










[Contrastive Learning] Improving Contrastive Learning by Visualizing Feature Transformation
关键词
对比学习 可视化方法 数据增广
问题简述
Motiviation
这是篇卖“方法”的文章。
- 作者提供了一种可视化工具(称之为score distribution),来分析、解释与理解对比学习的学习过程
- 基于score distribution的观察,作者提出了两种特征层面上的增广方式(Feature Transformation, FT),能够有效涨点。FT的使用十分方便,能够嵌入到各类对比学习方法之中;
方法介绍
先借用文章中的一图一公式来简单回顾下主流对比学习范式
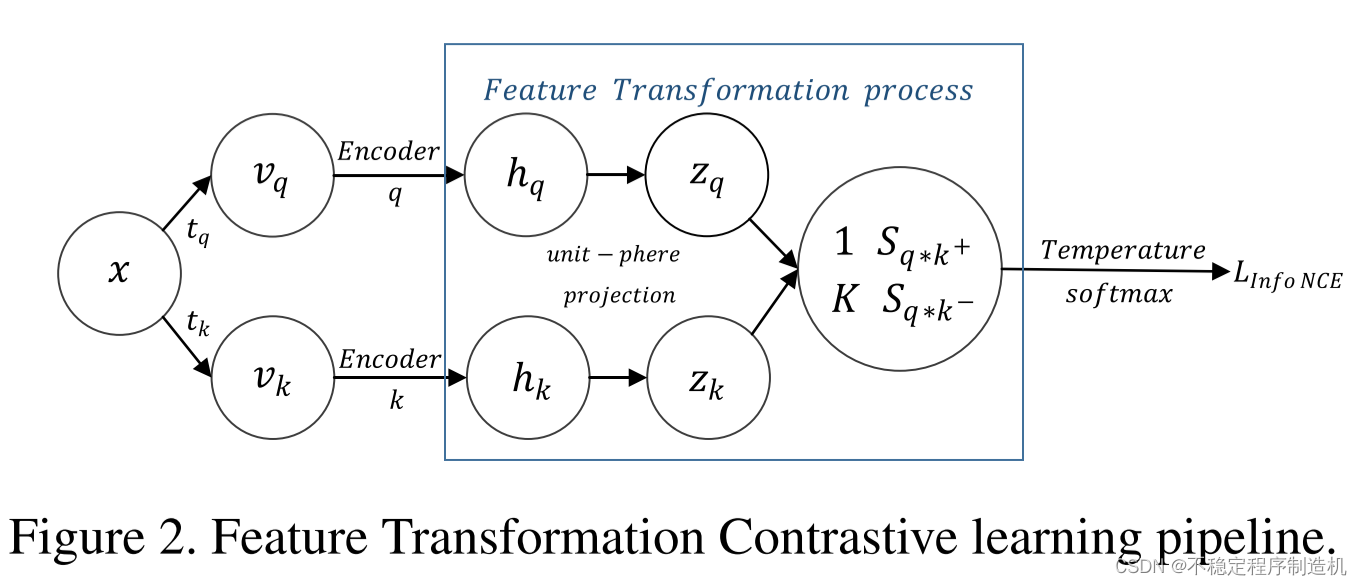
L
I
n
f
o
NCE
=
−
l
o
g
[
e
x
p
(
S
q
⋅
k
+
/
τ
)
e
x
p
(
S
q
⋅
k
+
/
τ
)
+
∑
K
e
x
p
(
S
q
⋅
k
−
/
τ
)
]
(1)
\mathcal{L_{Info\text{NCE}}} = -log[\frac{ exp(S_{q \cdot k^{+}}/\tau) }{ exp(S_{q \cdot k^{+}}/\tau) + \sum_{K}exp(S_{q \cdot k^{-}}/\tau)}] \tag{1}
LInfoNCE=−log[exp(Sq⋅k+/τ)+∑Kexp(Sq⋅k−/τ)exp(Sq⋅k+/τ)](1)
可视化工具 Score Distribution Visualization:
什么是Score Distribution呢?其实就是指
S
q
⋅
k
+
S_{q \cdot k^{+}}
Sq⋅k+(positive score distribution)与
S
q
⋅
k
−
S_{q \cdot k^{-}}
Sq⋅k− (negative score distribution),就是这么简单。
那为什么要使用score distribution呢?作者解释了两点:
- 主流的对比学习范式都是用InfoNCE损失,而InfoNCE损失其实就是在比较经过log-softmax之后的positive/negative score distributions。因此,使用score distribution能够更加直观的反应InfoNCE损失的学习过程;
- S q ⋅ k + S_{q \cdot k^{+}} Sq⋅k+ 和 S q ⋅ k − S_{q \cdot k^{-}} Sq⋅k− 是标量,数据量少,便于存储和可视化;
那Score Distribution怎么反应对比学习过程学的好坏呢?作者基于score distribution提出了三个统计量:
- positive score distribution均值,以下简称为 m e a n p s d mean_{psd} meanpsd.
- negative score distribution均值,以下简称为 m e a n n s d mean_{nsd} meannsd.
- negative score distribution方差,以下简称为 v a r n s d var_{nsd} varnsd.
以这三个统计量为基础,作者提出了两个标准:
- 在学习过程中, m e a n p s d mean_{psd} meanpsd最好不要太高。太高,说明参与训练的正例都是简单例,阻碍网络学习到更“本质”的特征;
- 在学习过程中, v a r n s d var_{nsd} varnsd最好不要太大,即 m e a n n s d mean_{nsd} meannsd的曲线最好保持平滑与稳定。波动太剧烈说明学习过程不稳定,容易导致模型塌缩(model collapse);
如何验证这两条标准是合理的呢,作者通过在MOCO中引入Score Distribution可视化工具来通过模型性能反推可视化工具的有效型,看下图:
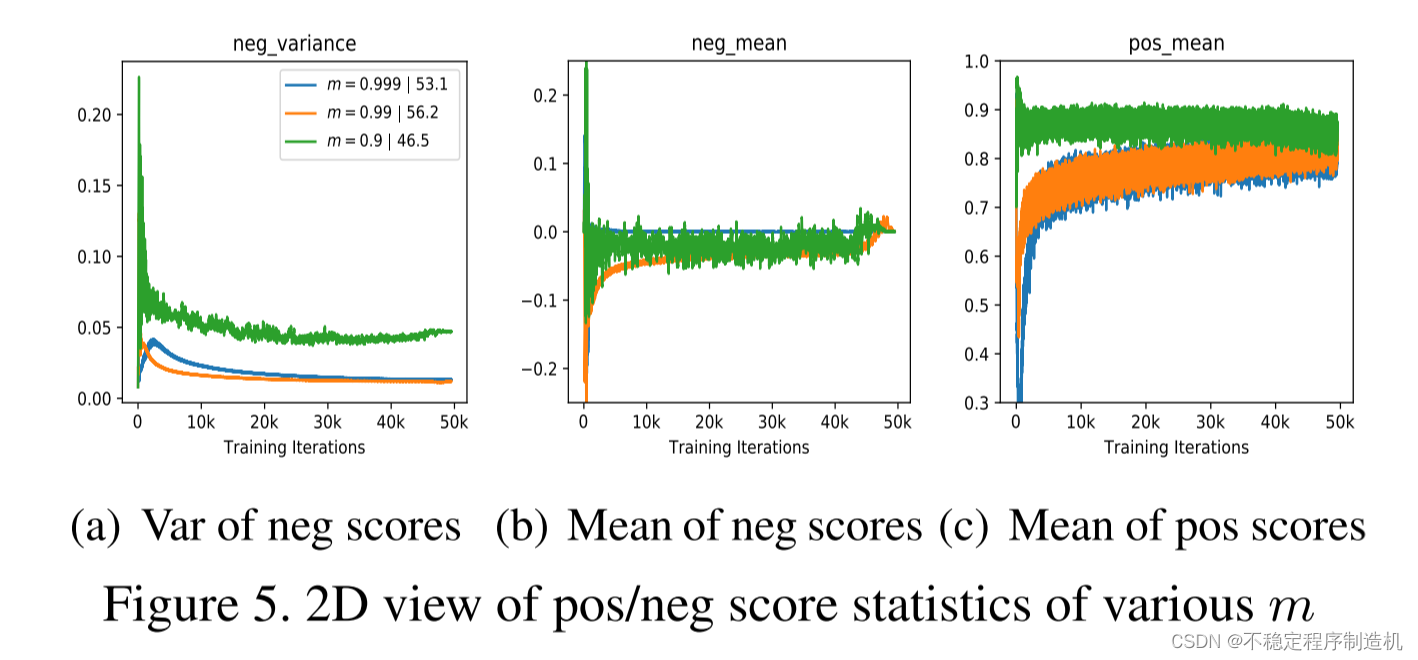
从上图(a)中我们可以看到,MOCO的效果随着动量参数m的变化而变化。用橙色曲线表示的
m
=
0.99
m=0.99
m=0.99分类精度达到56.2,是最好的; 蓝色曲线代表的
m
=
0.999
m=0.999
m=0.999次之,达到53.1;而绿色曲线代表的
m
=
0.9
m=0.9
m=0.9则只有46.5,模型性能大幅下降,塌缩了。
对比三种曲线在(a),(b),©三张子图上的表现,发现橙色曲线的表现是最符合两条标准的,即:
- (a)图中,橙色曲线最小,代表 v a r n s d var_{nsd} varnsd最小,蓝色和绿色依次变大,最终模型的分类精度也依次下降;
- (b)图中,绿色曲线最不平滑,即 m e a n n s d mean_{nsd} meannsd波动较大,反映了 m = 0.9 m=0.9 m=0.9时模型塌缩了;
- (c)图中,绿色曲线的 m e a n p s d mean_{psd} meanpsd最高,效果也最差,暗合标准1。
emmm,多少感觉有点牵强,不过看在Score Distribution是第一种分析对比学习的可视化工具,忍了。
特征层面数据增广 Feature Transformation:
本文提出了两种FT方式:

-
positive pair extrapolation,正例外延。目的是把正例之间的距离拉远,从而提升 m e a n p s d mean_{psd} meanpsd;
做法如下:
z ^ q = λ e x z q + ( 1 − λ e x ) z k + z ^ k + = λ e x z k + + ( 1 − λ e x ) z q \hat{z}_{q} = \lambda_{ex}z_{q}+(1-\lambda_{ex})z_{k^{+}} \\ \hat{z}_{k^+} = \lambda_{ex}z_{k^+}+(1-\lambda_{ex})z_{q} z^q=λexzq+(1−λex)zk+z^k+=λexzk++(1−λex)zq
λ e x \lambda_{ex} λex是超参数,要求大于1,满足Beta分布 λ ∼ B e t a ( α e x , α e x ) + 1 \lambda \sim Beta(\alpha_{ex},\alpha_{ex})+1 λ∼Beta(αex,αex)+1, 实验证明 ( α e x > 1 (\alpha_{ex}>1 (αex>1效果会比较好;其原理就和上图(b)中类似,这种做法实现简单的同时,能够满足 S q ⋅ k ≥ S ^ q ⋅ k S_{q \cdot k} \geq \hat{S}_{q \cdot k} Sq⋅k≥S^q⋅k -
negative pair interpolation,负例插值。目的是提升负例之间的多样性,从而提升 m e a n p s d mean_{psd} meanpsd;
Z ^ n e g = λ i n ⋅ Z n e g + ( 1 − λ i n ) ⋅ Z p e r m \hat{Z}_{neg} = \lambda_{in} \cdot Z_{neg}+(1-\lambda_{in})\cdot Z_{perm} Z^neg=λin⋅Zneg+(1−λin)⋅Zperm
Z n e g Z_{neg} Zneg就是负例的集合,在MOCO中就是memory queue,在SimCLR中就是BatchSize中的所有负例。假设 Z n e g = { z 1 , z 2 , . . . , z K } Z_{neg}=\{z_{1},z_{2},...,z_{K}\} Zneg={z1,z2,...,zK} Z p e r m Z_{perm} Zperm中的perm是permutation的缩写,即将 Z n e g Z_{neg} Zneg这个序列的顺序打乱。同样的, λ i n \lambda_{in} λin是超参数,同样也从Beta分布中采样得到 λ ∼ B e t a ( α i n , α i n ) \lambda \sim Beta(\alpha_{in},\alpha_{in}) λ∼Beta(αin,αin)。
原文中对于负例插值的作用解释如下:在负例数量不多的前提下,由负例构成的空间是十分稀疏的,通过负例(内)插值,能够使这个系数的空间更"稠密"一些,降低波动的影响;
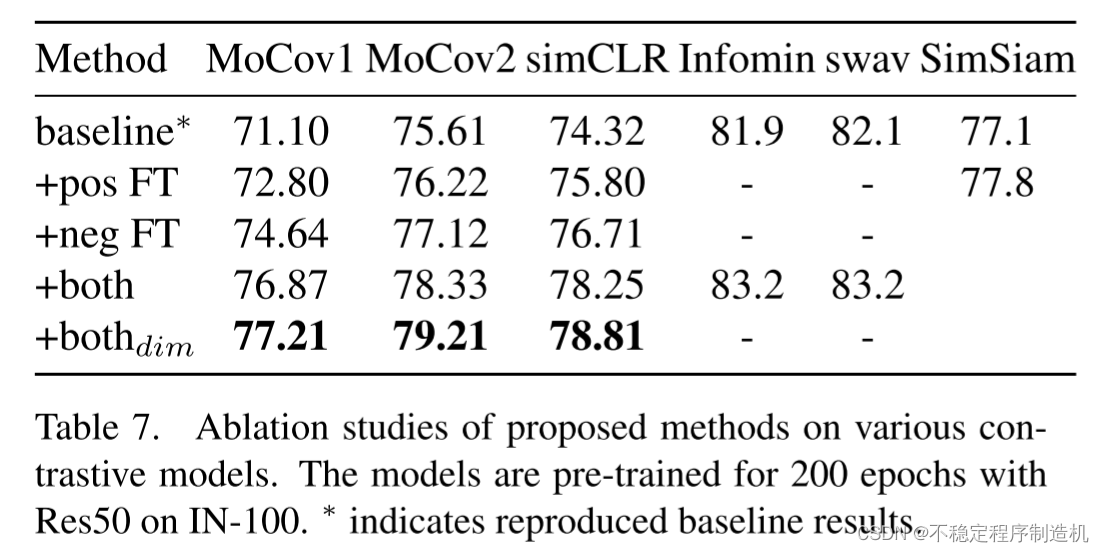
可以看出,两种FT效果还是挺明显的,而且对于对比学习框架没有约束,各个方法都能用。相比之下负例内插的效果更明显些,也符合“增大K值”很重要的一个共识。上表中最后一行代表着超参
λ
e
x
\lambda_{ex}
λex与
λ
i
n
\lambda_{in}
λin从一个标量变为了向量,两个FT操作也随之由vector-level变成了dimension-level;
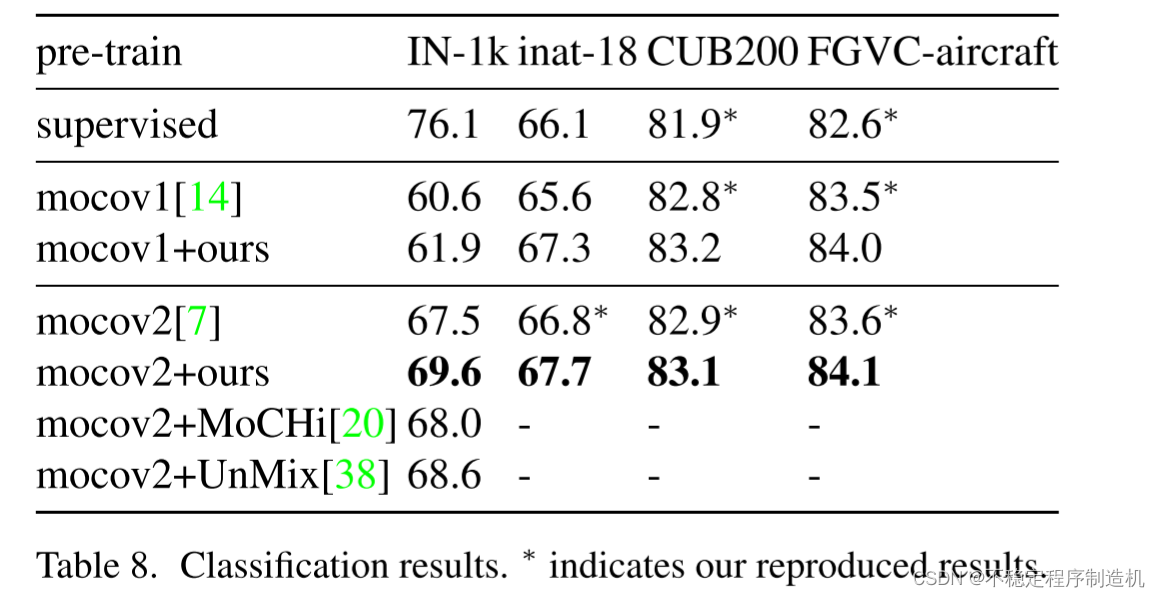
在不同的数据集上,效果也很好;
总结
卖方法的,思路不是很新颖,不过优点很明显:
- 能自圆其说,由Score Distribution的发现引入Feature Transformation的过程很自然。
- 效果很强,同时实现简单;
缺点: - 把Score Distribution作为一款可视化分析工具来说,感觉有点微妙。文中仅以MOCO的三个实验的纵向对比为例,不知道能否在不同的方法中进行横向对比?
顺道一提,本文有附加支撑材料,这个博文中没有涉及,读者有兴趣可以去看看。
参考文献
本文基本均为原创
Over~收工。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









