







1、问题排查
之前做的一个需求,迁移 redis 缓存数据,当在生产环境操作时,缓存数量太多,导致缓存数据导出失败,失败的数据量大概是 2w 条,因此需要对 redis 导出进行性能优化。
经过 arthas 查看代码执行耗时情况,发现在代码中频繁的操作 redis 服务器,即频繁的连接断开 redis 服务器而导致的性能瓶颈(arthas 的具体使用可以见我这篇迁移 ES 数据的文章:迁移ES数据时使用arthas监控耗时)
这里对我之前导出 redis 数据的思路做一个说明:
将数据导出成 json 文件,然后在浏览器上下载这个文件,之后支持批量导入 json 文件。因此需要记录 redis 缓存数据的 key 值,过期时间 ttl,数据类型 type,缓存内容 value,导出时间 exportTime
(新的过期时间 ttl = 旧的过期时间 ttl -(导出时间 exportTime - 导入时间 importTime))
优化前代码:
// 在我的项目中,myRedisCache是已经封装好的redis组件
List<String> keyList = myRedisCache.keys(patternKey);
List<Map<String, Object> mapList = new ArrayList<>();
for (String key : keyList) {
Map<String, Object> keyValueMap = new HashMap<>();
// 我的业务需要获取到redis缓存数据的 key:键值 ttl:过期时间 type:数据类型 value:缓存内容
Long ttl = myRedisCache.ttl(key);
String type = myRedisCache.type(key).code();
// 目前来说,缓存中只有String和Hash两种类型
if("string".equals(type)) {
String value = myRedisCache.get(key);
// ... 根据业务将value转成json类型,
} else if ("hash".equals(type)) {
Map<String, Object> value = myRedisCache.hmget(key);
// ... 根据业务将map转成json类型
}
// 记录导出时间
long exportTime = System.currentTimeMillis();
keyValueMap.put("key", key);
keyValueMap.put("value", value);
keyValueMap.put("ttl", ttl);
keyValueMap.put("type", type);
keyValueMap.put("exportTime", exportTime);
mapList.add(keyValueMap);
}
// ...使用输出流输出mapList的内容可以看到,如果 keyList 的大小是 2w 的话,意味着 for 循环要执行 2w 次,对 redis 的请求次数达到 6w 次,经过测试,发现迁移 2w 个 key 的缓存数据在开发环境竟然需要接近 30min 的耗时,这是不可接受的!
于是考虑能不能对 redis 做一次连接操作而不断开,等到 for 循环结束再断开呢?这样子可以将耗时缩短到 1/3,但是即使是 1/3 的耗时,也是很恐怖的,由于项目中使用的 redis 是 3 版本的,因此只支持单线程,这意味着客户端需要在长达十分钟的时间内无法进行其他操作,这显然不理想。
经过查阅资料,打算对导出操作进行分批处理,并使用 redis 的管道操作。
2、redis 管道操作
在单个客户端中,如果需要读写大量数据,可以考虑采用管道(Pipeline)方式。如果采用管道方式,那么多命令可以通过批量的方式一次性地发送到服务器,而结果也会一次性返回到客户端。
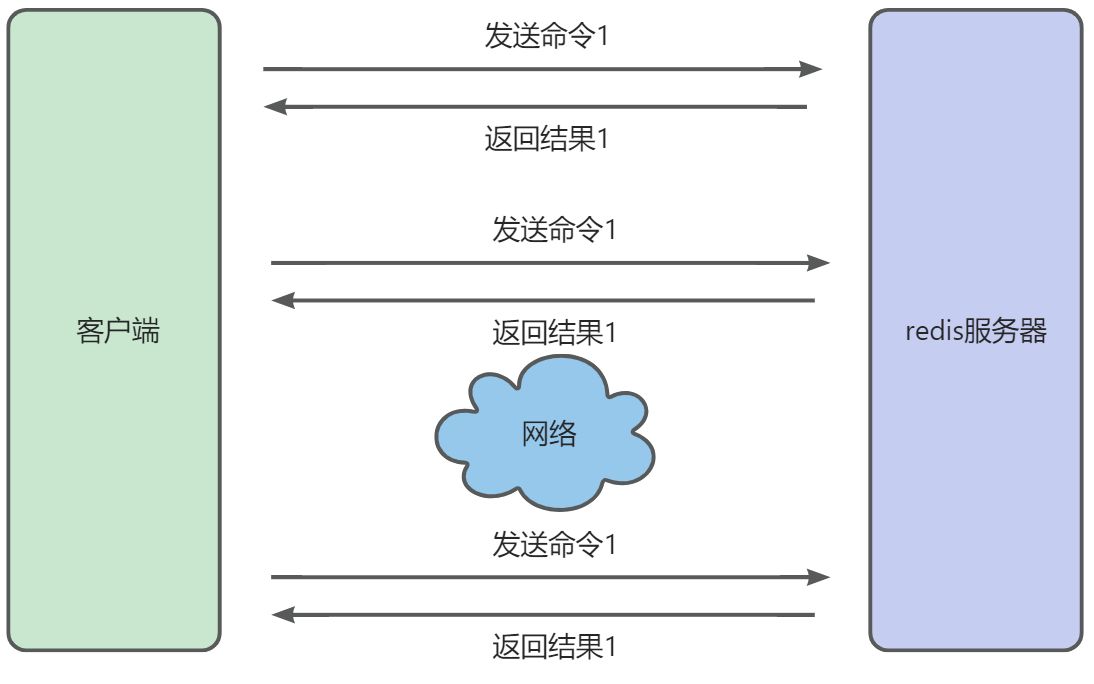
未使用管道执行 N 条命令,如果所示:
管道(Pipeline):一次向 Redis 发送多条命令。
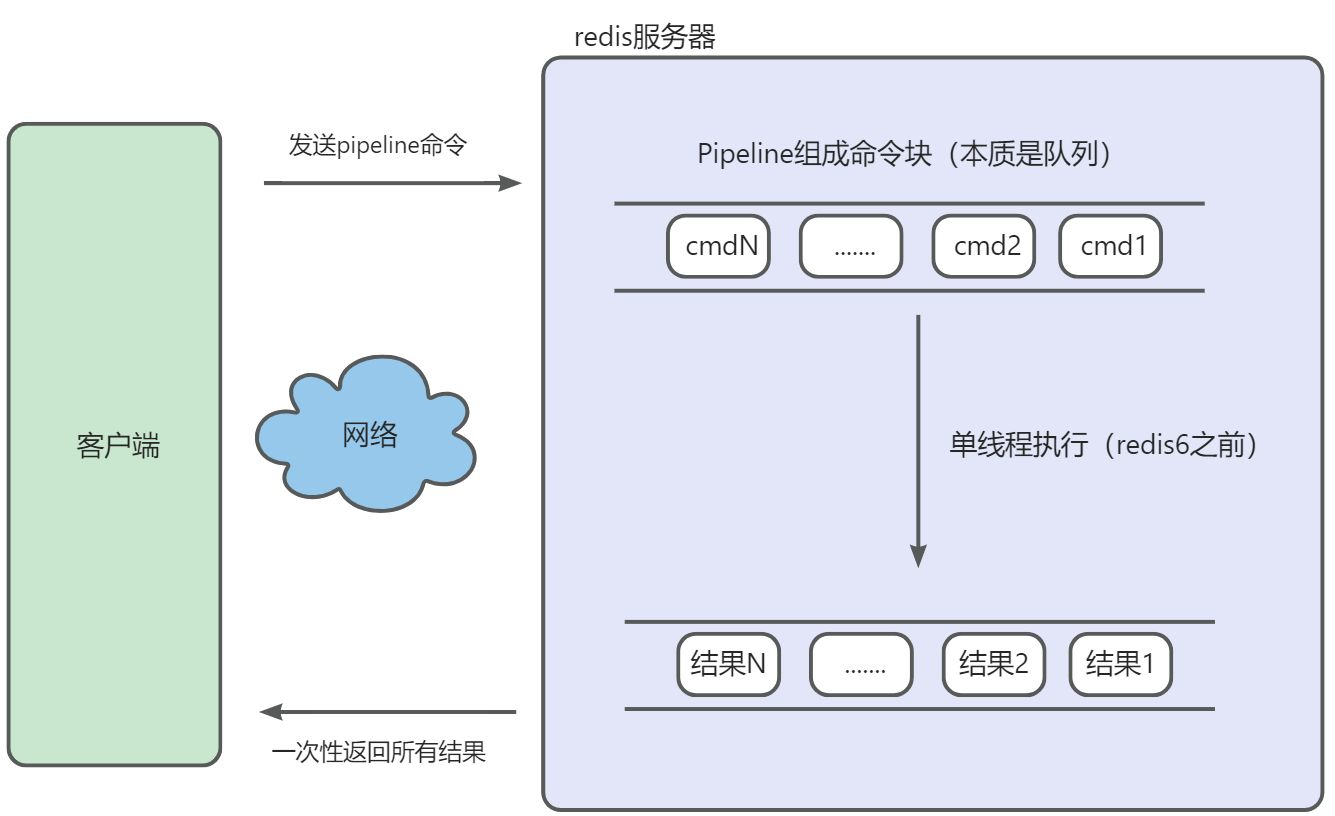
客户端可以一次性发送多个请求而不用等待服务器的响应,待所有命令都发送完后再一次性读取服务的响应,这样可以极大的降低多条命令执行的网络传输开销,管道执行多条命令的网络开销实际上只相当于一次命令执行的网络开销。
需要注意到是用 Pipeline 方式打包命令发送,Redis 必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。
所以并不是打包的命令越多越好。pipeline 发送的每个 Command 都会被 Server 立即执行,如果执行失败,将会在此后的响应中得到信息;也就是 Pipeline 并不是表达 "所有 Command 都一起成功" 的语义,管道中前面命令失败,后面命令不会有影响,继续执行。
因为在我的代码中 RedisCache 继承了 RedisService 接口,RedisService 接口被两个类实现,分别是基于 Jedis 和 RedisTemplate,下面展示这两处对 redis pipeline 的代码实现。
下面是优化后的代码(RedisTempalte):
// 在我的项目中,redisCache是已经封装好的redis组件
List<String> keyList = redisCache.keys(patternKey);
int totalKeys = keyList.size();
JSONArray jsonArray = new JSONArray();
for (int startIndex = 0; startIndex < totalKeys; startIndex += BATCH_SIZE) {
int endIndex = Math.min(startIndex + BATCH_SIZE, totalKeys);
List<String> batchKeys = keyList.subList(startIndex, endIndex);
// 将所需要的字段都存放在resultList中了,在这里我的BATCH_SIZE定义的大小是1000,
// 也就是说,resultList.size() == 1000
List<Map<String, Object>> resultList = redisCache.executePipeline(batchKeys);
// ...接下来是自己的业务操作
}
// ...使用输出流输出mapList的内容public List<Map<String, Object>> executePipeline(List<String> keys) {
// 由于new SessionCallback<Object>()匿名类的执行是不确定的,因此需要在外部手动初始化,并且匿名类引用的局部变量必须是
// `final`类型的或者`事实上是final`的,因此这里用原子类来包装List<Object>
// AtomicReference<List<Object>> typeList = new AtomicReference<>(new ArrayList<Object>());
List<String> orderKey = new ArrayList<>();
List<Object> typeList = redisTemplate.executePipelined(new SessionCallback<Object>() {
@Override
public Object execute(RedisOperations operations) throws DataAccessException {
for (String key : keys) {
orderKey.add(key);
operations.type(key);
// operations.type(key).code(); String type = operations.type(key).code();
// 上面这两种写法都是错误的,因为pipeline的操作是不确定的,也就是在这一刻它不确定
// 是否被操作了,因此无法进一步获取返回的结果,之后当execute中的方法执行完了,才有
// 确定的返回结果,此时才可以获取到返回值。在这里返回值存储在 typeList 中。下面同理
}
return null;
}
});
List<Map<String, Object>> mapList = new ArrayList<>();
// ...根据自己业务封装数据
return mapList;
}
基于 Jedis 的代码:
public List<Map<String, Object>> executePipeline(List<String> keys) {
// ProxyJedis jedis 的初始化操作...
Pipeline pipeline = jedis.pipelined();
List<Map<String, Object>> mapList = new ArrayList<>();
try {
for (String key : keys) {
pipeline.type(key);
}
List<Object> typeList = pipeline.syncAndReturnAll();
// ...业务代码
} catch (Exception e) {
// ...
} finally {
jedis.close();
}
return mapList;
}可见,在 Jedis 中,pipeline 返回结果需要调用 syncAndReturnAll() 方法,在 RedisTemplate 中则是执行 redisTemplate.executePipelined 方法后会自动返回执行结果。
此外,还需要注意,我在 redisTemplate 中批量处理的大小是 1000 个 key,但在 jedis 中则是 100 个 key,这是因为 jedis 在同等的超时机制和最大等待时长的情况下,允许承载的数据量更小,原因可能有:
- 内部实现: Spring Data Redis 可能在内部进行了更多的优化,以适应大数据量的场景。它可能在底层实现中采用了一些技巧,例如批量操作、异步执行等,以提高性能。
- 网络交互方式: Spring Data Redis 可能对网络交互有更好的优化,减少了网络往返的次数,提高了整体效率。
具体的原因我没有深挖,知道的小伙伴可以留言分享~
测试之后,使用基于RedisTemplate的管道操作,原本导出2w条数据需要大概30min的耗时,现在只需要2~3s,而使用基于Jedis的管道操作,耗时大约缩短为原来的 1/10。
参考文章:















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









