






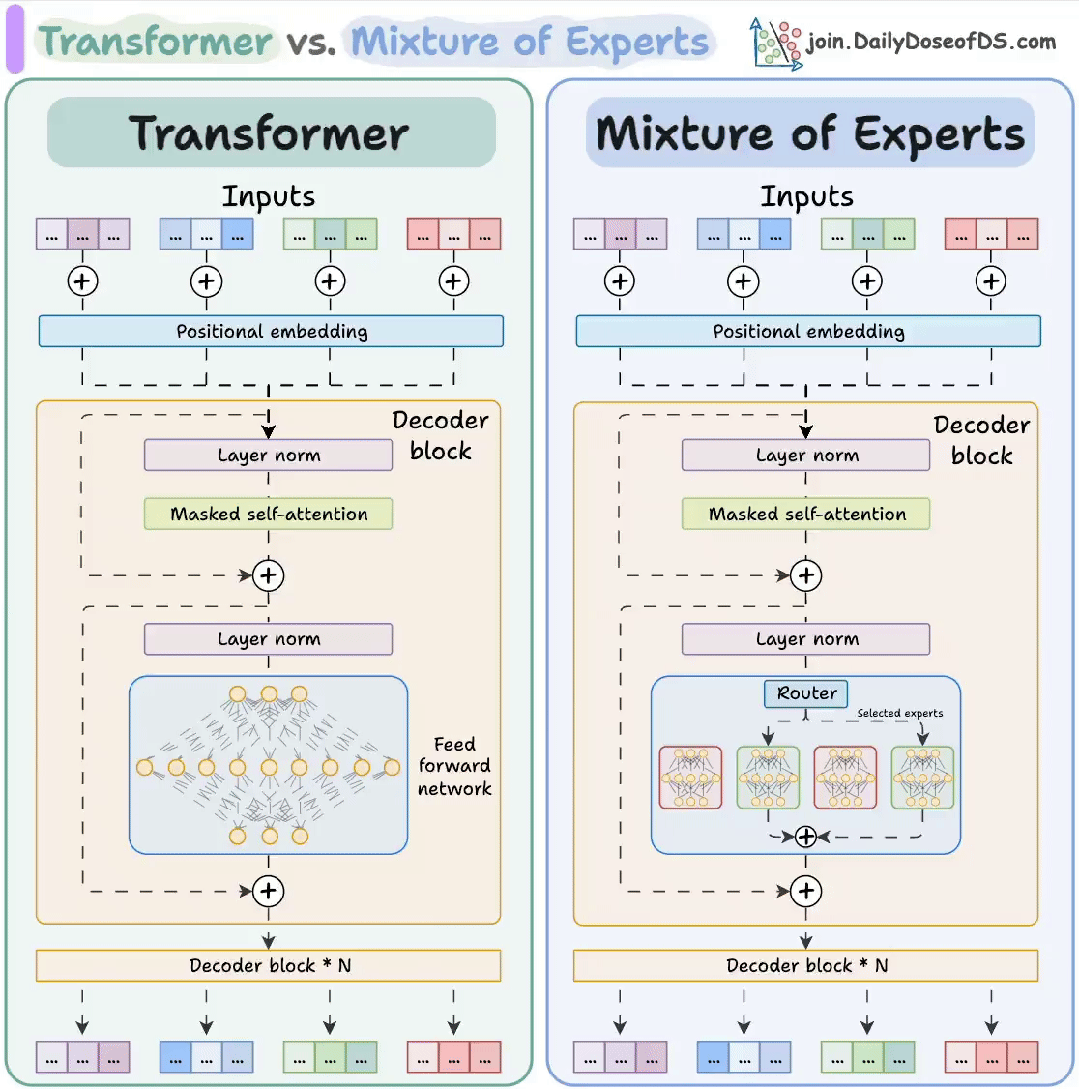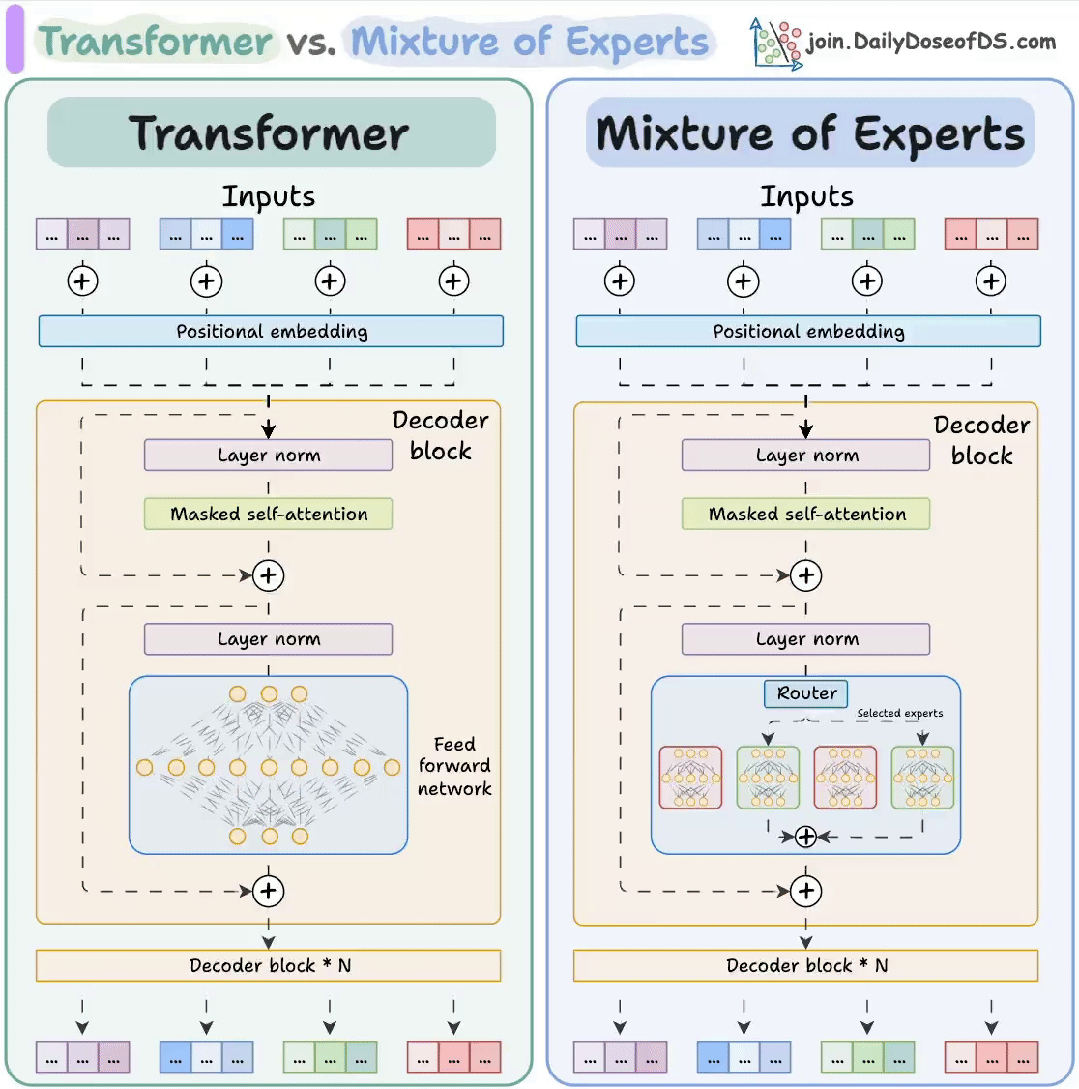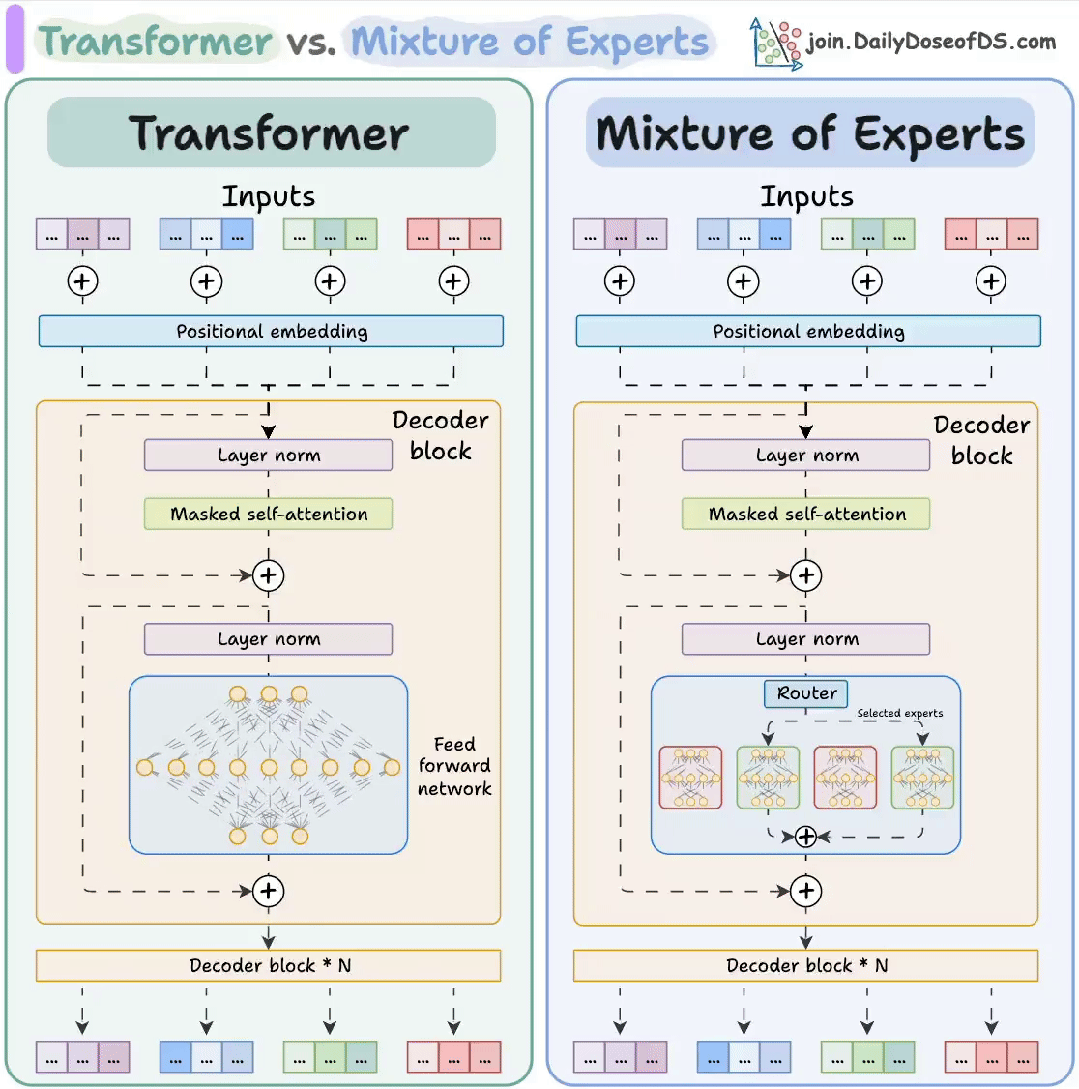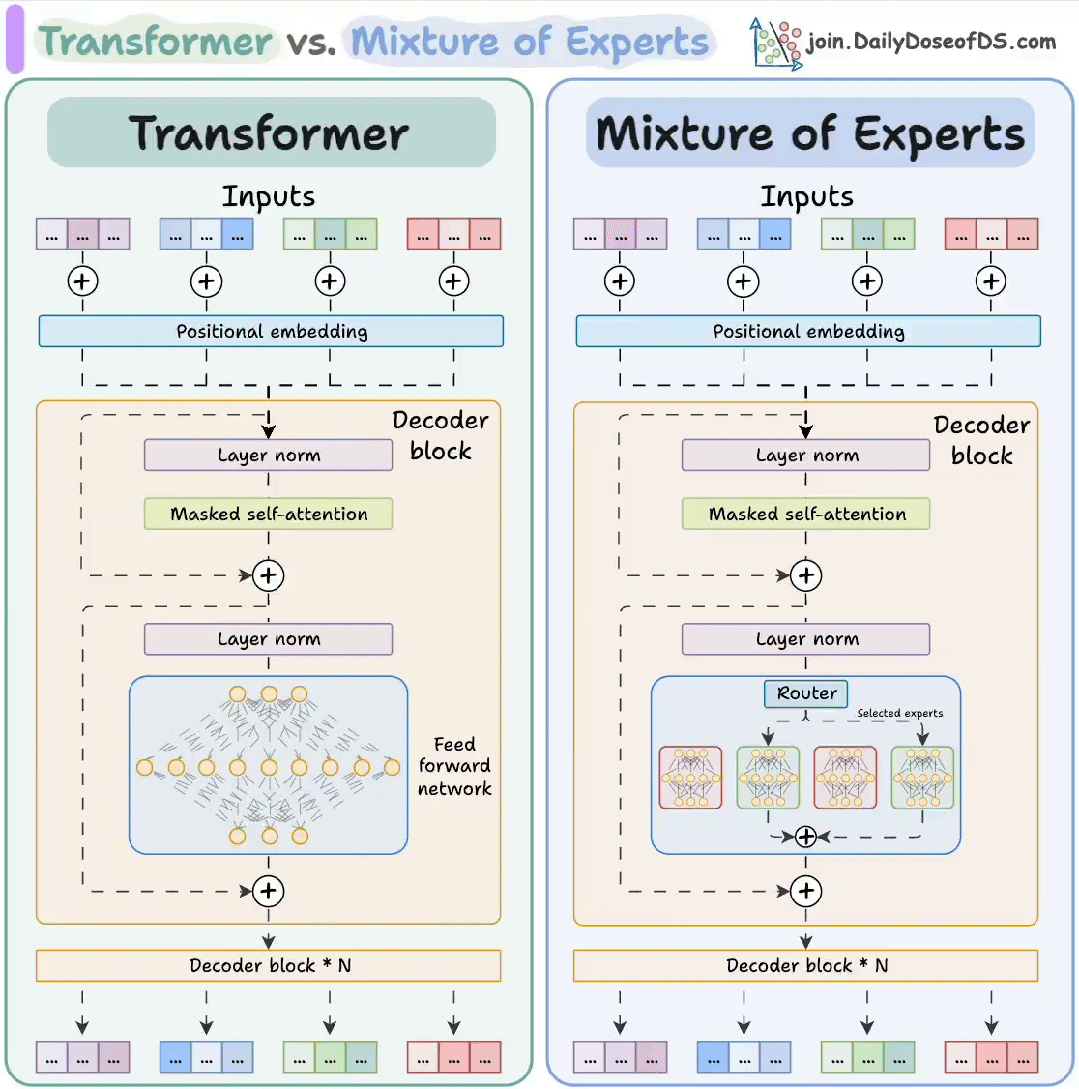
01. Transformer:像“万能翻译官”的神经网络
Transformer 是当今AI大模型(如ChatGPT)的核心架构,最初用于机器翻译,核心是自注意力机制(Self-Attention),能同时分析句子中所有词的关系,而非像传统RNN那样逐词处理。
核心特点:
- 并行计算:同时处理所有词,速度快。
- 长距离依赖:轻松捕捉句子开头和结尾的关联(比如“猫”和“它”)。
- 编码器-解码器结构:编码器理解输入(如英文),解码器生成输出(如中文)
举个栗子: 假设你要翻译“The cat sat on the mat”(猫坐在垫子上),Transformer 会让每个词“投票”决定其他词的重要性,比如“猫”和“垫子”关联性高,最终合成正确翻译。
02. MoE(混合专家):像“专家会诊”的智能系统
MoE(Mixture of Experts)是Transformer的升级版,通过动态激活不同专家来节省算力。比如Grok-3、Mixtral 8x7B都采用此架构。
核心特点:
- 专家网络:多个小模型(专家)各司其职(如语法专家、数学专家)。
- 门控路由:根据输入内容选择激活1-2个专家,其他“休眠”。
- 稀疏计算:仅用部分参数,推理速度比传统Transformer快30%
举个栗子: 假设 MoE 模型要回答“如何做红烧肉?”:MoE 只调用“烹饪专家”和“中文处理专家”,忽略“数学专家”,省电又高效!
03. 对比总结
特性
| 特性 | Transformer | MoE |
|---|---|---|
| 工作原理 | 所有参数全程参与计算 | 动态激活少数专家 |
| 计算效率 | 高并行但算力消耗大 | 稀疏激活,更省资源 |
| 适用场景 | 通用任务(如GPT-3) 垂直领域/多任务(如Grok-3) | 通用任务(如GPT-3) 垂直领域/多任务(如Grok-3) |
| 代表模型 | BERT、GPT系列 | Mixtral 8x7B、DeepSeek-MoE |
简单记忆:
- Transformer = 全能学霸,所有问题都自己解决。
- MoE = 专家团队,按需呼叫医生、律师等专业人士。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









