







摘要
“语义距离”这个概念试图对概念之间关联性的强弱给以定量表述。实际上语义距离的计算就是计算概念之间的相关系数。
论文中利用图结构计算词与词之间的距离,并用该距离去隔离给定单词的候选词。
注:
图是由顶点集V和顶点间的关系集合E(边的集合)组成的一种数据结构;
用二元组定义为:G=(V,E)。
实验部分
实验材料:
TLFi(一本法语词典),针对其中的名词,动词,形容词。
Prox基本的假设:
(论文中称该实验中计算语义距离的方法为Prox):
语义相近的词很可能是同义词。
大概步骤:
1.设计有向图(节点和边)
(1)节点:由字典中的条目或定义中出现的单词派生出来;
边:词与词之间的关联
(2)定义由两个成员组成:definiendum(被定义的词)和definiens(定义中出现的词)
(3)从字典中选择名词、形容词、动词的定义作为节点,并做下记录:
a型节点:被定义的词以及它的sub-sense(子定义)
标识由4个字段组成:
- 节点类型(即a)
- 其语法类别(S表示名词,V表示动词,A表示形容词)
- the lemma that correponds to the definiendum;
- 表示字典文章中子意义的层次位置的单词
o型节点:定义中出现的单词(定义中出现的所有类型都要被表示出来,包括虚词(代词、限定词和标点符号))。
标识由3个字段组成:
- 节点类型(即O)
- 单词的语法类别;
- its lemma.
(4).节点的连接方式:
①.自反(自身可到自身);
②.a型节点与a型节点之间:
高 → 低

eg.图中为怀旧这个词的六个子定义:
则a.S.nostalgie 会连接以上的六个子定义。
③.o型节点与o型节点之间:
每个o节点都连接到表示其入口的a节点,但表示入口的a节点和对应的o节点之间没有边
(例如,o.a.jonceux和a.a.jonceux之间有边,但a.a.jonceux和o.a.jonceux之间没有边)。
o节点 → a节点**(入口)**
2.将有向图转换为邻接矩阵,再转换为马尔可夫矩阵(需要求出转移概率,不知道怎么求)
(1)邻接矩阵:由“两节点之间有无边 ”推出 “两者间有无关系”
【两节点间有边相连,则表示为1,否则为0】
(2)马尔可夫过程:给予若某随机过程过去的状态以及当前的状态,该随机过程未来的状态只与当前状态有关。

(3)
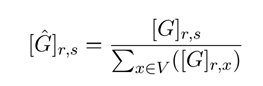
这个[G]是转换后的马尔可夫矩阵。(这个式子好像可以求概率)
(4)
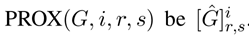
例如这个好像是求节点r经过i步路径到达s节点的概率。
3.计算词与词之间的距离
在图的构建基础上,发送随机粒子穿过图。
我们假设粒子在给定时间后在两个节点之间的平均距离表示这些节点之间的语义距离。显然,位于高度聚集区域的节点往往会被较小的距离隔开。
对于给定的单词,我们提取了与单词相同类别的a-节点作为候选同义词,这些单词与词典定义中代表该单词的o-node最接近。
实验改进与评估:
设置了另外两条不同的基线(大致理解为对同义词出现的不同的假设),并将其与Prox的加权与未加权进行比较。
疑惑:
1.文章中是想通过随机粒子的游走计算节点的距离(自我理解也就是词汇间的关系),那么计算之后是想要将其应用于马尔可夫图中的转移概率?
2.求出转移概率是因为求距离时要用到?
3.节点与节点的连接不是很明白
4.上面的2(3)的式子看不懂,说计算马尔可夫5步路径的概率是什么意思?是想看最后会在哪几个节点吗?由落在节点的概率大小来作为语义相似度的评估吗?
5.感觉文章很难翻译去看懂
学习的论文:
http://xueshu.baidu.com/usercenter/paper/show?paperid=75cd1b4deb7496469efec3aea131e4bf&sc_from=pingtai4&cmd=paper_forward&title=Synonym+extraction+using+a+semantic+distance+on+a+dictionary&wise=0















 1505
1505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









