







“DisCo: Remedy Self-supervised Learning on Lightweight Models with Distilled Contrastive Learning” 本文特点:轻量级模型
摘要:
虽然自监督表示学习(Self-Supervised representation Learning, SSL)受到了社区的广泛关注,但最近的研究认为,当模型规模减小时,其性能会出现断崖式下降。由于目前的SSL方法主要依赖于 对比学习 来训练网络,本文提出了一种简单而有效的方法,称为 蒸馏对比学习(DisCo)来缓解这个问题。具体而言,本文发现 主流SSL方法的 最终内在嵌入包含了最富有成效的信息,并提出 通过 约束学生的最后嵌入 与 教师的最后嵌入一致,提取 最后嵌入 以最大限度地 将教师的知识传递到一个轻量级模型。此外,我们发现存在一种称为 蒸馏瓶颈 的现象,并建议 扩大嵌入维度 来缓解这一问题。由于MLP只存在于SSL阶段,所以我们的方法在下游任务部署期间 不会向轻量级模型引入任何额外参数。实验结果表明,我们的方法在所有轻量级模型上都大大超过了最先进的技术。特别的是,当分别使用ResNet-101/ResNet-50作为老师来教学 EfficientNet-B0时,EfficientNet-B0 在ImageNet上的线性结果 分别提高了22.1%和19.7%,在参数更少的情况下非常接近ResNet-101/ResNet-50。
1.引言
深度学习在计算机视觉任务中取得了巨大的成功,包括图像分类、目标检测和语义分割。这样的成功很大程度上 依赖于人工标记的数据集,而获取这些数据集 既耗时又昂贵。因此,越来越多的研究者开始探索 如何更好地利用现成的未标记数据。其中,自监督学习(Self-supervised Learning, SSL)是 利用代理信号作为监督 来 探索数据本身所包含的信息 的一种有效方法。
通常情况下,通过自监督的方法对网络进行海量未标记数据的预训练,并对下游任务进行微调后,下游任务的性能会得到显著提高。因此,SSL受到了社会的广泛关注,许多方法被提出[26,31,13,33,8,9,20,19],其中 基于对比学习的方法 因其优越的结果而成为主流。这些方法在相对较大的网络中不断刷新SOTA结果,但同时在一些轻量级模型上不能令人满意。例如MobileNet-v3-Large/ResNet-152的参数个数为5.2M/57.4M[25, 22],使用mocov2[10]在ImageNet[36]上对应的线性评价top-1准确率为36.2%/74.1%。与完全监督的同行75.2%/78.57%相比,MobileNet-v3Large的结果远远不能令人满意。同时在实际场景中,由于硬件资源有限,有时只能部署轻量级模型。因此,提高小模型上的自监督表示学习能力具有重要的意义。
知识蒸馏[24]是将 大模型(老师) 学习到的知识转移到 小模型(学生) 的有效方法。近年来,一些自监督表示学习方法利用知识蒸馏来提高小模型的有效性。SimCLR-V2[9]在微调阶段使用logits以任务特定的方式传递知识。CompRess[1]和SEED[18] 在动态维护的队列上 模拟教师和学生模型之间的相似性分数分布。虽然蒸馏是有效的,但有两个因素显著影响结果,即哪些知识是学生最需要的和如何传递它。在这项工作中,我们对这两个方面提出了新的见解。
目前主流的基于对比学习的SSL方法是 在编码器后加入多层感知器(MLP)来获得低维嵌入。训练损失和精度评估 都是在这种嵌入上进行的。因此,我们假设这个最后的嵌入包含了最有成效的知识,应该被视为知识转移的首选。为了实现这一点,本文提出了一个简单而有效的蒸馏对比学习(DisCo)框架,在预训练阶段 将这些知识从大型模型转移到轻量级模型。DisCo将教师获得的MLP嵌入作为知识,利用MSE损失约束学生对应的嵌入与教师的嵌入一致,注入到学生中。此外,本文发现在学生的MLP中隐藏层的预算维度 可能会造成知识蒸馏的瓶颈。本文将这种现象称为“蒸馏瓶颈”,并提出通过 扩大嵌入维度 来缓解这一问题。从信息瓶颈[39]的角度来看,这种简单而有效的操作 与自监督学习设置中的模型泛化能力有关。值得注意的是,b我的方法在预训练阶段只引入了少量的额外参数,但在微调和部署阶段,由于去掉了MLP层,因此没有额外的计算负担。
实验结果表明,DisCo可以有效地将知识从教师传递给学生,使学生提取的表征更加泛化。本文的方法很简单,将其合并到现有的基于对比的SSL方法中可以带来显著的收益。
Contributions:
• 本文提出了一种简单而有效的自监督蒸馏方法,以提高轻量级模型的表示能力;
• 本文发现在自监督蒸馏阶段存在一种称为蒸馏瓶颈的现象,并建议扩大嵌入维度来缓解这一问题;
• 本文在轻量级模型上实现了最先进的SSL结果。其中,EfficientNet-B0[37]在ImageNet上的线性评价结果与ResNet-101/ResNet-50非常接近,而EfficientNet-B0的参数数量仅为ResNet101/ResNet-50的9.4%/16.3%。
2. 相关工作
2.1 自监督学习
自监督学习(Self-supervised learning, SSL)是一个通用框架,它可以从数据本身学习高级语义模式,而不需要从人类那里得到任何标记。目前的方法主要依赖于三种范式,即前置任务范式、基于对比的范式和基于聚类的范式。
前置任务。
基于前置范式的方法侧重于 设计更有效的代理任务,包括识别patches 是否是从同一图像裁剪的 Exampler- CNN[15]、预测 输入图像 旋转度数的Rotatio[26]、将洗牌patches 放回原始位置的Jigsaw [31],和根据周围环境,恢复输入图像的缺失部分的上下文编码器[33]。基于对比的方法在自监督表示学习方面表现出了令人印象深刻的性能,这使得同一输入的不同视图在特征空间中更接近[11、9、8、23、20、10、19、40、41、44]。SimCLR[8,9]表明,可以通过应用 强数据增强、使用更大批量的负样本 进行训练 以及在全局平均池化后添加投影头(MLP)来增强自监督学习。然而,SimCLR 依赖于非常大的批量 来实现相当的性能,无法广泛应用于许多实际场景。MoCo[20,10]将对比学习视为 查找词典,使用 内存库 来保持负样本的一致表示。因此,MoCo可以在没有大批量的情况下实现优异的性能,这更易于实现。BYOL[19]将预测器引入网络的一个分支,以打破对称性并避免平凡解。DINO[6]将对比学习应用于vision transformer。
基于聚类。
聚类是无监督表示学习最有前途的方法之一。DeepCluster[3] 使用 k-means分配来生成伪标签,以迭代地对特征进行分组 并 更新网络的权重。DeeperCluster[4] 扩展到 大型未精细设计的数据集,以捕获 互补的统计数据。与以前的工作不同,为了最大化 伪标签 和 输入数据之间的互信息,SeLa[2]将 伪标签分配 作为 最优传输的一个实例。SwAV[5] 制定了将 表示 映射到 原型向量的公式,原型向量在线分配,能够扩展到更大的数据集。
虽然主流方法SimCLR-V2、MoCoV2、BYOL和SwAV属于不同的自监督类别,但它们有四个共同点:1)一幅图像有两个视图,2)两个编码器用于特征提取,3)两个投影头将表示映射到低维空间,4)两个低维嵌入被视为一对正样本,这可以看作是一个对比过程。然而,所有这些方法在轻量化模型上都会出现性能下降的问题,这正是本文中试图解决的问题。
2.2 知识蒸馏
知识蒸馏(KD)试图 将知识从较大的教师模型 转移到 较小的学生模型。根据知识的形式,它可以分为三类,基于logits的、基于特征的 和 基于关系的。
基于Logits。
Logits 是指网络分类器的输出。KD[24] 提出通过 最小化 类别分布的KL散度,让学生模仿老师的logits。
基于特征的。
基于特征的方法直接将知识 从教师的中间层 传递给学生。FitNets[35] 将教师学习到的 中间表征 视为 hints 提示,并通过 最小化表征之间的均方误差 将知识传递给 更瘦 和 更深的学生。AT[43]提出 将教师的空间注意力 作为知识,让学生关注 教师关注的领域。SemCKD[7]自适应地选择更合适的教师和学生表示对。
基于关系的。
基于关系的方法 探索数据之间的关系,而不是单个实例的输出。RKD[32]将一批输入数据之间的相互关系 以及 距离级 和 角度级 的蒸馏损失从教师传递给学生。IRG[29]建议使用关系图来进一步表达关系知识。
2.3 SSL meets KD
最近,一些工作结合了自监督学习 和 知识蒸馏。CRD[38]引入了一种对比损失,以跨不同模式 传递成对关系。SSKD[42]让学生 模仿 转换的数据和自监督任务,以传递更丰富的知识。上述工作将自监督作为辅助任务,以进一步推动在全监督环境下的知识蒸馏过程。CompRess[1]和SEED[18]试图 将知识提取 作为一种手段来提高 小模型的自监督视觉表示学习能力,该模型利用MoCo[20]中的 负样本队列 来约束正样本在学生负样本上的分布,使其与教师的分布一致。然而,CompRess 和SEED 在很大程度上依赖于MoCo框架,这意味着在蒸馏过程中必须始终保留内存库。我们的方法还旨在通过 蒸馏 提高轻量级模型上的自监督表示学习能力,但是,我们不限制自监督框架,因此更灵活。此外,在相同的设置下,我们的方法在所有轻量级模型上都比SEED有很大的优势。
第三章内容与第二章重复
4. 实验

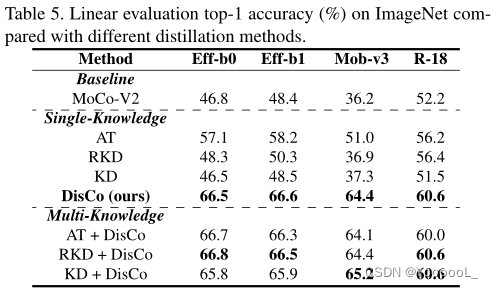
如表1所示,DisCo 蒸馏 的学生模型优于MoCo-V2(基线)预训练的学生模型,具有较大的优势。
此外,当DisCo 使用更大的模型作为老师时,学生将得到进一步的提高。
值得注意的是,当使用ResNet-101/ResNet-50 作为教师时,EfficientNet-B0的线性评估结果非常接近教师,而EfficientNet-B0的参数数量仅为 ResNet-101/ResNet-50的 9.4%/16.3%。
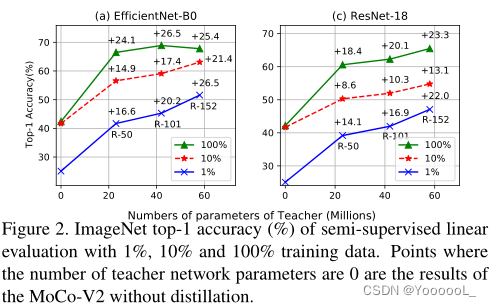
如图2所示,DisCo 蒸馏的学生模型 在任何数量的标记数据下 都优于基线。此外,DisCo还显示了不同注释分段下的一致性,即学生总是受益于较大的教师模型。更多标签将有助于提高学生模型的最终性能,这是意料之中的。
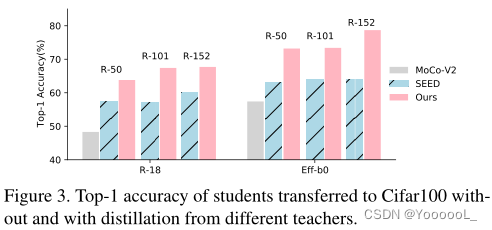
在不同的学生和教师架构下,本文的DisCo超过了MoCo-V2基线。另外,本文的方法与目前最先进的方法SEED相比,也有了明显的改进。值得注意的是,随着教师越好,DisCo带来的改进更加明显。
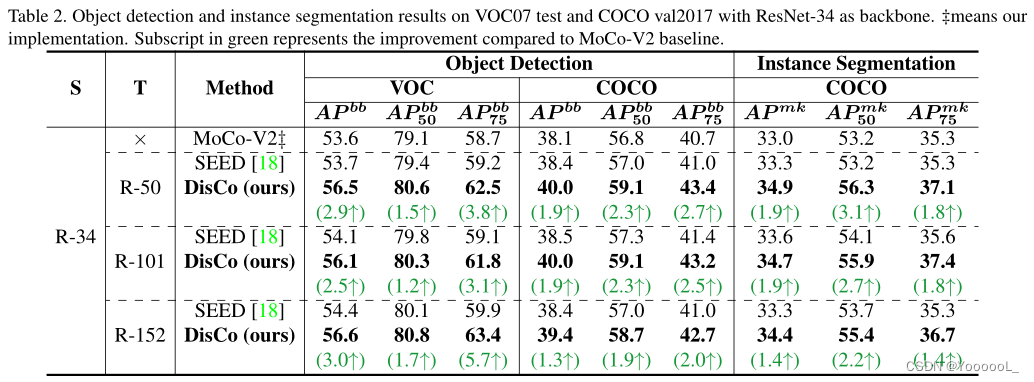
结果如表2所示。在目标检测方面,本文的方法对VOC和COCO数据集都有明显的改进。

本文将学生的MLP中隐藏层的维度进行扩展,使其与老师的一致,即2048D,可以看出结果可以进一步提高,记录在第三行。
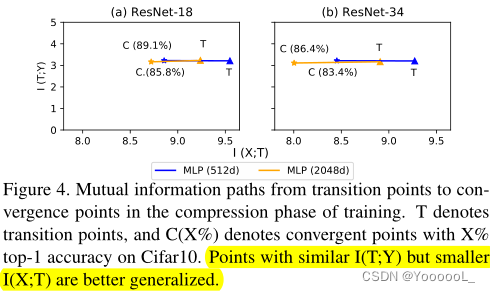
I(X; T ) 值变小,而 I(T ; Y ) 基本不变。 这说明在自监督迁移学习设置下,扩大隐藏维度可以使学生模型更加泛化。
本文验证了DisCo中两个重要模块的有效性,即 蒸馏损失 和 MLP隐藏维的扩展,结果如表4所示。由此可见,蒸馏损失会带来本质的变化,结果会得到很大的改善。即使只有蒸馏损失,也能取得良好的效果。此外,随着隐藏维数的增加,top-1精度也会增加,但当维数已经很大时,增长趋势会放缓。

可以看到,所有的蒸馏方法都可以改善基线,但DisCo的收获是最显著的,这表明DisCo选择传输的知识和传输的方式确实更有效。然后,我们也尝试将DisCo与其他方案相结合,将多元的知识从教师传递给学生。可以看出,将DisCo与T/RKD/KD相结合,可以大大提高性能,这进一步证明了DisCo的有效性。
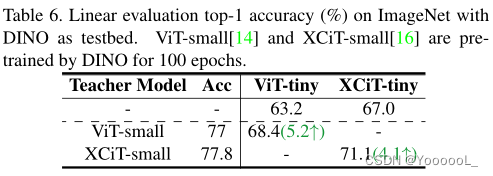
为了演示本文的方法的多功能性,本文进一步实验了两种SSL方法,这两种方法与我们在前面章节中使用的MoCo-V2基线截然不同。i)使用SwAV来证明对学习范式的兼容性,该范式测量的是集群之间的差异,而不是实例之间的差异(参见补充部分3);ii) DINO用于验证对骨干类型的兼容性,其中编码器是视觉转换器,而不是常用的CNN,如表6所示。可以看到DisCo并不局限于特定的SSL方法,并且可以在大多数流行的SSL框架下带来显著的改进。
Conclusion:
在本文中,提出蒸馏对比学习(DisCo)来弥补轻量级模型上的自监督学习。该方法将轻量级学生的最终嵌入约束为与教师的嵌入一致,从而最大限度地传递教师的知识。DisCo并不局限于特定的对比学习方法,它可以很大程度上弥补学生的表现。















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









