…
For documents clustering, the actions set can be defined as {Pick Document, Move into n-th Neighboring Cell, Drop Document…}. Those actions have abilities to change the key local context – “Average Similarity”.
3) What’s the map function for “{Local Context} è {Local Actions}”?
The difficult part of “Stigmergy” model is finding the map function F. This function decodes the local context into the probabilities of taking i-th action.
The design rules for function F is: Each individual should take the actions which have maximum probabilities to achieve better condition of it. For example, an ant should move to a cell which has higher strength of pheromone because such cell has higher probabilities in the shorter path to nest. For documents clustering, each document wants to find similar neighbors. The function F should outputs maximum probabilities to drop a document at a position where neighboring documents is similar to it (Average distance is low) and also outputs a maximum probabilities to pick up a document from a position where this document is very different with neighbors.
However, to avoid fall into the issue of local optimization, a stochastic mechanism should be applied in function F.
Currently, most researches choose the map function F by means of analysis and experiments. Though those manually defined map functions are pretty efficient to achieve global tasks, but I think we maybe can try other natural methods to generate a State Machine without too many magic numbers. For example, can we use Gene Algorithm to generate a State Machine instead of a formula F? Can we training a neural network? Expect to do some experiments recently (See Part III).
If the description above is the whole story of “Stigmergy”, I think it is an equivalent to Stochastic Heuristic Search. Actually, “Stigmergy” mechanism has another important fundamental fact: the environment itself changes as time going on. In the world of ants, pheromone evaporates with the lapse of time. This mechanism is more like the function of “forgetting” of our brain. Without the mechanism of “forgetting”, ants cannot find the way to home and also cannot be adaptive new changed conditions (such as there is a new shorter path appears). However, excepting the applications for finding shortest path, no clustering application adopts the “forgetting” mechanism. I don’t know the real reason of ignoring the important fundamental. Maybe the environment for clustering is comparatively stable enough, I guess.
I do believe that same mechanism not only apply to the world of ants but also apply to human society. Furthermore, I believe what happing in the ants’ society is what happing in our brain. “Intelligence” should be built by the same way of nest-building. “Intelligence” is complex, but the back-end mechanism of building intelligence should be simple. However, “Stigmery” is not the whole story. Considering the lack of “Stigmergy” mechanism, I think we should notice other important principles, for example:
- Evolutionary theories of Darwin.
Could we train the state machine by evolutionary theories? can we introduce multi nests for competition?
- Fractal Theory.
Could we think about multi layered document clustering?
Part II: How to apply “Stigmergy” model to Search system?
By the experience of using popular search engines (such as Google), I think we can do better by combining “User Intelligence” and “Machine Intelligence”. 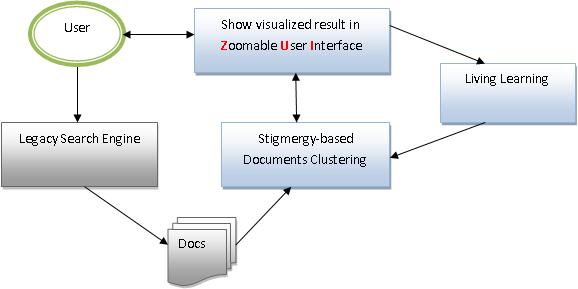
No machine can be more intelligent than a human user. Instead of trying providing more exact search result to user at back-end, maybe we can pay more attention to the interaction model between user and search engine.
In the above figure, “Sigmergy-based Document Clustering” works on the raw output of legacy search engine. It classifies the documents into multi layered clusters according to contents-similarity.
At the same time, ZUI (Zoomable User Interface) has been demonstrated as the best UI for user to search information. ZUI need multi-layered clustered data, this is just match the output of our clustering.
“Living Learning” component is also built on “Stigmergy” model. Different with clustering, it is another application of Stigmergy - Trail Following. It help user to see the path he/she walked and also help back-end clustering know the potential relationship between topics. (For example, could we show a visual “Road” between cluster A and B if many users jump from A to B when exploring the search result?)
The clustering result of Sigmergy model should look very natural: similar documents will congregate around a local topic center (the center of one cluster has maximum similarity to its neighboring documents), relative topics will be closer in physical position. The boundary of clusters should also look natural – because “Stigmergy” model involves stochastic process. So, if we draw the clustering result in 3-D by use “similarity” as the document height, it should looks like the figure below.
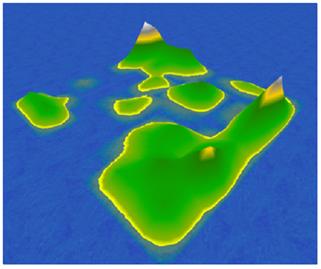
Thus, we not only providing a documents list and its ranking, we also let user know the relationship of the output documents. It should be very helpful for user to exploring the search result.
ZUI is not graphical zoom but semantic zoom (similar to Google Earth?). On different zoom level, it display different context. For example, it only shows the title of representative document of a cluster at beginning. If user zooms into a cluster, it will show more elements of the cluster. Zoom in more, user will see the thumb, abstract….and lastly, user can read its content directly.
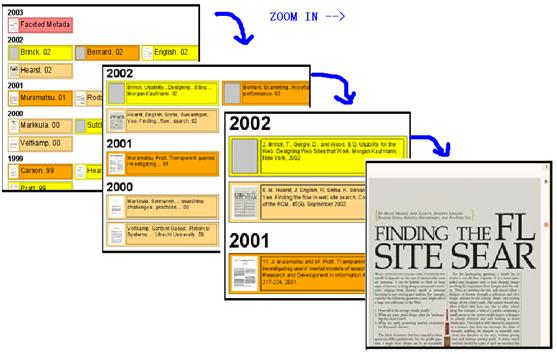
In fact, this model does not only apply to documents search, but also apply to the search for picture, audio, book, etc.
About implementation of Stigmergy-based clustering, we need to define the 3 tasks described in Part-I. As a beginning, we can just leverage the research result from others.
- {Local Context} to describe the local environments and current ant state. If we use TF*IDF eigenvector to represents a document, we can define the {Local Context} = {TFIDF Vectors of neighboring 3X3 Cells, If Carried with Document, Recently Visited Cells}.
Normalized TFIDF weight V(w) for word w in the eigenvector for specific document is:
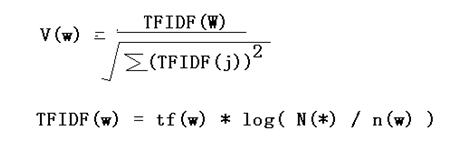
Where tf(w) is the frequency of word w in this document, and N(*) is the total number of documents, n(w) is the number of documents containing the word w.
- {Actions} to modify local context. Actions for clustering are simple: Move, Pick, and Drop. Ant can move to a random neighboring cell if no other occupant. By pick up or drop a document to current cell, ants will modify the environments and its own state.
- The function F for map local context into actions. Because most research randomly chooses the movement action (why not use the “Pheromone”?), so the function F is mainly to calculate the probabilities of P(drop) and P(pick). Finally, the core of function F is to determine the similarity (distance) between current document and its 3X3 neighbors. To measure the distance of two vectors, we can use Euclidean distance or cosine distance. Of course, like any manually defined map functions, we need to add some tuning parameters, such as we want function F to output higher probabilities to drop/pick documents at the beginning and lower probabilities at the end (Otherwise ants will build the cluster at the beginning and then destroy the clusters at the end).
About implementation of Living learning, we also need to define {Local Context}, {Actions} and the map function F. Similar to ants following trails scenario, please see the Part-I.
About implementation of ZUI, I did not think too much about it. It seems we need a data-driven ZUI engine running in server side to generate visual representation of clustered search result. ZUI engine maybe use AJAX technology to communicate with the scripts running in the browser side.
Part III: Experiments Plans
To furthermore understand and observe the behavior of “Stigmergy” model, I plan to do following basic experiments if have free time.
- Ants following trail Experiment. From this experiment, I want to observe the affection of ants’ number and pheromone evaporation. Instead of using manually define map function F, I also want to know if it’s possible to generate a state machine by GA algorithm.
- Outlook Email Auto Clustering and User Behavior Learning. We received many email every day, the actions we may taking maybe include Read, Reply, and Delete or never read. We have two questions here: 1) Can we auto cluster the emails for better management? 2) Can we learn by actions we took in the past to distinguish which type of emails should be important? Intending to read or reply?
Some References:
- O.E. Holland. Stigmergy and Collective Robotics
- J. Handl. Ant-based Clustering and Topographic Mapping.
- J. Handl. Ant-based clustering: a comparative study of its relative performance with respect to K-means, average link and 1d-SOM.
- Vitorino Ramos. Self-Organized Stigmergic Document Maps: Environment as a Mechanism for Context Learning.
- Andre L. Vizine. Text Document Classification Using Swarm Intelligence.
- B. Bederson. Pad++: A Zooming Graphical Interface for Exploring Alternate Interface Physics. Proc.
- B. Bederson. PhotoMesa: a zoomable image browser using quantum treemaps and bubblemaps.
- Combs, T. and B. Bederson. Does Zooming Improve Image Browsing?
- Eric Bier. Zoomable User Interface for In-Depth Reading.
- Peter Knees. An innovative three-dimensional user interface for exploring music collections.
(No permissions to republish, to post on servers)
(未经允许,不得转载)















 1153
1153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









