







本文选择了三个重要的统计数据来可视化分数分布:正负样本得分的均值 (表示pos/ negative对距离的近似平均值) 和 负样本得分的方差 (表示负样本在内存队列中的波动程度)。
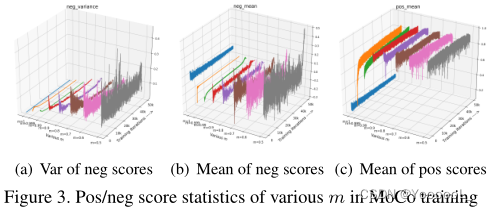
如图3(a)所示,当m变小时,编码器k的更新速度增加,导致训练步骤之间的 特征差异增加,表现为队列中 负样本分数的方差增加,即 不一致性。其中,当m = 1(训练中没有更新fk)时,方差接近于零(蓝线),而m = 0.9(红线)的方差较大,但相对不稳定。m= 0.5(灰色) 会带来更剧烈的内存队列波动/ 不一致性,导致 传输精度较差 甚至模型崩溃。
模型崩溃的内部分析:
模型崩溃是由多种原因引起的。m小(fk的更新速度快)带来的不仅是 不一致,还有负样本分数的混乱。负分数的平均值 反映了内存队列中 所有负样本对 的近似得分。如果随着训练过程的剧烈波动,相应的损失值和梯度也会剧烈波动,导致收敛性差。

从图4中可以看出,m = 0.99时(图4(a))平滑稳定的梯度 随着m的减少而变得尖锐杂乱。为了学习一个更好的预训练模型,我们需要为训练过程 准备 能够 保持分数分布和梯度的 稳定平滑 的负样本对,这类似于监督学习。
Hard Positive boost Performance:
m越小,更新速度越快,编码fk和fq的相似性也越大,即在极端情况下,当m = 0时,参数θk和θq在每个训练步骤中完全相同。编码器fq和fk的相似度的增加 会减少 zq和zk+之间的不相似度,只保留数据增强带来的视图方差,导致更高的正分值。从图3(c)可以看出,m≤0.9的高正分值会产生较容易的正对,且特征空间中距离较近,视图方差较小。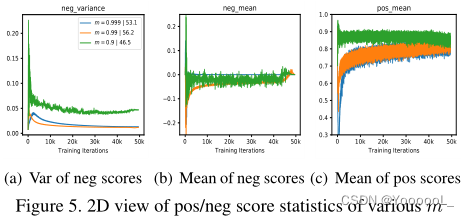
然而,m越高,正样本对更难,导致更高的转移精度。注意,这个观察结果(将简单的正变换为困难的正)可以用InfoMin原理 解释:提高zq和zk+之间的视图方差 对应于 增加对比学习的互信息,这迫使编码器学习更稳健的嵌入,从而提高传输精度。
为了保证分数分布和梯度的稳定和平滑,我们可以采用一些特征变换方法,通过减少容易得到的正分数 来产生不易得到的正分数。因此,本文提出了一种 正特征外推方法 来提高传输精度。
Info-NCE的学习目标是将嵌入空间中的正对(zq和zk+)拉近,而将负对(zq和所有记忆队列中的zk−)推远。因此,我们可以直接对pos/neg特征进行特征变换,以提供 适当的正则化 或使学习更加困难。本文 通过 正样本外推 将原有的正对进一步转化为 增加难度,通过内存队列的负样本内插 来增加负样本的多样性,如图6所示。本文没有改变损失项,因为它只是 用新的转换后的pos/ negg分数替换了原始的成对分数,用于计算损失项。
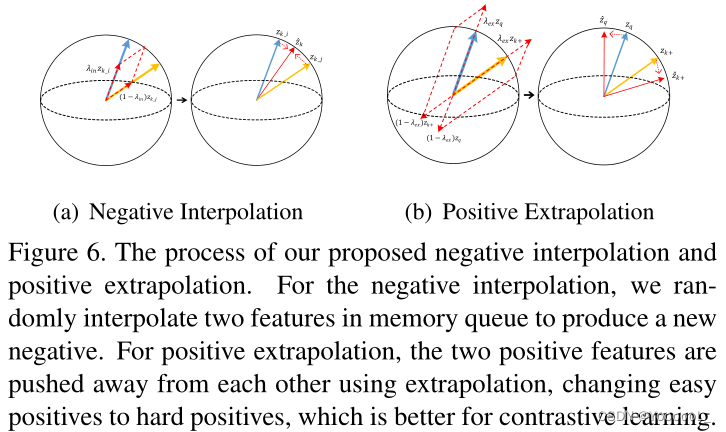
图6:对于负插值,我们在内存队列中随机插入两个特征来产生一个新的负插值。对于正样本外推,两个正样本通过外推相互推开,将容易的正样本改变为难正样本,这有利于对比学习。
正样本外插:
首先,我们简单地对两个正特征进行加权相加,生成新的特征:
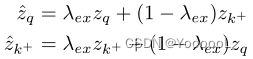
我们应该保证特征变换后的分数小于变换前的。直观地看,这似乎是在特征空间中推开zq和zk+的一种简单方法。外推后,外推特征向量之间的距离被扩大了。因此,外推可以作为一种特征转换,从简单的正样本中产生难正样本。如图6(b)所示,它给两个正向量带来了 较小的方向变化,同时传递了一个更大的视图方差的样本,以便更好地进行对比学习。
正特征之间的插值将正对拉在一起,从而降低了训练过程中的难度。也就是说,正对的视图方差在减小,因此容易产生非鲁棒特征。
负样本内插:
以往的对比模型没有充分利用负样本。例如,在MoCo中,有许多重复的负样本特征 存储在一个又一个迭代的内存队列中。因此,本文设计一种新的策略来 充分利用内存队列的负样本,增加内存队列的多样性。在具有足够随机性的情况下,本文提出了内存队列中的负插值,直观地为每个训练步骤提供多样化的负插值。
本文在两个内存队列之间使用一个简单的插值来创建一个新队列。
![]()
正外推增加了两个pos特征之间的视图方差,而负内插同样增加了内存队列的“样本方差”(多样性)。本文的方法可以通过随机插值 来填充分布的不完整样本点,从而得到一个更具辨别性的模型。负插值的目的是在每个训练步骤中充分利用负样本。
扩展内存队列而不是FT:在对比学习中 增加反例(K)的数量 有利于最终的性能,因此他们要么使用内存队列,要么使用大的batch size 来获得更多的负样本。与原始队列相比,插值的负特征包含了足够多的多样化的负特征。因此,即使是扩展队列(˜Zneg)的双负样本(更多的相互信息)也不能提高性能。
扩展队列需要对每个对比损失进行两倍的计算。因此,本文推荐使用较少的计算量但更有效的特征转换,而不是特征增强。
何时添加特征转换? 从不同时期开始FT (正样本外推+负插值)可以持续提高基线的准确性,从更早开始可以提高更多。本文的FT为训练带来了更大的梯度,这使得模型脱离了局部极小值,避免了过拟合。这些分析表明,本文的FT是一种即插即用的方法,并为对比模型的训练带来了持久的视角不变性和辨别能力。
维数级的混合会提高性能。
实验表明,本文的FT对各种对比模型具有通用性和鲁棒性。
最近的研究表明,在分类和检测上,SOTAs模型的迁移精度是不一致的,具有低相关性,称为“任务偏差”。一个重要的原因是SOTA的前置任务 针对分类 进行了专门的设计和优化,例如实例判别 和聚类 ,使得分类得到了很大的增强,而检测得到的增益很小。本文的FT在设计时并不是针对局部信息,而是更多的来自特征变换的不变性。这些实验表明,我们的FT比基于pre-task 的对比模型更少的任务偏差。性能的提升表明了本文FT的有效性和鲁棒性,并能够学习更多的“视图不变”和判别表示。
Conclusion:
本文开发了一个可视化工具来可视化正、负对的分数分布。利用这个可视化工具,我们可以了解对比学习过程的内部。本文发现了 启发我们的新特征转换 的重要观察,包括正样本外推,以便为训练创造更多的难正样本。
此外,本文还提出了负样本之间的插值,充分利用负样本,提供多样化的负样本。特征转换能够学习更多的视图不变和判别表示。转移到下游任务成功地证明了本文的模型具有较少的任务偏差。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









