






前言
当今科技领域的发展日新月异,向量数据库成为了热门的话题之一。
这些数据库以其高效的向量检索和相似度搜索功能,为各种应用场景提供了强大的支持。
本文旨在汇总向量数据库
Milvus、Zilliz、Faiss、Qdrant、LlamaIndex、Chroma、LanceDB、Pinecone、Weaviate、
基本介绍
1. Milvus
Milvus是一个开源的向量相似度搜索引擎,由Zilliz团队开发。它提供了高性能的向量检索和相似度搜索功能,支持海量数据的快速查询。Milvus支持多种向量类型和距离度量方法,并提供了易于使用的API和丰富的功能,使得开发者可以轻松构建各种应用,如图像搜索、推荐系统和自然语言处理。
2. Zilliz:
Zilliz是一家专注于大规模向量数据分析的公司,他们开发了多个与向量相关的开源项目,其中包括Milvus和Chroma。Zilliz致力于提供高效的向量数据处理和分析解决方案,帮助用户在海量数据中进行快速的相似度搜索和数据分析。
3. Faiss:
Faiss是Facebook AI Research开发的一个高性能向量相似度搜索库。它支持多种向量索引结构和距离度量方法,并提供了高效的搜索算法,能够在大规模数据集上进行快速的相似度搜索。Faiss被广泛应用于图像识别、语音识别和自然语言处理等领域。
4. Qdrant:
Qdrant是一个开源的向量搜索引擎,由Qdrant团队开发。它提供了高性能的向量检索和相似度搜索功能,支持多种向量类型和距离度量方法。Qdrant还提供了丰富的查询语法和灵活的配置选项,使得用户可以根据自己的需求进行定制化的搜索。
Qdrant 因其易用性和用户友好的开发者文档,面世不久即获得关注。
Qdrant 以 Rust 语言构建,提供 Rust、Python、Golang 等客户端 API,能够满足当今主流开发人员的需求。
不过, Qdrant 作为后起之秀,和其他竞品仍然存在一定差距,例如界面及查询功能不够完善。
5. LlamaIndex:
LlamaIndex是一个基于向量的数据库引擎,由Llama Labs开发。它提供了高效的向量存储和检索功能,支持多种向量类型和距离度量方法。LlamaIndex还提供了易于使用的API和丰富的功能,使得开发者可以快速构建各种应用,如推荐系统、广告投放和智能搜索。
6. Chroma:
Chroma是Zilliz团队开发的一个开源的向量数据管理系统。它提供了高效的向量存储和查询功能,支持多种向量类型和距离度量方法。Chroma还提供了可扩展的架构和分布式计算能力,能够处理大规模的向量数据集。

Qdrant Cloud VS Zilliz Cloud
–这两个都是云服务,不同点在于
Qdrant 更适合追求低成本基础设施维护的开发人员。
而如果应用系统更注重性能和可扩展性,Zilliz Cloud/Milvus 是更合适的选择。因为 Zilliz Cloud/Milvus 具备可扩展性极强、性能更佳、延时更低的特点,适用于对性能指标有着严格要求的场景。
每秒查询次数(QPS)
测试结果显示,在 10,000,000 条 768 维的向量数据中进行检索时,Zilliz Cloud 两款实例的 QPS 分别是 Qdrant Cloud 实例的 7 倍和 1 倍。

具体见参考资料
Qdrant 用法
架构
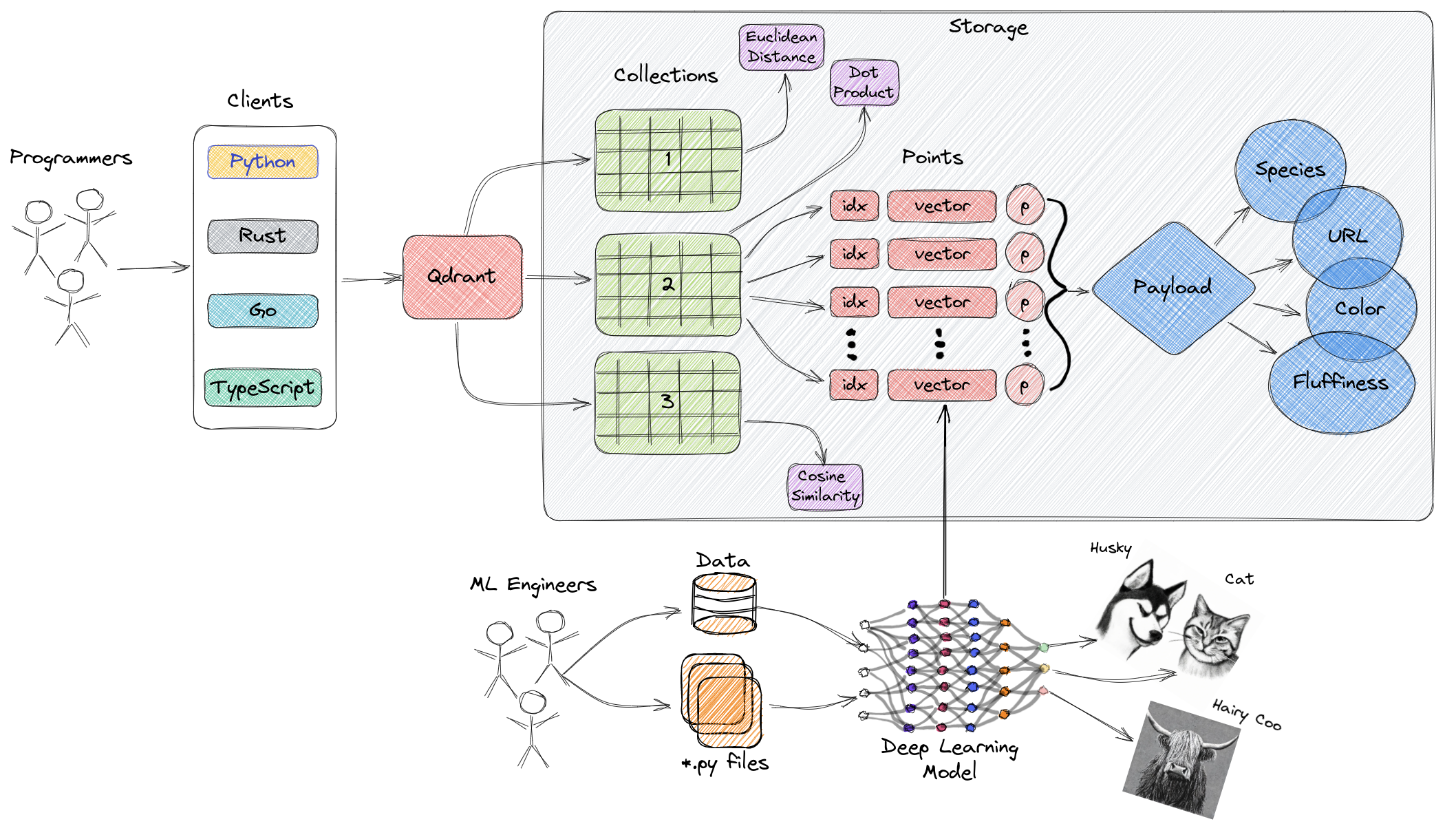
同其他数据库一样,支持本地和服务器部署
docker 部署
提取预构建的 Docker 映像并运行容器:
docker pull qdrant/qdrant
docker run -d -p 7541:6333 --ip=10.0.180.16 qdrant/qdrant # 7541对外,6333是容器端口,必须是6333或者6334
-d 后台启动服务后
Access web UI at http://localhost:6333/dashboard
2023-12-06T04:43:43.136073Z INFO storage::content\_manager::consensus::persistent: Initializing new raft state at ./storage/raft\_state.json
2023-12-06T04:43:43.552838Z INFO qdrant: Distributed mode disabled
2023-12-06T04:43:43.552926Z INFO qdrant: Telemetry reporting enabled, id: 9fcc223f-6fbe-4932-8a31-4663683e1baf
2023-12-06T04:43:43.564727Z INFO qdrant::tonic: **Qdrant gRPC listening on 6334**
2023-12-06T04:43:43.564772Z INFO qdrant::tonic: TLS disabled for gRPC API
2023-12-06T04:43:43.565817Z INFO qdrant::actix: TLS disabled for REST API
2023-12-06T04:43:43.565952Z INFO qdrant::actix: **Qdrant HTTP listening on 6333 **
2023-12-06T04:43:43.565991Z INFO actix\_server::builder: Starting 95 workers
即可访问 http://10.0.180.16:7541/dashboard
安装包
pip install qdrant-client pymilvus
langchain demo
包括 本地 和 url 用法,下面的代码是将 文本 转换成向量 并存储到数据库
from langchain.vectorstores import Qdrant
from langchain.schema import Document
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
docs \= \[Document(page\_content=u'avc')\]
embeddings \= HuggingFaceEmbeddings(
model\_name\=r"F:\\weights\\text2vec-base-chinese")
# qdrant = Qdrant.from\_documents(
# docs,
# embeddings,
# location=":memory:", # 这个可以 Local mode with in-memory storage only
# # path="emb\_qdrant\_pickle2", # 不行
# collection\_name="my\_documents",
# )
qdrant \= Qdrant.from\_documents(
docs,
embeddings,
url\='10.0.180.16:7541',
prefer\_grpc\=False, # 上面起服务用 6333,这里就需要False
collection\_name\="my\_documents", # 这个随便
)
print(qdrant.similarity\_search('a'))
读取已存储的数据
from langchain.vectorstores import Qdrant
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import qdrant\_client
embeddings \= HuggingFaceEmbeddings(model\_name=r"F:\\weights\\text2vec-large-chinese")
client \= qdrant\_client.QdrantClient(
url\='10.0.180.16:7541', prefer\_grpc=False
)
qdrant \= Qdrant(
client\=client, collection\_name="my\_documents",
# embedding\_function=embeddings.embed\_query, # 这里报过错,可查看源码
embeddings=embeddings
)
found\_docs \= qdrant.similarity\_search('员工绩效管理模式有哪些')
print(found\_docs)
加上 filter 过滤
embeddings = OpenAIEmbeddings(deployment="text-embedding-ada-002")
client \= qdrant\_client.QdrantClient(
url\='10.0.180.x6:7541', prefer\_grpc=False
)
question \= 'Idarat Al Mukhabarat Al Jawiyya'
vector \= embeddings.embed\_query(question)
search\_result \= client.search(
collection\_name\="company3",
query\_vector\=vector,
query\_filter\=Filter(
must\=\[FieldCondition(key="metadata.language", match=MatchValue(value="id"))\]
),
with\_payload\=True,
limit\=3,
)
print(search\_result)
View Code
纯 python 代码


from qdrant\_client.http.models import PointStruct
from langchain.vectorstores import Qdrant
import qdrant\_client
from qdrant\_client.http.models import Distance, VectorParams
from qdrant\_client.http.models import Filter, FieldCondition, MatchValue
client \= qdrant\_client.QdrantClient(
url\='10.0.180.16:7541', prefer\_grpc=False
)
#\## 创建collection
client.create\_collection(
collection\_name\="test\_collection",
vectors\_config\=VectorParams(size=4, distance=Distance.DOT),
)
#\## 写入
operation\_info = client.upsert(
collection\_name\="test\_collection",
wait\=True,
points\=\[
PointStruct(id\=1, vector=\[0.05, 0.61, 0.76, 0.74\],
payload\={"page\_content": "Berlin", "metadata":{"language": "ru", "recodeid": 523622}}),
PointStruct(id\=2, vector=\[0.19, 0.81, 0.75, 0.11\],
payload\={"page\_content": "London", "metadata":{"language": "xx", "recodeid": 523622}}),
\],
)
#\## 带条件查询
search\_result = client.search(
collection\_name\="test\_collection",
query\_vector\=\[0.2, 0.1, 0.9, 0.7\],
query\_filter\=Filter(
must\=\[FieldCondition(key="metadata.language", match=MatchValue(value="xx"))\]
),
with\_payload\=True,
limit\=3,
)
print(search\_result)
FAISS 用法
Faiss是一个高效地稠密向量相似检索和聚类的工具包,
由Facebook开发,由C++编写,并且提供了python2和python3的封装。
安装
pip install faiss-cpu
pip install faiss\-gpu
用法
- xb 对于数据库,它包含所有必须编入索引的向量,并且我们将搜索它。它的大小是nb-by-d
- xq对于查询向量,我们需要找到最近的邻居。它的大小是nq-by-d。如果我们只有一个查询向量,则nq = 1
import numpy as np
d \= 3 # dimension
nb = 5 # database size 从多少个里面找最近的
nq = 2 # nb of queries 有多少个被查找的
xb \= np.array(\[\[1, 1, 1\], \[1.2, 1.3, 1.2\], \[3, 3, 3\], \[5, 5, 5\], \[5.2, 5.3, 5.2\]\]).astype('float32')
# xb\[:, 0\] += np.arange(nb) / 1000.
xq = np.array(\[\[1.1, 1, 1\], \[5.2, 5.2, 5.2\]\]).astype('float32')
# xq\[:, 0\] += np.arange(nq) / 1000.
import faiss # make faiss available
index = faiss.IndexFlatL2(d) # build the index
print(index.is\_trained)
index.add(xb) # add vectors to the index
print(index.ntotal)
k \= 4 # we want to see 4 nearest neighbors
D, I = index.search(xb\[:5\], k) # sanity check
print(I)
# \[\[0 1 2 3\] 第一行代表 和 xb\[0\]即\[1.1, 1, 1\] 最近的 4个元素,由近及远
# \[1 0 2 3\] 第二行代表 和 xb\[1\]即\[1.2, 1.3, 1.2\] 最近的 4个元素,由近及远
# \[2 1 0 3\]
# \[3 4 2 1\]
# \[4 3 2 1\]\]
print(D)
# \[\[ 0. 0.17000002 12. 48. \] 对应上面的实际距离
# \[ 0. 0.17000002 9.37 42.57 \]
# \[ 0. 9.37 12. 12. \]
# \[ 0. 0.16999996 12. 42.57 \]
# \[ 0. 0.16999996 14.969999 47.999996 \]\]
D, I \= index.search(xq, k) # actual search
print(I\[:5\]) # neighbors of the 5 first queries
print(I\[-5:\])
Chroma 用法
非 langchain 用法
import chromadb
# 获取Chroma Client对象
chroma\_client = chromadb.Client()
# 创建Chroma数据集
collection =
chroma\_client.create\_collection(name\="my\_collection")
# 添加数据
collection.add(
documents\=\["This is an apple", "This is a banana"\],
metadatas\=\[{"source": "my\_source"}, {"source":
"my\_source"}\],
ids\=\["id1", "id2"\]
)
# 查询数据
results = collection.query(
query\_texts\=\["This is a query document"\],
n\_results\=2
)
results
langchain 统一用法
暂未验证
#\## 创建VectorStore对象
# 通过HuggingFace创建embedding\_function
embeddings = HuggingFaceEmbeddings(model\_name=model)
# 创建VectorStore的具体实现类Chroma对象,并指定collection\_name和持久化目录
vector = Chroma(collection\_name = 'cname', embedding\_function=embeddings,persist\_directory='/vs')
# 先将文本拆分并转化为doc
loader = TextLoader(url,autodetect\_encoding = True)
docs \= loader.load()
text\_splitter \= RecursiveCharacterTextSplitter(chunk\_size=1000, chunk\_overlap=200)
splits \= text\_splitter.split\_documents(docs)
# 插入向量数据库
vector.add\_documents(documents=splits)
###
# 删除id为1的doc对象
vector.delete('1')
###
# 根据file\_id的条件,查询到所有符合的doc对象的id
reuslt = vector.get(where={"file\_id":file\_id})
# 使用delete方法,批量删除这些id对应的doc对象
if reuslt\['ids'\] :
vector.delete(reuslt\['ids'\])
###
# 删除id为2的doc对象
vector.delete('2')
# 插入新的doc对象
vector.add\_documents(new\_doc)
###
# 查询与“语义检索”最相似的doc对象
docs = vector.similarity\_search("语义检索")
# 打印查询结果
for doc in docs:
print(doc)
# 查询与“语义检索”最相似的doc对象,并返回分数
docs\_with\_score = vector.similarity\_search\_with\_score("语义检索")
# 打印查询结果和分数
for doc\_with\_score in docs\_with\_score:
print(doc\_with\_score\[0\], doc\_with\_score\[1\])
#\##
# 查询与“LangChain”相关的但不相似的doc对象
docs = vector.max\_marginal\_relevance\_search("LangChain")
# 打印查询结果
for doc in docs:
print(doc)
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









