






Statistical Learning
why estimate f
- 用来预测
预测的时候可以将 f̂ 当成一个black box来用,目的主要是预测对应x时候的y而不关系它们之间的关系。 - 用来推断
推断的时候, f̂ 不能是一个black box,因为我们想知道predictor和response之间的关系,用来做特征提取,关系分析等。
根据目的是预测还是推断或者两者结合选择不同的模型,需要做一下trade off。
how estimate f
- 参数方法
它将确定了f的形式,将估计p维的f函数降为了对一些参数的估计
先构建参数表达式,然后用参数表达式去训练数据,例如linear regression。
优点是模型和计算简单,缺点是预先确定了f的形式,可能会和真实的f相差较大。 - 非参数方法
对f的形式并未做假设,它要求得到的结果与训练集越接近越好,但是保证模型不要太过复杂。
优点是适用于更多的f,能够得到更高的正确率,缺点是因为是无参数估计,所以需要的数据量是很大的。
模型精度和解释的权衡
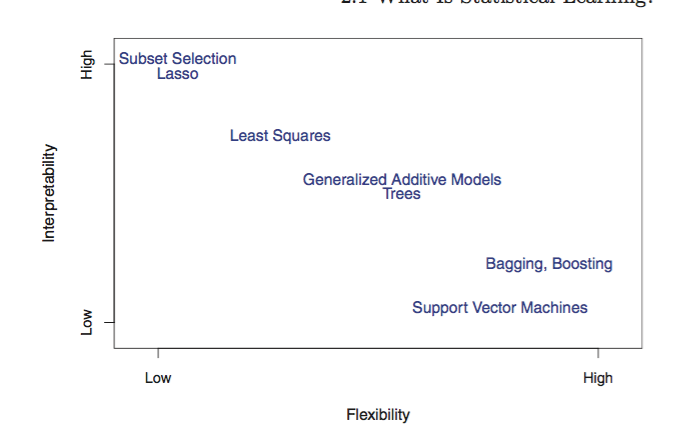
模型越复杂,对于模型的可解释度越小。
如果需要对模型进行高精度预测的话,比如股票市场,可以采用更flexible的方法。
然而,在股票市场,高精度的方法有时候效果更差,原因是对训练数据产生了过拟合。
监督和非监督学习
注意有 SEMI-SUPERVISED LEARNING的问题
分类和回归问题
注意很多机器学习的方法,既可以应用到回归问题,也可以应用到分类问题。只要qualitative的对象被合适地编码。
Assessing model Accuracy
Measuring quality of fit
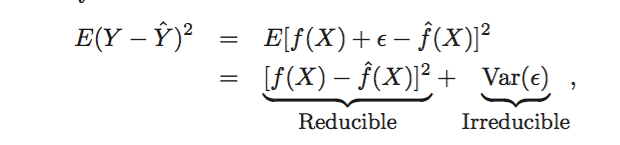
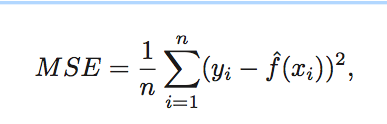
模型更flexibility,degrees of freedom越大。
具体来说,更flexibility,意味着vc维更大,可以shatter的点更多,所以effective points更多, degrees of freedom更大也就是问题的规模更大,模型的选择更多。
模型的选择更多(Hsets更大),这样可以选出训练集MSE最小的点,但是因为VC维的增大,且数据量的有限(VC bound的标准),并不可以保证测试集和训练集的MSE很接近,因此会造成测试集MSE很大,造成过拟合的现象。
解决这个问题,一般采用cross-validation,将训练集的一部分用作测试集,以此来估计
Eout
,避免过拟合现象。
bias-variance trade-off

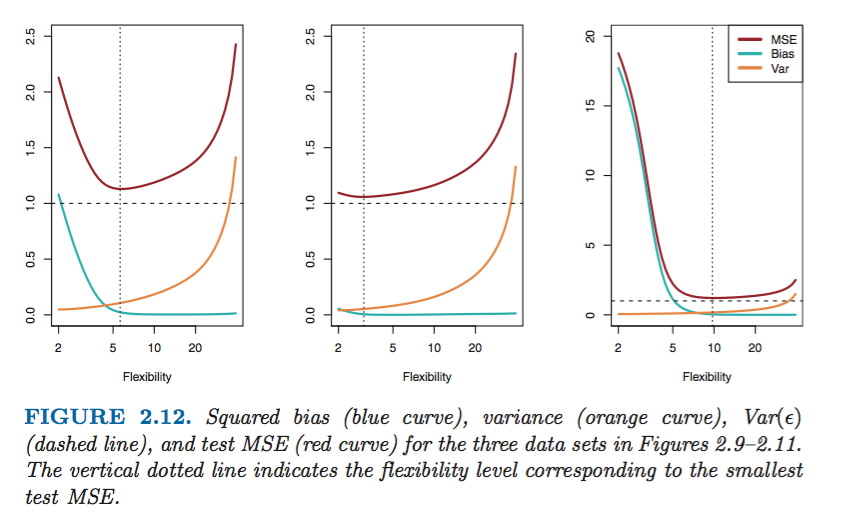
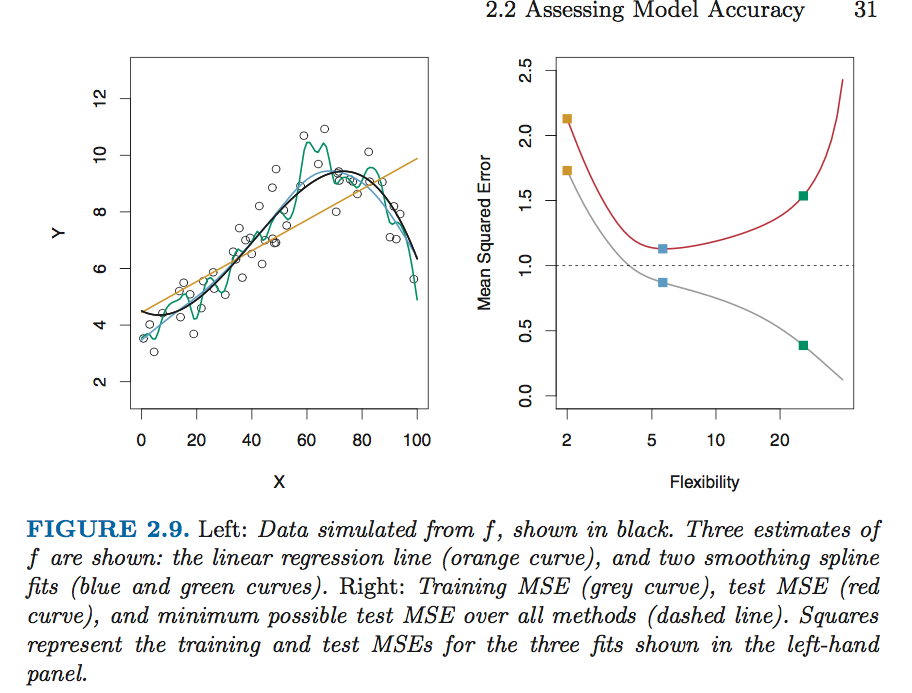
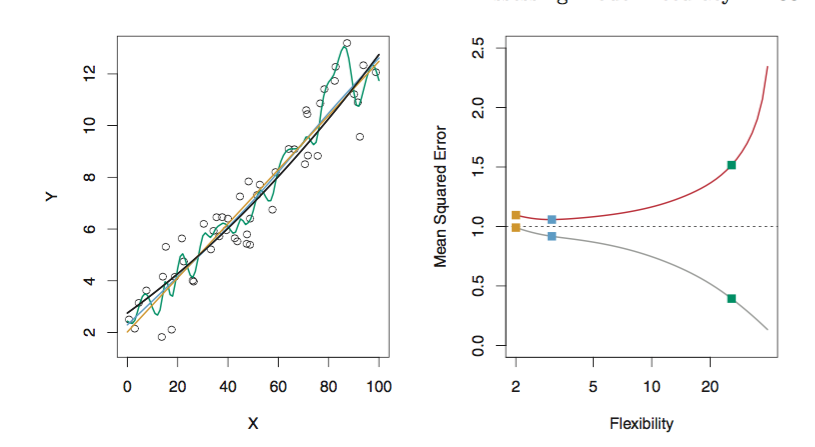
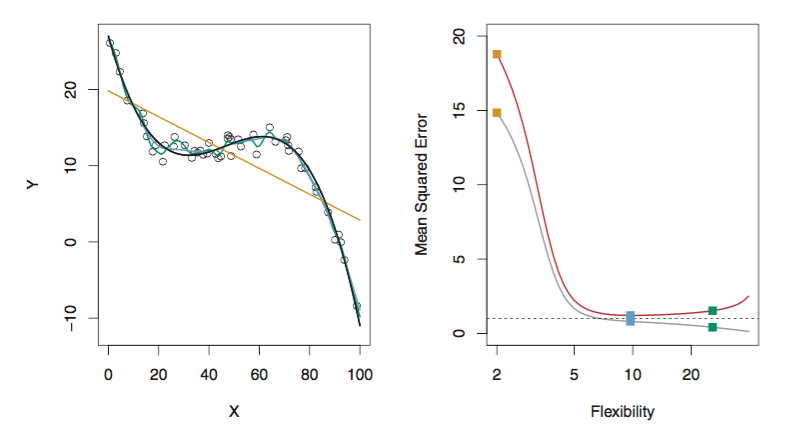
一般来说,测试集的MSE会出现U shape。
U shape,是两种因素共同作用的结果:
1. bias和variance
2. vc维增大后的
Ein≈0
和
Ein≈Eout
MSE有一个最小值, Var(ϵ) 。
variance refers to the amount by which f̂ would change if we estimated it using a different traing data set.
不同的训练集预测出来的 f 相差的多少叫做variance,训练集中一个数据的小改变造成f̂ 变化很大,那么这个模型的variance就很大。bias refers to the error that is introduced by approximating a real-life problem.
比如,很多问题不是线性的,如果用线性回归来做,那么与实际问题的关系就会相差很大,这样即使数据量再大也无济于事。
当我们使用更flexible的方法时,会造成bias的下降和variance的上升。通常来说,测试集上的MSE大小取决于两者的变化速度。一般来说,刚开始bias下降的多,MSE下降,后来variance上升的多,造成MSE上升,因此会有U形曲线。
classification setting
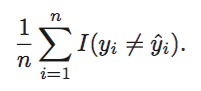
bayes classifier
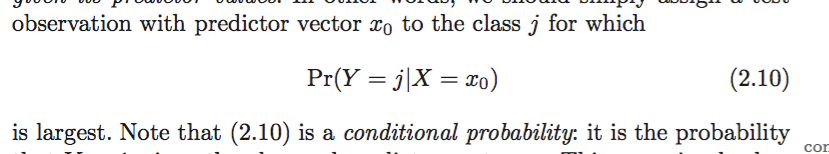
就是一个简单的条件概率分类器,根据不同的
xo
选择概率最大的
y
。
理论上,贝叶斯分类器能够选出最小error rate的模型,其错误率表示为
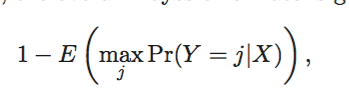
在仿真的数据中,错误率并不是0。因为两种类型的数据有重叠,所以有些点的概率小于1。从这种程度上,bayes error rate和irreducible error有相似的地方,都是不能减少的错误。
knn
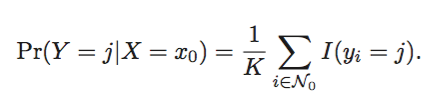
理论上,我们偏爱贝叶斯分类器去得到最优的模型。
但是实际上,我们并不知道特定点X对应的Y分布,因此不能够直接使用贝叶斯分类器。
但是,有很多方法,可以人工地构造条件概率分布,然后接着使用贝叶斯分类器。
KNN虽然很简单,但是它的error rate却可以很逼近最低的bayes error rate。
R
Exercise
当数据中噪声的含量很大,也就是inflexible的方法,因为越flexible的方法越fit噪声,造成variance的提高。















 1162
1162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









