







author: 张俊林
语义编辑距离其实是去年和语义Jaccard一起做的,这篇文章主体内容也是去年写的。之所以现在才看到,说明我手上的存货文章几乎见底了,否则也许这篇很久以后才会发出来。一般我手上会写出后攒着几篇作为存货,这是为了尽量做到周更,避免没精力写的时候手上没货以作备用。最近一个多月写东西的动力急剧衰减,所以没有写任何新的文章,只能陆续用存货来救场,可见持之以恒地做一件费力又没有明显收益的事情确实是挺不容易的,不过今年尽量还是能够做到每周一更,也算是对自己的一种锻炼。
为什么这里我们说是穷人的语义处理工具箱?在“穷人的语义处理工具箱之一:语义版Jaccard”一文开头我们说明了原因,此处就不再赘述。我们直接进入主题。
|编辑距离(Edit Distance)
编辑距离由俄罗斯科学家Vladimir Levenshtein提出,所以编辑距离也被称为Levenshtein距离。这是一种很常用的计算两个字符串相似性的度量工具。它的具体含义是指把一个字符串转换为另一个字符串所需要的最小编辑次数,这里的“编辑”一般包含三种操作:插入一个字符、删除一个字符以及将某个字符替换成另外一个字符。假设每种操作的代价都是1,那么把一个字符串通过上述三种操作不断变换,直到转为另外一个字符串的最小编辑操作次数n就是编辑距离:n。
比如假设我们现在手头有两个字符串:edit和red,那么通过下列操作来将edit转换为red:
Step1:edit->redit (插入r)
Step 2:redit->redt (删除i)
Step 3:redt->red (删除t)
总共做了三次操作,假设每种操作代价是相同的,都是1,那么edit和red的编辑距离是3。
编辑距离是动态规划的一个典型实例,假设给定了要比较的两个字符串a和b,我们定义:
EditDistance(i,j):字符串a的长度为i的子串(即a中由第1个字符到第i个字符构成的子串)和字符串b长度为j的子串(即b中由第1个字符到第j个字符构成的子串)的编辑距离。
那么可以递归定义编辑距离如下:
初始状态1:
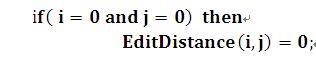
意思是:如果两个子串长度都为0,那么它们的编辑距离为0,这个好理解。
初始状态2:
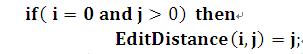
意思是:如果a句子的子串长度为0而b句子的子串长度不为0,那么它们的编辑距离为b句子的子串长度,这个也很好理解,因为要把a句子子串替换为b句子子串,那么只要不断插入b句子子串的j个字符就行。
初始状态3:
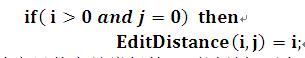
这个和初始状态2的意思其实是类似的,不过是把两个子串对调一下位置。它的意思是:如果 b句子的子串长度为0而a句子的子串长度不为0,那么它们的编辑距离为a句子的子串长度,这个同样也很好理解,因为要把a句子子串替换为b句子子串,那么只要不断删除a句子子串的i个字符就行。
递归状态:
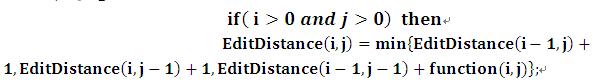
如果两个子串长度都不为0,那么需要考虑如下三种情况,并取其编辑距离最小值:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9159
9159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









