







导语
今天,我们介绍的是排序算法经典的一种排序算法,这个算法是插入排序。
相信大家都玩过纸牌。插入排序的工作方式就像许多人排序一手扑克牌。
开始时,我们的左手为空并且桌子上的牌面朝下(意味着我们不在翻开之前并不知道下一张牌是多大的)。
然后,我们每次从那些牌中选出一张牌,并把它插入到正确的位置(一般我们认为左边的最小),我们从左到右(或从右到左)将它与已在手中的每张牌进行比较。

动态图演示如下:
算法分析
对于插入排序,我们将伪代码的过程命名为INSERTION-SORT
其中
- 参数是A[1..N],为长度n的一个需要排序的序列。
- A.length表示数组A中元素的数量
该算法在数组A中重排这些数,在任何时候,最多只有其中的常数个数字存储在数组外面。
等INSERTION-SORT结束时,输入数组A包含排序好的输出序列。
算法伪代码
INSERTION-SORT(A)
1 for j=2 to A.length
2 key = A[j]
3 //Insert A[j] into the sorted sequence A[1..j-1]
4 i = j - 1
5 while i > 0 and A[i] > key
6 A[i+1] = A[i]
7 i = i - 1
8 A[i+1]=key图示分析
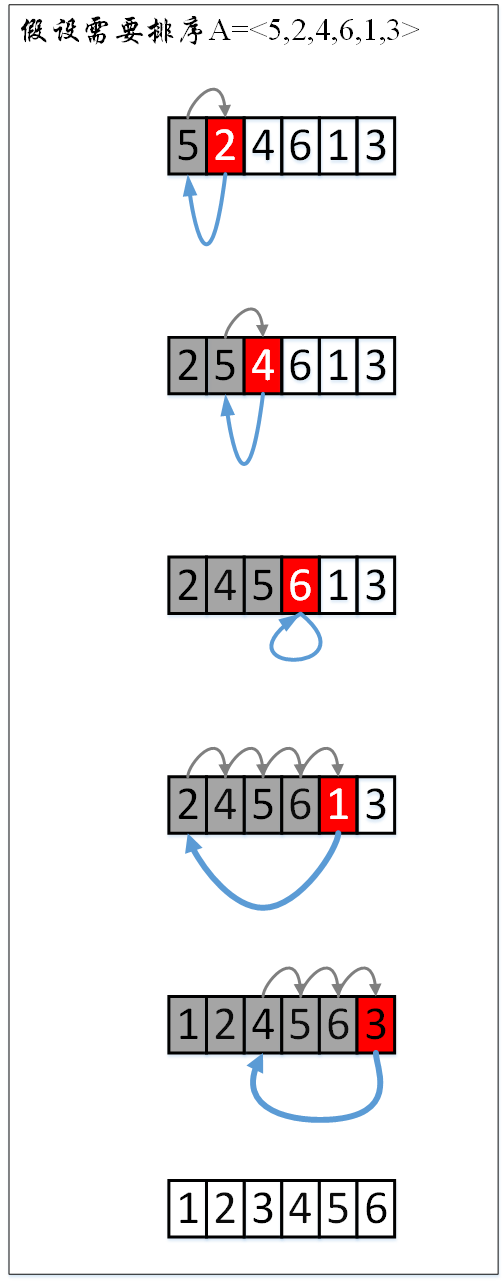
算法复杂度分析
| INSERTION-SORT(A) | 代价 | 次数 |
|---|---|---|
| for j=2 to A.length | c1 | n |
| c2 | n−1 | |
| i = j - 1 | c3 | n−1 |
| while i > 0 and A[i] > key | c4 | ∑nj=2tj |
| A[i+1] = A[i] | c5 | ∑nj=2(tj−1) |
| i = i - 1 | c6 | ∑nj=2(tj−1) |
| A[i+1]=key | c7 | n−1 |
该算法的运行时间是执行每条语句的运行时间之和。基于此,我们可以计算在具有n个值输入上INSERTION-SORT(A)的运行时间T[n],我们将代价与次数列对应元素之积求和,得
最好情况下:
对于给定的n个需要排序的,若输入已排序,则出现最佳情况。这个时候,对于j=2,3,….,n,可以发现,当i取初值j-1时,有 A[i]≤key 。从而对j=2,3,…,n有 tj=1 ,也就是说只需要比较一次。
我估计说到这里,有些人看不懂,我就简单的说吧:
假设现在你左手中的牌都是已经排好序了的,而且是从小到大排序,现在你手上拿了一张牌,比你左手上的牌最右边(即是你手中牌中最大)还要大,那么你一定要保证牌是从小到大的排序,必然会把牌之间放在你牌的最右边。而这个过程,你只是和你本来有的牌的最大一张比较了一次。
所以最好的情况下的时间复杂度 Tn 为:
T(n)=c1n+c2(n−1)+c3(n−1)+c4(n−1)+c7(n−1)=(c1+c2+c3+c4+c7)n−(c1+c2+c3+c4)
即T(n)=an+b其中 a 和
b 依赖于语句代价 ci 。我们可以得出一个结论:
在最好情况下,插入排序的时间复杂度在 O(n) ,即 线性时间 上完成排序。
最坏情况下:
若输入数组已方向排序,即按照递减排序排好了序,则导致最坏情况。我们必须把每个元素A[j]与整个已排序子数组A[1..j-1]中的每个元素都要进行比较,所以对j=2,3,…,n,有 tj=j 。
我估计有人问为什么 tj=j ,那么我就这样告诉你吧:
tj 是while语句进行比较语句的执行的次数,最后一次是进行i>0的判断,所以A[1..j-1]与A[j]实际上进行了j-1次比较,那么为什么进行j-1次比较呢,我们这么想,j代表我要加入第几张牌,我就以j=3来说,我即将加入第3张牌进入我左手的牌中(左手有两张牌,已经升序排列了好了),而这个牌比前面2个都要小,那么我是需要和比较两次才知道的,所以一共比较j-1次。
值得注意的是,这时候的
∑j=2nj=n(n+1)2−1
以及
∑j=2n(j−1)=n(n−1)2
上述是求和递推公式,我并不会给予证明,毕竟这可不是数学教学。所以最坏的情况下的时间复杂度 Tn 为:
T(n)=c1n+c2(n−1)+c3(n−1)+c4(n(n+1)2−1)+c5(n(n−1)2)+c6(n(n−1)2)+c7(n−1)=(c42+c52+c62)n2+(c1+c2+c3+c42−c52−c62+c7)n−(c2+c3+c4+c7)
即
T(n)=an2+bn+c其中 a 、
b 和 c 依赖于语句代价ci 。我们可以得出一个结论:
在最坏情况下,插入排序的时间复杂度在 O(n2) ,即 n的二次函数 上完成排序。
平均情况和最坏情况差不多,复杂度也在 O(n2)
结语
接下来,我将会在下一文中编写出语言版本去实现算法。敬请期待。
















 4452
4452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











