






前言
这个问题在使用大模型写SQL时经常遇到,我之前做过电商数据分析,有很多SQL取数和SQL清洗的应用场景,比如针对某次电商促销活动进行复盘分析,需要得出“每一个品类在618促销期间的订单转化率”。
随便使用一个大模型,比如使用DeepSeek V3模型,在输入框中输入下面的提示词:
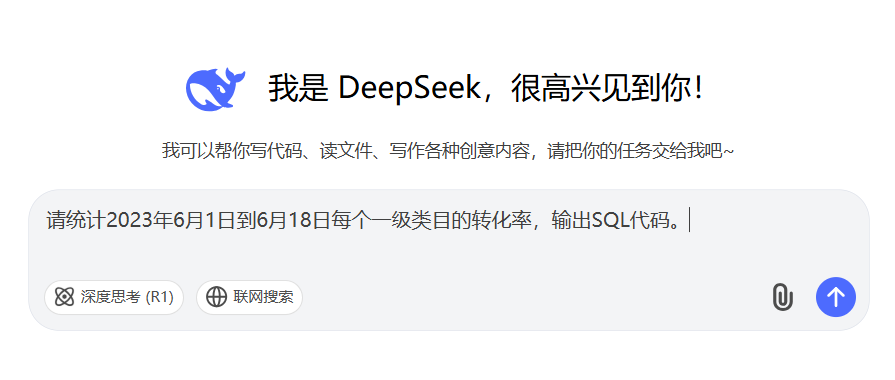
请统计2023年6月1日到6月18日每个一级类目的转化率,输出SQL代码。
大模型很快就给出了SQL代码。
SELECT category, COUNT(order_id)/COUNT(user_id) AS conversion_rate_2023FROM ordersWHERE order_date BETWEEN '2023-06-01' AND '2023-06-18'GROUP BY category;
第一印象感觉是没有问题的,而且,在SQL环境下运行也是没有问题的,没有产生代码报错,但实际上这里出现了典型的AI幻觉问题。因为指代不清楚,这里的user_id是订单表中的“下单客户”,而不是“所有访问客户”,分母指代错误,导致转化率错误,而真正的分母应该是从行为日志中获取的“访问用户数”。
在电商的数据维表中,用户交易数据和用户行为数据是相互独立的,分为两个不同的维表,要计算转化率数据,实际上我们需要将用户交易数据和用户行为数据先关联起来,然后做数值运算,这样才能得到正确的结果。
SELECT pv.category, COUNT(DISTINCT o.user_id) AS buyers, COUNT(DISTINCT pv.user_id) AS visitors, ROUND(COUNT(DISTINCT o.user_id) * 1.0 / COUNT(DISTINCT pv.user_id), 4) AS conversion_rate_2023FROM page_views pvLEFT JOIN orders o ON pv.user_id = o.user_id AND pv.category = o.category AND o.order_date BETWEEN '2023-06-01' AND '2023-06-18'WHERE pv.event_time BETWEEN '2023-06-01' AND '2023-06-18'GROUP BY pv.categoryORDER BY conversion_rate_2023 DESC;
上面是一个AI出现幻觉写SQL的常见场景,也反映出大模型在理解业务上更像是一个新手,不具备深入地理解业务的能力,这就导致生成的SQL代码存在问题,我们知道要写出完美的SQL语句,必须要具备深厚的业务知识。
只有系统地学习大模型,才能充分理解与大模型的对话技巧,所以,在你跟大模型对话时,务必要告诉大模型一些必要的业务知识,相当于老带新一样,手把手教他业务上的知识,你可以告诉他(大模型):
-
公司电商转化率是如何定义的?
-
计算转化率需要哪些维表?
-
各个维表中的字段含义是什么?
-
各维表中的数据是如何埋点取到的?
-
每一个字段背后隐藏着哪些业务?
只有通过这样的训练,你才能让一个新手逐渐转变为职场老手,确切地说“大模型≠人”,需要人不断地干涉和引导,明白了这些道理,那么,在接下来如何应对AI幻觉时,我们可以采取下面几个方法来避免AI幻觉。
1.Prompt时明确数据Schema和业务规则
大模型出现幻觉,在很大一程度上是对于数据的过度推理和臆想,所以,在设计提示词时需要明确表字段和表之间的关系,比如输入下面的提示词,明确数据信息,这样可以避免大模型过度推理,导致AI幻觉。
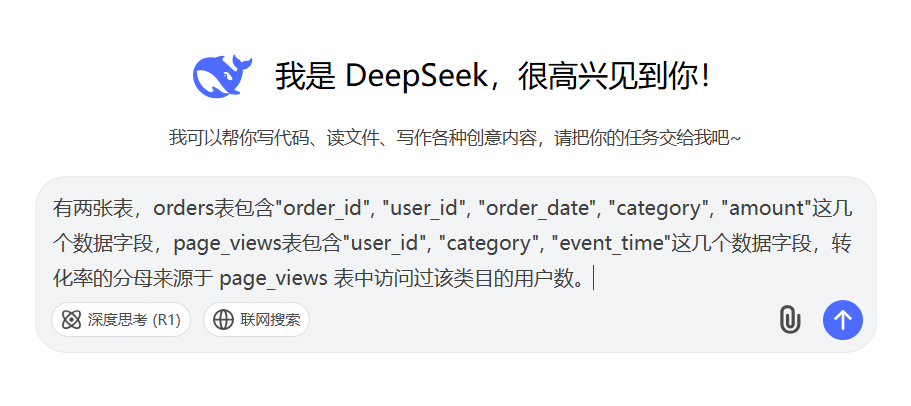
有两张表,orders表包含"order_id", “user_id”, “order_date”, “category”, “amount"这几个数据字段,page_views表包含"user_id”, “category”, "event_time"这几个数据字段,转化率的分母来源于 page_views 表中访问过该类目的用户数。
2.先问大模型思路,再写SQL代码
现在各个大模型都有深度思考的能力,查看大模型思考的过程也是在校验大模型是否思考的准确,打开大模型深度思考开关,详细看大模型的思考过程,用自己的业务知识判断大模型的思考过程是否正确,输入下面的提示词:
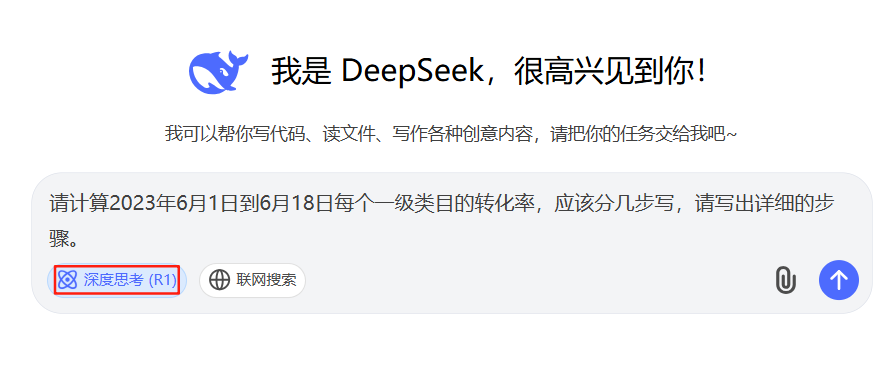
请计算2023年6月1日到6月18日每个一级类目的转化率,应该分几步写,请写出详细的步骤。
3.反向校验,让模型自主推理
我们知道,现在大模型都有很强的推理能力,得到结果的时候,我们可以试图让它由结果反推回去,这样的好处是可以让大模型自己进行深度思考,论证一下结果的可行性,可以输入下面的提示词:
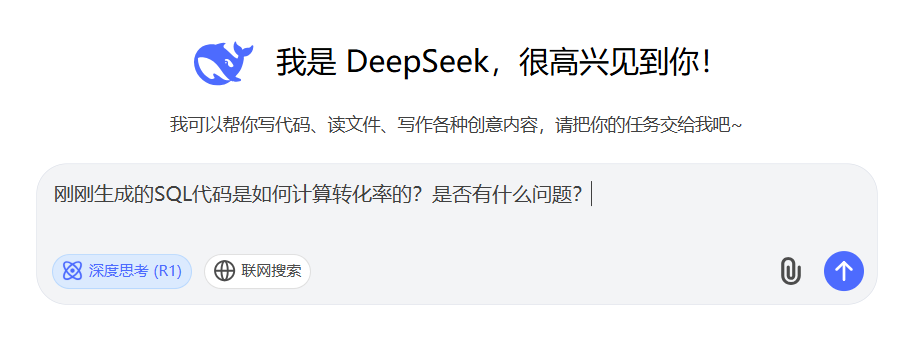
刚刚生成的SQL代码是如何计算转化率的?是否有什么问题?
4.小样本数据验证结果是否合理
在SQL实际应用中,我们都会事先选择一个小的样本去测试SQL代码的可读性和正确性,现在很多公司的数据平台在SQL运行时都会耗费大量的算力,倘若开始的代码就是错误,这样不仅会浪费很多算力,同时,SQL代码清洗结果的错误有时候也是灾难性的,造成严重的数据损失,所以,建议用小样本数据先行测试。
5.持续对话训练,错误结果反馈修正
还有一种防止AI出现幻觉的方法,就是当AI出现幻觉的时候及时与大模型交互,反馈该错误,将该错误标记出来,那么大模型可以根据上下文来推理和思考,在下一次遇到类似的错误时就可以避免。
6. 多轮提示+角色扮演提示词
其实,还有一种方式是设定SQL角色,让大模型代入角色比直接提问,回答的结果更加精确,比如让SQL代入一个资深的数据分析师的角色,基于深厚的业务和技术背景,同时给予提示词更多的规则指导,比如输入下面的提示词:
你是一名资深的SQL数据分析师,现有两个数据的维表如下,请你计算2023年6月1日到6月18日每个一级类目的转化率,写出详细的分析步骤,并附带SQL代码。
以上几个调试方法可以帮助你避免在使用大模型做数据分析时出现幻觉,记住大模型≠人,所以少不了人的干预和调试,试图通过大模型直接生成SQL是不可取的,需要必要的人为干预。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









