







目录
1、如何理解数据库的三范式
a、列不可再分:每个字段值都是不可拆分的原子值。例:省市区分开写更符合原子性
b、属性完全依赖组件:每个字段值都是不可拆分的原子值。例:订单表只存订单相关的数据,订单商品存订单商品表中。

c、属性不依赖于其它非主属性 属性直接依赖于主键
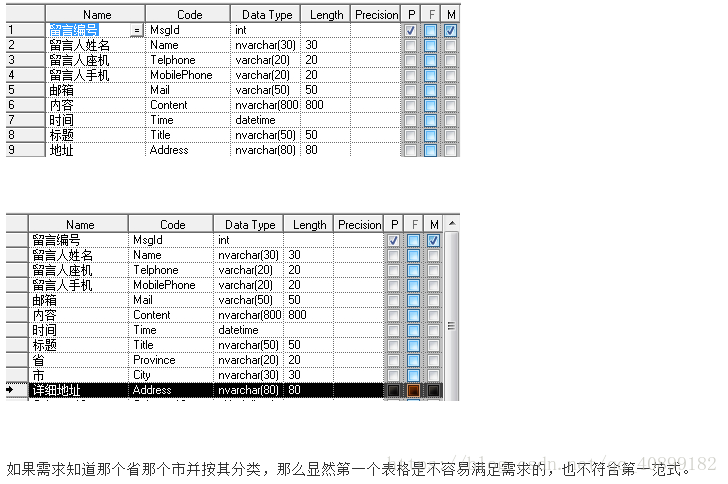
数据不能存在传递关系,即每个属性都跟主键有直接关系而不是间接关系。像:a-->b-->c 属性之间含有这样的关系,是不符合第三范式的。
比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)
这样一个表结构,就存在上述关系。 学号--> 所在院校 --> (院校地址,院校电话)
这样的表结构,我们应该拆开来,如下。
(学号,姓名,年龄,性别,所在院校)--(所在院校,院校地址,院校电话)
2、InnoDB和MyISAM的区别
1、InnoDB是行锁,MyISAM是表锁
2、InnoDB支持事务,MyISAM不支持事务
3、InnoDB默认使用共享表空间,MyISAM不使用共享表空间
4、InnoDB数据和索引存在共享表空间里,MyISAM数据存在MYD文件,索引存在MYI文件
3、char和varchar的区别
1、char定长,varchar可变长度。比如char(10)、varchar(10),同时存储'abcd',char的长度还是10,varchar的长度会变成4。
2、char的存取速度要varchar快的多,因为固定的长度更利于程序存储和查找。以空间换时间
3、数据经常修改,应使用char,避免产生过多的数据碎片
4、MySQL索引
1、索引创建原则。首先要搞清楚索引为什么快,索引类似书的目录,MySQL使用索引时先查索引对应的值,然后根据匹配的索引值查对应的行。
2、索引对性能的影响。索引减少服务器对数据的扫描量,帮助服务器避免排序和创建临时表,将随机IO转化为顺序IO。但降低写的速度,因为写操作需要额外操作索引,另外占用了一定的磁盘空间。
3、索引使用场景。几十条,几百条数据表不建议建索引;中大型,几千到几百万,特别适用索引;特大型,上千万条数据,建议分区,分表操作。
4、索引类型。普通索引;唯一索引,具有唯一性的约束;主键索引,不允许有空值;组合索引,多列组成一个索引,遵循abc原则,索引为abc,a、ab、abc可以用到索引,acb就用不到;外检索引,只有innodb支持,用于实现级联操作。
5、主键索引和唯一索引的区别。主键一定是唯一索引,唯一索引可以不是主键索引;主键只能有一个,唯一索引可以是多个;
6、like查询,%不能在前,会启用索引,可以使用全文检索引擎
7、or前后都要有索引
8、字符串类型的索引 查询时加引号
5、SQL编写
1、关联更新
update set A,B SET A.c1=B.c1,A.c2=B.c2 where A.id=B.id and B.age > 40
或
update A inner join B on A.id=B.id set A.c1=B.c1,A.c2=B.c2 where B.age > 40
2、左连接left join,以左表为主,先查左表,再查左表在右表关联的数据;内连接inner join(支持等连接和不等连接及自连接),右连接right join,以右表为主,先查右表,再查右表在左表关联的数据。
3、union、union all。把多个查询结果集中在一起,联合查询的列数要相等,有重复会合并。union all 不会合并,union all 效率高于 union。
4、多关联查询
表A ,球队表
| id | name |
表B,赛程表
| id | hostid | guestid | time | result |
select t1.name as hostname,m.result,t2.name as guestname,time from match as m left join team as t1 on m.hostid=t1.id left join team t2 on m.guestid=t2.id where time between '2020-06-20' and '2020-06-30'
6、MySQL优化
1、通过慢查询日志记录慢查询sql,使用pt-query-dgist进行分析
2、使用 show profile 。先设置set profiling =1,再使用 show profile for query "查询ID" 查看某条SQL执行时间花费在什么地方了
3、show status 查看查询计数器
4、show processlist 查看是否有大量线程处于不正常长状态
5、explain 查看单条sql的执行时间,可以看到索引使用情况,扫描行数等
6、limit的使用,过大时使用id>1000的条件
7、避免select *
8、count(*) 效率大于 count(列)
9、大量耗时查询可拆分为多条小的sql语句,提升缓存效率,降低锁的竞争
10、大量关联查询,可以使用逆三范式冗余字段来设计表名
11、大量统计数据查询 可以做汇总表 加 缓存
12、关联查询 on 或 using条件上应有索引
13、group by 和 order by 要使用同一表的字段
14、group by 不需要排序时可以加一个 order by null ,避免mysql 文件排序
7、分区分表
1、分区。创建表时使用partition by子句定义每个分区存放的数据,执行查询时,优化器会根据分区定义过滤没有需要的数据的分区。如果是已有表,需要加partition_id字段。5.1版本中,分区表表达式必须是整数,5.5版本可以使用列分区。分区字段中如果有主键或唯一索引列,主键列和唯一列都必须包含进来。分区表中无法使用外键索引。
2、分表。水平分,垂直分。通过hash算法达到查不同的分表数据。
3、主从复制原理。在主库上把数据源更改记录到二进制日志,从库将主库的日志复制到自己的中继日志,从库读取中继日志中的事件,将其重放到从库数据中。
例:千万用户,活跃用户只有1%,如何提升网站效率。①可使用分区,将活跃和非活跃用户分成两个区,根据查询条件判断查哪个区的数据。②水平分表,将活跃和非活跃用户分成两个分表,根据查询条件判断查哪个分表的数据。
8、MySQL安全性
1、防sql注入,使用mysql预处理
2、特殊字符过滤
3、不要暴露SQL语句
4、定期做数据备份
5、关闭远程访问数据库的权限















 483
483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









